微信公众号开发
如何快速开发一个古诗词小程序

前言:
github日常淘宝,看到的项目可能因为历史原因已经不维护了,跑步起来,那么我们就让他跑起来吧!
本篇以一个古诗词小程序为例,大概花了一天的时间,给想学习的小白或者业余你想整一个玩玩的时候能有个思路。
github链接在文章最下方。
最终实现效果:

1.探索:去github逛街
成功发现一个小可爱 「诗词墨客」:
二话不说,点个star ⭐️ 对作者表示鼓励。
2.运行:一顿操作,给我跑起来
git clone git@github.com:huangjianke/weapp-poem.git cd weapp-poem npm install wepy-cli -g npm install wepy build --watch
打开微信小程序
导入dist文件夹,我这里已经导入过了。

3. 结果:微信小程序启动!
不出所料失败,一片空白,说好的诗词呢。

哈哈哈哈当然跑步起来了,我们都没有数据~
此处有解答:
古诗词数据存储于 LeanCloud,使用前先在 LeanCloud注册App,然后导入由 chinese-poetry-mysql整理的 mysql 格式数据,并在app.wpy中配置您自己的App相关信息
简单来说我们要:
-
- leancloud(一个提供云服务的厂商)上注册账户
-
2. 导入数据到LeanCloud中去。
-
- 配置app.wpy
那接下来我们就一步步来操作。
3.1:注册并创建应用

稍微看下目录结构,长这样:

3.2 导入数据
接下来我们要把数据导入到数据库中。
数据从哪里来,我们照着提示来:
我们去 chinese-poetry-mysql下载sql语句包。
把数据导入到 LeanCloud中去。
很简单的,唯一麻烦的是,我们需要把sql语句转成能上传LeanCloud的csv或者json。
好在我已经处理过了:
把这里的csv文件通通导入进来就行了~

csv文件
问:为啥分成了怎么多份?
因为LeanCloud最大只允许上传30M的文件,所以我手动把他分成几份…
用的蠢办法直接粘贴复制的几十万行…懒的写脚本了
一开始不太明白怎么导入,折腾了下csv的格式。

导入的时候要注意:
-
• class名称要一致,poetry开头的csv都是导入到poetry的Class去的。
-
• 不要像我一样重复导入…几十m的csv导入估计要几分钟。只有三十几万的诗歌,但我却有50w条数据。
导入完成结果如图:

文档目录结构
3.2 配置 app.wpy
appId,appkey,REST API 照着填下去


3.4 重新运行
嘿嘿,总算有效果了:

摘录:
这里原仓库并没有提供extract表,那咱自己动手,从诗经中随便拿一句出来。
首页:

文集页面:

作者页面:

详情页面:

这样一个基本的诗词小程序就有了,哈哈哈哈给自己点个赞。
4. 改进

-
• 这几十万首歌没有搜索明显不行呀,我这辈子都看不完…
-
• 数据库中的数据全是繁体,看来要弄个简繁转换。
-
• 整个播放诗句语音提高逼格。
4.1 简体繁体转换: 老规矩github上面去淘宝:
发现一个这个https://github.com/toolgood/ToolGood.Words
把这个下载就好了。

直接引入有问题,要在js后面加导出模块函数。

用的时候这样就能用了
import { Translate } from '../../libs/wordsTranslate.min.js';
// 类似这样用
//translate.ToSimplifiedChinese(this.item.author);
4.2搜索:咱们直接来个全文检索:
- 1. 这里就随便先建议一个全文索引:作者,标题,内容。
ps:速度有点慢,建立的时候要稍微等一段时间。
真正的简单粗暴,当然这里明显可以改的更好一些哈哈哈。

有了全文索引怎么用呢?去文档捞一捞:全文搜索开发指南 - LeanCloud 文档

好了,学会了,去代码上cv一波。
思路:搜索的时候把输入的简体转化为繁体,在调用api搜索,最后在整合下页面 效果如下:

4.3诗歌的语音播放:
网上找了一个比较好用的接口: http://ovooa.com/API/yuyin/api.php:这个网站超多好用的api 哈哈哈
建议大家可以去看看,挺多好玩的。
主要代码:
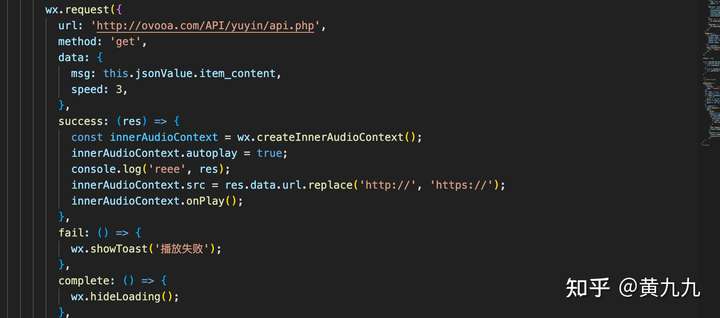
大功告成,你已经制作好了一个简单的古诗词小程序~
接下来就是小程序的上架,我们申请好小程序,填写appid和secret上传代码,审核通过后就能上架了。
5. 总结
当然这个小程序还有很多问题,还有很多功能可以完善。
-
• 诗词不够全,还缺少了很多诗词…
-
• 语音朗读只能说能听…
-
• 搜索不够精准,比如按照特定的分类来搜索:作者,标题,内容。
-
• 加入用户模块,这样就能喜欢、收藏一些诗词对吧。
这些坑就留着下次填吧。
都看到这里了点个赞不过分吧哈哈哈,谢谢大家~。
有什么不对的地方可以下方留言,我看到会改的!
本偏文章 github链接:https://github.com/hzeyuan/weapp-poem
-
微信小程序开发入门指南12-20
-
小程序 createCameraContext() 怎么实现识别条形码功能?-icode9专业技术文章分享12-20
-
微信小程序的接口信息py可以抓到吗?-icode9专业技术文章分享11-22
-
怎样解析出微信小程序二维码带的参数?-icode9专业技术文章分享11-22
-
微信小程序二维码怎样解析成链接?-icode9专业技术文章分享11-22
-
微信小程序接口地址的域名需要怎么设置?-icode9专业技术文章分享11-22
-
微信小程序的业务域名有什么作用-icode9专业技术文章分享11-22
-
微信小程序 image有类似html5的onload吗?-icode9专业技术文章分享11-22
-
微信小程序中怎么实现文本内容超出行数后显示省略号?-icode9专业技术文章分享11-22
-
微信小程序怎么实现分享样式定制和图片定制功能?-icode9专业技术文章分享11-22
-
微信小程序全栈教程:从零开始的全攻略11-20
-
微信小程序全栈学习:从零开始的完整指南11-19
-
微信小程序如何封装接口域名?-icode9专业技术文章分享11-13
-
如何在微信小程序中实现直传功能?-icode9专业技术文章分享11-13
-
如何在小程序的地图组件中添加标记和文字?-icode9专业技术文章分享11-13
