Javascript
【JS 逆向百例】HN某服务网登录逆向,验证码形同虚设

声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
逆向目标
-
目标:某政务服务网登录接口
-
主页:
aHR0cHM6Ly9sb2dpbi5obnp3ZncuZ292LmNuL3RhY3MtdWMvbG9naW4vaW5kZXg= -
接口:
aHR0cHM6Ly9sb2dpbi5obnp3ZncuZ292LmNuL3RhY3MtdWMvbmF0dXJhbE1hbi9sb2dpbk5v -
逆向参数:
Form Data:loginNo、loginPwd、code、requestUUID
Request Headers:token
抓包分析
本次逆向目标来源于某位粉丝的求助:
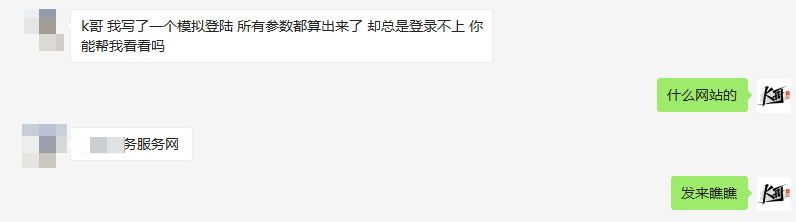
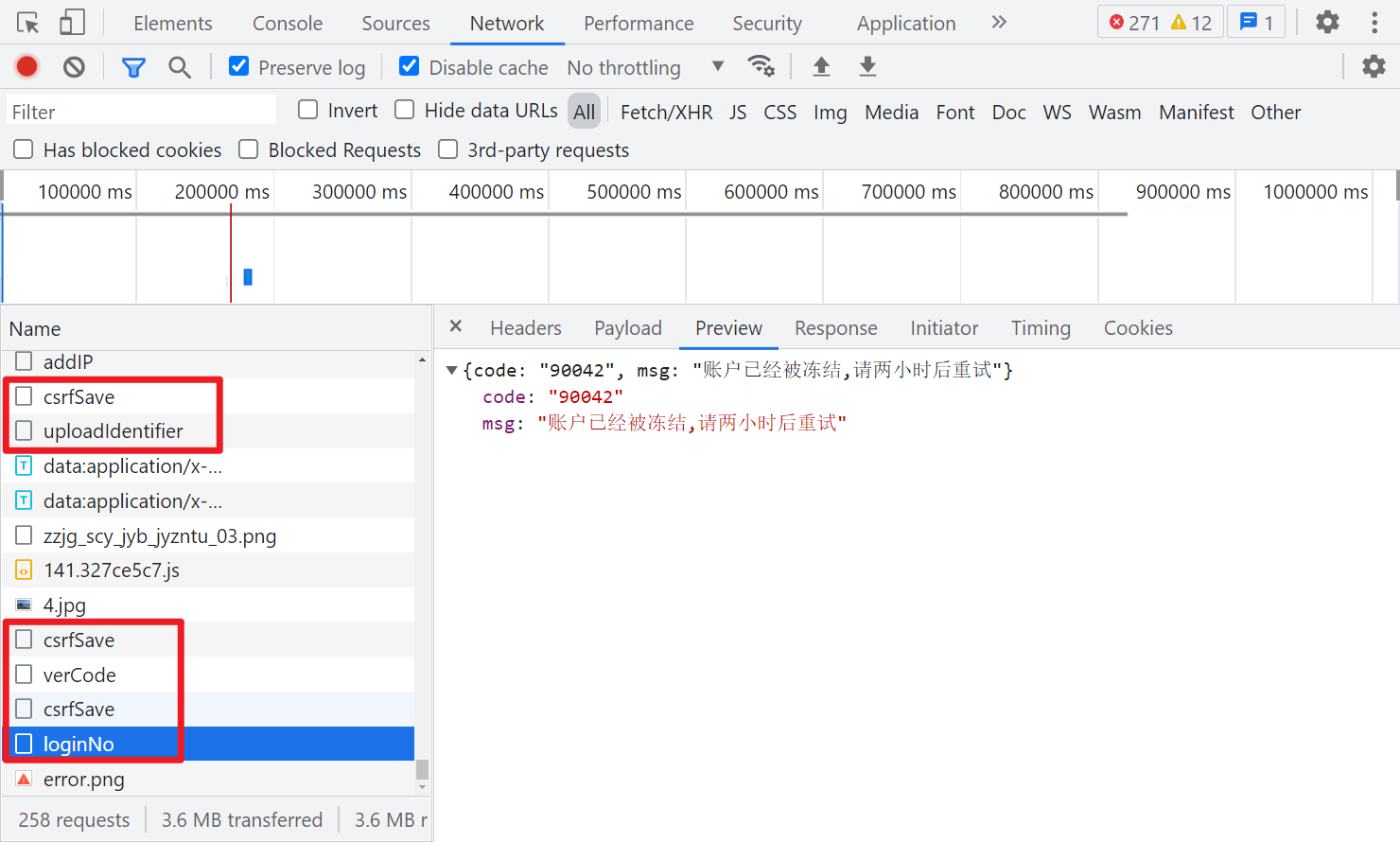
随便输入账号密码点击登陆,抓包发现接口的 Request Headers 有个加密参数 token,Form Data 里 loginNo、loginPwd、code、requestUUID 都是经过加密处理了的,loginNo 和 loginPwd 应该就是用户名密码了,由于登录前需要过一下滑动验证码,因此可以猜测另外两个参数与验证码有关,不过仅从抓包来看,另外两个参数类似于 uuid 的格式,不太像验证码的参数。
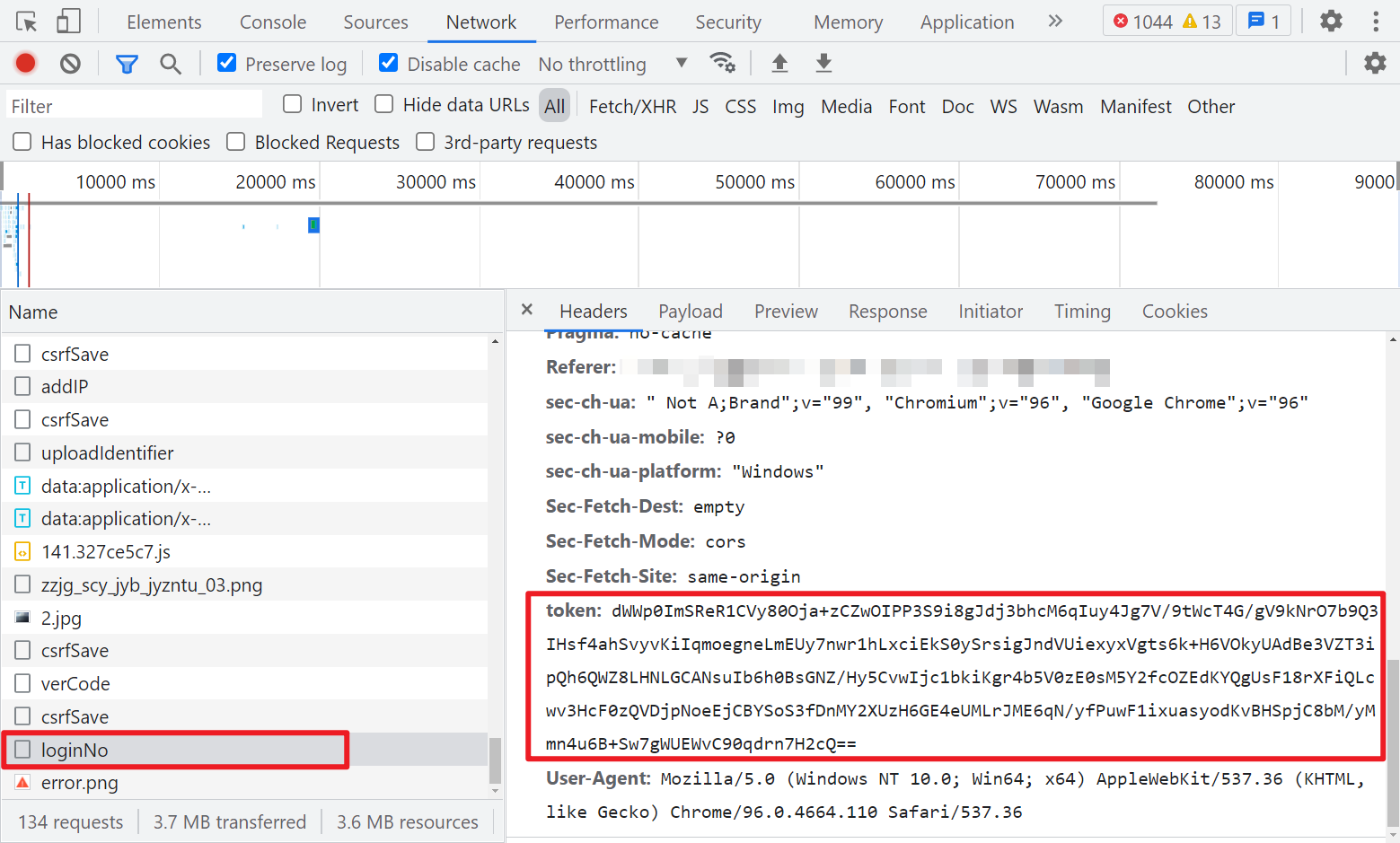
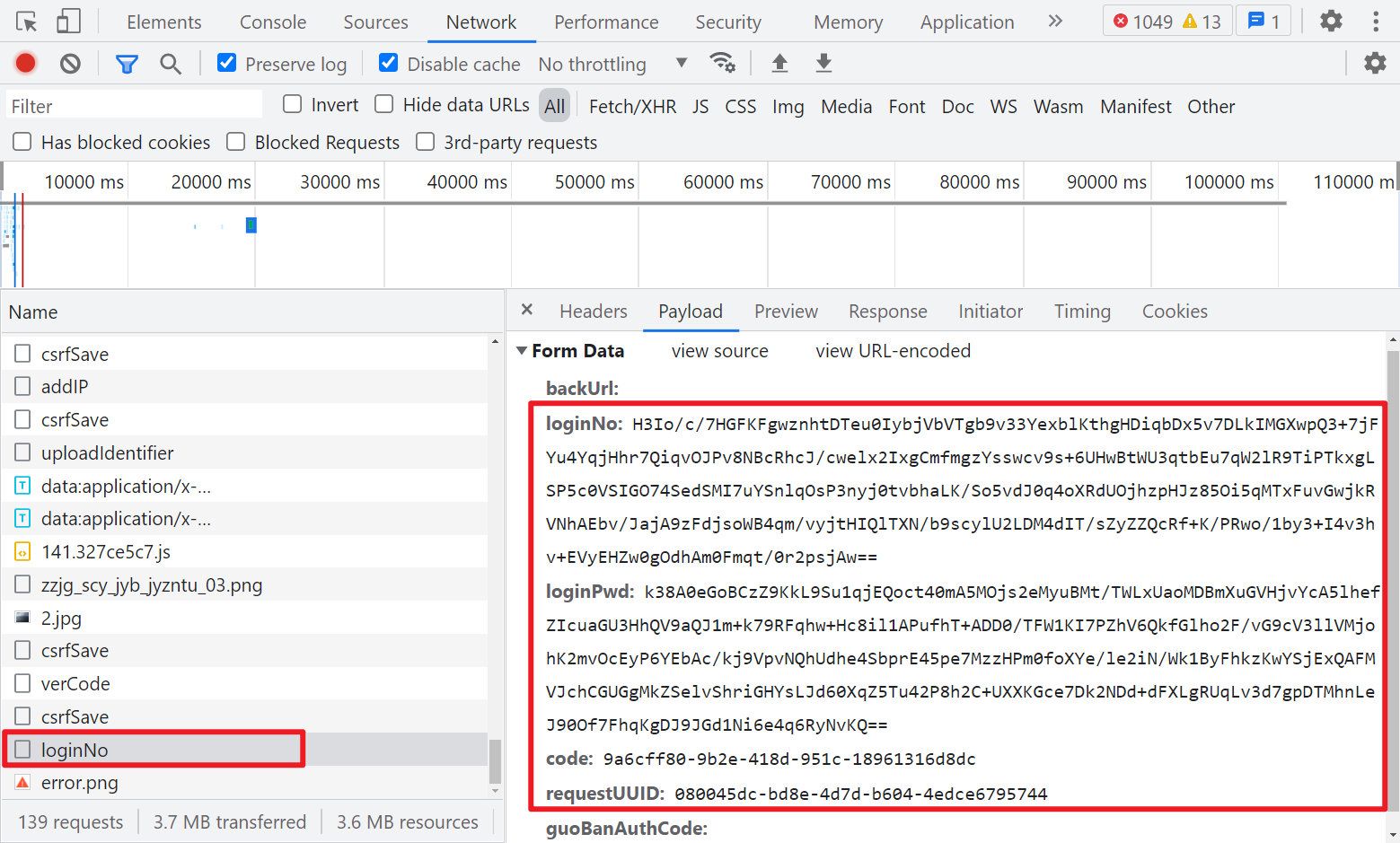
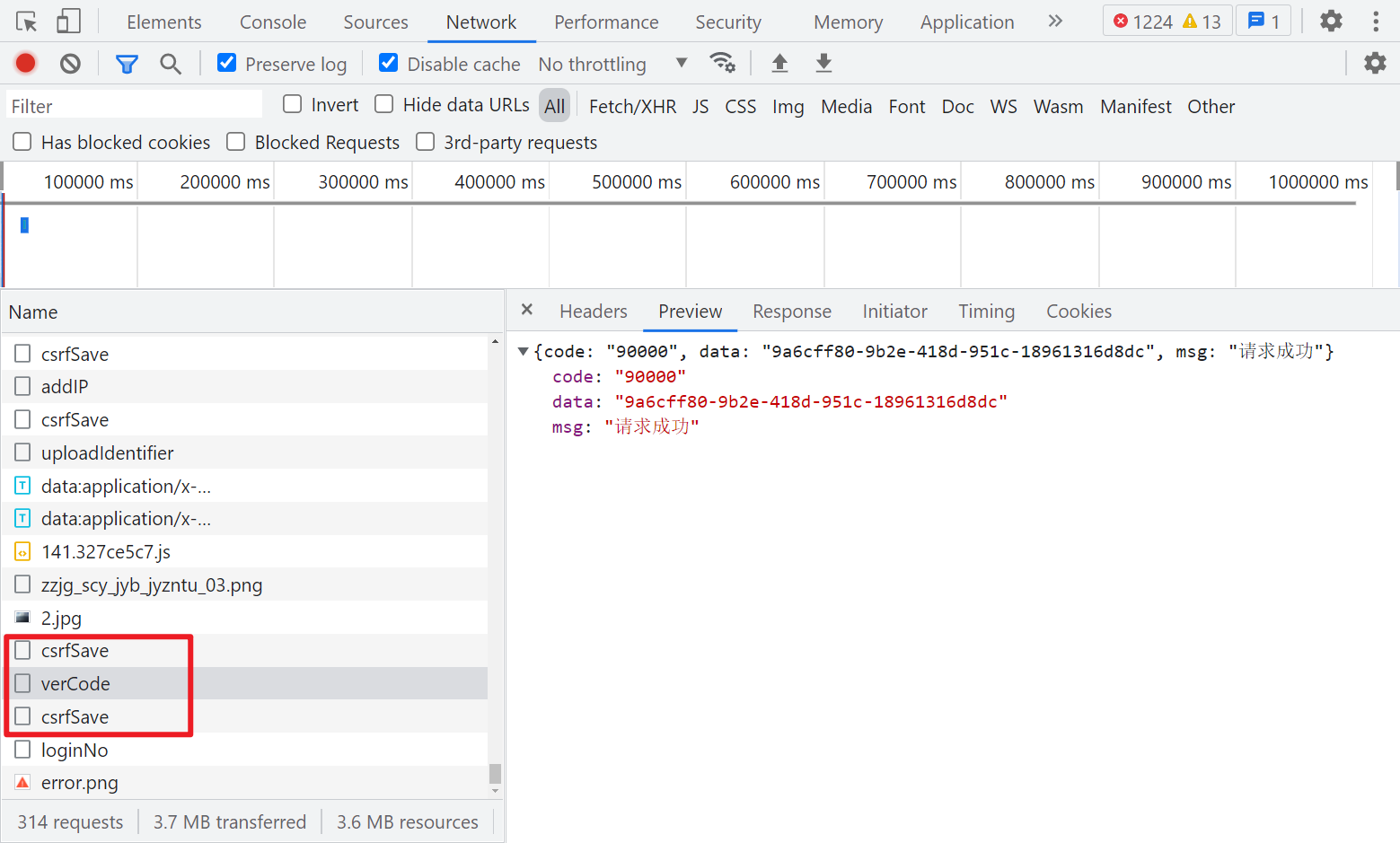
另外可以注意到登陆前,有两次 csrfSave 和一次 verCode 的请求,正常请求成功就会返回一个 JSON,里面有个 data 参数,后面应该是会用到的。
参数逆向
Form Data
先看 Form Data,搜索任意一个参数,比如 loginNo,很容易在 login.js 里找到加密的地方,用户名和密码都经过了 encrypt 这个函数进行加密,backUrl 这个值,是利用 localStorage 属性,从浏览器储存的键值对的数据里取的,为空也不影响。
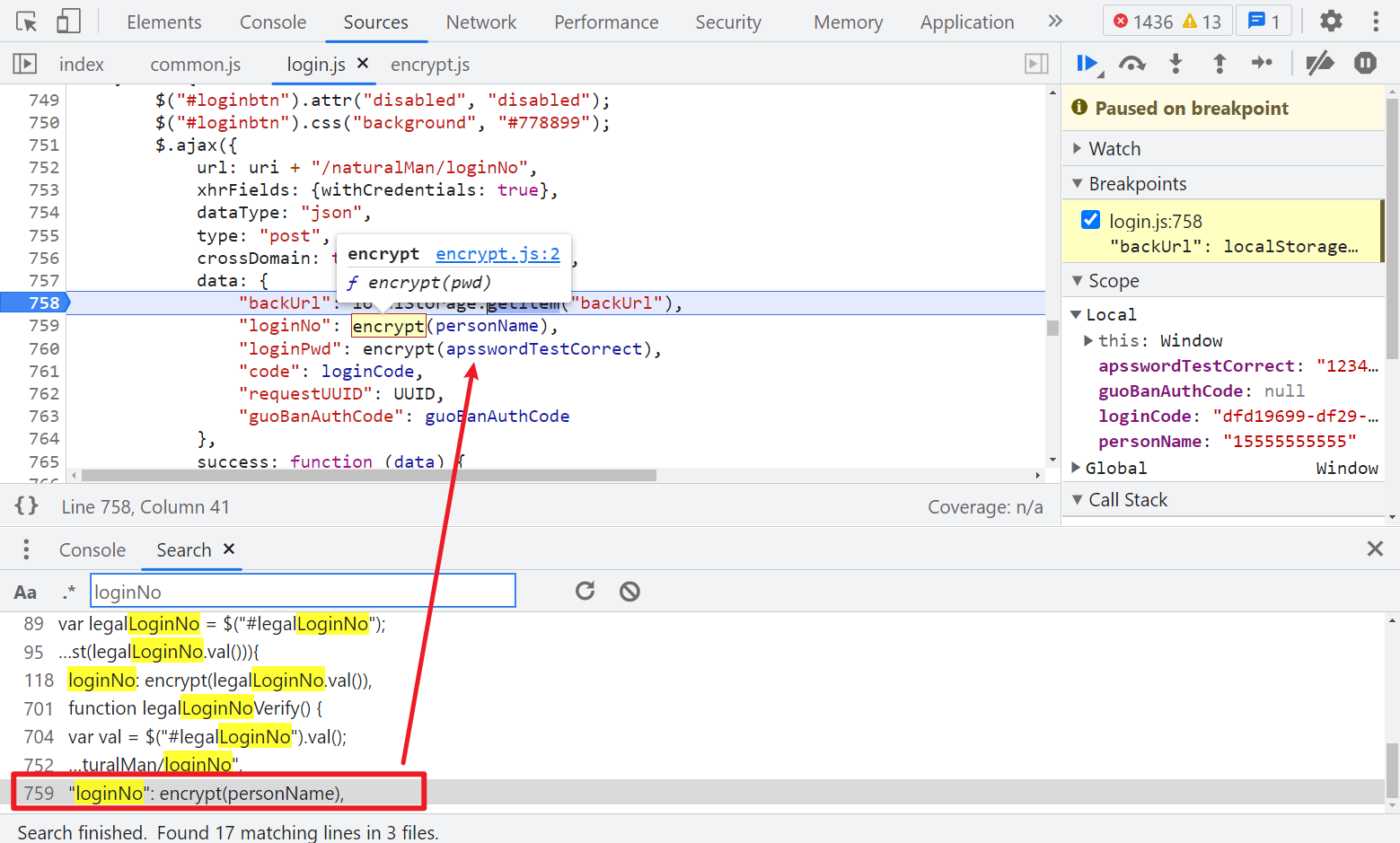
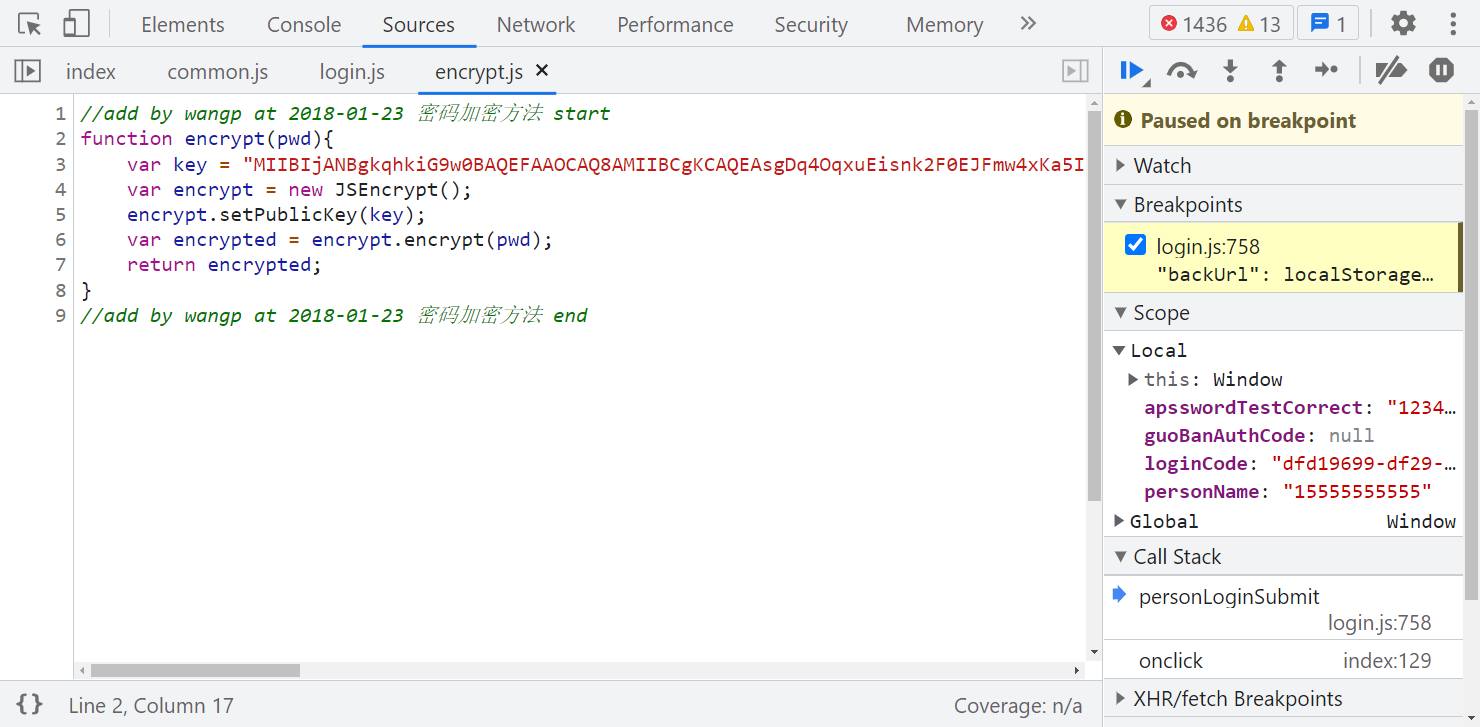
跟进 encrypt,可以看到用到了 JSEncrypt,标准的 RSA 加密:
再看看 loginCode,直接搜索这个值,可以看到是 verCode 这个请求返回的:
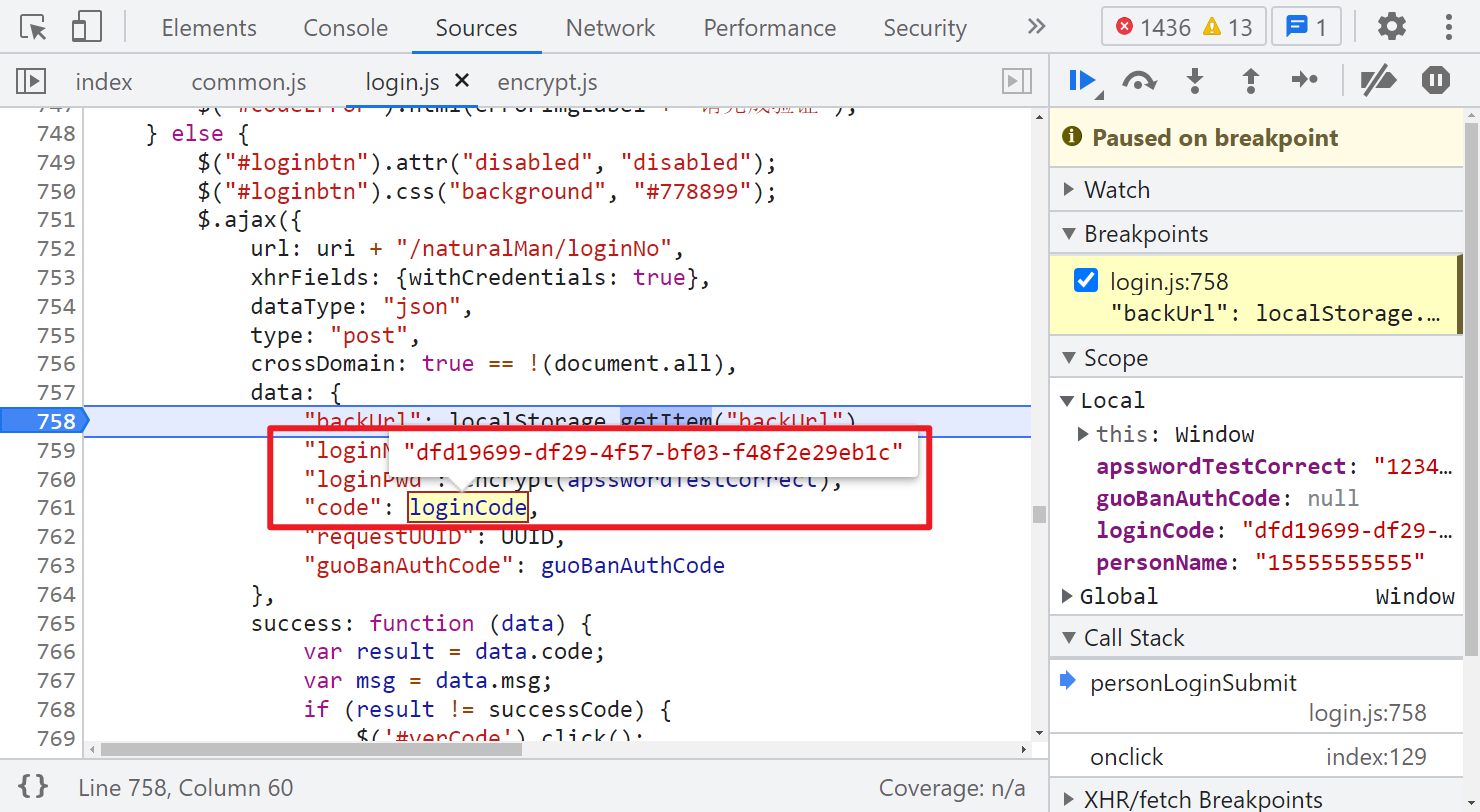
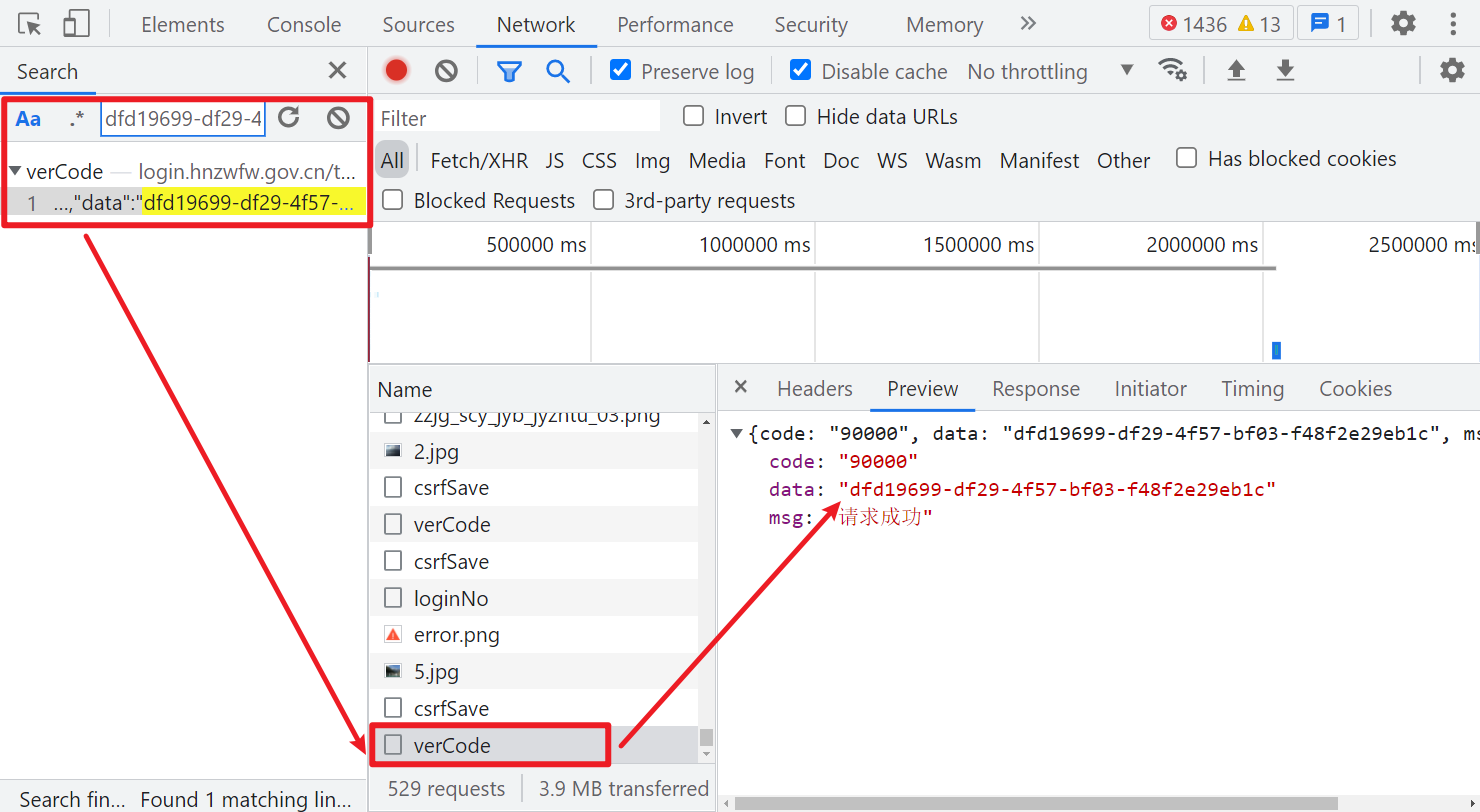
然后再看看 requestUUID,其值就是个 UUID,直接在当前文件(login.js)里搜索,可以看到定义的地方,有个 uploadUUID() 方法,就是在设置 UUID 的值,方法里面是向一个 uploadIdentifier 的接口发送了 post 请求:
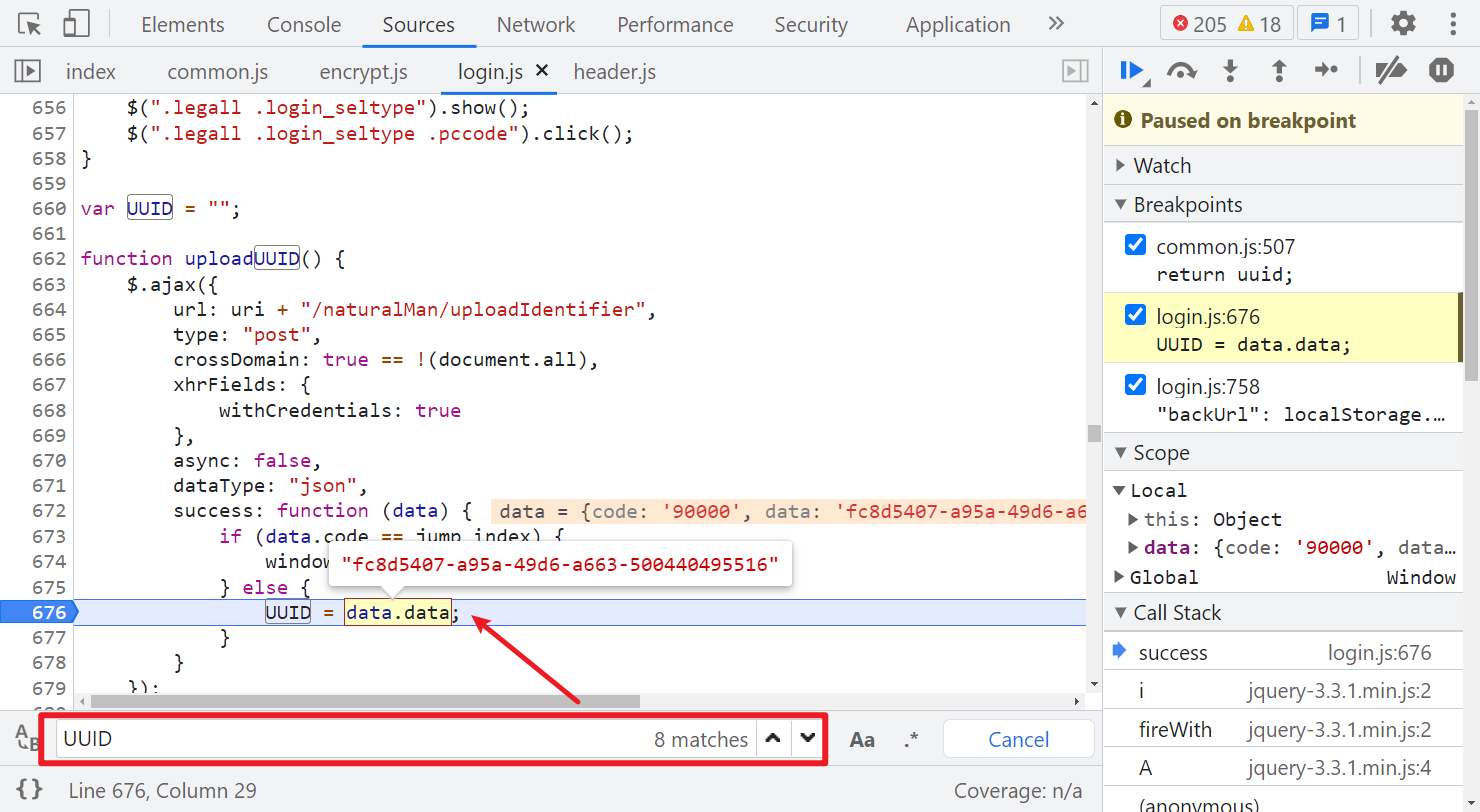
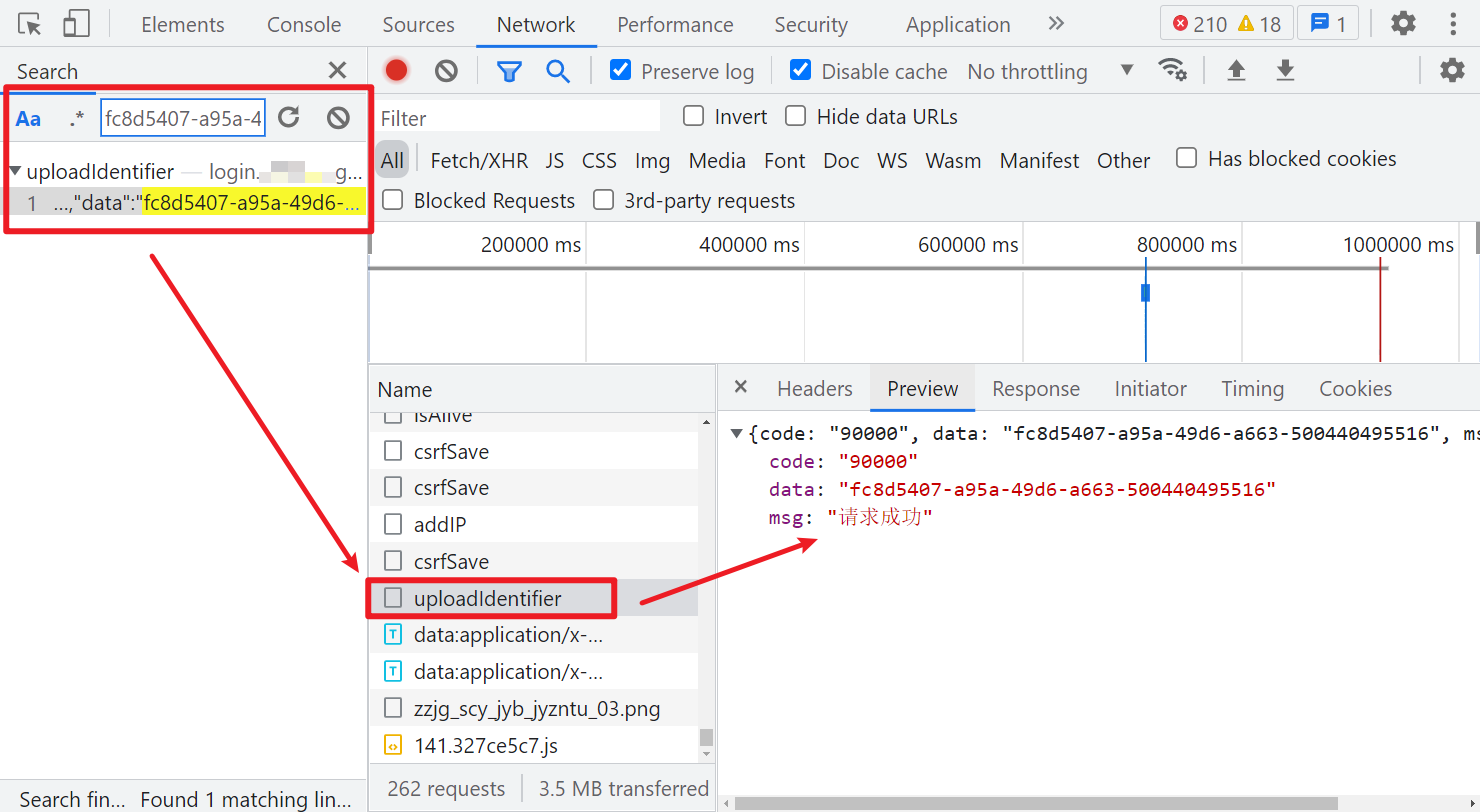
这里注意,如果你直接全局搜索 UUID 的话,还可以在 common.js 里搜索到一个方法,经过测试,直接使用这个方法生成一个 uuid 也是可以请求通过的,这网站可能不严谨,不会严格检测这个值。
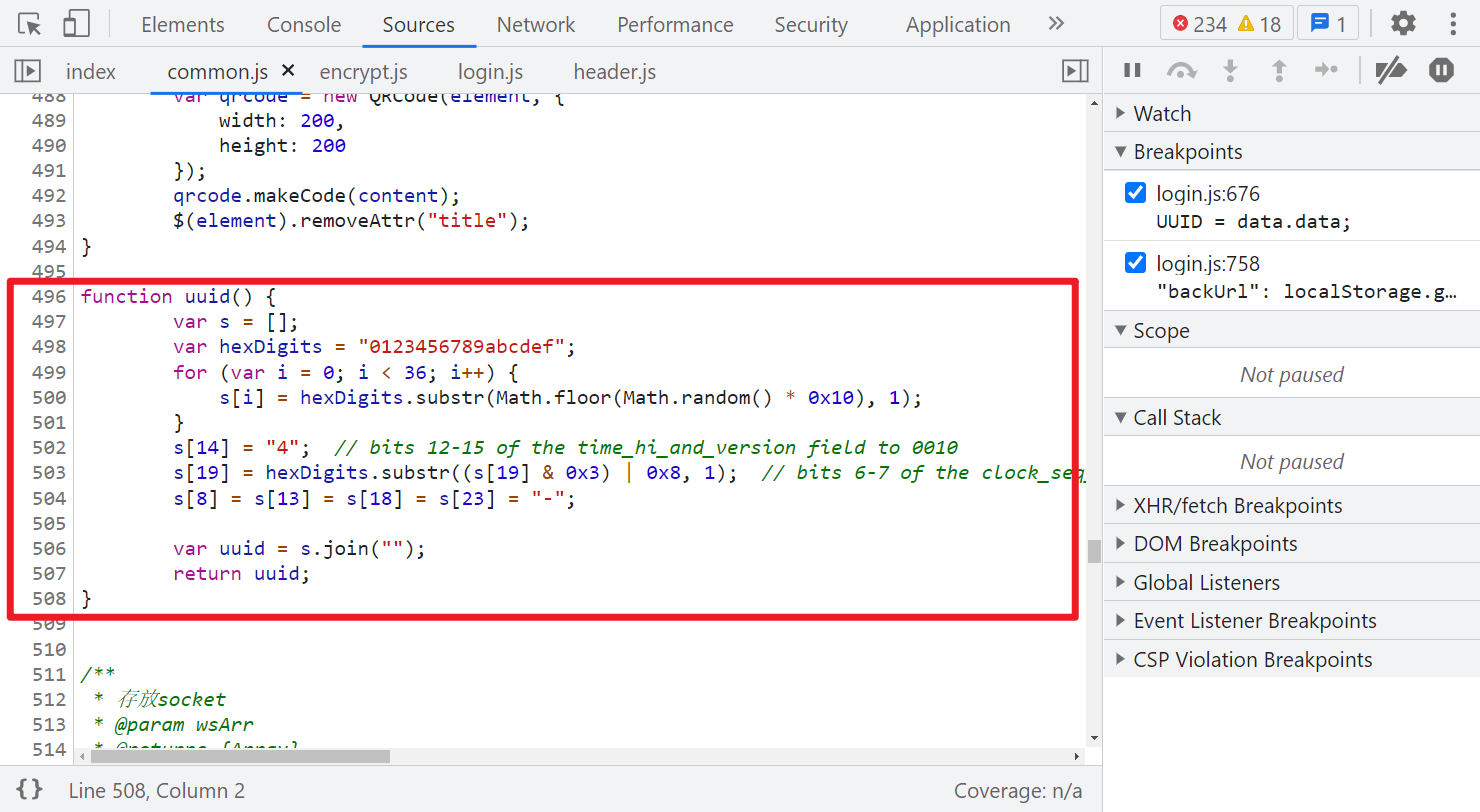
Request Headers
Form Data 解决了,再来看看 Request Headers 里的 token 参数,由于它存在于请求头里,所以我们可以通过 Hook 的方式来查找其生成的地方:
(function () {
var org = window.XMLHttpRequest.prototype.setRequestHeader;
window.XMLHttpRequest.prototype.setRequestHeader = function (key, value) {
if (key == 'token') {
debugger;
}
return org.apply(this, arguments);
};
})();
这里我们也可以直接搜索 token、setRequestHeader 之类的关键字,很容易在 common.js 里找到,当我们点击登陆,会有一个 csrfSave 的请求,返回的 data 值,经过 encrypt 方法加密后就是登陆请求头的 token 了。
这个 token 参数在很多请求中都会用到,生成方法是一样的,都是拿 csrfSave 请求返回的 data 经过 RSA 加密后得到的:
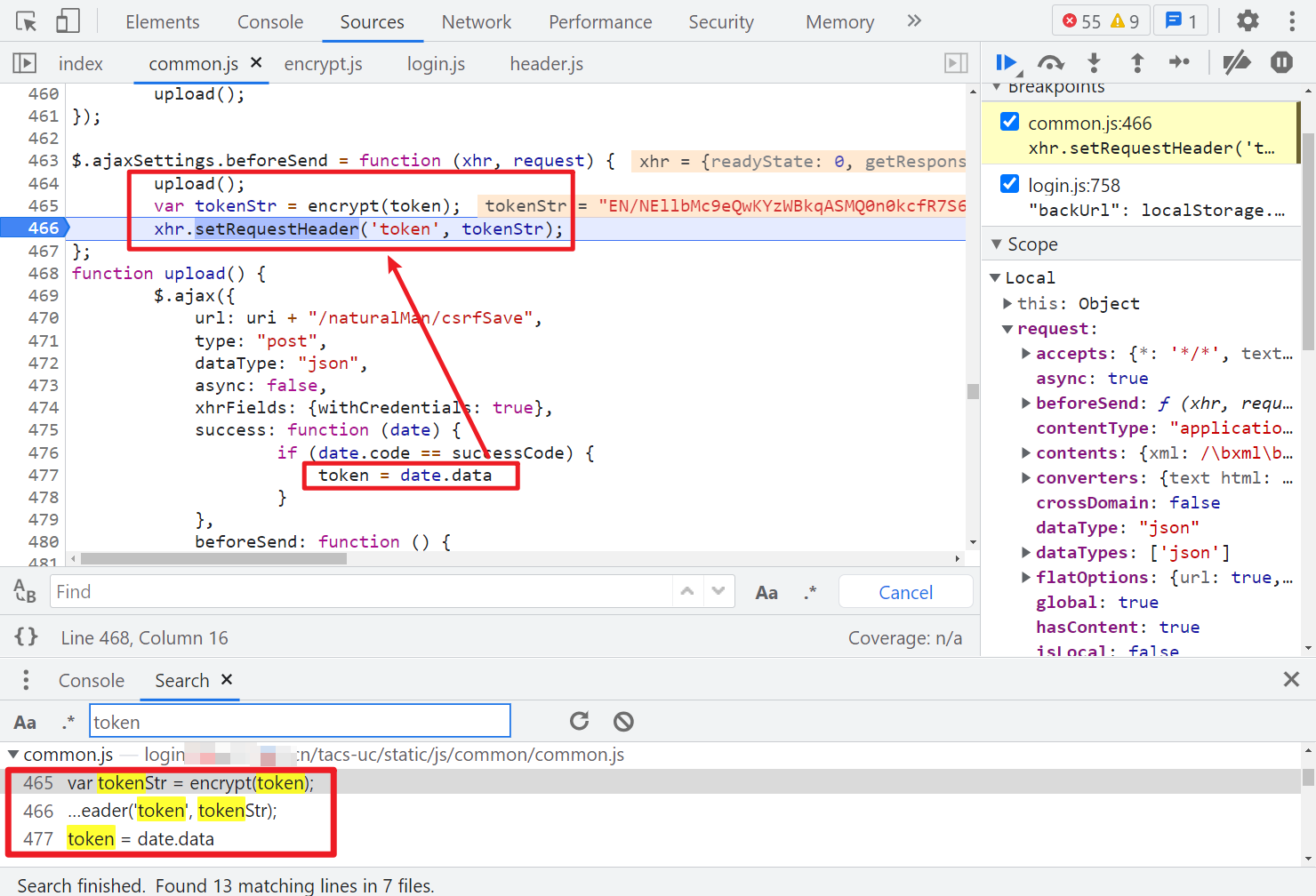
另外注意一点的就是,以上所有涉及到网络请求的,Cookie 都需要一个 SESSION 值,这个可以在首次访问页面获取到:
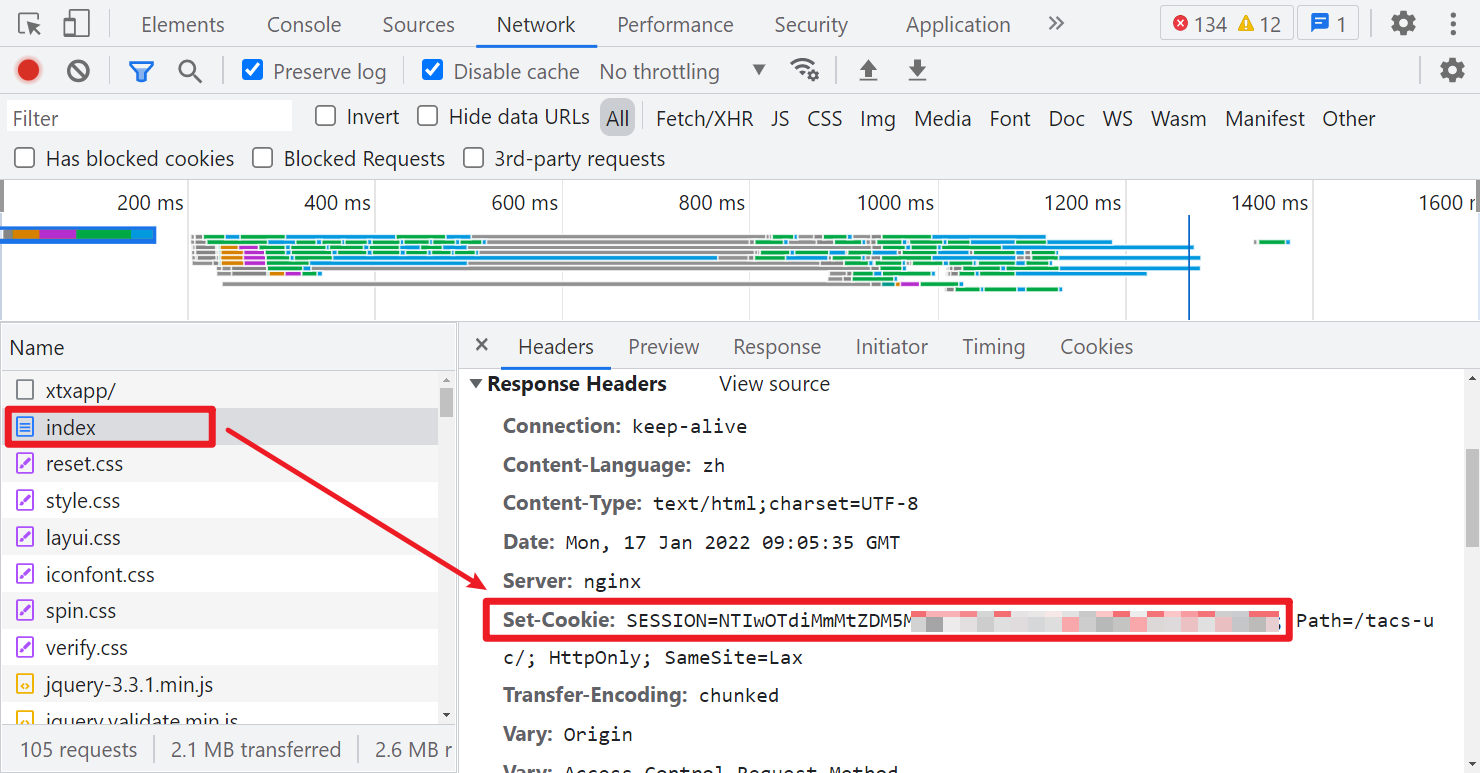
登陆流程
这里我们理一下登陆的流程:
- 访问首页拿 Cookie 中的 SESSION 值;
- 访问 csrfSave,拿到一个 data 值,经过 RSA 加密得到 token,携带 token 访问 uploadIdentifier,拿到 uuid;
- 访问 csrfSave,拿到一个 data 值,经过 RSA 加密得到 token,携带 token 访问 verCode,拿到 code;
- 访问 csrfSave,拿到一个 data 值,经过 RSA 加密得到 token,携带 token、uuid、code 和加密后的账号密码,访问 loginNo 登录。
这里第2步,也可以直接用 Python 或者 JS 生成一个 uuid,网站校验不严格,也可以通过,另外可以看出这个滑块是假的,通过代码可以无视滑块进行登录。
完整代码
GitHub 关注 K 哥爬虫,持续分享爬虫相关代码!欢迎 star !https://github.com/kgepachong/
以下只演示部分关键代码,不能直接运行! 完整代码仓库地址:https://github.com/kgepachong/crawler/
JavaScript 加密代码
/* ==================================
# @Time : 2022-01-11
# @Author : 微信公众号:K哥爬虫
# @FileName: encrypt.js
# @Software: PyCharm
# ================================== */
JSEncrypt = require("jsencrypt")
function encrypt(pwd){
var key = "MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEAsgDq4OqxuEisnk2F0EJFmw4xKa5IrcqEYHvqxPs2CHEg2kolhfWA2SjNuGAHxyDDE5MLtOvzuXjBx/5YJtc9zj2xR/0moesS+Vi/xtG1tkVaTCba+TV+Y5C61iyr3FGqr+KOD4/XECu0Xky1W9ZmmaFADmZi7+6gO9wjgVpU9aLcBcw/loHOeJrCqjp7pA98hRJRY+MML8MK15mnC4ebooOva+mJlstW6t/1lghR8WNV8cocxgcHHuXBxgns2MlACQbSdJ8c6Z3RQeRZBzyjfey6JCCfbEKouVrWIUuPphBL3OANfgp0B+QG31bapvePTfXU48TYK0M5kE+8LgbbWQIDAQAB";
var encrypt = new JSEncrypt();
encrypt.setPublicKey(key);
var encrypted = encrypt.encrypt(pwd);
return encrypted;
}
// 测试样例
// console.log(encrypt("15555555555"))
Python 登录代码
# ==================================
# @Time : 2022-01-11
# @Author : 微信公众号:K哥爬虫
# @FileName: hnzww_login.py
# @Software: PyCharm
# ==================================
import execjs
import requests
cookies = {}
UA = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36"
with open("encrypt.js", encoding="utf-8") as f:
js = execjs.compile(f.read())
def csrf_save():
url = "脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler"
headers = {"User-Agent": UA}
response = requests.post(url=url, headers=headers, cookies=cookies).json()
data = response["data"]
return data
def get_session():
url = "脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler"
headers = {"User-Agent": UA}
response = requests.get(url=url, headers=headers)
cookies.update(response.cookies.get_dict())
def get_uuid():
url = "脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler"
headers = {
"User-Agent": UA,
"token": js.call("encrypt", csrf_save())
}
response = requests.post(url=url, headers=headers, cookies=cookies).json()
uuid = response["data"]
return uuid
def ver_code():
url = "脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler"
headers = {
"User-Agent": UA,
"token": js.call("encrypt", csrf_save())
}
response = requests.post(url=url, headers=headers, cookies=cookies).json()
data = response["data"]
return data
def login(phone, pwd, code, uuid):
url = "脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler"
headers = {
"User-Agent": UA,
"token": js.call("encrypt", csrf_save())
}
data = {
"backUrl": "",
"loginNo": js.call("encrypt", phone),
"loginPwd": js.call("encrypt", pwd),
"code": code,
"requestUUID": uuid,
"guoBanAuthCode": ""
}
response = requests.post(url=url, headers=headers, cookies=cookies, data=data)
print(response.json())
def main():
phone = input("请输入账号:")
pwd = input("请输入密码:")
get_session()
uuid = get_uuid()
code = ver_code()
login(phone, pwd, code, uuid)
if __name__ == '__main__':
main()
-
【JS逆向百例】爱疯官网登录逆向分析12-23
-
Vue3教程:新手入门到实践应用12-21
-
VueRouter4教程:从入门到实践12-21
-
Vue3项目实战:从入门到上手12-20
-
Vue3项目实战:新手入门教程12-20
-
VueRouter4项目实战:新手入门教程12-20
-
如何实现JDBC和jsp的关系?-icode9专业技术文章分享12-20
-
Vue项目中实现TagsView标签栏导航的简单教程12-20
-
Vue3入门教程:从零开始搭建你的第一个Vue3项目12-20
-
从零开始学习vueRouter4:基础教程12-20
-
Vuex4课程:新手入门到上手实战全攻略12-20
-
Vue3资料:新手入门及初级教程12-20
-
Vuex4入门指南:轻松掌握Vue状态管理12-20
-
Vue3学习:从入门到实践的简单教程12-20
-
Vue学习:从入门到简单项目实战12-20
