C/C++教程
【clickhouse专栏】clickhouse性能为何如此卓越

在《clickhouse专栏》上一篇文章中《数据库、数据仓库之间的区别与联系》,我们介绍了什么是数据库,什么是数据仓库,二者的区别联系。clickhouse的定位是“数据仓库”,所以理解了上一篇的内容,其实就能够知道clickhouse适用于什么样的应用场景,不适合什么样的应用场景。
下面本节我们就来继续为大家介绍clickhouse的一些非常有意义的特性,来帮助大家更深入的理解ck的应用场景,以及它为什么被称为“性能怪兽”。
[TOC]
一、列式数据存储
clickhouse的性能之所以彪悍,其列式存储设计是非常重要的原因之一。给大家举一个例子,假如我们现在有一张学生信息表student
| id | name | age |
|---|---|---|
| 1 | 小红 | 7 |
| 2 | 小明 | 8 |
| 3 | lucy | 7 |
如果这张表采用行式数据存储,其在磁盘上的结构是下面这样的:

如果这张表采用列式数据存储,其在磁盘上的结构是下面这样的:

对比上面的两张图我们可以看到,采用列式存储的优点。
- 比如:我们查询学生年龄的最大值,列式数据存储只需要定位到年龄那一列的起始地址,然后顺序读取数据进行排序计算即可。而行式数据存储的方式,因为年龄这一字段的数据单元不是连续的,需要根据索引不断的寻址,或者全表扫描才能获取到所有的年龄数据。所以在采用列式存储时,我们需要针对某一列进行查询过滤、统计计算性能就远胜于行式数据存储方式。
- 另外,因为数据库的设计一列的数据通常是同一种数据类型,列式数据存储有比行式存储高达10倍以上的压缩比,节省了大量的磁盘及内存空间,可以有效降低服务器成本。
二、支持SQL并且性能卓越
目前开源世界里的大部分的列式存储数据库是不支持SQL的,即使很多号称支持SQL,其实支持SQL也是伪SQL,并且支持能力有限。
但是经过笔者的实验,clikhouse对于标准SQL的支持已经可以与传统的关系型数据库媲美,虽然对于数据仓库click house,我更建议大家使用宽表进行数据存储,但是不代表ck不具备多表关联查询的能力。
可以访问:https://clickhouse.com/benchmark/dbms/ ,获取click house官方在线的针对各种数据统计型SQL的性能对比。
三、分布式分片存储集群
clikhouse不仅支持单机模式,也支持分布式分片数据存储的集群模式。数据以分片的行式,存储在多台服务器节点上面,因此ck可以利用集群服务器的规模计算能力,快速的做出数据统计结果的响应。ck数据分片分布式存储的机制,使得clickhouse具备了横向扩展,海量数据分析处理的能力。
数据分片包括很多的方式,比如:数据随机写入不同服务器分片存储上、数据被发往指定的服务器分片存储之上、数据按照hash值进行分片、当然我们还可以自定义数据分片的方式。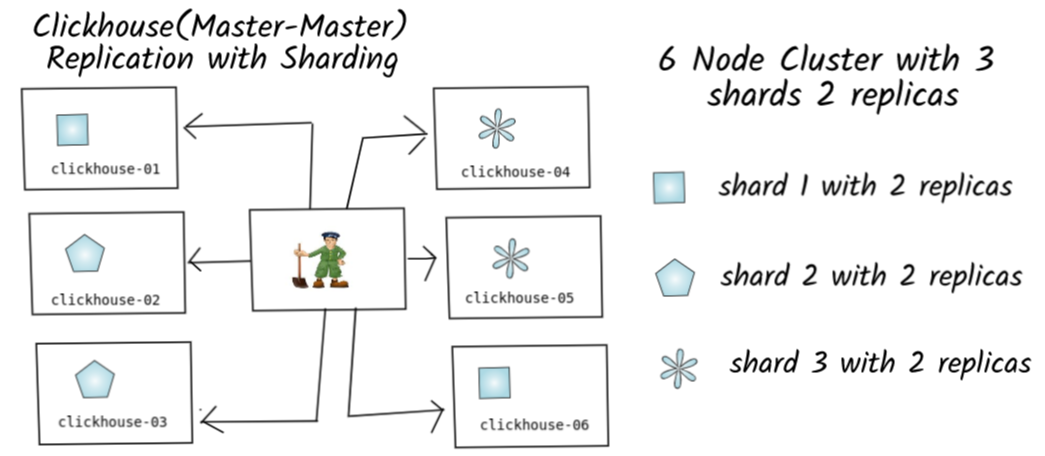
分布式数据存储将数据分散到集群内的各个服务器上(以分片(shard)的行式存在),为了保证数据的安全,每一个分片又有多个副本(replica),副本也是分布式存储的,这样即使部分服务器宕机,仍然可以保障ck集群可用。
四、 支持按序存储
与传统的RMDB数据库不同的是,clickhouse支持在建表的时候就通过sort by关键字指定排序字段。这样在数据入表的时候,实际是先进行了排序操作,按照排序字段进行排序后的数据有序存放。
后续在进行数据查询、过滤、统计的时候,就能够有效的、快速的获取连续的数据块中的数据,提升查询统计的性能。这种按序存储的特性其实还是有非常广泛的应用场景的,比如:股票K线图都是按照交易日时间排序的,预设排序字段、按序存储有效的提升了统计性能。
五、支持数据TTL
在数据统计分析的数据库中,通常我们需要数据TTL能力,也就是说:某些数据达到一定的存储周期之后自动删除。ck就提供了这种能力,降低了系统运维人员的工作难度。
ck支持以下几种粒度的TTL
- 列级别TTL:为某一列设置TTL时间,当这一列中的部分数据过期之后,列值会被自动替换为默认值,全部数据过期之后会自动删除该列。
- 行级别TTL:为某一行设置TTL时间,当某一行过期后,会直接删除该行。
- 分区级别TTL:ck支持数据分区并设置TTL时间,当分区过期后,会直接删除该分区。
-
怎么实现ansible playbook 备份代码中命名包含时间戳功能?-icode9专业技术文章分享11-22
-
ansible 的archive 参数是什么意思?-icode9专业技术文章分享11-22
-
ansible 中怎么只用archive 排除某个目录?-icode9专业技术文章分享11-22
-
exclude_path参数是什么作用?-icode9专业技术文章分享11-22
-
微信开放平台第三方平台什么时候调用数据预拉取和数据周期性更新接口?-icode9专业技术文章分享11-22
-
uniapp 实现聊天消息会话的列表功能怎么实现?-icode9专业技术文章分享11-22
-
在Mac系统上将图片中的文字提取出来有哪些方法?-icode9专业技术文章分享11-22
-
excel 表格中怎么固定一行显示不滚动?-icode9专业技术文章分享11-22
-
怎么将 -rwxr-xr-x 修改为 drwxr-xr-x?-icode9专业技术文章分享11-22
-
在Excel中怎么将小数向上取整到最接近的整数?-icode9专业技术文章分享11-22
-
Excel中常见的取整函数有哪些?-icode9专业技术文章分享11-22
-
错误信息:does not match the actual quantity supplied 提示是什么意思?-icode9专业技术文章分享11-22
-
WebSocket学习:初学者的简单指南11-21
-
获取apk的md5值有哪些方法?-icode9专业技术文章分享11-20
-
xml报文没有传 IdentCode ,为什么正常解析没报错呢?-icode9专业技术文章分享11-20
