Java教程
Springboot2.x整合ElasticSearch7.x实战(一)

学习一个新技术,最快的掌握方式就是先学会使用,让我们有了很强的满足感,在研究底层代码。
本篇幅是继上一篇[Springboot2.x整合ElasticSearch7.x实战目录],适合初学 Elasticsearch 的小白,可以跟着整个教程做一个练习。
编者荐语:在大数据搜索中,Elasticsearch 使用频率非常高。学习 Java 了解大数据那是我们 Java 攻城狮很好的选择。
@[toc]
第一章 课程介绍
自我介绍
大家好,我是pub哥
ElasticSearch SpringBoot 介绍
ElasticSearch
ElasticSearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库——无论是开源还是私有。
ElasticSearch 使用 Java 编写的,它的内部使用的是 Lucene 做索引与搜索,它的目的是使全文检索变得简单,通过隐藏 Lucene 的复杂性,取而代之提供了一套简单一致的 RESTful API。
然而,ElasticSearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎,它可以被下面这样准确地形容:
- 一个分布式的实时文档存储,每个字段可以被索引与搜索
- 一个分布式近实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
Elasticsearch 是与名为 Logstash 的数据收集和日志解析引擎以及名为 Kibana 的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为 “Elastic Stack” (以前称为“ELK stack”)。
SpringBoot
Spring Boot 是由 Pivotal 团队提供的全新框架,其设计目的是用来简化新 Spring 应用的初始搭建以及开发过程。该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。用我的话来理解,就是 Spring Boot 其实不是什么新的框架,它默认配置了很多框架的使用方式,就像 Maven 整合了所有的 Jar 包,Spring Boot 整合了所有的框架。
简单来说,使用 Spring Boot 可以非常方便、快速搭建项目,使我们不用关心框架之间的兼容性,适用版本等各种问题,我们想使用任何东西,仅仅添加一个配置就可以,所以使用 Spring Boot 非常适合构建微服务。
环境介绍
centOS 7.3
JDK1.8 及以上
ElasticSearch 7.*
第二章 软件安装
服务器环境
确保你的服务器安装了 jdk1.8 或以上版本环境
Elasticsearch通过文件映射(mmap)来读取磁盘中的文件,这样可以比read系统调用少一次内存拷贝,也被称为0拷贝技术。ES映射的文件会很多,所以需要修改最大映射文件的数量,通过修改vm.max_map_count配置项可实现。设置方式
文件最后添加一行
vim /etc/sysctl.conf
vm.max_map_count=262144
以上几点是环境搭建的基础
Linux安装JDK
es 最小支持 jdk 版本是 jdk8
Linux安装es,方法和要点
国内版本镜像页:https://mirrors.huaweicloud.com/elasticsearch/
下载:
wget https://mirrors.huaweicloud.com/elasticsearch/7.7.0/elasticsearch-7.7.0-linux-x86_64.tar.gz
解压:
tar -zxvf elasticsearch-7.7.0-linux-x86_64.tar.gz
es集群、初步配置和使用
设置堆内存,修改 jvm.options ,学习阶段初学者 200m 即可,示例如下。
-Xms200m
-Xmx200m
在启动前,先修改配置文件, config/elasticsearch.yml
贴一下全部配置(ip地址是服务器对外访问地址):
cluster.name: my-application node.name: node01 node.master: true node.data: true #bootstrap.memory_lock: false #bootstrap.system_call_filter: false network.host: 0.0.0.0 http.port: 9200 transport.tcp.port: 9300 http.cors.enabled: true http.cors.allow-origin: "*" # 集群发现:配置该节点会与哪些候选地址进行通信,默认端口9300,可填ip;ip+port;域名 discovery.seed_hosts: ["39.12.1.1"] # cluster.initial_master_nodes: ["39.12.1.1"] discovery.zen.minimum_master_nodes: 1 #http.cors.allow-headers: Authorization #xpack.security.enabled: true #xpack.security.transport.ssl.enabled: true
启动:
./bin/elasticsearch
到此为止,单机版本已搭建完成。访问下面地址,可以看到我们的es版本信息。
http://ip+9200/
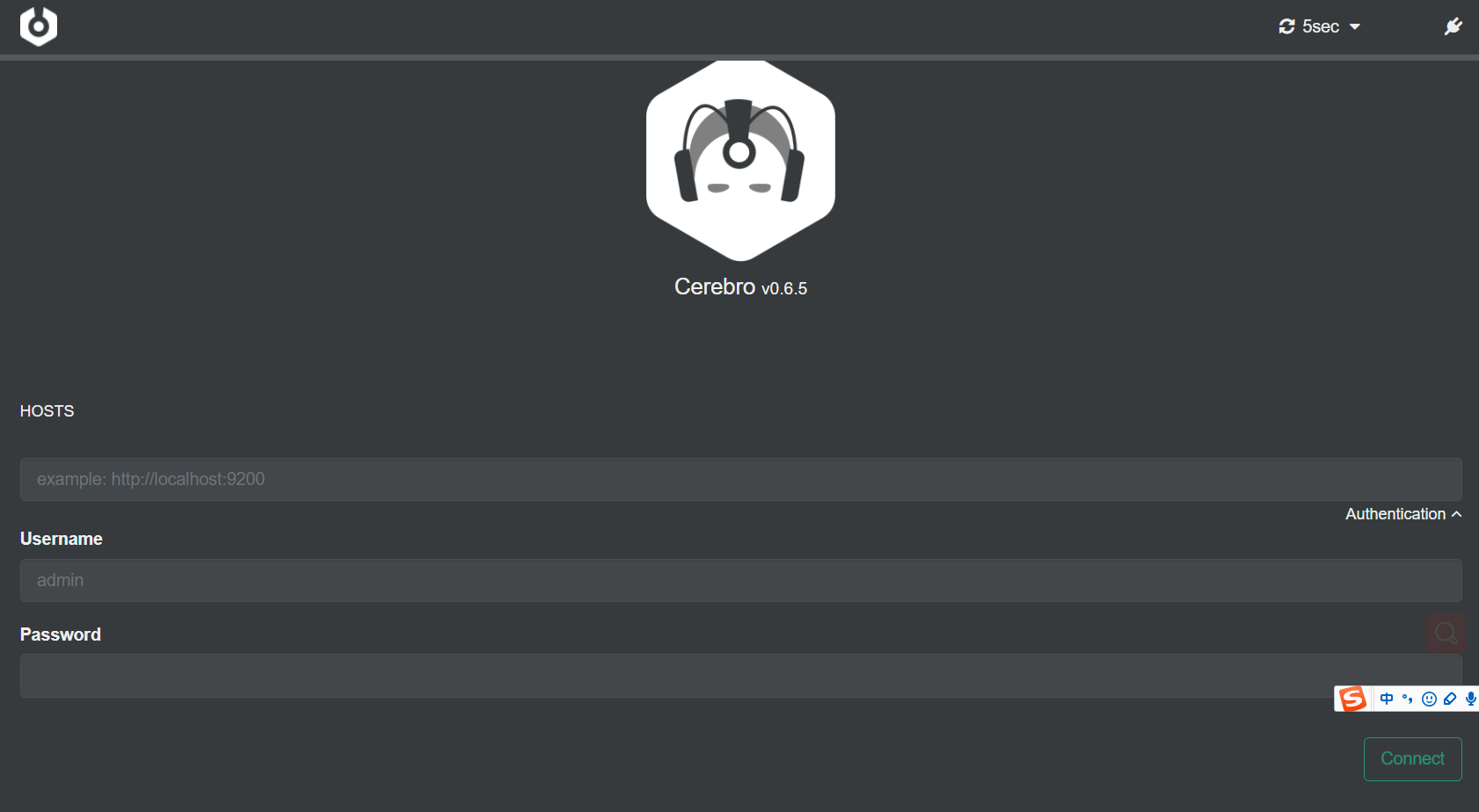
安装使用可视化工具插件head,Cerebro
这里只介绍 cerebro 安装
下载:
wget https://github.com/lmenezes/cerebro/releases/download/v0.6.5/cerebro-0.6.5.tgz
解压:
tar zxvf cerebro-0.6.5.tgz
启动:
cd cerebro-0.6.5
bin/cerebro
在看和分享是对我最大的鼓励,我是 pub 哥,我们下期再见
-
Springboot应用的多环境打包入门11-23
-
Springboot应用的生产发布入门教程11-23
-
Python编程入门指南11-23
-
Java创业入门:从零开始的编程之旅11-23
-
Java创业入门:新手必读的Java编程与创业指南11-23
-
Java对接阿里云智能语音服务入门详解11-23
-
Java对接阿里云智能语音服务入门教程11-23
-
JAVA对接阿里云智能语音服务入门教程11-23
-
Java副业入门:初学者的简单教程11-23
-
JAVA副业入门:初学者的实战指南11-23
-
JAVA项目部署入门:新手必读指南11-23
-
Java项目部署入门:新手必看指南11-23
-
Java项目部署入门:新手必读指南11-23
-
Java项目开发入门:新手必读指南11-23
-
JAVA项目开发入门:从零开始的实用教程11-23
