Java教程
给你一本武林秘籍,和KeeWiDB一起登顶高性能

KeeWiDB,骨骼清奇,是万中无一的NoSQL奇才。现将KeeWiDB高性能修炼之路整理至此秘籍,见与你有缘,随KeeWiDB一同登顶吧!
创新性分级存储架构设计,单节点读写能力超过18万QPS,最高可线性堆叠至千万级并发吞吐量,同时兼容Redis协议,访问延迟达到毫秒级,新一代分布式KV存储数据库KeeWiDB在NoSQL江湖中脱颖而出。
由内而外深入探索其成长史,可从三个角度讲起,为并发而生的架构、量身“自”造的引擎以及新老硬件的加持。修炼的过程有点长,且听我娓娓道来。
江湖 · 风云涌动
随着web2.0的快速发展,SNS网站的兴起彻底带火了NoSQL,个性化实时的动态请求带来高并发负载问题、海量用户产生的动态数据带来存储效率问题等都把关系型数据库难得够呛。更别提突然爆火需要的超高吞吐、全球部署需要的超低延迟了。
至此数据库江湖一分为二,SQL是“稳重”的高僧,而NoSQL则是“灵活”的新秀,以“轻”、“快”突出重围。
江湖道法:一生二,二生三,三生万物。
NoSQL数据库领域逐渐演化出四大门派,分别是键值(Key-Value)存储派、文档(Document-Oriented)存储派、列(Wide Column Store/Column-Family)存储派和图形(Graph-Oriented)存储派,各具特色。
大弟子KV存储数据库应用最为广泛、技术最为成熟。过去几年,江湖中最受欢迎的数据库产品Redis,就是KV一派,支持高并发、低延迟以及丰富的数据结构。但Redis本身是一个全内存的KV数据库,无法解决海量数据所带来的规模与成本问题;同时,随着近些年Redis的应用场景渐渐突破了缓存的范畴,其数据可靠性也面临巨大的挑战。
为了解决Redis的痛点问题,江湖中出现了基于磁盘的KV数据库产品,例如Pika、Kvrocks、SSDB等。这些产品虽然一定程度上能够满足业务在成本、持久化、规模方面的诉求,但性能跟不上,且与Redis有着明显的差距。
江湖在等待一位武林高手破解难题。KeeWiDB,应运而生,脱颖而出。
KeeWiDB·脱颖而出
擂台赛,突出重围!
来看一组基于String类型的单节点测试结果,得益于多线程优势,KeeWiDB不仅在吞吐量上超过了Redis,而且P99 延迟能做到不超过 3 毫秒。
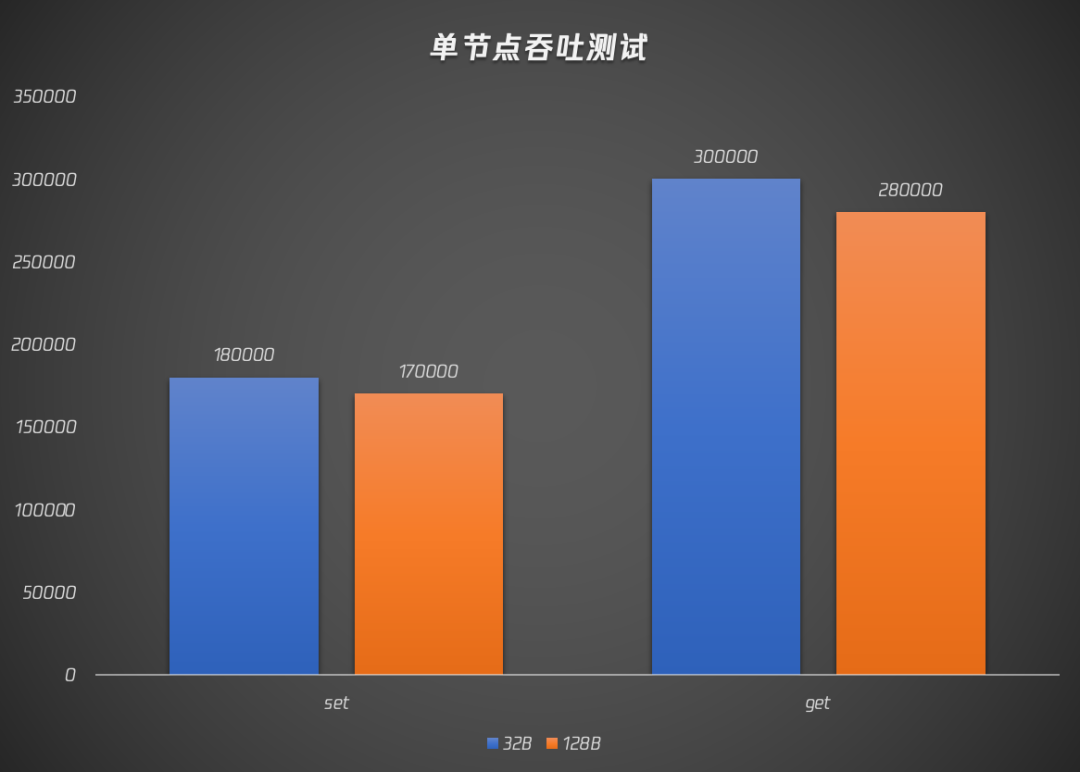
这么高的吞吐是怎么做到的呢?简单说,目标导向(吸星大法)!
KeeWiDB就是要做到 Redis 和基于磁盘的 KV 数据库产品做不到的,就是要实现集低成本、高并发、高性能于一体。
具体地,新一代分布式KV存储数据库产品KeeWiDB,保留了基于磁盘的 KV 数据库产品对于成本和规模问题优秀解法,通过创新性的软硬件结合方法进一步提供了媲美Redis的性能以及命令级持久化的能力,同时满足了业务在性能、成本、持久化、规模四个方面的核心诉求,带给用户最极致的使用体验。
台上一分钟,台下十年功!KeeWiDB的成就并非凭空,也得是历经寒洞修炼才能走上高性能之路。
筋骨篇·为并发而生的软件架构
要想成为一个武林高手,首先要有一副强健的筋骨,这是一切武功的基础。对于KeeWiDB来说,一个优秀的软件架构就是它的钢筋铁骨。
(1)Scale Out的整体架构
KeeWiDB既是分布式KV存储产品,又能支持冷热分离。江湖都在传其架构必然复杂,但大道至简,“Simple is The Best”。
KeeWiDB的架构就只分为Server和Proxy两层,如下图:
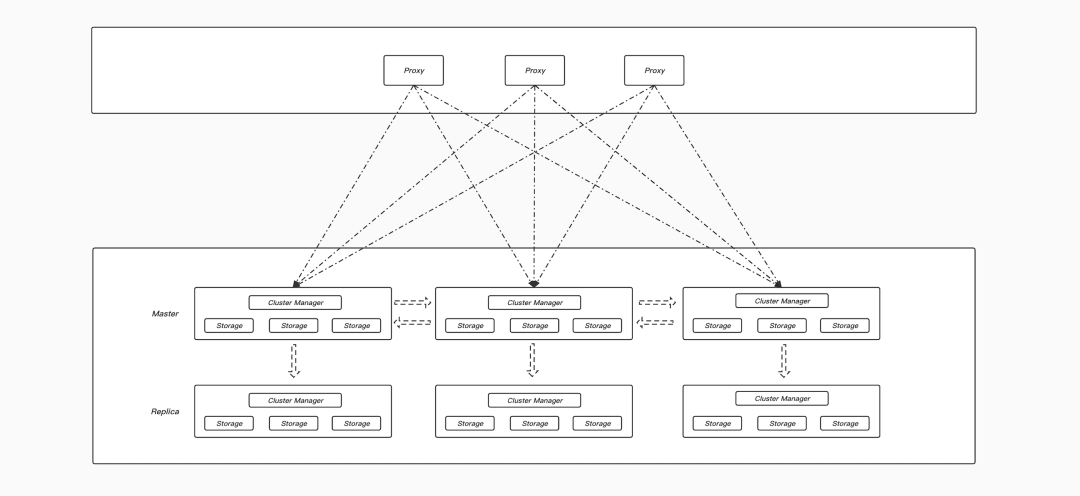
图:KeeWiDB的整体架构
Server层由多个server节点组成,实现数据存储与数据库核心特性。
与Redis Cluster类似,Server层的节点先被分为一个个独立的分片,再将整个系统中的数据划分到16384个虚拟slot中,由每个分片独立负责其中一部分slot的读写;分片内部有多个节点,节点之间通过Replication协议完成数据复制,构成一主多备的高可用架构;分片之间通过Gossip协议通信,一起组成一个去中心化的集群。这样,用户访问Server层中任意节点,请求都能路由到正确的节点。此外,Server层还支持新节点自动发现、故障探测、故障自动切换、数据搬迁等能力,极大降低了运维成本。
Proxy层由多个无状态的proxy节点组成,实现代理转发功能。
这一层是可选的,主要是帮助没有实现集群重定向协议的客户端屏蔽KeeWiDB底层的实现,让用户可以用像访问原生Redis一样访问KeeWiDB,减少用户的迁移成本。同时,我们在Proxy层也做了相当多的产品功能,例如监控指标采集,流量控制,读写分离等等。
这里再强调一点,无论是 Server层还是Proxy层,都可以很方便地通过新增节点来快速地提升整个系统的并发能力。
(2)Shared Nothing的多线程模型
作为一个基于持久化介质的数据库,KeeWiDB很自然地选用了多线程模型,以便使用更多的CPU核心来提升单节点性能。传统的数据库存储引擎往往使用多线程共享资源的编程模型,在这种模型下,性能的优化方向是尽最大努力减少锁竞争,提高并行度。例如,LevelDB的MemTable为了提升性能就是基于无锁SkipList来实现的。
但是存储引擎内部的共享资源除了各种数据结构和数据文件外,往往还包括WAL这样的日志文件。这些日志文件的写入过程涉及到持久化操作,相对较慢,但为了保证写入的顺序一般又需要加锁。这样一来,虽然是多线程并发地处理用户请求,但到了写日志时却退化成了串行执行,显然会成为性能瓶颈。同时,随着硬件技术的发展,网络和磁盘的访问延迟可降至10us量级,软件栈的处理延迟在整个IO路径上的占比逐渐凸显出来,这种情况下无论是锁冲突还是线程的上下文切换,都可能造成巨大的性能毛刺。
要解决上述这些问题,必须禁止线程间共享资源,即Shared Nothing。
在前文中我们谈到,Server层每个节点独立负责一部分slot,这里我们又进一步将每个节点的slot区间按规则划分为多个子区间,每个worker线程负责特定一组slot子区间的读写,并且每个worker线程享有单独的管理结构和存储资源,以此保证在每个用户请求的处理过程中都不涉及任何的线程锁和线程上下文切换,这无论是对单个请求延迟的降低,还是多个请求并发的提升,都有巨大的好处。
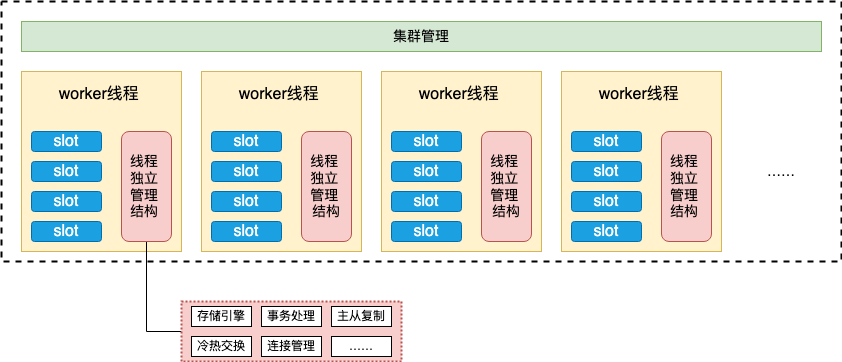
图:KeeWiDB单个节点内部多线程的Shared Nothing架构
(3)协程,让并发更上一层楼
通过前文对整体架构和多线程模型的设计,KeeWiDB已经可以让分属不同slot的用户请求高效地并发起来了。但一个线程负责的往往不止一个slot,同一个slot内也远不止一个key,所以用户的多个请求分发到同一个线程的概率还是有的,如果线程内部只能顺序地处理这些请求,那大量的时间都会花费在同步等待磁盘IO上,并发度还是不够。
为了进一步提升单个线程内部的并发度,我们引入了C++20的新特性——协程。
协程的本质是函数。调用协程后,原来的地方就会被阻塞,主动把CPU让给别的协程,这就实现了线程内部的并发;等条件满足了再通过协程的中断可恢复特性在原来的地方继续运行,这种写法又跟同步一样自然。
简言之,协程用同步的语义解决了异步的问题,让我们用较小的开发代价实现了巨大的性能提升。
内功篇·量身打造的存储引擎
钢筋铁骨的基础已经打好,下一步KeeWiDB需要一套适合自己的内功心法。
如果内功心法高效,即使是简单的一拳一脚也能虎虎生风,威力十足;反之,如果内功心法弱鸡,那再华丽的招式也只能是花拳绣腿,中看不中用。
对于KeeWiDB这样的数据库存储产品来说,存储引擎就是我们要重点打造的内功心法。
(1)LSM Tree的“功过是非”
当前业界主流的KV存储产品大都采用了基于LSM Tree 的 RocksDB / LevelDB 作为自己的存储引擎。这主要是因为,LSM Tree通过独特的“Out-of-Place Update”设计,可以将来自用户的离散随机写入转换为对持久化介质的批量顺序写入,而磁盘设备的顺序IO性能往往要优于随机IO,这种设计有利于磁盘设备扬长避短。
但凡事有利必有弊,RocksDB / LevelDB这类存储引擎优异的写入性能也是牺牲了一些东西才换来的,在《RocksDB Tuning Guide》中就有提到它的三大问题:
- 空间放大(Space Amplification):用户对数据的所有更新操作都是“Out-of-Place Update”,数据可能有多个版本,但失效的旧版本数据需要等Compaction才能真正的删除,无法及时清理,从而造成空间放大。
- 读放大(Read Amplification):用户读取数据时,可能需要从上到下(从新到旧)查找多个层的SSTable文件,并且在每一个SSTable文件中的查找都需要读取该文件的多个meta数据块,从而造成读放大。
- 写放大(Write Amplification):用户写入数据时需要先写入WAL文件,后续无论是将内存中的MemTable持久化为L0层的SSTable文件,还是将每一层的小SSTable文件合并到下一层的大SSTable文件,都会产生重复写入,从而造成写放大。
其中,空间放大和读放大是“Out-of-Place Update”这种方式天生带有的特点,而写放大则是为了优化前两个问题,引入Compaction机制后带来的。这三个问题是一组矛盾体,就像分布式系统中的CAP一样不可兼得,只能根据具体的业务场景做均衡和取舍。
在HDD作为主流磁盘设备的时代,顺序写入的性能比随机写入高2~3个数量级,用几十倍的写放大来换取近千倍的写入性能提升是一桩划算的买卖。但随着硬件技术的发展,SSD逐渐替代HDD成为当前的主流磁盘设备,情况悄然发生了变化:
一则,SSD的顺序写入性能虽然依旧高于随机写入,但差异已经缩小到十倍以内;
二则,SSD的使用寿命和其写入量有关,写放大太严重会导致SSD内部元件的可擦除次数急剧下降,大大缩短其使用寿命。
在这种情况下,这笔买卖是否依旧划算?
(2)基于哈希索引的自研存储引擎
KeeWiDB作为一个云上的数据库产品,天然需要面对多租户场景,一台机器上往往会部署多个server节点,这些节点可能会共享同一块磁盘;同时,在前文“筋骨篇”的第二节中我们提到每个server节点的进程中还有多个worker线程,每个线程都有独立的专属存储引擎,但它们共享一块磁盘。所以,即使每个进程中的每个线程自身都是顺序地写入这块磁盘,但从磁盘的角度,来自不同进程不同线程的写入整体上还是随机的。
此外,KV存储产品应对的业务场景里,用户请求都是以点查为主,范围查询较少,对应到对磁盘设备的访问上,就是随机读占绝大多数,顺序读较少。LSM Tree类存储引擎虽然可以把随机写转换为顺序写,却不能把随机读也转为顺序读。相反,LSM Tree类存储引擎的设计思想本质上就是牺牲一部分读性能来换取极致的写性能,对随机读反而更不友好。
综合前文提到的LSM Tree类存储引擎的优缺点,以及KV存储云产品的业务特点,KeeWiDB最终选择自己来,推出基于哈希索引的全新自研存储引擎。
新引擎基于Page页进行数据组织,并通过Free List进行页管理;而每个Page又包含数个Block,它是最小的存储分配单元,并通过Page页首部的一个Bitmap进行管理。这样我们就能在O(1)时间复杂度下,进行高效的数据块分配和释放,同时具有更加紧凑的数据组织形式,更小的写放大和更小的空间放大。
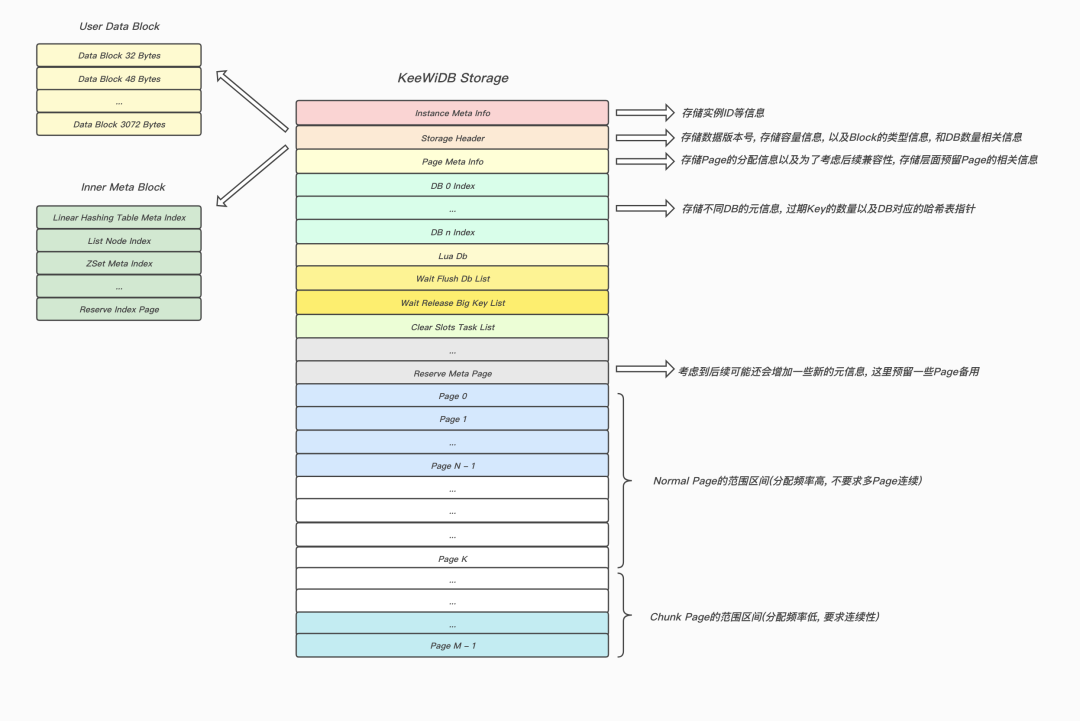
图:KeeWiDB自研存储引擎的数据组织结构
打开Page页内部结构给大家瞧瞧!
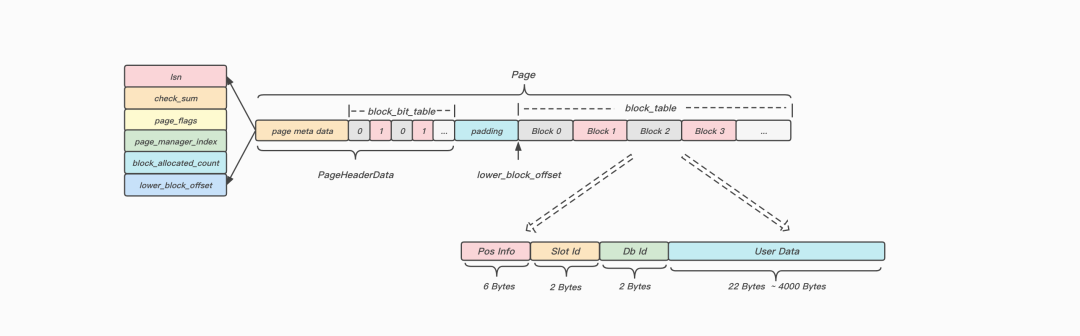
图:KeeWiDB自研存储引擎的Page页内部结构
新引擎采用哈希表作为主索引,主要是基于其优秀的等值查询时间复杂度。在工程实践中,每个哈希桶对应1个Page页,在Meta Page缓存到内存的情况下,每次读写操作平均只需要1次磁盘IO。同时,作为磁盘型数据库,在内存资源有限的情况下,相较于B族索引,哈希索引的空间占用更小,具有更高的内存利用率。
而为了避免哈希resize可能会导致的长尾延迟问题,KeeWiDB选择了线性哈希表。线性哈希表能够将哈希桶分裂的消耗分摊到单次插入操作中,且每次只需要分裂1个哈希桶,绝大多数情况下,分裂只需要1次额外的磁盘IO,操作消耗更小,用户请求的延迟更稳定。
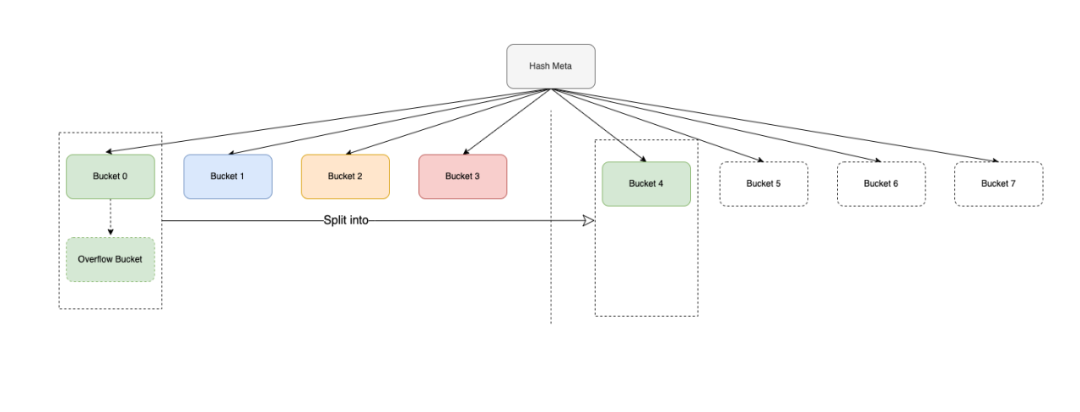
图:KeeWiDB自研存储引擎的线性哈希索引
在前文“筋骨篇”的第三节中我们提到,为了在处理磁盘IO时更好得利用CPU资源,我们引入了协程。为了适配协程并发的需求,KeeWiDB在新引擎的线性哈希表做了并发安全的改造,能支持增删查改的并发操作,而基本的互斥操作单元仅为1个Page页,在Shared Nothing的多线程模型里,多协程的互斥基本不需要额外的同步消耗,能更好的利用计算资源,提高系统整体的吞吐量。
兵器篇·来自硬件技术的加持
工欲善其事,必先利其器!自我修炼已完成,如果再有一把称手的神兵利器,岂不是如虎添翼?
(1)拥抱新硬件
KeeWiDB的立项之初,除了专注自身的软件架构和存储引擎设计之外,也一直在关注新型硬件技术的发展。当时市面上比较成熟的新型存储介质有:ScaleFlux公司的可计算存储设备,Samsung公司的KV SSD,以及Intel公司的Persistent Memory(PMem)。
KeeWiDB综合考虑了易用性、成熟度、性价比等多方面的条件之后,最终选择Intel公司的PMem,它具有以下特点:
- 持久化:PMem提供持久化相关指令,完成持久化的数据即使掉电也不丢失;
- 低延迟:PMem的读写速度比SSD还要快1~2个数量级,接近内存的读写速度;
- 大容量:PMem的单条最大容量可达512GB,相比于传统内存的单条最大容量64GB有8倍的提升,单服务器容量轻松上TB;
- 字节寻址:PMem的读写大小没有限制,相比于传统磁盘每次至少读写一个块(通常大小为4KB)的限制,其读写粒度更细。
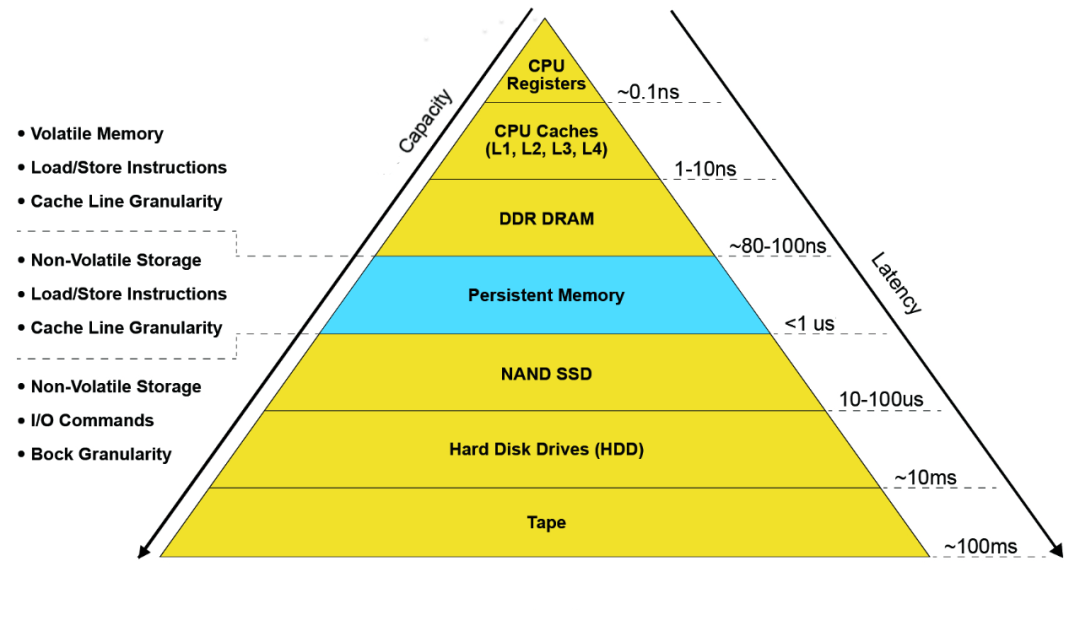
图:PMem新硬件在整个存储硬件体系中的位置
数据库相关的研发和运维同学都知道,数据库虽然理论上需要保证事务的ACID四大特性,但实际上,这里面的D(durability)很难百分百做到。以MySQL为例,要想做到严格的机器掉电不丢数据,必须开启“双1设置”;但因为磁盘的写入速度相比内存慢2~3个数量级,一旦开启“双1设置”,数据库的写入性能就会急剧下降到用户难以接受的地步。所以在实际使用中很少有用户开启MySQL的“双1设置”,这就只能做到进程崩溃时靠操作系统Page Cache刷脏的帮助不丢数据,机器掉电还是会丢一部分数据。
KeeWiDB将事务日志选择性地存储到PMem中,利用其字节寻址的特性和低延迟持久化的特点,在实现命令级持久化的同时依然可以为用户提供高性能的写入。
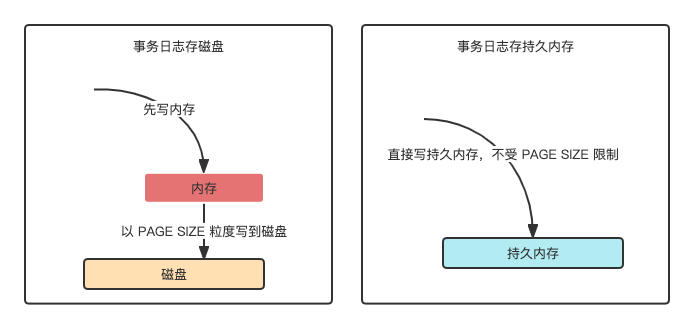
图:事务日志存磁盘和PMem的对比
(2)善用老技术
云上的数据库产品需要处理复杂多变的用户场景。俗话说,林子大了什么鸟都有,有的用户延迟敏感,有的用户并发高,还有的用户流量猛。
前文中提到,多个实例的server节点可能会被分配到同一块物理磁盘,虽然当前数据中心使用的NVMe SSD的性能已经非常强悍,但如果多个实例的用户同时发起高并发或大流量的读写,还是可能超出单块SSD的性能上限。
对于硬件技术的应用,KeeWiDB从来都是喜新但不厌旧(吸星大法再现)。所以针对这种情况,KeeWiDB采用成熟的RAID 0技术,将多块SSD以条带的方式组成一个磁盘组,对软件层展现为一块逻辑磁盘。这样一来每个节点都可以同时用到多块SSD的IO能力,单个节点的并发上限有效提升,也起到了在多个实例之间削峰填谷的作用,KeeWiDB处理读写热点冲突的能力也大大提升。
当然,有读者有疑问了,RAID 0固有的缺点是数据没有冗余,磁盘组中的任意一块SSD损坏都会导致丢数据,KeeWiDB不会因此丢数据吗?
别担心,因为KeeWiDB的每个分片都是主备架构的,无论是master还是replica的磁盘组损坏,都还有另一个节点可以继续服务。即使是主备两个节点的磁盘组都损坏了,也还有备份机制可以恢复数据。
未完待续
有了高度可扩展的软件架构做筋骨,高效强大的自研存储引擎当内功,再加上来自新老硬件技术的兵器加持,KeeWiDB已经是大家心中的“武林高手”了。但,KeeWiDB的目标是要成为“绝顶高手”,还少了那么一些些的细节。
这里先放点预告,下次再展开说说!
- 为了提升server节点的吞吐,KeeWiDB做了组提交的优化,并去除了一般组提交方案中的主动等待来降低对延迟的影响;
- 为了提升hash/set等复杂结构的并发度,KeeWiDB细化了事务锁的粒度来允许同一个一级key的不同二级key之间做并发读写;
- 为了解决现有基于key的冷热分离方案无法解决的大key问题,KeeWiDB实现了基于page的冷热分离方案,提升了冷数据读取性能;
- 为了让replica节点回放命令保证主备一致性的同时速度能跟上master节点的写入速度,KeeWiDB做了并发回放的优化;
等等等等……
-
Java中定时任务实现方式及源码剖析11-24
-
Java中定时任务实现方式及源码剖析11-24
-
鸿蒙原生开发手记:03-元服务开发全流程(开发元服务,只需要看这一篇文章)11-24
-
细说敏捷:敏捷四会之每日站会11-24
-
Springboot应用的多环境打包入门11-23
-
Springboot应用的生产发布入门教程11-23
-
Python编程入门指南11-23
-
Java创业入门:从零开始的编程之旅11-23
-
Java创业入门:新手必读的Java编程与创业指南11-23
-
Java对接阿里云智能语音服务入门详解11-23
-
Java对接阿里云智能语音服务入门教程11-23
-
JAVA对接阿里云智能语音服务入门教程11-23
-
Java副业入门:初学者的简单教程11-23
-
JAVA副业入门:初学者的实战指南11-23
-
JAVA项目部署入门:新手必读指南11-23
