PostgreSQL教程
京东云PostgreSQL在GIS场景的应用分享

在地图或地理信息有关的场景里,地址关键词的检索尤其重要。比如打开百度地图,想要查询某个位置的信息“北京市海淀区清华东路17号中国农业大学”,往往我们输入的是关键词“中国农业大学”而不是精确到街道的详细地址信息。在地址关键词检索的背后,需要的是一款可以支持全文检索和模糊查询的数据库与之匹配,以此快速提高地址检索的效率。
PostgreSQL被誉为“世界上可获得的最先进的开源数据库 ”,拥有很强的文本搜索能力,不仅支持全文检索,PostgreSQL还支持模糊查询、正则查询。除此之外,PostgreSQL还内置了表达式索引、Gin索引功能,配合丰富的插件生态,在地址关键词检索方向有比较大的优势。
本文介绍了一种基于PostgreSQL物流地址关键词检索的方法,以此来说明如何用PostgreSQL提升物流地址关键词的检索效率。
一、应用背景
在需要地址检索的场景中,用户输入地址文本后需要对地址进行分词,然后通过全文索引技术与地址语料数据库进行匹配,得到规范化的地址信息,并在此基础上进行地址定位。通常地址查询语句在经过地址分词处理后会被分割成几段关键词,通过关键词匹配到历史地址语料数据库,再返回查询语句得到查询结果。通常从用户输入关键词查询到得到返回结果由于关键词分词和匹配方法不同,会耗时几秒到几十秒不等。
检索数据库中的条目是很基本常见的功能,实现的方法也很多,常见包括:
1、基于Elasticsearch 或 Lucene这类专业独立的检索引擎实现
2、基于数据库自带的检索功能实现
虽然基于Elasticsearch这类系统能实现比较灵活的检索功能,但开发和运维成本也将大大增加,如何利用PostgresSQL内置的功能快速高效的实现大多数中文检索场景是我们要讨论的技术方案。
二、技术方案
GIN(Generalized Inverted Index, 通用倒排索引) 是一个存储对(key, posting list)集合的索引结构,其中key是一个键值,而posting list 是一组出现过key的位置。如('hello', '14:2 23:4')中,表示hello在14:2和23:4这两个位置出现过,在PostgreSQL中这些位置实际上就是元组的tid。表中的每一个属性在建立索引时,都可能会被解析为多个键值,所以同一个元组的tid可能会出现在多个key的posting list中。通过这种索引结构可以快速的查找到包含指定关键字的元组。pg_trgm是PostgreSQL基于N-gram模型分词的扩展插件,它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列,pg_trgm就是三元的3-Gram,每连续的3个字符为一个TOKEN,然后在对TOKEN建立GIN倒排索引,就可以进行高效、精准的模糊查询。
pgbigm与pg_trgm类似,也是PostgreSQL基于N-gram模型分词的扩展插件,区别在于pgbigm是二元的2-Gram。
结合PostgreSQL 索引和分词模型的特点,我们构建了1亿行左右的北京区域的本文地址数据进行性能测试,对比分析PostgreSQL在物流关键词检索的场景里有明显效率的提升,测试结果如下:
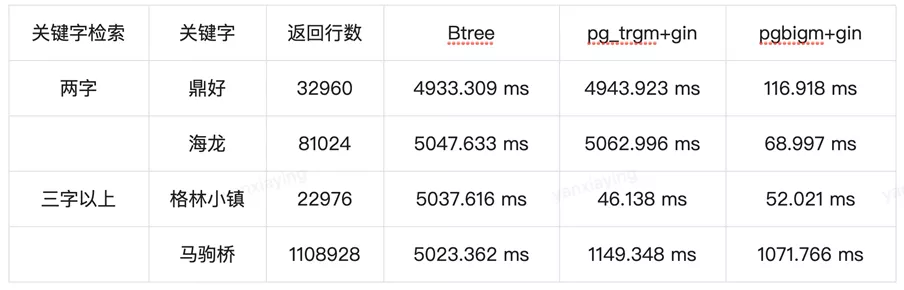
从以上结果可以看出,无论是pg_trgm+gin还是pgbigm+gin性能比常用的Btree在进行模糊查询的时候,性能要好很多。同时,因为pg_trgm生成的TOKEN是三个字符,只有在三个字符以上条件,才能匹配到对应的TOKEN,当小于3个字符,需要前后模糊搜索1个或者2个字符,所以检索性能下降比较明显,相比来说pgbigm(基于二元的Tri-Gram)在处理单字、双字字符的模糊查询效率都比较高。由于物流的关键字都是三个字符以上,所以采用的是pg_trgm+gin的方案进行关键词检索查询,从而保证毫秒级别的响应时间。
另外对于文本地址数据,往往都具备自然语言的特性,jieba结巴分词是一个强大的分词库,分词更加贴合业务属性特点,主要功能包含:支持不同模式的分词、自定义字典、关键字提取、词性标注。pg_jieba运用了jieba分词算法,构建了PostgreSQL中文分词插件,分词效果也有不错的表现。
三、总结
综上,PostgreSQL支持丰富的索引,具备强大的全文检索能力以及多样的插件生态,支持不同场景下的文本查询,用户完全不需要将数据同步到搜索引擎,再来查询,使用PostgreSQL可以大幅度的简化用户的架构,开发成本,同时保证数据查询的绝对实时性。京东云基于开源的 PostgreSQL构建的一款功能强大的关系型数据库云数据库 PostgreSQL ,支持丰富的数据类型及地理信息扩展,具有强大的并行计算能力。支持备份、监控、迁移等全套解决方案。
作者:曲艺伟/彭智
-
快速清空 PostgreSQL 数据库中的所有表格,让你的数据库重新焕然一新!01-05
-
在PostgreSQL中创建角色:判断角色是否存在并创建01-04
-
PostgreSQL一站式插件推荐 -- pg_enterprise_views05-16
-
PostgreSQL 实时位置跟踪11-22
-
如何将PostgreSQL插件移植到openGauss11-22
-
PostgreSQL:修改数据库用户的密码11-11
-
Windows 环境搭建 PostgreSQL 物理复制高可用架构数据库服务11-06
-
Windows 环境搭建 PostgreSQL 逻辑复制高可用架构数据库服务10-27
-
PostgreSql安装(Windows10版本)10-11
-
PostgreSQL-Network Address类型操作和函数09-13
-
PostgreSQL-运算符和函数309-11
-
PostgreSQL-数据类型309-08
-
postGIS+postgreSQL+Supermap部署GIS数据09-06
-
PostgreSQL-系统列09-04
-
PostgreSQL-插入09-04
