软件工程
懒人python操作,代码中永远只需要导入一个库

本文主要是介绍懒人python操作,代码中永远只需要导入一个库,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
Pyforest是一个开源的Python库,可以自动导入代码中使用到的Python库。
实话说,作为一个程序员还是得不停的学习呀。昨天晚上睡觉之前就在论坛上面溜达了一会儿,发现了有个叫pyforest的python非标准库可以自动导入代码中使用到的Python库,我竟然还不知道。
于是,迫不及待的测试了一下还真行,真是拯救了我们这些懒人。事情的来龙去脉说清楚了,接下来直接步入正题。
将Pyforest安装一下,粉丝朋友都知道我一直用的都是pip的安装方式。
pip install pyforest -i https://pypi.tuna.tsinghua.edu.cn/simple
我们使用pandas这个python库来验证一下。将pyforest导入到我们的代码块中。
import pyforest
然后,拿出我以前做数据测试的一个excel文件,文件的内容如下:
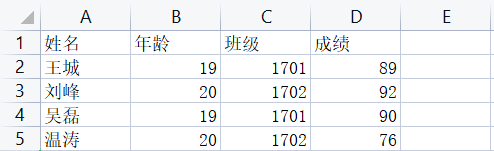
看一下在不直接导入pandas库的情况下,能不能准确的将数据读取出来。
data_frame = pd.read_excel('C:/data.xlsx')
print(data_frame) # 打印读取效果
# 姓名 年龄 班级 成绩
# 0 王城 19 1701 89
# 1 刘峰 20 1702 92
# 2 吴磊 19 1701 90
# 3 温涛 20 1702 76
OK,结果正常读取出来了。
原理就是,在使用pandas读取excel数据的时候,这个pandas库已经被导入进来了。
import pandas as pd
但是在开发工具中pd这个对象是没有被定义的,所以在开发工具中会认为这是个错误。但是不影响,在程序运行的时候会根据pyforest自动import的。
在上面的程序运行没有问题的情况下,可以使用pyforest库中的函数查看一下被导入的非标准库有哪些。
print(pyforest.active_imports()) # 打印一下导入的非标准库 # ['import pandas as pd']
同样的,还可以查看一下pyforest导入了哪些python标准库(也就是python中的内置库)
list_ = [n for n in dir(pyforest)]
print(f'python内置库的总数是:{str(len(list_))}')
# python内置库的总数是:105
print(list_)
# ['ARIMA', 'CountVectorizer', 'ElasticNet', 'ElasticNetCV', 'GradientBoostingClassifier',
# 'GradientBoostingRegressor', 'GridSearchCV', 'Image', 'KFold', 'KMeans', 'LabelEncoder',
# 'Lasso', 'LassoCV', 'LazyImport', 'LinearRegression', 'LogisticRegression', 'MinMaxScaler',
# 'OneHotEncoder', 'PCA', 'Path', 'PolynomialFeatures', 'Prophet', 'RandomForestClassifier',
# 'RandomForestRegressor', 'RandomizedSearchCV', 'Ridge', 'RidgeCV', 'RobustScaler', 'SimpleImputer',
# 'SparkContext', 'StandardScaler', 'StratifiedKFold', 'TSNE', 'TfidfVectorizer', '__builtins__',
# '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__',
# '__spec__', '__version__', '_importable', '_imports', '_jupyter_labextension_paths',
# '_jupyter_nbextension_paths', 'active_imports', 'alt', 'bokeh', 'cross_val_score', 'cv2', '
# dash', 'dd', 'dt', 'fastai', 'fbprophet', 'gensim', 'get_user_symbols', 'glob', 'go',
# 'import_symbol', 'imutils', 'install_extensions', 'install_labextension', 'install_nbextension',
# 'keras', 'lazy_imports', 'lgb', 'load_workbook', 'metrics', 'mpl', 'nltk', 'np', 'open_workbook',
# 'os', 'pd', 'pickle', 'plt', 'px', 'py', 'pydot', 'pyforest_imports', 're', 'sg', 'skimage',
# 'sklearn', 'sm', 'sns', 'spacy', 'statistics', 'stats', 'svm', 'sys', 'textblob', 'tf', 'torch',
# 'tqdm', 'train_test_split', 'user_specific_imports', 'user_symbols', 'utils', 'wr', 'xgb']
这篇关于懒人python操作,代码中永远只需要导入一个库的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
您可能喜欢
-
[开源]4.8K+ star!速度高达60MS,这款下载神器也是绝了!11-29
-
如何优化教育管理?班级协作提升教程11-29
-
2024年最受欢迎的需求管理工具大盘点,如何选择适合团队的需求管理平台?11-29
-
从需求到满意:如何把客户的预期落地?11-29
-
低代码入门教程:轻松搭建你的第一个应用11-29
-
避免项目崩盘!这5大外委项目管理技巧你知道吗?11-29
-
提升项目成功率的关键:6个方法让你突破管理瓶颈!11-29
-
营销策划中的沟通不畅问题如何破解?试试这5款工具提高工作效率11-29
-
看板办公协同软件能提高团队效率吗?深度解析11-29
-
嫌Heptabase 贵?试试这些免费知识管理软件的表现11-28
-
一款软件能否彻底改变营销人的工作方式?11-28
-
如何让活动策划既快又准?这款软件有答案!11-28
-
创业公司如何管理团队知识?8款主流软件功能全面评测与分析11-28
-
使用CloudFlare解析主域名和子域名到同一网站11-28
-
提高项目管理效率:2024年最佳任务可视化工具对比分析11-28
栏目导航
