Java教程
TiFlash 源码解读(七)TiFlash Proxy 模块

Overview
在前面的介绍中,大家应该对 TiFlash 如何存储、计算有了一定的了解。那么今天我们主要讲解一下 TiFlash 如何被添加副本,以及获得数据的。
如何对一张表添加一个 TiFlash 副本呢?是通过下面的指令
ALTER TABLE t SET TIFLASH REPLICA 1
也就是说,此时这张表对应的数据已经在集群中的 TiKV 上被存储了,我们实际上需要的是将数据从 TiKV 导入到 TiFlash 的存储中。
有很多方案可以做到这一点,我们有一个很棒的产品 TiCDC,指定 TSO,它可以捕捉 TiKV ChangeLog,并将 TSO 时刻对应的状态同步到下游支持 MySQL 协议的数据库中。但 TiDB 作为一个 HTAP 数据库,我们希望 AP 部分的 TiFlash 能够提供实时一致性。例如在读取时,我们只需要 resolve 直接相关的一些 Region,而不是等待一个表甚至多个表的 resolve ts。
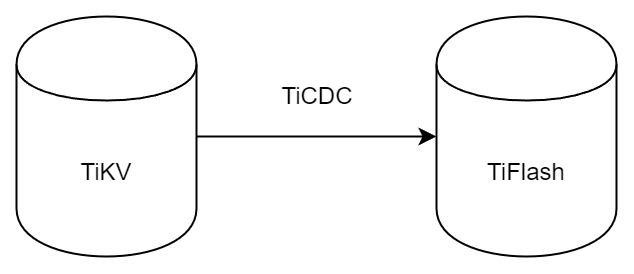
因此,TiFlash 选择将自己作为一个“特殊的” TiKV 节点加入 TiDB 集群。这样的特殊性是必要的,例如 TiFlash 需要在合适的地方做行转列,或者让 TiKV 在行为上不依赖于底层的 RocksDB 存储等。这个特殊的 TiKV,就是 TiFlash Proxy。目前它是作为一个 TiKV fork 而存在的,但我们计划在未来将它作为一个 depend TiKV 的独立项目来维护。
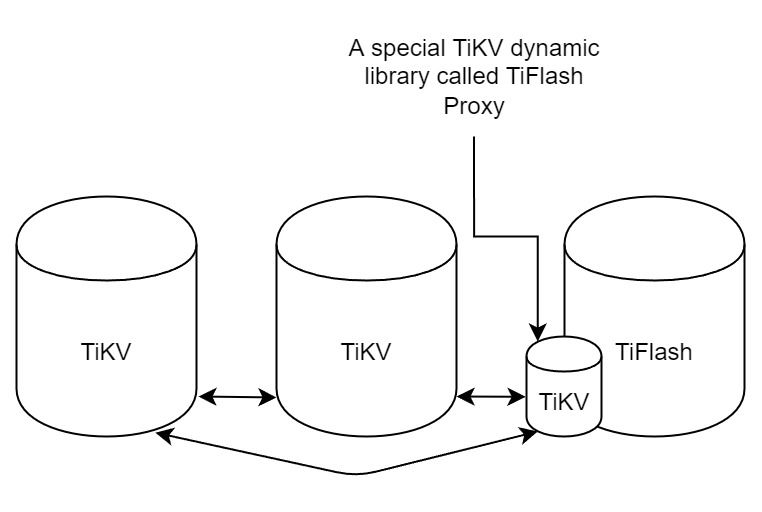
在我们的官网上,给出了整个 TiFlash 的体系结构,其中 Raft Store 附近的模块就是 TiFlash Proxy。可以看到,它会和 PD 通信注册自己作为一个特殊的 TiKV store,加入 TiKV 中的各个 Raft Group 进行复制,将 TiKV 传来的数据 apply 给 TiFlash。
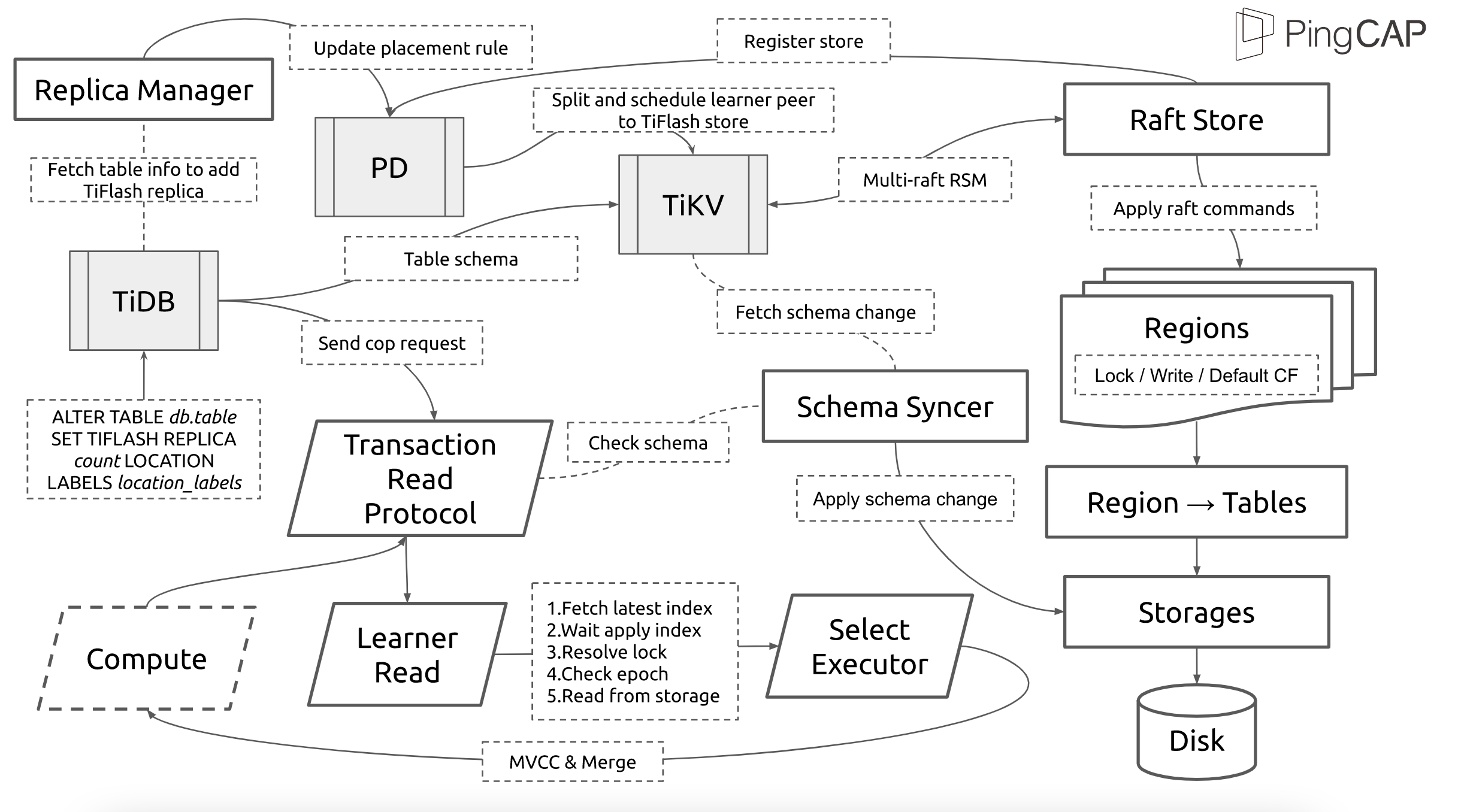
但相比之下,我更喜欢用下一幅图来介绍。没错,如果把 TiKV 比作纳威人,那么 TiFlash 就是进入纳威星球的地球人。地球人需要将自己伪装成纳威人的样子才能融入纳威族。因此便有了阿凡达,也就是 TiFlash Proxy。Proxy 满足 TiKV 协议对 Store 的定义,从而可以向 PD 注册识别自己。地球人可以操纵阿凡达,TiFlash 也可以控制 Proxy 的行为,特别是在 Apply 部分,将在稍后介绍。但 Proxy 是以 Learner 角色加入的 Raft 集群,不参加任何 Raft 的决议,所以即使我们搞砸了,Proxy 并不会像阿凡达一样给 TiKV 集群带来破坏。当然了,Raft Leader 需要往 Proxy Replicate 数据,这本身会造成一些负担。
下面我们来具体介绍 Proxy 的实现。
FFI 机制
TiKV 是用 Rust 实现的,而 TiFlash 是用 C++ 实现的。TiFlash Proxy 对 TiKV 进行改造,并作为一个动态链接库给到 TiFlash。为了实现 zero-overhead 的抽象,我们使用 Rust 的 FFI 实现和 C++ 的相互调用。
使用 FFI 时需要小心处理 safe 和 unsafe code 的边界。例如需要保证共享对象的 layout 是一致的。此外,因为 FFI 机制通过指针进行交流,还需要 Pin 住这些对象,防止 Rust 将其移动。
因此,Proxy 提供了 gen-proxy-ffi 模块来自动化这一过程。C++ 端和 Rust 端共享一个 ProxyFFI.h,任何新增的 FFI 调用只需要在该接口中定义一遍,调用 gen-proxy-ffi 模块即可生成 Rust 端的接口代码。
在接口头文件之外,还有一个 @version 文件,存放接口文件的校验码,当接口文件变动时,@version 文件的内容也会被修改,TiFlash 在加载 Proxy 时,会校验 @version 中的内容,如果内容不一致,说明 proxy 的版本不匹配,程序会退出。
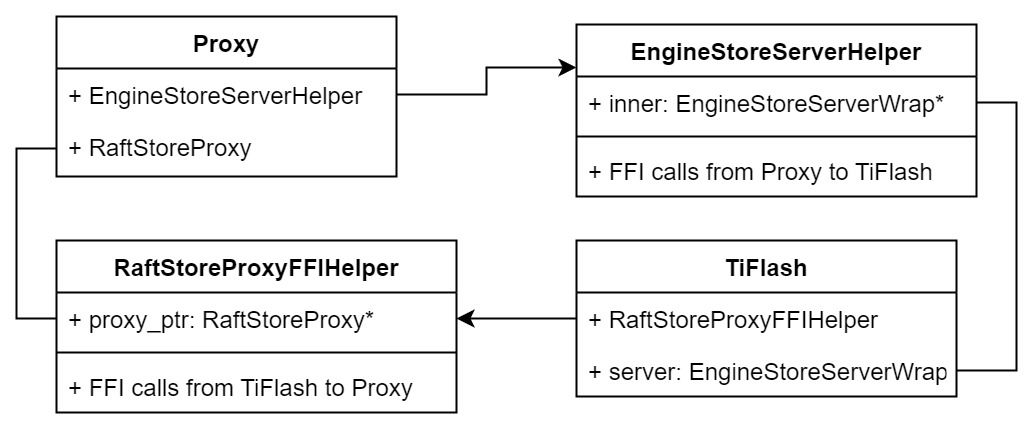
TiFlash 和 Proxy 会各自将 FFI 函数封装入 Helper 对象中,然后再互相持有对方的 Helper 指针。其中 RaftStoreProxyFFIHelper 是 Proxy 给 TiFlash 调用的句柄,它封装了 RaftStoreProxy 对象。TiFlash 通过该句柄可以进行 ReadIndex、解析 SST、获取 Region 相关信息以及 Encryption 等相关工作。EngineStoreServerHelper 是 TiFlash 给 Proxy 调用的句柄,Proxy 通过该句柄可以向 TiFlash 写入数据和 Snapshot、获取 TiFlash 的各种状态等。
这些结构的在 TiFlash 启动时进行初始化,只有当初始化成功后,TiFlash 才会进入正常服务。
添加 TiFlash 副本
下面我们看看,Proxy 是如何和 PD 交互,加入某个 Raft Group,并被注册为对应 Region 的一个特殊的 TiKV peer 的
在执行 ALTER TABLE SET TIFLASH REPLICA 1 后,TiDB 将向 PD 创建一个 id 为 table-{tid}-r 的 Rule,这个 Rule 的作用是告诉 PD 给这个表对应的 key range 添加1个 learner peer。并且设置 label_constraints 为 engine in [“tiflash”] 让这个 rule 只对 TiFlash store 生效。但需要注意的是,我们设置的 key range 会将表中和索引相关的部分过滤掉,这样 PD 不会将 TiKV 自己索引对应的 Region 调度给 TiFlash。
curl http://127.0.0.1:2379/pd/api/v1/config/rules/group/tiflash
[
{
"group_id": "tiflash",
"id": "table-69-r",
"index": 120,
"start_key": "7480000000000000ff455f720000000000fa",
"end_key": "7480000000000000ff4600000000000000f8",
"role": "learner",
"count": 1,
"label_constraints": [
{
"key": "engine",
"op": "in",
"values": [
"tiflash"
]
}
],
"create_timestamp": 1657621816
}
]
在这个 rule 生效后,对应 key range 中的 Region 就可以被调度到 TiFlash 上了。此时会走 replicate peer 逻辑,Pd 只会告知待创建 peer 的 region id 和 peer id,而所有实际的数据将会后续通过 Region Leader 发送的 Snapshot 过来。
而当 Pd 将某个 Region 调度走后,会触发 destroy peer,Proxy 也会将这个消息传递给 TiFlash,通知 TiFlash 将对应的 Region 删除。
需要注意的是,Region 调度应当和数据库的 DDL 区分开来。诸如 DDL 之类的信息,实际上是 TiFlash 通过 TiKV 的 client-c 主动去拉的,并不在 Proxy 的同步范围内。
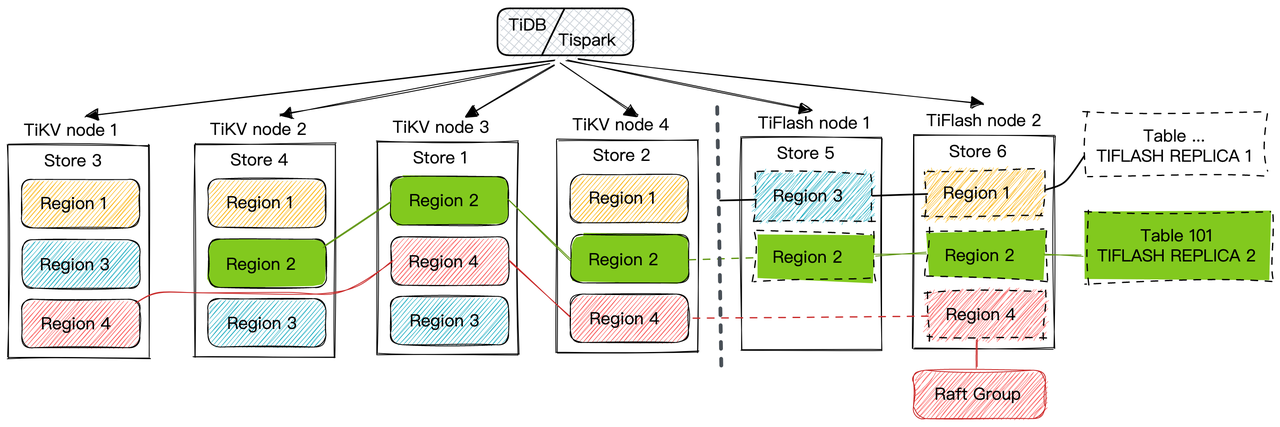
Proxy 的写入
现在 TiFlash 已经通过 Proxy 加入了成为了一个副本,那么每个 Region 的数据都会从 Raft Group Leader 被 replicate 过来。当对应的 log entry 被 commit 后,就会被 ApplyFsm 处理到。下面我们就来看看,Proxy 是如何处理这些传过来的数据的。
TiFlash as a KvEngine
TiKV 的盘上存储主要可以分为四部分,两个 Engine、SnapshotMgr 和 PlaceholderFile。其中 SnapshotMgr 用来管理 Raft Snapshot。PlaceholderFile 用来预留空间做 recovery。
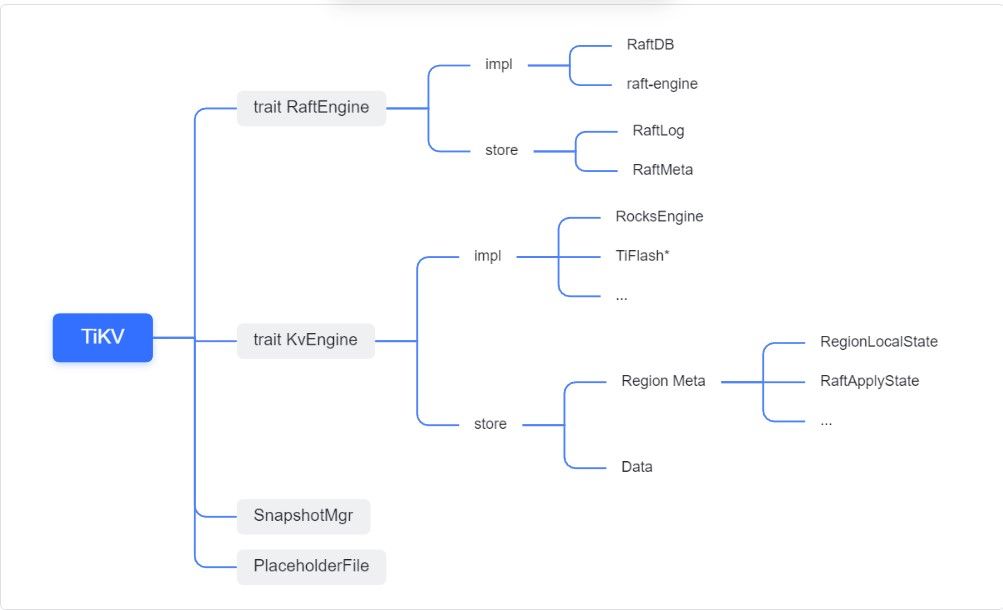
下面来看两个 Engine,它们被抽象为两个 engine trait:KvEngine 和 RaftEngine。
RaftEngine 中存储 RaftLog、以及 RaftLocalState 等和 Raft 算法直接相关的状态,它有基于 RocksDB 的实现 RaftDB 以及我们刚 GA 的组件 raft-engine 的实现。
KvEngine 中目前存储 RegionLocalState、RaftApplyState 这些和 Region 以及 Apply 相关的 meta 信息,以及真实写入的数据。
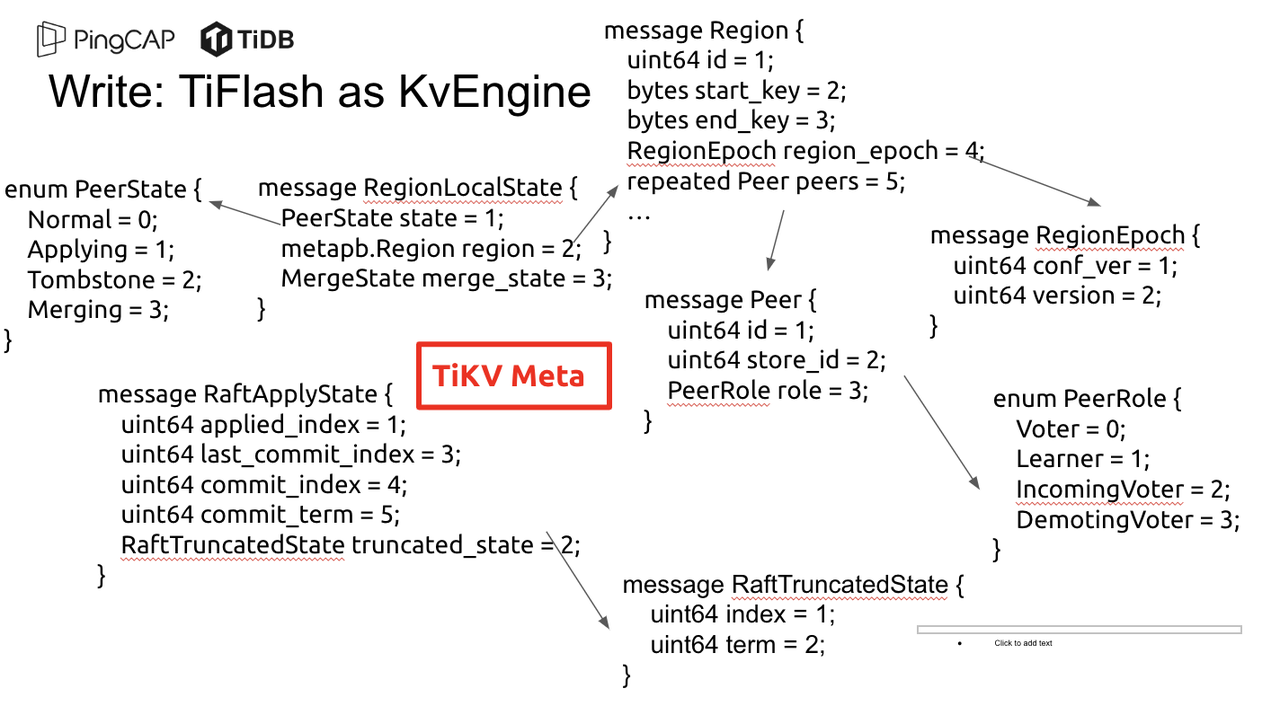
简单介绍一下这些 meta 数据:
1.RegionLocalState 主要包含 Region 的 range、epoch、各个 peer 以及当前 Region 状态,其中
- RegionEpoch 会在 ConfChange,以及 Split 和 Merge 的时候发生变化,在处理 Raft 消息时,我们会校验 RegionEpoch 并拒绝掉过期的消息
- PeerState 状态比如 Normal、Applying、Merging、Tombstone等。
2.RaftApplyState 中包含 apply index、commit index、truncated state 等信息
- apply index 表示当前 apply raft log 的进度。如果 apply raft log 在 persist 前发生宕机,那么重启后就会从较老的 apply index 开始重放日志。所以 apply raftlog 是需要支持幂等的,对于一些特殊的不支持幂等的指令,就需要 apply 完立刻 persist 并 fsync。
- 因为日志不可能无限增长,所以 TiKV 会定期做 CompactLog 来 gc raft log。truncated state 表示上次做完 CompactLog 后现有日志的头部。
通过抽象两个 trait,TiKV 赋予了我们定制存放 RaftLog 和 KV 数据的能力。总体上 TiFlash 可以被看做一个 KvEngine。但是,目前 TiKV 使用单个 RocksDB 实现 KvEngine,即 RocksEngine,并对此做出一些针对性的优化;而 TiFlash 使用 DelteTree 存储列式数据,并且支持多盘部署。在场景上的差异导致我们不能简单把 TiFlash 封装成 KvEngine。
实际上,Proxy 在 KvEngine 的实现中区分了写入。对于 meta 信息,Proxy 保留了 RocksEngine 去存放它们,这样在 Proxy 侧才能正常运行 Fsm。但是对于写入的数据,我们通过之前说的 FFI 接口,将它们传给 TiFlash 处理,Proxy 不会像 TiKV 一样把数据重复写到 RocksEngine 中。因为最终我们读请求,是由 TiFlash 直接 serve,而不会转发给 Proxy 了。所以其实 KvEngine 中只有 meta,没有真实数据。
TiKV Write Pattern
下面简单介绍下 TiKV 的写流程。TiKV 中有两个 BatchSystem,BaftBatchSystem 用来维护 Raft 状态机,它持有 ApplyBatchSystem。ApplyBatchSystem 负责写入被 Commit 的数据。ApplyBatchSystem 由 Poller 驱动,Poller::poll 中有个循环会不停驱动唯一的 control 以及若干的 normal 状态机。一个 normal 状态机实际对应一个 Region,在收到对应消息后,会调用 handle_normal 处理对应的 normal 状态机。具体到每个 normal 状态机中,有一个 WriteBatch 机制。每批的写由 prepare_for 开头,finish_for 结尾,中间伴随着多次 commit,表示 write 到盘上。对于不同的情形,会在 write 完做 fsync 或者不做。
此外,在一轮循环的前后,都会分别调用 PollHandler::begin 和 PollerHandler::end,这里面会包含 write 和 fsync 的逻辑。也就是 BatchSystem 的意思,将一系列副作用落盘。
while True:
let (control_fsm, normal_fsms) = fetch_fsm()
PollHandler::begin()
handle_control()
for normal_fsm in normal_fsms[..max_batch_size]:
// In handle_normal()
normal_fsm.prepare_for()
normal_fsm.commit()
...
normal_fsm.commit()
normal_fsm.finish_for()
PollHandler::end()
Proxy 需要处理的写入
为了详细阐释这个问题,我们先来看看 Proxy 实际要处理什么写入。Proxy 处理的写入主要分为普通的 KV write、Admin Command 以及 IngestSST。这些写入会被存放在内存中,并定时落盘。对于其中已提交的数据,会被写入到列式存储 DeltaTree 中;未提交的部分则由 RegionPersister 负责持久化到 PageStorage 上。
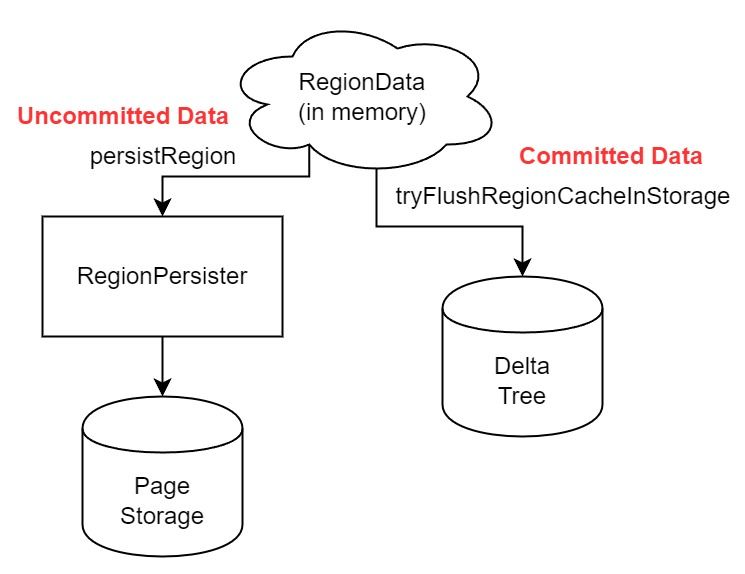
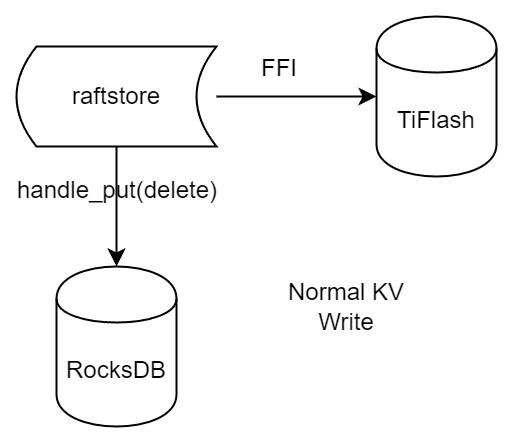
普通的 KV write,就是一组 Put、Delete 和 DeleteRange 命令。对于这样的命令,TiKV 会定期刷盘存入自己的 RocksEngine 中。而 Proxy 直接通过 FFI 将对应的写入传递给 TiFlash,而不会往自己的 RocksEngine 中做任何的写入。
特别地,DeleteRange 命令一般被 TiKV 用来删除表,但因为 TiFlash 自己会维护一份 schema,可以在 drop 时根据 gc safe time 自行删除表,所以 proxy 不需要将 DeleteRange 转发给 TiFlash。
Admin Command 用来维护 Raft 状态机,例如 CompactLog 用来 gc raft log,BatchSplit 用来将一个 Region 分成多个 Region。这些 Admin 通常可能涉及 meta 信息的修改,例如 Apply state。对于这些命令,我们会在 Proxy 端按照 TiKV 的方式执行得到结果,并传递给 TiFlash 侧。TiFlash 侧根据结果来更新自己的 meta 信息。简而言之,就是 Proxy 执行一遍,然后把题目和答案都拿给 TiFlash 抄。好处是,我们不需要在 TiFlash 端再复写一遍处理 Admin 的逻辑了。
特别注意,有一些 Admin Command 我们是无法处理的,需要被 Skip 掉。例如 ComputeHash 和 VerifyHash 被用来校验存储的一致性。但是因为 TiKV 和 TiFlash 使用的底层存储不同,这样的校验是无法被完成的,所以 Proxy 会跳过这些命令的处理。另外诸如 CompactLog 的 Admin Command 有可能被 Skip 掉,这个在下文会详细介绍。
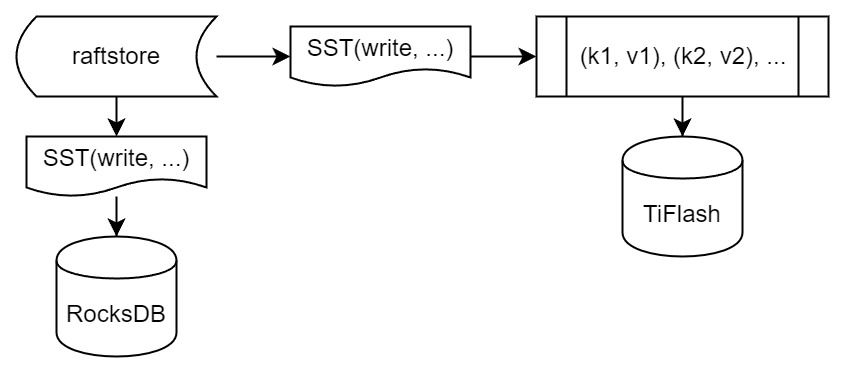
此外,还有一种特殊的写入 IngestSST。IngestSST 是将一系列 SST 文件整体写入,可以将它看做用 SST 承载的 KV write。但实际上 IngestSST 中一般包含 write 列和 default 列。熟悉 percolator 算法的同学应该知道,它们分别对应于 commit 记录和真实数据。因为目前 IngestSST 大多是在 BR/Lightning 导入已提交的数据,所以 lock 列一定是空的。因为 TiKV 的存储引擎是 RocksDB,所以直接把 SST 文件插入到较深的 level 可以取得性能上的优化。但由于 TiFlash 使用 DeltaTree 做列式存储,在处理 IngestSST 时需要读出 KV 对并做行转列,相比 TiKV 的开销还是比较大的。
另外,Apply Snapshot 也可以被视为广义上的写入。一个 Snapshot 实际上也是一系列 SST 组成的,所以在 Apply Snapshot 时同样需要做行转列。但我们不能混淆 IngestSST 和 Apply Snapshot。IngestSST 是一个特殊的写,而 Snapshot 是 Raft 算法中一个和写入平行的概念,当某个 Peer 新被创建,或者 raft 日志落后较多时,Leader 就会发送一个 Snapshot 给它以快速追赶进度。一个 Region peer 在做 Snapshot 的时候,是不能处理写入的。
此外,Proxy 还需要处理一个特殊情况,即 empty entry。根据 TiKV 的实现,如果新 Leader 当选,或者在 TransferLeader 时尝试 ReadIndex,那么会产生一个空的 entry。前者的话,前者的话,根据 Raft 论文,不能 commit 来自较旧term 的日志 entry,所以新 Leader 就需要提交一个 Empty Entry 来推进 commit。后者的话,是新 Leader 上任后需要 propose 一个空 entry 来更新自己的 commit_index 并续约 lease。这个空 entry 中没有任何的写入数据,TiKV 侧可以不做额外处理,但这个空 entry 却需要被转发给 Proxy 用来推进状态机。否则可能后续 wait index 就会超时。
类似的,如果一个命令被执行失败了,我们同样要推进它的 apply index。这里的失败例如在 PrepareMerge 后,epoch 变大了,后续不匹配的 write 会被跳过。但基于同样的原因,我们依然要将被推进的 apply index 传递给 TiFlash 侧。
针对 TiFlash 场景做出的优化
Persistence
下面我们介绍对于 TiFlash 的场景,Proxy 需要对 apply 过程做哪些优化性质的修改。
首先需要注意到,TiKV 对 write 和 fsync 的频率的容忍度是比 TiFlash 高的,这是因为 RocksDB 落盘只需要 sync 一下 WAL 即可。而 TiFlash 存储,比如 DeltaTree,是没有单独的 WAL 的。因为 raftlog 就是 TiFlash 的 WAL。所以 TiFlash 落盘开销大,支持不了 TiKV 这样的频率。
为了减少这样的开销,Proxy 有两方面调整优化。首先,如果 TiKV 的一个 WriteBatch 中只有普通的 kv write,那么在 commit 和 finish_for 时,Proxy 不会将更新后的 Apply State 和数据(其实这些数据也没写到 Proxy 里面)落盘。这样是安全的,如果发生宕机重启,那么会通过 RaftLog 从上次 persist 的 Apply Index 重放。容易看到,这种方案要求 Raft log 不能过早被之前提到的 CompactLog 给 truncate 掉,这就涉及第二个优化。
首先,出于安全性考虑,我们必须在执行 CompactLog 时让 TiFlash 刷一次盘把数据彻底写入,如果出于种种原因,TiFlash 拒绝或者失败,我们就得回滚 CompactLog。这里回滚的意思是,将 truncate state 回滚到之前的状态,不触发 gc 任务,但同样的,apply index 还是要推进的。因为开销大,所以这个刷盘的频率不能太高,并最好由 TiFlash 来控制。因此在执行完 CompactLog 后,FFI 到 TiFlash 端时,我们根据 row、size 和随机的超时时间来决定是否落盘,并最终决定 Proxy 是否回滚。方便起见,我们处理在 TiKV 每次定时的 CompactLog 时进行这样的判断。当然,TiFlash 可以在除 CompactLog 的其他写入 Command 时都返回 Persist,让 Proxy 去 persist apply state,但目前没有这么做。
除了之前讨论的 CompactLog 之外,剩下的大部分 Admin Command,它们基本也都涉及对 meta 信息的修改。对于这些 Command,Proxy 和 TiKV 的处理方式一样,都会让 TiKV 触发一次落盘。
对于普通 kv 写,能够延迟 persist,原因是我们禁止了一部分 CompactLog 去 schedule gc raft log 的任务,但对于 IngestSST 则不然。因为 SST 文件不像 Raftlog 一样通过 CompactLog 来 gc,TiKV 会在每次 commit 之后删除 SST,删除了数据就没了,所以原则上在 IngestSST 之后就立即 Persist。看起来开销很大是吧,所以,Proxy 对于 IngestSST 的写入也有优化。从性能来考虑,我们是可以直接生成 DTFile 到 DeltaTree 中的,从而避免很大的 default 列中的真实数据以 Region 形式存到 RegionPersister 中。但由于在某些时候,IngestSST 的 write 列或者 default 列不能完全 match,所以我们只能 flush 一部分到 DeltaTree 中,而将某些多出来的数据先存留在内存中。为了让这一部分数据 recoverable,我们会延迟 SST 文件的删除,直到我们确定 SST 中所有的数据已经持久化了。
Proxy 将 normal write 和 admin command 的两种写入抽象为了 fn_handle_write_raft_cmd 和 fn_handle_admin_raft_cmd 两个 FFI。它们会返回一个枚举,分别为 None、Persist 和 NotFound。一个 None 的返回值,说明 TiFlash 不希望将数据和 meta 信息立即落盘;一个 Persist 的返回值则相反。另外的 NotFound 返回值表示 Region 没有找到。我们有其他的 FFI 处理 IngestSST 等,在这里就不介绍了。
Apply Snapshot
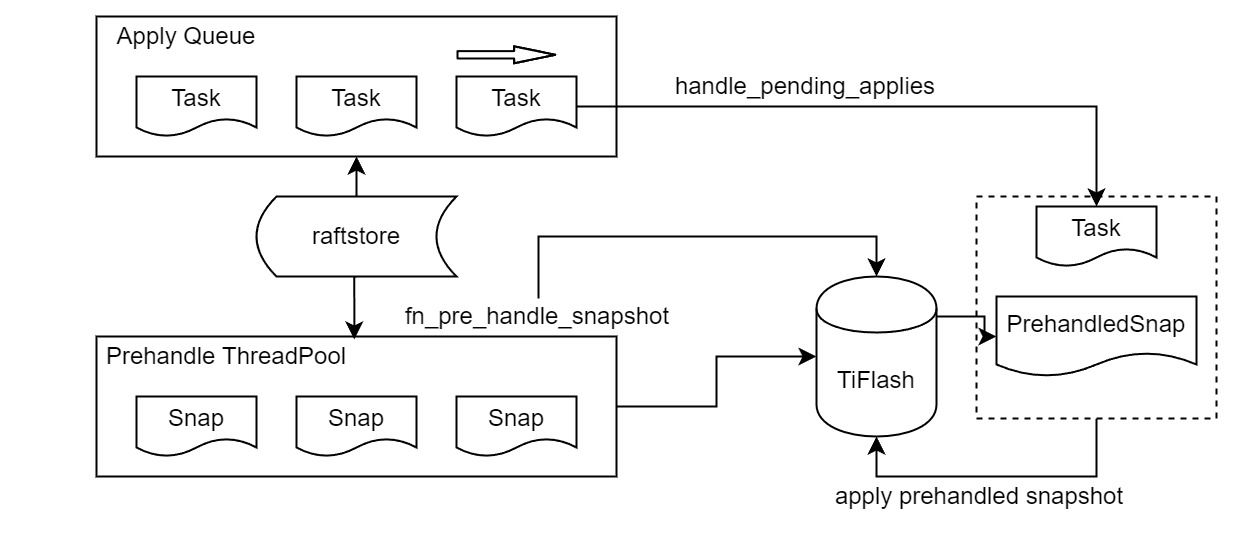
对于 Apply Snapshot,TiKV 可以在 apply 的时候直接将收到的 sst 文件 ingest 到自己的 RocksDB 中。但因为 TiFlash 并不用 RocksDB,而是有自己的列式存储,所以会有一个比较耗时的行转列过程。TiKV 是将收到的 Apply Task 放到一个专门的 Apply Queue 中,并用一个单独的 RegionRunner 线程中串行地 Apply Snapshot,如果将行转列放在这个过程中,会极大降低效率。因此,Proxy 为 Apply Snapshot 过程引入一个 Pre-handle 步骤。在收到 Pending 的 Snapshot 后,会进入该步骤中,将 Snapshot 加入一个线程池中并发地进行行转列。
在 Apply Queue 处理到 Snapshot 时,会去 retrieve pre handle 的结果。所以如果 pre handle 没有结束, apply snapshot 依然会被 block。但因为我们使用了线程池并发处理多个 snapshot 的 pre-handle,所以减少了等待的时间,
Apply Snapshot 过程也是一个 FFI 传递给 TiFlash,这个过程就是主要调用 checkAndApplySnapshot 函数进行校验、落盘以及修改 meta。
同理,对于 IngestSST 写,也可以有类似的优化。但其实 TiKV 中已经有一个 low-priority pool 了,所以 Proxy 并没有对这一块做更改。
Proxy 的后续发展
目前,Proxy 主要是 fork 的 TiKV 并修改产生的,这导致我们不太容易 Follow TiKV 的最新特性。因此,我们目前正在打算基于 TiKV 的 engine traits 和 Observer 机制做一个新的 Proxy。这样能够摆脱对 TiKV 源码级的依赖。
在这之后,Proxy 更可以被看做是一个 TiKV 上支持异构 KvEngine 的框架,由此可以产生很多有趣的 idea。我们欢迎大家来基于该框架来继续碰撞出新的火花。
问题回复
1.为什么在 TiFlash 侧也有 Region、以及对应的 ApplyState 等状态信息,不能复用 Proxy 中的么?
- 这实际上是个历史的设计问题。首先 Proxy 通过 FFI replicate 过来的信息已经足以维护 TiFlash 侧的 apply 状态了。Proxy 侧对状态的修改,通过 None/Persist 就可以维护。
- 如果我们不再 TiFlash 侧维护一份,那么就需要频繁读和写 Proxy 侧的 Apply 信息,这会产生较多的 FFI 调用,以及可能的编解码的工作
2.TiFlash Proxy 是否可以被静态链接到 TiFlash 中呢
- 由于 Proxy 和 TiFlash 使用不同的 OpenSSL 的实现,而 Rust 又很喜欢打包自己的依赖,这可能在链接期产生重复符号的问题。
- 但我们也有尝试一些方案,例如 rename 掉 Proxy 中的符号,目前来看是可行的
3.TiFlash Proxy 如何 pick TiKV 的新特性和 bugfix
- 目前 Proxy fork 了 TiKV,所以是源码级的依赖。跟进 TiKV 的大版本主要靠 merge release。此外,对于一些 critical 的 bugfix,我们会从 TiKV 做 cherry pick
- 但这样的管理非常麻烦,并且也难以追上 TiKV 的更新。
-
Java中定时任务实现方式及源码剖析11-24
-
Java中定时任务实现方式及源码剖析11-24
-
鸿蒙原生开发手记:03-元服务开发全流程(开发元服务,只需要看这一篇文章)11-24
-
细说敏捷:敏捷四会之每日站会11-24
-
Springboot应用的多环境打包入门11-23
-
Springboot应用的生产发布入门教程11-23
-
Python编程入门指南11-23
-
Java创业入门:从零开始的编程之旅11-23
-
Java创业入门:新手必读的Java编程与创业指南11-23
-
Java对接阿里云智能语音服务入门详解11-23
-
Java对接阿里云智能语音服务入门教程11-23
-
JAVA对接阿里云智能语音服务入门教程11-23
-
Java副业入门:初学者的简单教程11-23
-
JAVA副业入门:初学者的实战指南11-23
-
JAVA项目部署入门:新手必读指南11-23
