C/C++教程
TiFlash 函数下推必知必会丨十分钟成为 TiFlash Contributor

作者: 黄海升,TiFlash 研发工程师
TiFlash 自[开源]以来得到了社区的广泛关注,很多小伙伴通过[源码阅读的活动]学习 TiFlash 背后的设计原理,也有许多小伙伴跃跃欲试,希望能参与到 TiFlash 的贡献中来。这次,我们特别筛选了 TiFlash 中一些入门级别的 issue,帮助大家无门槛地参与到大型开源项目中来。
Issue 列表:https://github.com/pingcap/tiflash/issues/5092
按照惯例,我们也给 TiFlash New Contributor 准备了限量马克杯,获取流程见文末。
背景知识
TiFlash 作为 TiDB HTAP 体系的重要一环,会接收并执行 TiDB 下推下来的算子。而有时 Projection, Selection 等等算子里会带有函数,这就意味要下推这些算子就必须支持在 TiFlash 里执行算子包含的函数。
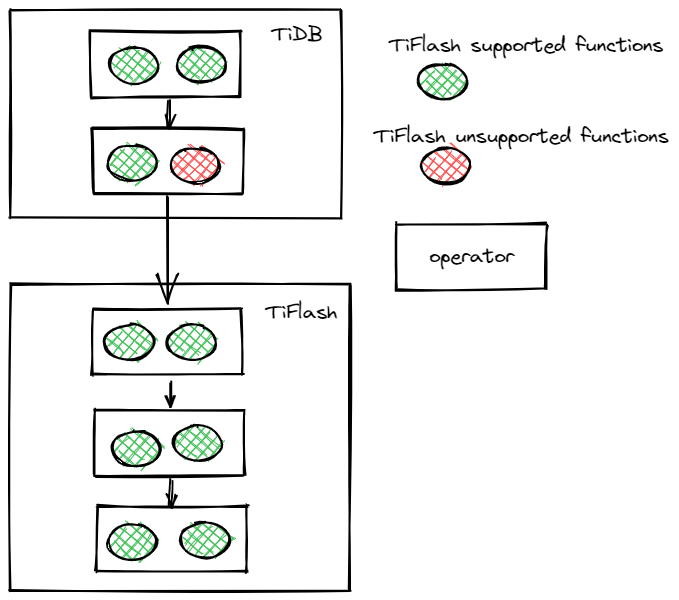
如上图所示,如果某个算子带有 TiFlash 不支持的函数,就会导致一连串的算子都无法下推到 TiFlash 里执行。为了最大化地发挥 TiFlash MPP 并行计算的能力,我们需要让 TiFlash 支持 TiDB 的所有函数。看似无关紧要的函数支持,却是 TiDB HTAP 的重要一环!
手把手教你下推函数
1. 确认要下推的函数的行为
函数是由 TiDB 下推给 TiFlash 执行的,所以必须保证函数在 TiFlash 执行的逻辑和 TiDB 保持一致,包括:
- 主要逻辑
- 返回值类型
- 异常处理
- etc
以返回值类型为例,sqrt在 TiDB 一定会返回 float64,即便参数是Decimal类型的,也会在函数内部对参数先evalReal;而 floor、ceil 则会根据参数的类型和大小决定返回值是普通的整型,还是Decimal 类型。
一般情况下,TiFlash 要与 TiDB 保持一致是比较简单的。但是对于一些特别的输入,在实现的时候需要特别关注,如 sqrt 一个负数,是返回 NaN,还是返回 Null,还是抛出异常呢?
所以在实际开发之前,要去好好地看一下 TiDB 是如何实现这个函数的。
2. 将 TiDB function 映射到 TiFlash function
TiDB 对函数的标识是 tipb::ScalarFuncSig,而 TiFlash 使用 func_name 作为函数的标识。
在 TiFlash 的代码里,我们会用映射表的形式将 tipb::ScalarFuncSig 映射成 func_name。
所以下推新函数的第二步,是给你要下推的函数,在 TiFlash 起个 func_name,然后在对应的映射表里加一个 tipb::ScalarFuncSig 到 func_name 的映射。
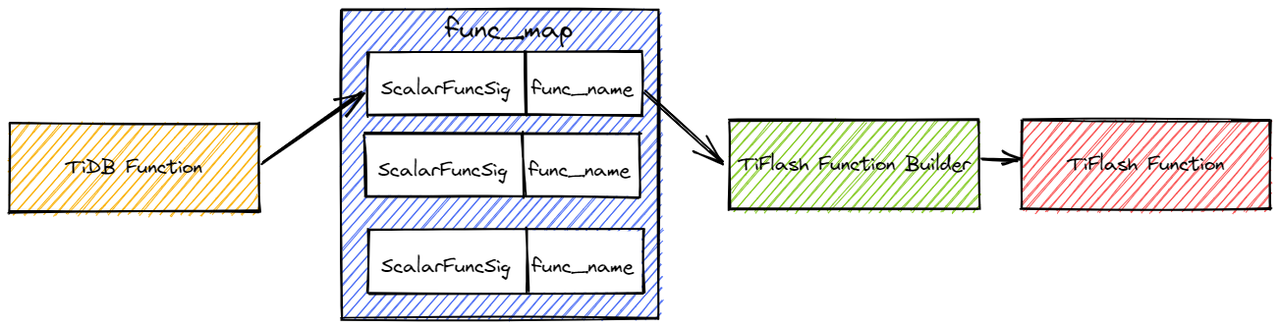
通常 SQL 函数会分为 window function,aggregate function,distinct aggregation function 和 scalar function。在 TiFlash 侧会为每一类函数维护一个映射表,映射表和函数的对应如下:
window_func_map- 用于 window function
agg_func_map- 用于普通的聚合函数
distinct_agg_func_map- 用于 distinct 的聚合函数
scalar_func_map- 用于一般的标量函数
3. 注册 TiFlash 函数
在映射了 tipb::ScalarFuncSig 到 func_name 后,TiDB 下推的函数会根据 func_name 找到 TiFlash 函数对应的 builder,build 出 TiFlash Function 后,由 TiFlash Function 在实际执行流中执行函数逻辑。
目前在 TiFlash 有两种 Function Builder 的实现方法,一种是 reuse function,一种是 create function directly。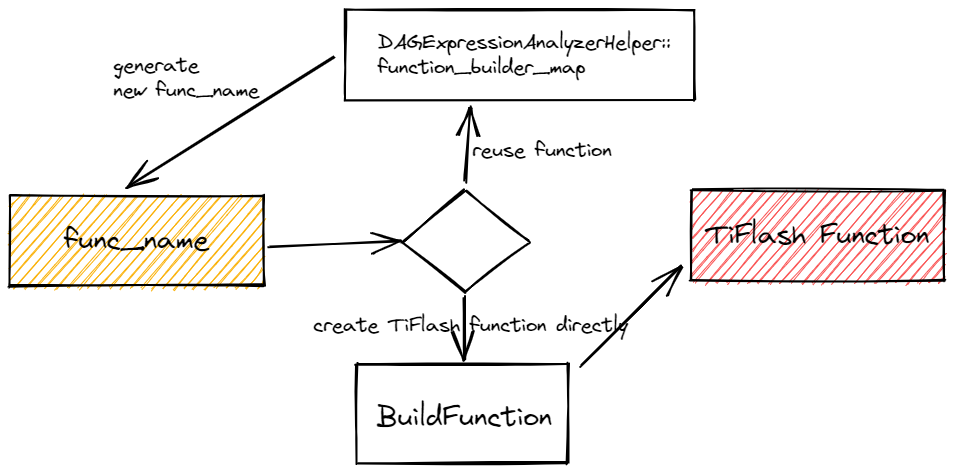
reuse function
reuse function 用于可以复用其他函数的情况。比如 ifNull(arg1, arg2) -> if(isNull(arg1), arg2, arg1),如果自己直接写一个 ifNull 的实现就会相当耗费时间,通过这种方式就可以直接复用其他函数的逻辑。
在 TiFlash 中是用 DAGExpressionAnalyzerHelper::function_builder_map 来记录哪些是复用函数以及如何复用的逻辑。
添加一个对应的 DAGExpressionAnalyzerHelper::FunctionBuilder,在 DAGExpressionAnalyzerHelper::function_builder_map 添加对应的映射 <func_name, FunctionBuilder>。
具体的实现可以参考 DAGExpressionAnalyzerHelper 里其他 FunctionBuilder 的实现。
create function directly
create function directly 用于不能复用其他函数的情况。需要在 dbms/src/Functions 下面写对应的函数实现代码。通常会有一定的分类,比如 String 相关的会在 FunctionString 里面。
然后调用 factory.registerFunction 将函数实现类注册在到 FunctionFactory 即可。factory.registerFunction 通常都会放在一起,简单找找即可。
4. TiFlash 侧开发函数
接下来要进行 TiFlash 侧函数主体的开发。如果不能复用 TiFlash 已经开发好的函数,那我们就得继承 IFunction 接口开发一个函数。不过好在 clickhouse 本身已经有很多现成的函数,不过因为不一定与 TiDB/MySQL 兼容,我们不能直接使用,所以留在了 Functions 下面,以待后来者利用。
所以当真的需要继承 IFunction 实现一个函数时,可以先检索 Functions 下面有没有现成的语意相同的 clickhouse 函数,在那个函数上修修改改,满足与 TiDB/Mysql 的兼容性后,纳入 TiFlash Function 体系里。
如果不巧,没有现成的 clickhouse 函数利用,那就得从 0 开始开发一个向量化函数,不过也不必担忧,虽然向量化函数开发相对困难一点,但是还是可以从别的函数上找到一些脉络,模仿一些开发范式。
TiFlash vs. TiDB
TiFlash 和 TiDB 的向量化函数实现上存在不同点,参与过 TiDB 贡献的 Contributor 需要关注下:
- C++ 与 Golang 的区别
- TiFlash 里重度使用 C++ 模板去写函数,尤其是涉及数据类型的代码;
- TiFlash 的向量化函数体系和 TiDB 的函数体系(行式/向量化)的不同
- 表达式相关类的设计、使用与TiDB 差别很大
IDataTypeIColumn
- 参数的 Column 类型(vector 和 const)组合会爆炸式增长。比如两个参数的 function 会有四种组合
- vector, const
- vector, vector
- const, vector
- const, const
- 表达式相关类的设计、使用与TiDB 差别很大
以上两点让 TiFlash 的函数开发有一定的难度,和 TiDB 的函数开发差别会相当大。可以参考下 Function 目录下其他函数的实现,比如 FunctionSubStringIndex。在开发函数的时候大家应该会有很多体会 :)
可以参考的函数实现
- TiDBConcat
- FunctionSubStringIndex
- Format
5. TiDB 侧下推函数
下推函数是从 TiDB 侧发起的,所以 TiDB 也要做一些修改,让函数下推。在 expression/expression.go 里的 scalarExprSupportedByFlash 会判断哪些函数可以被下推到 TiFlash 里执行,TiDB planner 会根据 scalarExprSupportedByFlash 来决定算子是否可以下推到 TiFlash。
比如要下推 sqrt 函数到 tiflash,在 tidb 的 expression/expression.go 中找到函数 scalarExprSupportedByFlash,会发现所有可以下推的函数的名字都被 hard-code 进了各种 switch case,将需要下推的函数 aqrt 加进 switch case 中即可。
6. 验证函数真的下推了
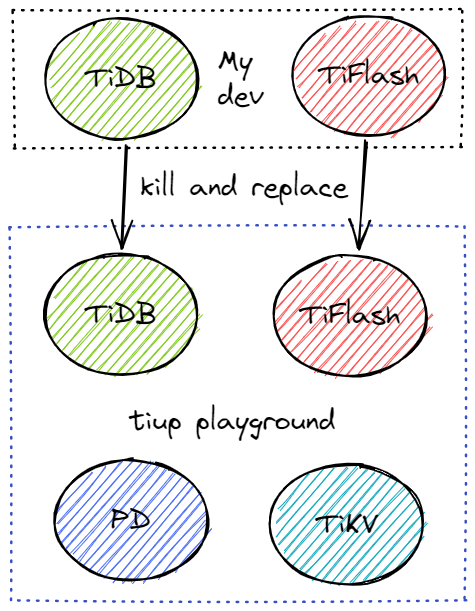
在 TiDB 和 TiFlash 侧的开发都完成后,我们需要先在本地验证一下整个下推流程是不是真的 work 了。
- 首先我们需要现在本地启动一个 TiDB,TiKV,TiFlash 和 PD 的集群。这里推荐用 TiUP,按照 官方文档 安装 TiUP,用 playground 启动即可。
比如: tiup playground nightly --tiflash 1 --db 1 --pd 1 --kv 1
- 然后用自己 build 好的 TiDB 和 TiFlash 替换掉原有集群的 TiDB 和 TiFlash
- TiFlash
执行 ps -ef | grep tiflash,找到 tiflash 进程,形式应该像这样:
xzx 11238 11028 52 20:20 pts/0 00:00:05 /home/xzx/.tiup/components/tiflash/v5.0.0-nightly-20210706/tiflash/tiflash server --config-file=/home/xzx/.tiup/data/ScRdWJM/tiflash-0/tiflash.toml
记下进程号 11238,记下 tiflash 后面跟的参数 server --config-file=/home/xzx/.tiup/data/ScRdWJM/tiflash-0/tiflash.toml。
然后 kill 11238,用 server --config-file=/home/xzx/.tiup/data/ScRdWJM/tiflash-0/tiflash.toml 启动自己 build 好的 TiFlash。
- TiDB
与 TiFlash 类似,找到 tiup TiDB 进程,kill 掉原进程,用对应参数启动 TiDB 替换即可。
- 验证下推流程
用类似 explain select sum(sqrt(x)) from test 的查询来看函数是否被下推到 tiflash 计算。
创建 tiflash 副本:
create table test.t (xxx); -- 因为通常本地起一个节点, 所以 tiflash 副本数只能设 1 alter table test.t set tiflash replica 1;
测试的 SQL 可以像这样:
-- 尽量使用 MPP set tidb_enforce_mpp=1; -- 强制只能走 TiFlash set tidb_isolation_read_engines='tiflash'; explain select xxxfunc(a) from t;
如果函数被下推到了 TiFlash,那 explain 的结果可以看到包含该函数的 Projection 算子在 TiFlash 侧。explain sql 可以反复执行多几次,因为 TiFlash 副本建立需要一些时间,但是不会太长。如果很长一段时间都看不到函数下推了,那么应该就是真的有问题。:)
explain sql 执行成功之后,可以把 explain 去掉,实际执行下 sql 看效果。
7. 测试
提交 pr 后,在 TiFlash 的 GitHub CI 里,会启动实际的 TiDB, TiFlash, PD, TiKV 集群,自动执行单元测试和集成测试。需要贡献者提前准备测试的代码。
集成测试
对于函数下推,通常会在 integration-test 增加一组测试。在 tests/fullstack-test/expr 下面,为新的下推函数建一个 func.test,测试内容参照同目录下其他函数的测试即可,如 substring_index.test。
单元测试
形式
TiFlash 的函数单测放在 dbms/src/Functions/test 下面。通常命名格式为 gtest_${func_name}.cpp。
单测模板如下:
#include <TestUtils/FunctionTestUtils.h>
#include <TestUtils/TiFlashTestBasic.h>
namespace DB::tests
{
class {gtest_name} : public DB::tests::FunctionTest
{
};
TEST_F({gtest_name}, {gtest_unit_name})
try
{
const String & func_name = {function_name};
// case1
ASSERT_COLUMN_EQ(
{ouput_result},
executeFunction(
func_name,
{input_1},
{input_2},
...,
{input_n},);
// case2
...
// case3
...
}
CATCH
TEST_F({gtest_name}, {gtest_unit_name2})...
TEST_F({gtest_name}, {gtest_unit_name3})...
...
} // namespace DB::tests
可以参考该目录下其他函数单测的写法, 做适当调整。
FunctionTestUtils 是用于函数测试的公共类,里面提供了各类常用的方法,如 createColumn 等等。如果在写 gtest 时发现有其他可以共用方法,也可以补充在这里。
内容
以 function(arg_1, arg_2, arg_3, … arg_n) 为例,一个 TiFlash 函数单元测试的内容应该至少包含以下几个部分:
数据类型
对于每个 arg_i 的所有支持类型 Type,需要测试 Type 与 Nullable(Type)。此外理论上所有 arg_i 都应该支持 DataTypeNullable(DataTypeNothing),但是 TiDB 很少会用到 DataTypeNullable(DataTypeNothing),所以碰到相关的 bug 可以先记下来。
列类型
对于 arg_i 的每种 Type:
- 如果该 Type 不为 nullable,需要测试两种形式的列:
- ColumnVector
- ColumnConst
- 如果该 Type 为 nullable,需要测试三种形式的列:
- ColumnVector
- ColumnConst(ColumnNullable(non-null value))
- ColumnConst(ColumnNullable(null value))
- 如果该 Type 为 DataTypeNullable(DataTypeNothing), 需要测试两种形式的列:
- ColumnVector
- ColumnConst(ColumnNullable(null value))
边界值
一些通用的边界值例子如下:
- 数值类型(int,double,decimal 等):最大/最小值,0 值,null 值
- 字符串类型:空字符串,中文等非 ascii 字符,null 值,有 collation/无 collation
- 日期类型:zero date,早于 1970-01-01 的某个时间,夏令时时间,null 值
此外,对于具体的函数,可以根据其具体实现,有针对性地构造边界值。
返回值类型
根据 MySQL 相关文档,确保 TiFlash 函数返回值类型与 MySQL/TiDB 一致
注意:
- Decimal 类型在 TiFlash 的内部表示有四种:Decimal32,Decimal64,Decimal128 和 Decimal256,对于所有 Decimal 类型,这四种内部表示都需要测试到。
- 函数的每个 arg_i 可能的类型实际上应该以 TiDB 可能下推的类型为准,考虑到获取 TiDB 可能下推的类型比较麻烦,当前测试可以根据 TiFlash 目前支持的类型来写
- 有一部分 TiDB 下推的函数中,其下推的函数签名中包含了类型信息,例如对于 a = b ,TiDB 下推的函数签名包括:EQInt,EQReal,EQString,EQDecimal,EQTime,EQDuration,EQJson,虽然 a 和 b 各自都可以是 int/real/string/decimal/time/duration/json 类别,但是 TiDB 下推的时候保证了 a 和 b 的类别是一致的,从工作量角度考虑,当前测试只需要保证相同类别之间的 equal 函数被测试到即可,int = decimal 这种的可以先不测。
- 对于输入参数可以无穷多的函数(例如 case when),需要确保其最小循环单元被测试到。
- 预期测试过程中会发现很多 bug,对于一些比较容易 fix 的 bug,可以在测试的同时顺便 fix,对于一些比较难或者不确定需不需要 fix 的 bug,可以先开 issue,再将相应的测试注释掉。
常见的问题
- 函数即使返回 null,也需要给其对应的 nestedColumn 赋一个有意义的值
TiFlash 中的函数实现中,有一个可以重载的函数:useDefaultImplementationForNulls,对于大多数函数来说,如果不需要对 null 做特殊处理的话,可以返回 true,这样的话,在实现这个函数的时候就不需要有任何 null 值相关的考虑,其原理是在 IExecutableFunction::defaultImplementationForNulls
中会将 nullable column 的 nestedColumn 取出来传给该函数,而 nestedColumn 始终都是 not null 的类型。
当然对于一些需要对 null 值特殊处理的函数,比如 concat_ws,因为要达到 “输出参数如果是 null 则忽略该参数” 的目的,concat_ws 需要自己处理 null 值逻辑,这样的话就必须重载 useDefaultImplementationForNulls 让其返回 false。对于需要自己实现 null 值处理逻辑的函数,如果结果为 null,必须给这个 nullable column 的 nestedColumn 设上一个有意义的值,所有 Function 都假设 nullable column 对应的 nestedColumn 中每一行都是一个有意义的值,即使是 null。之前出现过因为 nestedColumn 里面值不合法导致的bug,具体可以参照:#3875, #2268
推荐默认值如下:
- 数值类型:零值
- Date相关类型:zerodate
- 字符串类型:空字符串
- 使用
useDefaultImplementationForConstants()简化函数开发
TiFlash 中的函数实现中,有一个可以重载的函数:useDefaultImplementationForConstants,如果重载这个方法返回 true,那么在函数开发的时候,可以不考虑 const, const, ..., const 的列组合。
IExecutableFunction::defaultImplementationForConstantArguments 中会将 const, const, ..., const 转为 vector, vector, .., vector 来处理。
- 使用
getArgumentsThatAreAlwaysConstant简化函数开发 (不推荐)
在函数开发中,可能发现某个参数通常为常量,并且如果假设该参数一直为常量的话,开发函数会简单很多,这时候可以考虑强制该参数为常量,不为常量就报错。这时重载 getArgumentsThatAreAlwaysConstant,返回指定的常量参数的下标(从 0 开始)即可。
但是通常情况下不要这么做,除非是开发周期要求很紧的时候,在后面也最好找时间补回去。
-
增量更新怎么做?-icode9专业技术文章分享11-23
-
压缩包加密方案有哪些?-icode9专业技术文章分享11-23
-
用shell怎么写一个开机时自动同步远程仓库的代码?-icode9专业技术文章分享11-23
-
webman可以同步自己的仓库吗?-icode9专业技术文章分享11-23
-
在 Webman 中怎么判断是否有某命令进程正在运行?-icode9专业技术文章分享11-23
-
如何重置new Swiper?-icode9专业技术文章分享11-23
-
oss直传有什么好处?-icode9专业技术文章分享11-23
-
如何将oss直传封装成一个组件在其他页面调用时都可以使用?-icode9专业技术文章分享11-23
-
怎么使用laravel 11在代码里获取路由列表?-icode9专业技术文章分享11-23
-
怎么实现ansible playbook 备份代码中命名包含时间戳功能?-icode9专业技术文章分享11-22
-
ansible 的archive 参数是什么意思?-icode9专业技术文章分享11-22
-
ansible 中怎么只用archive 排除某个目录?-icode9专业技术文章分享11-22
-
exclude_path参数是什么作用?-icode9专业技术文章分享11-22
-
微信开放平台第三方平台什么时候调用数据预拉取和数据周期性更新接口?-icode9专业技术文章分享11-22
-
uniapp 实现聊天消息会话的列表功能怎么实现?-icode9专业技术文章分享11-22
