C/C++教程
Crane-scheduler:基于真实负载进行调度

作者
邱天,腾讯云高级工程师,负责腾讯云 TKE 动态调度器与重调度器产品。
背景
原生 kubernetes 调度器只能基于资源的 resource request 进行调度,然而 Pod 的真实资源使用率,往往与其所申请资源的 request/limit 差异很大,这直接导致了集群负载不均的问题:
-
集群中的部分节点,资源的真实使用率远低于 resource request,却没有被调度更多的 Pod,这造成了比较大的资源浪费;
-
而集群中的另外一些节点,其资源的真实使用率事实上已经过载,却无法为调度器所感知到,这极大可能影响到业务的稳定性。
这些无疑都与企业上云的最初目的相悖,为业务投入了足够的资源,却没有达到理想的效果。
既然问题的根源在于 resource request 与真实使用率之间的「鸿沟」,那为什么不能让调度器直接基于真实使用率进行调度呢?这就是 Crane-scheduler 设计的初衷。Crane-scheduler 基于集群的真实负载数据构造了一个简单却有效的模型,作用于调度过程中的 Filter 与 Score 阶段,并提供了一种灵活的调度策略配置方式,从而有效缓解了 kubernetes 集群中各种资源的负载不均问题。换句话说,Crane-scheduler 着力于调度层面,让集群资源使用最大化的同时排除了稳定性的后顾之忧,真正实现「降本增效」。
整体架构
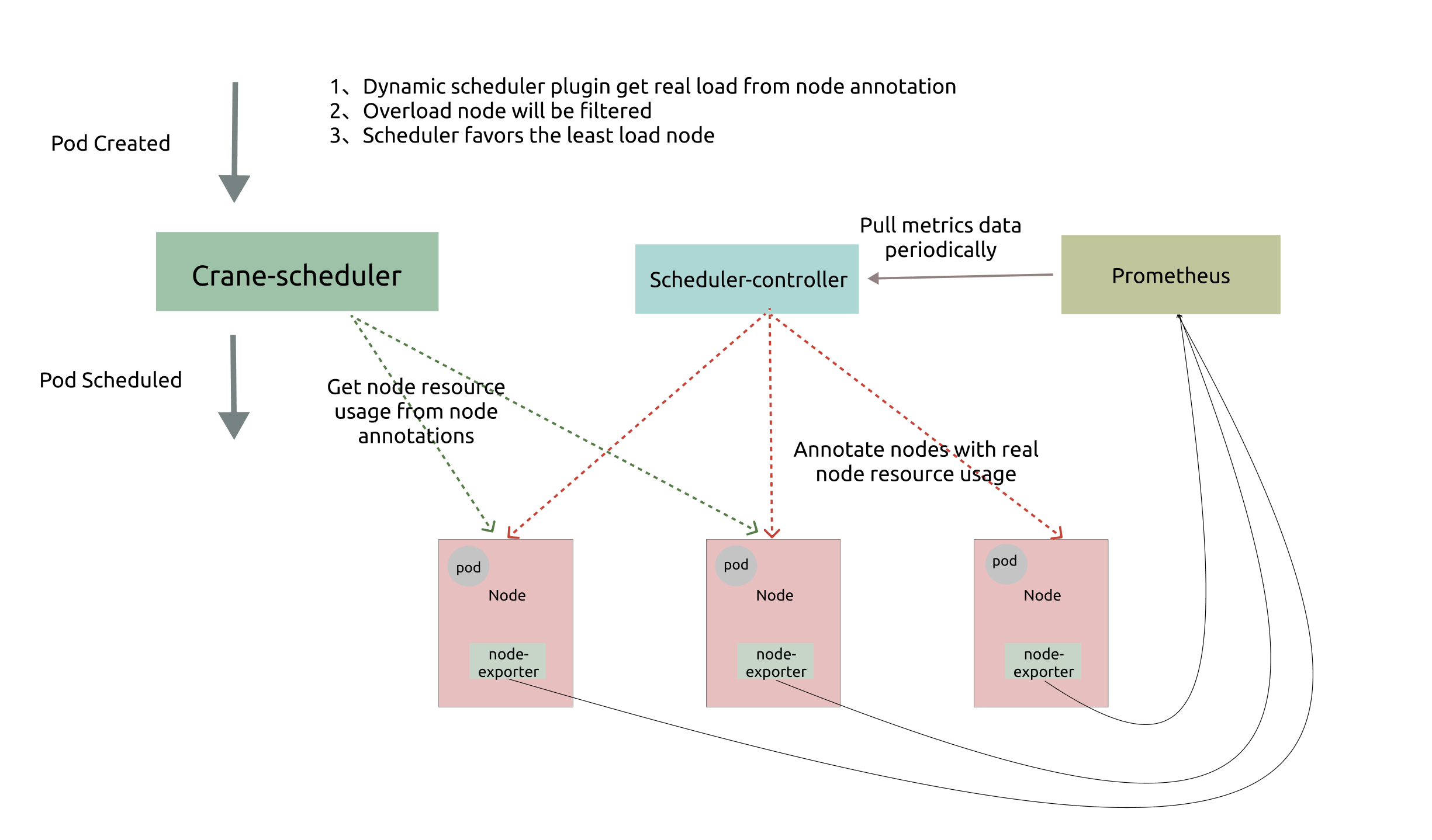
如上图所示,Crane-scheduler 依赖于 Node-exporter 与 Prometheus 两个组件,前者从节点收集负载数据,后者则对数据进行聚合。而 Crane-scheduler 本身也包含两个部分:
-
Scheduler-Controller 周期性地从 Prometheus 拉取各个节点的真实负载数据, 再以 Annotation 的形式标记在各个节点上;
-
Scheduler 则直接在从候选节点的 Annotation 读取负载信息,并基于这些负载信息在 Filter 阶段对节点进行过滤以及在 Score 阶段对节点进行打分;
基于上述架构,最终实现了基于真实负载对 Pod 进行有效调度。
调度策略
下图是官方提供的 Pod 的调度上下文以及调度框架公开的扩展点:
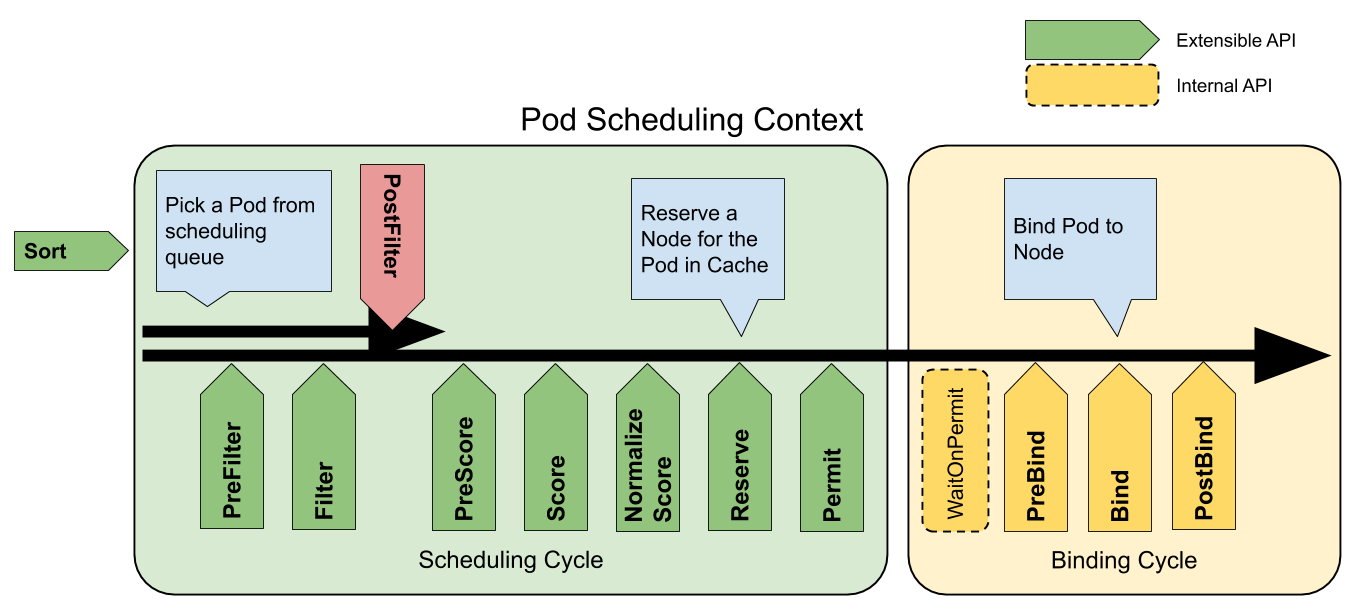
Crane-scheduler 主要作用于图中的 Filter 与 Score 阶段,并对用户提供了一个非常开放的策略配置。这也是 Crane-Scheduler 与社区同类型的调度器最大的区别之一:
- 前者提供了一个泛化的调度策略配置接口,给予了用户极大的灵活性;
- 后者往往只能支持 cpu/memory 等少数几种指标的感知调度,且指标聚合方式,打分策略均受限。
在 Crane-scheduler 中,用户可以为候选节点配置任意的评价指标类型(只要从 Prometheus 能拉到相关数据),不论是常用到的 CPU/Memory 使用率,还是 IO、Network Bandwidth 或者 GPU 使用率,均可以生效,并且支持相关策略的自定义配置。
数据拉取
如「整体架构」中所述,Crane-scheduler 所需的负载数据均是通过 Controller 异步拉取。这种数据拉取方式:
-
一方面,保证了调度器本身的性能;
-
另一方面,有效减轻了 Prometheus 的压力,防止了业务突增时组件被打爆的情况发生。
此外,用户可以直接 Describe 节点,查看到节点的负载信息,方便问题定位:
[root@test01 ~]# kubectl describe node test01
Name: test01
...
Annotations: cpu_usage_avg_5m: 0.33142,2022-04-18T00:45:18Z
cpu_usage_max_avg_1d: 0.33495,2022-04-17T23:33:18Z
cpu_usage_max_avg_1h: 0.33295,2022-04-18T00:33:18Z
mem_usage_avg_5m: 0.03401,2022-04-18T00:45:18Z
mem_usage_max_avg_1d: 0.03461,2022-04-17T23:33:20Z
mem_usage_max_avg_1h: 0.03425,2022-04-18T00:33:18Z
node.alpha.kubernetes.io/ttl: 0
node_hot_value: 0,2022-04-18T00:45:18Z
volumes.kubernetes.io/controller-managed-attach-detach: true
...
用户可以自定义负载数据的类型与拉取周期,默认情况下,数据拉取的配置如下:
syncPolicy:
## cpu usage
- name: cpu_usage_avg_5m
period: 3m
- name: cpu_usage_max_avg_1h
period: 15m
- name: cpu_usage_max_avg_1d
period: 3h
## memory usage
- name: mem_usage_avg_5m
period: 3m
- name: mem_usage_max_avg_1h
period: 15m
- name: mem_usage_max_avg_1d
period: 3h
Filter 策略
用户可以在 Filter 策略中配置相关指标的阈值,若候选节点的当前负载数据超过了任一所配置的指标阈值,则这个节点将会被过滤,默认配置如下:
predicate:
## cpu usage
- name: cpu_usage_avg_5m
maxLimitPecent: 0.65
- name: cpu_usage_max_avg_1h
maxLimitPecent: 0.75
## memory usage
- name: mem_usage_avg_5m
maxLimitPecent: 0.65
- name: mem_usage_max_avg_1h
maxLimitPecent: 0.75
Score 策略
用户可以在 Score 策略中配置相关指标的权重,候选节点的最终得分为不同指标得分的加权和,默认配置如下:
priority:
### score = sum((1 - usage) * weight) * MaxScore / sum(weight)
## cpu usage
- name: cpu_usage_avg_5m
weight: 0.2
- name: cpu_usage_max_avg_1h
weight: 0.3
- name: cpu_usage_max_avg_1d
weight: 0.5
## memory usage
- name: mem_usage_avg_5m
weight: 0.2
- name: mem_usage_max_avg_1h
weight: 0.3
- name: mem_usage_max_avg_1d
weight: 0.5
调度热点
在实际生产环境中,由于 Pod 创建成功以后,其负载并不会立马上升,这就导致了一个问题:如果完全基于节点实时负载对 Pod 调度,常常会出现调度热点(短时间大量 pod 被调度到同一个节点上)。为了解决这个问题,我们设置了一个单列指标 Hot Vaule,用来评价某个节点在近段时间内被调度的频繁程度,对节点实时负载进行对冲。最终节点的 Priority 为上一小节中的 Score 减去 Hot Value。Hot Value 默认配置如下:
hotValue:
- timeRange: 5m
count: 5
- timeRange: 1m
count: 2
**注:**该配置表示,节点在 5 分钟内被调度 5 个 pod,或者 1 分钟内被调度 2 个 pod,HotValue 加 10 分。
案例分享
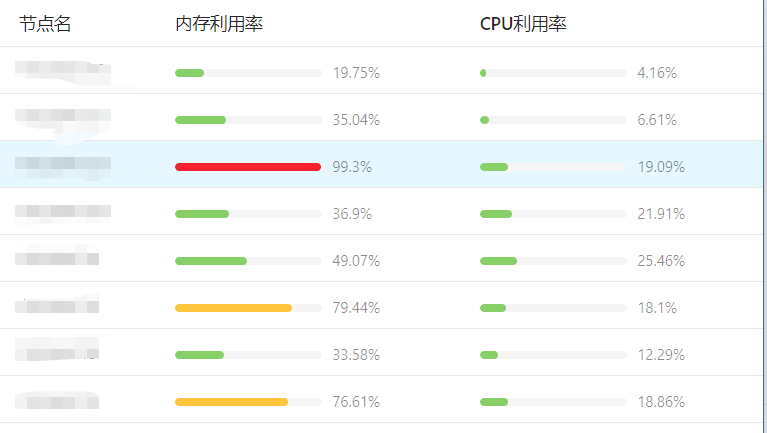
Crane-scheduler 目前有众多公有云用户,包括斗鱼直播、酷狗、一汽大众、猎豹移动等公司均在使用,并给予了产品不错的反馈。这里我们先分享一个某公有云用户的真实案例。该客户集群中的业务大多是内存消耗型的,因此极易出现内存利用率很高的节点,并且各个节点的内存利用率分布也很不平均,如下图所示:
了解到用户的情况后,我们推荐其使用 Crane-scheduler,组件运行一段时间后,该用户集群内各节点的内存利用率数据分布发生了显著变化,如下图 :
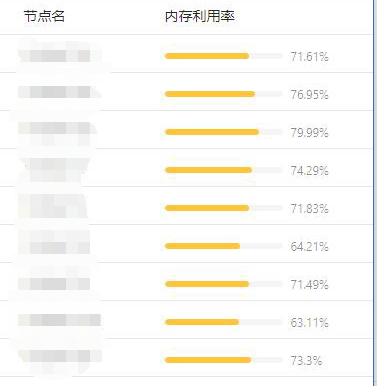
可见,用户集群的内存使用率更加趋于均衡。
另外, Crane-scheduler 也在公司内部各个 BG 的自研上云环境中,也得到了广泛的使用。下面是内部自研上云平台 TKEx-CSIG 的两个生产集群的 CPU 使用率分布情况,其中集群 A 未部署 Crane-scheduler:
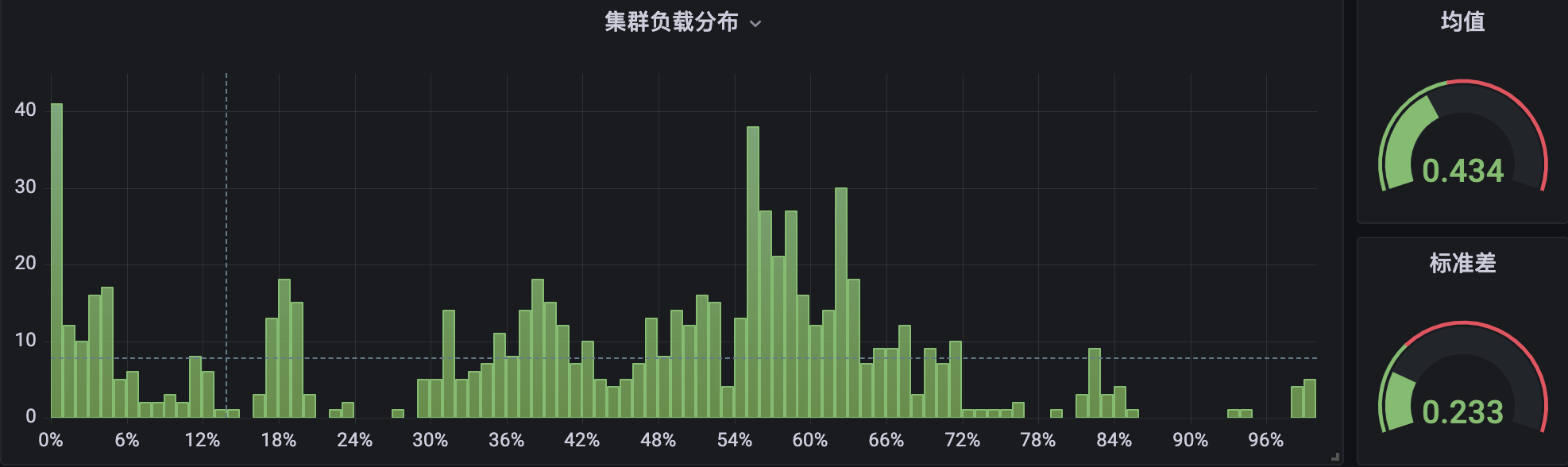
集群 B 部署了组件并运行过一段时间:
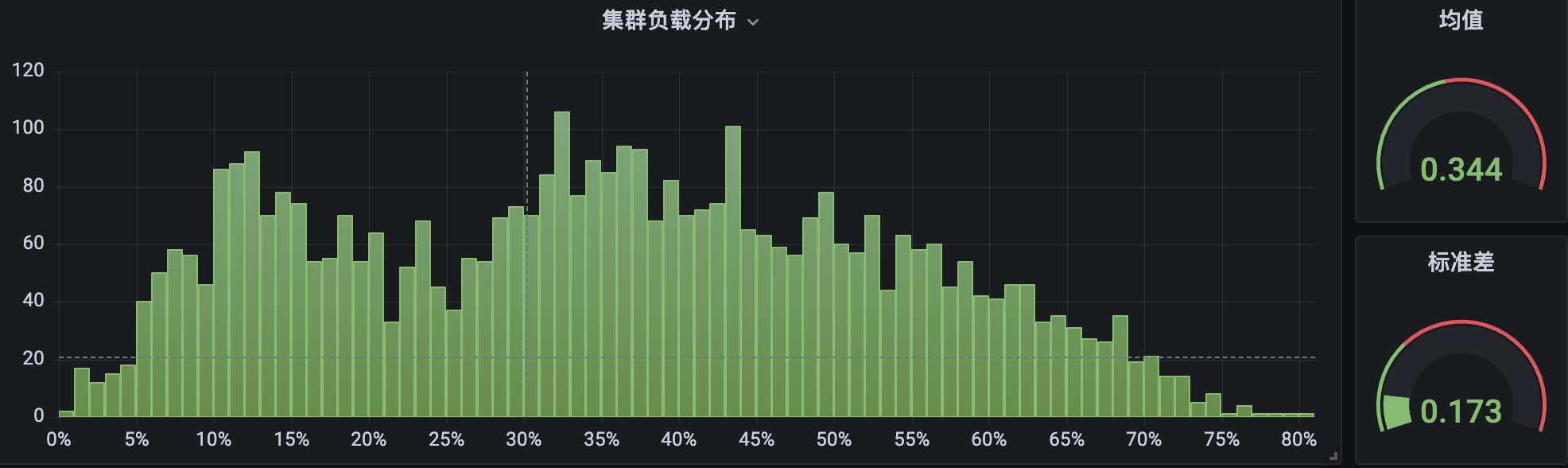
很明显,在集群 B 中,节点 CPU 使用率分布在两端( < 10% 与 > 80%)所占的比例,要显著小于集群 A,并且整体分布也更加紧凑,相对而言更加均衡与健康。
衍生阅读:什么是 Crane
为推进云原生用户在确保业务稳定性的基础上做到真正的极致降本,腾讯推出了业界第一个基于云原生技术的成本优化开源项目 Crane( Cloud Resource Analytics and Economics )。Crane 遵循 FinOps 标准,旨在为云原生用户提供云成本优化一站式解决方案。
Crane-scheduler 作为 Crane 的调度插件实现了基于真实负载的调度功能,旨在从调度层面帮助业务降本增效。
近期,Crane 成功加入 CNCF Landscape,欢迎关注项目:https://github.com/gocrane/crane。
-
增量更新怎么做?-icode9专业技术文章分享11-23
-
压缩包加密方案有哪些?-icode9专业技术文章分享11-23
-
用shell怎么写一个开机时自动同步远程仓库的代码?-icode9专业技术文章分享11-23
-
webman可以同步自己的仓库吗?-icode9专业技术文章分享11-23
-
在 Webman 中怎么判断是否有某命令进程正在运行?-icode9专业技术文章分享11-23
-
如何重置new Swiper?-icode9专业技术文章分享11-23
-
oss直传有什么好处?-icode9专业技术文章分享11-23
-
如何将oss直传封装成一个组件在其他页面调用时都可以使用?-icode9专业技术文章分享11-23
-
怎么使用laravel 11在代码里获取路由列表?-icode9专业技术文章分享11-23
-
怎么实现ansible playbook 备份代码中命名包含时间戳功能?-icode9专业技术文章分享11-22
-
ansible 的archive 参数是什么意思?-icode9专业技术文章分享11-22
-
ansible 中怎么只用archive 排除某个目录?-icode9专业技术文章分享11-22
-
exclude_path参数是什么作用?-icode9专业技术文章分享11-22
-
微信开放平台第三方平台什么时候调用数据预拉取和数据周期性更新接口?-icode9专业技术文章分享11-22
-
uniapp 实现聊天消息会话的列表功能怎么实现?-icode9专业技术文章分享11-22
