Java教程
隐私计算FATE-离线预测


一、说明
Fate 的模型预测有 离线预测 和 在线预测 两种方式,两者的效果是一样的,主要是使用方式、适用场景、高可用、性能等方面有很大差别;本文分享使用 Fate 基于 纵向逻辑回归 算法训练出来的模型进行离线预测实践。
- 基于上文 《隐私计算FATE-模型训练》 中训练出来的模型进行预测任务
- 关于 Fate 的基础概览和安装部署可参考文章 《隐私计算FATE-关键概念与单机部署指南》
二、查询模型信息
执行以下命令,进入 Fate 的容器中:
docker exec -it $(docker ps -aqf "name=standalone_fate") bash
首先我们需要获取模型对应的 model_id 和 model_version 信息,可以通过 job_id 执行以下命令获取:
flow job config -j 202205070226373055640 -r guest -p 9999 --output-path /data/projects/fate/examples/my_test/
job_id 可以在 FATE Board 中查看。
执行成功后会返回对应的模型信息,以及在指定目录下生成一个文件夹 job_202205070226373055640_config
{
"data": {
"job_id": "202205070226373055640",
"model_info": {
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "202205070226373055640"
},
"train_runtime_conf": {}
},
"retcode": 0,
"retmsg": "download successfully, please check /data/projects/fate/examples/my_test/job_202205070226373055640_config directory",
"directory": "/data/projects/fate/examples/my_test/job_202205070226373055640_config"
}
job_202205070226373055640_config 里面包含4个文件:
- dsl.json:任务的 dsl 配置。
- model_info.json:模型信息。
- runtime_conf.json:任务的运行配置。
- train_runtime_conf.json:空。
三、模型部署
执行以下命令:
flow model deploy --model-id arbiter-10000#guest-9999#host-10000#model --model-version 202205070226373055640
分别通过 --model-id 与 --model-version 指定上面步骤查询到的 model_id 和 model_version
部署成功后返回:
{
"data": {
"arbiter": {
"10000": 0
},
"detail": {
"arbiter": {
"10000": {
"retcode": 0,
"retmsg": "deploy model of role arbiter 10000 success"
}
},
"guest": {
"9999": {
"retcode": 0,
"retmsg": "deploy model of role guest 9999 success"
}
},
"host": {
"10000": {
"retcode": 0,
"retmsg": "deploy model of role host 10000 success"
}
}
},
"guest": {
"9999": 0
},
"host": {
"10000": 0
},
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "202205070730131040240"
},
"retcode": 0,
"retmsg": "success"
}
部署成功后返回一个新的 model_version
四、准备预测配置
执行以下命令:
cp /data/projects/fate/examples/dsl/v2/hetero_logistic_regression/hetero_lr_normal_predict_conf.json /data/projects/fate/examples/my_test/
直接把 Fate 自带的纵向逻辑回归算法预测配置样例,复制到我们的
my_test目录下。
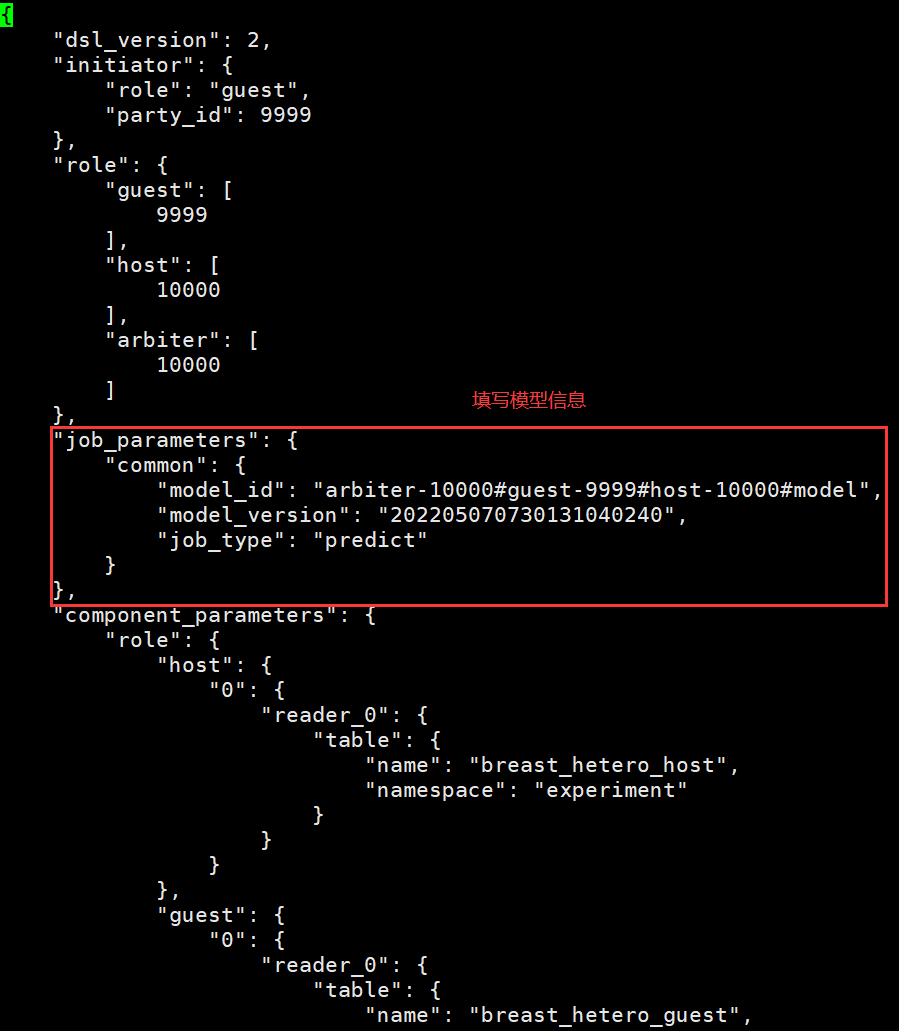
预测的配置文件主要配置三部分:
- 上面部分为配置发起者以及参与方角色
- 中间部分需要填入正确的 模型信息
- 下面的则为预测使用的数据表
唯一需要修改的就是中间的 模型信息 部分;需要注意的是这里输入的版本号是 模型部署 后返回的版本号,并且需要增加 job_type 为 predict 指定任务类型为预测任务。
五、执行预测任务
执行以下命令:
flow job submit -c hetero_lr_normal_predict_conf.json
与模型训练一样也是使用 submit 命令,通过 -c 指定配置文件。
执行成功后返回:
{
"data": {
"board_url": "http://127.0.0.1:8080/index.html#/dashboard?job_id=202205070731385067720&role=guest&party_id=9999",
"code": 0,
"dsl_path": "/data/projects/fate/fateflow/jobs/202205070731385067720/job_dsl.json",
"job_id": "202205070731385067720",
"logs_directory": "/data/projects/fate/fateflow/logs/202205070731385067720",
"message": "success",
"model_info": {
"model_id": "arbiter-10000#guest-9999#host-10000#model",
"model_version": "202205070730131040240"
},
"pipeline_dsl_path": "/data/projects/fate/fateflow/jobs/202205070731385067720/pipeline_dsl.json",
"runtime_conf_on_party_path": "/data/projects/fate/fateflow/jobs/202205070731385067720/guest/9999/job_runtime_on_party_conf.json",
"runtime_conf_path": "/data/projects/fate/fateflow/jobs/202205070731385067720/job_runtime_conf.json",
"train_runtime_conf_path": "/data/projects/fate/fateflow/jobs/202205070731385067720/train_runtime_conf.json"
},
"jobId": "202205070731385067720",
"retcode": 0,
"retmsg": "success"
}
六、查看预测结果
可以通过返回的 board_url 或者 job_id 去 FATE Board 里查看结果,但是图形化界面里最多只能查看 100 条记录;
我们可以通过 output-data 命令,导出指定组件的所有数据输出:
flow tracking output-data -j 202205070731385067720 -r guest -p 9999 -cpn hetero_lr_0 -o /data/projects/fate/examples/my_test/predict
- -j:指定预测任务的 job_id
- -cpn:指定组件名。
- -o:指定输出的目录。
执行成功后返回:
{
"retcode": 0,
"directory": "/data/projects/fate/examples/my_test/predict/job_202205070731385067720_hetero_lr_0_guest_9999_output_data",
"retmsg": "Download successfully, please check /data/projects/fate/examples/my_test/predict/job_202205070731385067720_hetero_lr_0_guest_9999_output_data directory"
}
在目录 /data/projects/fate/examples/my_test/predict/job_202205070731385067720_hetero_lr_0_guest_9999_output_data 中可以看到两个文件:
- data.csv:为输出的所有数据。
- data.meta:为数据的列头。
-
[开源]10.3K+ Star!轻量强大的开源运维平台,超赞!11-22
-
Flutter基础教程:新手入门指南11-21
-
Flutter跨平台教程:新手入门详解11-21
-
Flutter跨平台教程:新手入门与实践指南11-21
-
Flutter列表组件教程:初学者指南11-21
-
Flutter列表组件教程:新手入门指南11-21
-
Flutter入门教程:初学者必看指南11-21
-
Flutter入门教程:从零开始的Flutter开发指南11-21
-
Flutter升级教程:新手必读的升级指南11-21
-
Flutter升级教程:轻松掌握Flutter版本更新11-21
-
Flutter适配教程:轻松掌握屏幕适配技巧11-21
-
Flutter数据存储教程:入门级详解与实战11-21
-
Flutter数据存储教程:轻松入门数据存储11-21
-
Flutter网络编程教程:新手入门必读11-21
-
Flutter网络编程教程:新手入门指南11-21
