Java教程
超详细的编码实战,让你的springboot应用识别图片中的行人、汽车、狗子、喵星人(JavaCV+YOLO4)

欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
本篇概览
- 在[《三分钟:极速体验JAVA版目标检测(YOLO4)》]一文中,咱们体验了YOLO4强大的物体识别能力,如下图,原图中的狗子、人、马都被识别并标注出来了:

-
如果您之前对深度学习和YOLO、darknet等有过了解,相信您会产生疑问:Java能实现这些?
-
没错,今天咱们就从零开始,开发一个SpringBoot应用实现上述功能,该应用名为yolo-demo
-
让SpringBoot应用识别图片中的物体,其关键在如何使用已经训练好的神经网络模型,好在OpenCV集成的DNN模块可以加载和使用YOLO4模型,我们只要找到使用OpenCV的办法即可
-
我这里的方法是使用JavaCV库,因为JavaCV本身封装了OpenCV,最终可以使用YOLO4模型进行推理,依赖情况如下图所示:
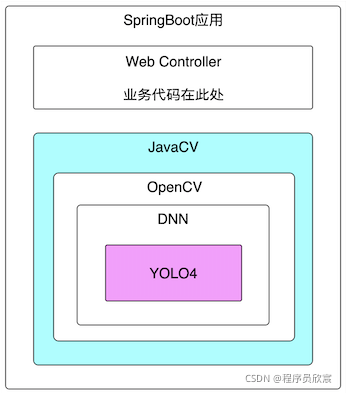
关键技术
-
本篇涉及到JavaCV、OpenCV、YOLO4等,从上图可以看出JavaCV已将这些做了封装,包括最终推理时所用的模型也是YOLO4官方提前训练好的,咱们只要知道如何使用JavaCV的API即可
-
YOVO4的paper在此:https://arxiv.org/pdf/2004.10934v1.pdf
版本信息
- 这里给出我的开发环境供您参考:
- 操作系统:Ubuntu 16(MacBook Pro也可以,版本是11.2.3,macOS Big Sur)
- docker:20.10.2 Community
- java:1.8.0_211
- springboot:2.4.8
- javacv:1.5.6
- opencv:4.5.3
实战步骤
-
在正式动手前,先把本次实战的步骤梳理清楚,后面按部就班执行即可;
-
为了减少环境和软件差异的影响,让程序的运行调试更简单,这里会把SpringBoot应用制作成docker镜像,然后在docker环境运行,所以,整个实战简单来说分为三步 :制做基础镜像、开发SpringBoot应用、把应用做成镜像,如下图:
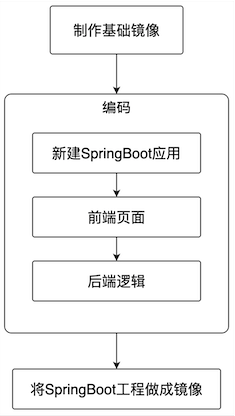
-
上述流程中的第一步制做基础镜像,已经在[《制作JavaCV应用依赖的基础Docker镜像(CentOS7+JDK8+OpenCV4)》]一文中详细介绍,咱们直接使用镜像bolingcavalry/opencv4.5.3:0.0.1即可,接下来的内容将会聚焦SpringBoot应用的开发;
-
这个SpringBoot应用的功能很单一,如下图所示:
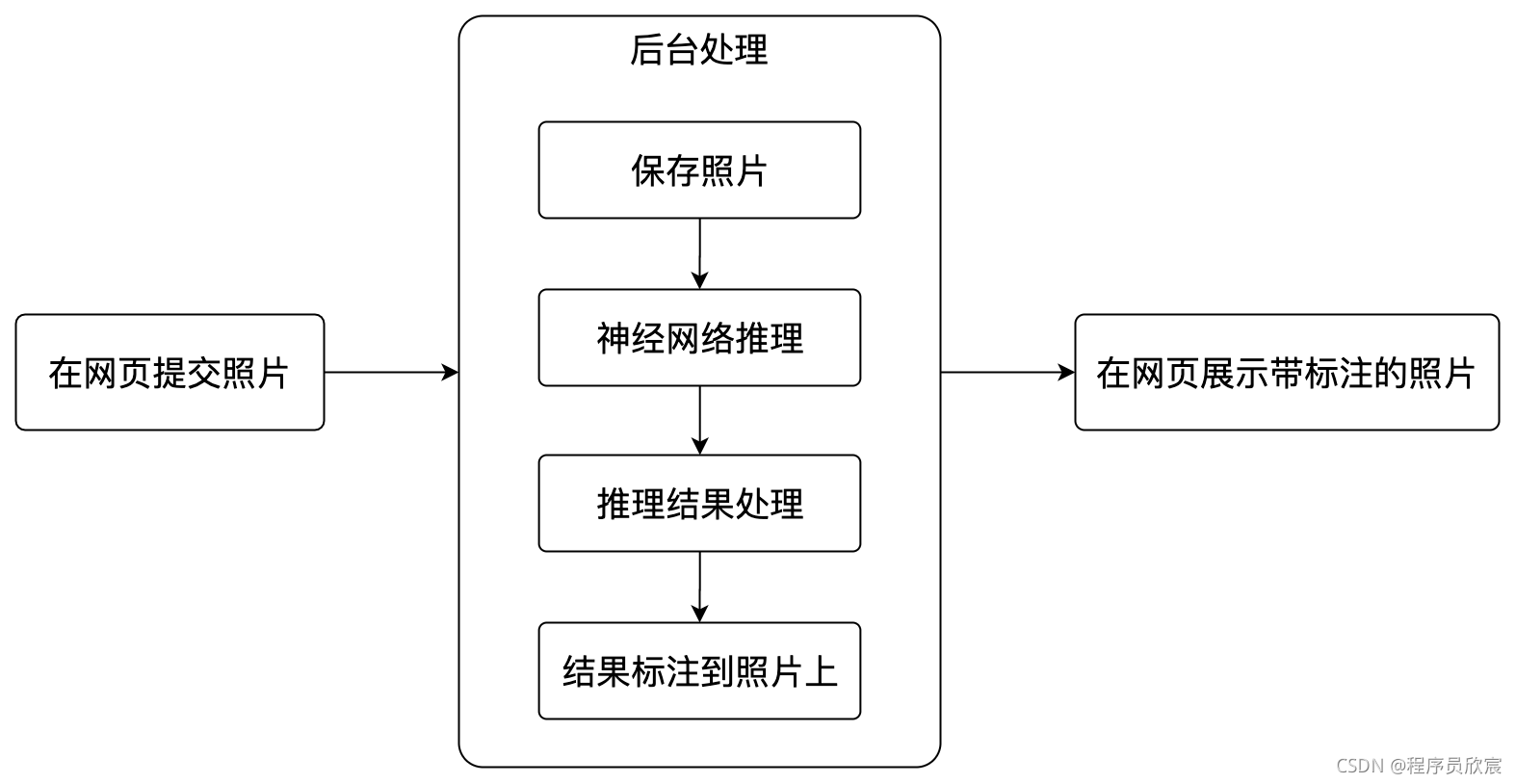
- 整个开发过程涉及到这些步骤:提交照片的网页、神经网络初始化、文件处理、图片检测、处理检测结果、在图片上标准识别结果、前端展示图片等,完整步骤已经整理如下图:
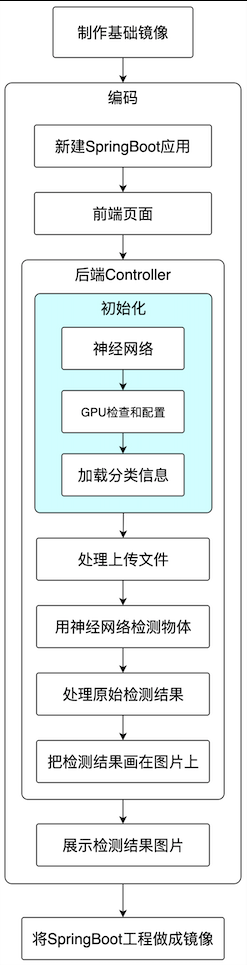
- 内容很丰富,收获也不会少,更何况前文已确保可以成功运行,那么,别犹豫啦,咱们开始吧!
源码下载
- 本篇实战中的完整源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
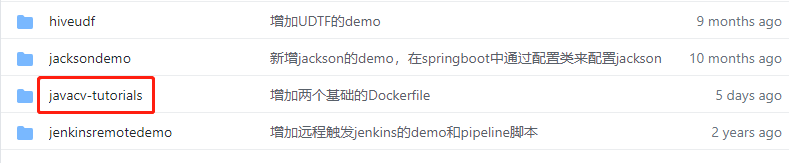
- 这个git项目中有多个文件夹,本篇的源码在javacv-tutorials文件夹下,如下图红框所示:
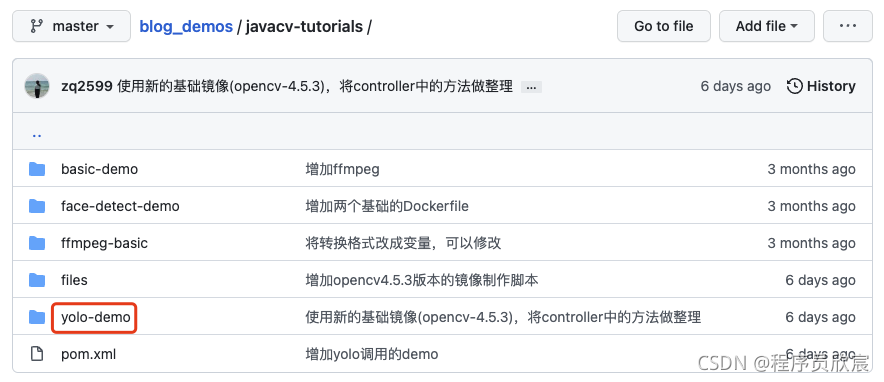
- javacv-tutorials里面有多个子工程,今天的代码在yolo-demo工程下:
新建SpringBoot应用
- 新建名为yolo-demo的maven工程,首先这是个标准的SpringBoot工程,其次添加了javacv的依赖库,pom.xml内容如下,重点是javacv、opencv等库的依赖和准确的版本匹配:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bolingcavalry</groupId>
<version>1.0-SNAPSHOT</version>
<artifactId>yolo-demo</artifactId>
<packaging>jar</packaging>
<properties>
<java.version>1.8</java.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<maven-compiler-plugin.version>3.6.1</maven-compiler-plugin.version>
<springboot.version>2.4.8</springboot.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<maven.compiler.encoding>UTF-8</maven.compiler.encoding>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${springboot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!--FreeMarker模板视图依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>javacv-platform</artifactId>
<version>1.5.6</version>
</dependency>
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>opencv-platform-gpu</artifactId>
<version>4.5.3-1.5.6</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- 如果父工程不是springboot,就要用以下方式使用插件,才能生成正常的jar -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<mainClass>com.bolingcavalry.yolodemo.YoloDemoApplication</mainClass>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
- 接下来的重点是配置文件application.properties,如下可见,除了常见的spring配置,还有几个文件路径配置,实际运行时,这些路径都要存放对应的文件给程序使用,这些文件如何获取稍后会讲到:
### FreeMarker 配置 spring.freemarker.allow-request-override=false #Enable template caching.启用模板缓存。 spring.freemarker.cache=false spring.freemarker.check-template-location=true spring.freemarker.charset=UTF-8 spring.freemarker.content-type=text/html spring.freemarker.expose-request-attributes=false spring.freemarker.expose-session-attributes=false spring.freemarker.expose-spring-macro-helpers=false #设置面板后缀 spring.freemarker.suffix=.ftl # 设置单个文件最大内存 spring.servlet.multipart.max-file-size=100MB # 设置所有文件最大内存 spring.servlet.multipart.max-request-size=1000MB # 自定义文件上传路径 web.upload-path=/app/images # 模型路径 # yolo的配置文件所在位置 opencv.yolo-cfg-path=/app/model/yolov4.cfg # yolo的模型文件所在位置 opencv.yolo-weights-path=/app/model/yolov4.weights # yolo的分类文件所在位置 opencv.yolo-coconames-path=/app/model/coco.names # yolo模型推理时的图片宽度 opencv.yolo-width=608 # yolo模型推理时的图片高度 opencv.yolo-height=608
- 启动类YoloDemoApplication.java:
package com.bolingcavalry.yolodemo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class YoloDemoApplication {
public static void main(String[] args) {
SpringApplication.run(YoloDemoApplication.class, args);
}
}
- 工程已建好,接下来开始编码,先从前端页面开始
前端页面
-
只要涉及到前端,欣宸一般都会发个自保声明:请大家原谅欣宸不入流的前端水平,页面做得我自己都不忍直视,但为了功能的完整,请您忍忍,也不是不能用,咱们总要有个地方提交照片并且展示识别结果不是?
-
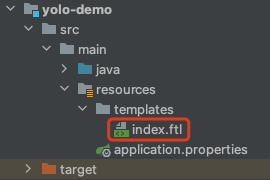
新增名为index.ftl的前端模板文件,位置如下图红框:
- index.ftl的内容如下,可见很简单,有选择和提交文件的表单,也有展示结果的脚本,还能展示后台返回的提示信息,嗯嗯,这就够用了:
<!DOCTYPE html>
<head>
<meta charset="UTF-8" />
<title>图片上传Demo</title>
</head>
<body>
<h1 >图片上传Demo</h1>
<form action="fileUpload" method="post" enctype="multipart/form-data">
<p>选择检测文件: <input type="file" name="fileName"/></p>
<p><input type="submit" value="提交"/></p>
</form>
<#--判断是否上传文件-->
<#if msg??>
<span>${msg}</span><br><br>
<#else >
<span>${msg!("文件未上传")}</span><br>
</#if>
<#--显示图片,一定要在img中的src发请求给controller,否则直接跳转是乱码-->
<#if fileName??>
<#--<img src="/show?fileName=${fileName}" style="width: 100px"/>-->
<img src="/show?fileName=${fileName}"/>
<#else>
<#--<img src="/show" style="width: 200px"/>-->
</#if>
</body>
</html>
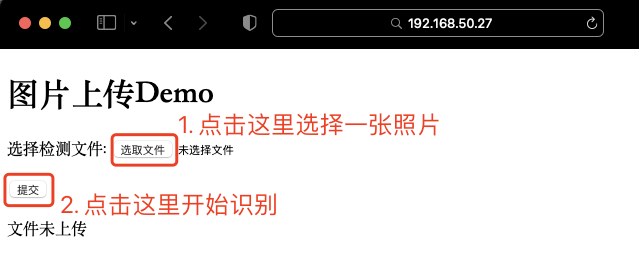
- 页面的效果,就像下面这样:
后端逻辑:初始化
-
为了保持简单,所有后端逻辑放在一个java文件中:YoloServiceController.java,按照前面梳理的流程,咱们先看初始化部分
-
首先是成员变量和依赖
private final ResourceLoader resourceLoader;
@Autowired
public YoloServiceController(ResourceLoader resourceLoader) {
this.resourceLoader = resourceLoader;
}
@Value("${web.upload-path}")
private String uploadPath;
@Value("${opencv.yolo-cfg-path}")
private String cfgPath;
@Value("${opencv.yolo-weights-path}")
private String weightsPath;
@Value("${opencv.yolo-coconames-path}")
private String namesPath;
@Value("${opencv.yolo-width}")
private int width;
@Value("${opencv.yolo-height}")
private int height;
/**
* 置信度门限(超过这个值才认为是可信的推理结果)
*/
private float confidenceThreshold = 0.5f;
private float nmsThreshold = 0.4f;
// 神经网络
private Net net;
// 输出层
private StringVector outNames;
// 分类名称
private List<String> names;
- 接下来是初始化方法init,可见会从之前配置的几个文件路径中加载神经网络所需的配置、训练模型等文件,关键方法是readNetFromDarknet的调用,还有就是检查是否有支持CUDA的设备,如果有就在神经网络中做好设置:
@PostConstruct
private void init() throws Exception {
// 初始化打印一下,确保编码正常,否则日志输出会是乱码
log.error("file.encoding is " + System.getProperty("file.encoding"));
// 神经网络初始化
net = readNetFromDarknet(cfgPath, weightsPath);
// 检查网络是否为空
if (net.empty()) {
log.error("神经网络初始化失败");
throw new Exception("神经网络初始化失败");
}
// 输出层
outNames = net.getUnconnectedOutLayersNames();
// 检查GPU
if (getCudaEnabledDeviceCount() > 0) {
net.setPreferableBackend(opencv_dnn.DNN_BACKEND_CUDA);
net.setPreferableTarget(opencv_dnn.DNN_TARGET_CUDA);
}
// 分类名称
try {
names = Files.readAllLines(Paths.get(namesPath));
} catch (IOException e) {
log.error("获取分类名称失败,文件路径[{}]", namesPath, e);
}
}
处理上传文件
- 前端将二进制格式的图片文件提交上来后如何处理?这里整理了一个简单的文件处理方法upload,会将文件保存在服务器的指定位置,后面会调用:
/**
* 上传文件到指定目录
* @param file 文件
* @param path 文件存放路径
* @param fileName 源文件名
* @return
*/
private static boolean upload(MultipartFile file, String path, String fileName){
//使用原文件名
String realPath = path + "/" + fileName;
File dest = new File(realPath);
//判断文件父目录是否存在
if(!dest.getParentFile().exists()){
dest.getParentFile().mkdir();
}
try {
//保存文件
file.transferTo(dest);
return true;
} catch (IllegalStateException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return false;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return false;
}
}
物体检测
- 准备工作都完成了,来写最核心的物体检测代码,这些代码放在yolo-demo应用处理web请求的方法中,如下所示,可见这里只是个大纲,将推理、结果处理、图片标注等功能串起来形成完整流程,但是不涉及每个具体功能的细节:
@RequestMapping("fileUpload")
public String upload(@RequestParam("fileName") MultipartFile file, Map<String, Object> map){
log.info("文件 [{}], 大小 [{}]", file.getOriginalFilename(), file.getSize());
// 文件名称
String originalFileName = file.getOriginalFilename();
if (!upload(file, uploadPath, originalFileName)){
map.put("msg", "上传失败!");
return "forward:/index";
}
// 读取文件到Mat
Mat src = imread(uploadPath + "/" + originalFileName);
// 执行推理
MatVector outs = doPredict(src);
// 处理原始的推理结果,
// 对检测到的每个目标,找出置信度最高的类别作为改目标的类别,
// 还要找出每个目标的位置,这些信息都保存在ObjectDetectionResult对象中
List<ObjectDetectionResult> results = postprocess(src, outs);
// 释放资源
outs.releaseReference();
// 检测到的目标总数
int detectNum = results.size();
log.info("一共检测到{}个目标", detectNum);
// 没检测到
if (detectNum<1) {
// 显示图片
map.put("msg", "未检测到目标");
// 文件名
map.put("fileName", originalFileName);
return "forward:/index";
} else {
// 检测结果页面的提示信息
map.put("msg", "检测到" + results.size() + "个目标");
}
// 计算出总耗时,并输出在图片的左上角
printTimeUsed(src);
// 将每一个被识别的对象在图片框出来,并在框的左上角标注该对象的类别
markEveryDetectObject(src, results);
// 将添加了标注的图片保持在磁盘上,并将图片信息写入map(给跳转页面使用)
saveMarkedImage(map, src);
return "forward:/index";
}
- 这里已经可以把整个流程弄明白了,接下来展开每个细节
用神经网络检测物体
-
由上面的代码可见,图片被转为Mat对象后(OpenCV中的重要数据结构,可以理解为矩阵,里面存放着图片每个像素的信息),被送入doPredict方法,该方法执行完毕后就得到了物体识别的结果
-
细看doPredict方法,可见核心是用blobFromImage方法得到四维blob对象,再将这个对象送给神经网络去检测(net.setInput、net.forward)
/**
* 用神经网络执行推理
* @param src
* @return
*/
private MatVector doPredict(Mat src) {
// 将图片转为四维blog,并且对尺寸做调整
Mat inputBlob = blobFromImage(src,
1 / 255.0,
new Size(width, height),
new Scalar(0.0),
true,
false,
CV_32F);
// 神经网络输入
net.setInput(inputBlob);
// 设置输出结果保存的容器
MatVector outs = new MatVector(outNames.size());
// 推理,结果保存在outs中
net.forward(outs, outNames);
// 释放资源
inputBlob.release();
return outs;
}
-
要注意的是,blobFromImage、net.setInput、net.forward这些都是native方法,是OpenCV的dnn模块提供的
-
doPredict方法返回的是MatVector对象,这里面就是检测结果
处理原始检测结果
- 检测结果MatVector对象是个集合,里面有多个Mat对象,每个Mat对象是一个表格,里面有丰富的数据,具体的内容如下图:
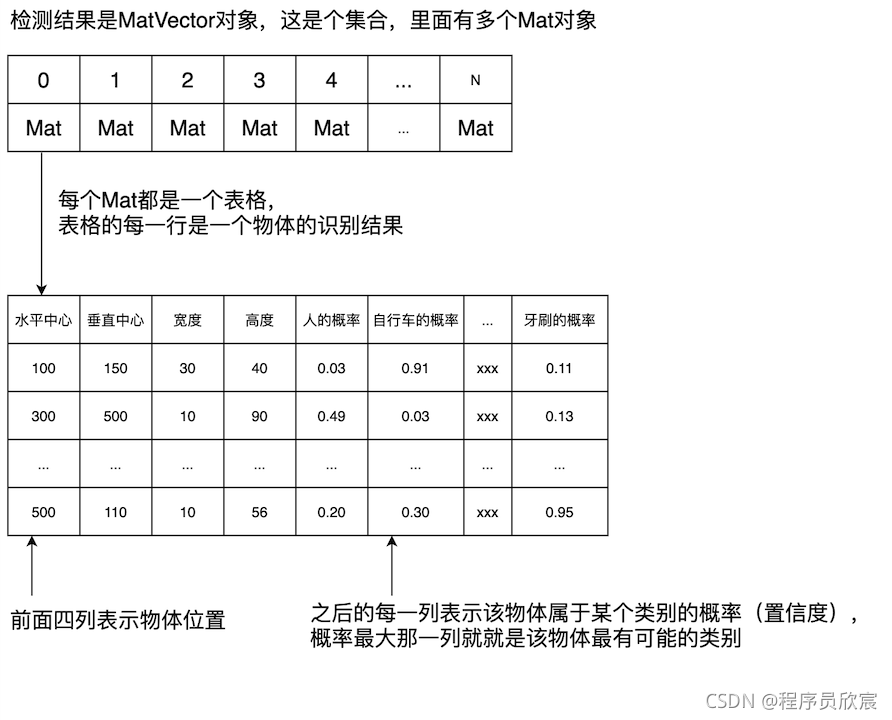
- 看过上图后,相信您对如何处理原始的检测结果已经胸有成竹了,只要从MatVector中逐个取出Mat,把每个Mat当做表格,将表格每一行中概率最大的列找到,此列就是该物体的类别了(至于每一列到底是啥东西,为啥上面表格中第五列是人,第六列是自行车,最后一列是牙刷?这个稍后会讲到):
/**
* 推理完成后的操作
* @param frame
* @param outs
* @return
*/
private List<ObjectDetectionResult> postprocess(Mat frame, MatVector outs) {
final IntVector classIds = new IntVector();
final FloatVector confidences = new FloatVector();
final RectVector boxes = new RectVector();
// 处理神经网络的输出结果
for (int i = 0; i < outs.size(); ++i) {
// extract the bounding boxes that have a high enough score
// and assign their highest confidence class prediction.
// 每个检测到的物体,都有对应的每种类型的置信度,取最高的那种
// 例如检车到猫的置信度百分之九十,狗的置信度百分之八十,那就认为是猫
Mat result = outs.get(i);
FloatIndexer data = result.createIndexer();
// 将检测结果看做一个表格,
// 每一行表示一个物体,
// 前面四列表示这个物体的坐标,后面的每一列,表示这个物体在某个类别上的置信度,
// 每行都是从第五列开始遍历,找到最大值以及对应的列号,
for (int j = 0; j < result.rows(); j++) {
// minMaxLoc implemented in java because it is 1D
int maxIndex = -1;
float maxScore = Float.MIN_VALUE;
for (int k = 5; k < result.cols(); k++) {
float score = data.get(j, k);
if (score > maxScore) {
maxScore = score;
maxIndex = k - 5;
}
}
// 如果最大值大于之前设定的置信度门限,就表示可以确定是这类物体了,
// 然后就把这个物体相关的识别信息保存下来,要保存的信息有:类别、置信度、坐标
if (maxScore > confidenceThreshold) {
int centerX = (int) (data.get(j, 0) * frame.cols());
int centerY = (int) (data.get(j, 1) * frame.rows());
int width = (int) (data.get(j, 2) * frame.cols());
int height = (int) (data.get(j, 3) * frame.rows());
int left = centerX - width / 2;
int top = centerY - height / 2;
// 保存类别
classIds.push_back(maxIndex);
// 保存置信度
confidences.push_back(maxScore);
// 保存坐标
boxes.push_back(new Rect(left, top, width, height));
}
}
// 资源释放
data.release();
result.release();
}
// remove overlapping bounding boxes with NMS
IntPointer indices = new IntPointer(confidences.size());
FloatPointer confidencesPointer = new FloatPointer(confidences.size());
confidencesPointer.put(confidences.get());
// 非极大值抑制
NMSBoxes(boxes, confidencesPointer, confidenceThreshold, nmsThreshold, indices, 1.f, 0);
// 将检测结果放入BO对象中,便于业务处理
List<ObjectDetectionResult> detections = new ArrayList<>();
for (int i = 0; i < indices.limit(); ++i) {
final int idx = indices.get(i);
final Rect box = boxes.get(idx);
final int clsId = classIds.get(idx);
detections.add(new ObjectDetectionResult(
clsId,
names.get(clsId),
confidences.get(idx),
box.x(),
box.y(),
box.width(),
box.height()
));
// 释放资源
box.releaseReference();
}
// 释放资源
indices.releaseReference();
confidencesPointer.releaseReference();
classIds.releaseReference();
confidences.releaseReference();
boxes.releaseReference();
return detections;
}
- 可见代码很简单,就是把每个Mat当做表格来处理,有两处特别的地方要处理:
- confidenceThreshold变量,置信度门限,这里是0.5,如果某一行的最大概率连0.5都达不到,那就相当于已知所有类别的可能性都不大,那就不算识别出来了,所以不会存入detections集合中(不会在结果图片中标注)
- NMSBoxes:分类器进化为检测器时,在原始图像上从多个尺度产生窗口,这就导致下图左侧的效果,同一个人检测了多张人脸,此时用NMSBoxes来保留最优的一个结果

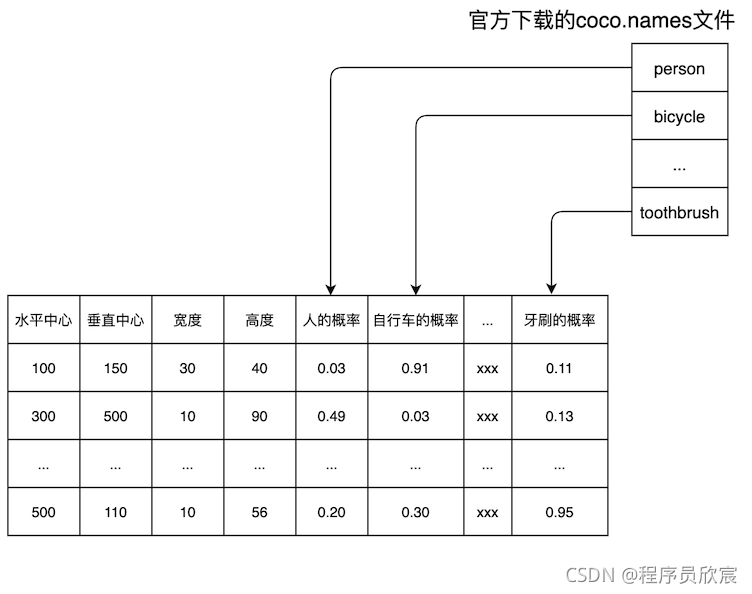
- 现在解释一下Mat对象对应的表格中,每一列到底是什么类别:这个表格是YOLO4的检测结果,所以每一列是什么类别应该由YOLO4来解释,官方提供了名为coco.names的文件,该文件的内容如下图,一共80行,每一行是表示一个类别:

- 此刻聪明的您肯定已经明白Mat表格中的每一列代表什么类别了:Mat表格中的每一列对应coco.names的每一行,如下图:
- postprocess方法执行完毕后,一张照片的识别结果就被放入名为detections的集合中,该集合内的每个元素代表一个识别出的物体,来看看这个元素的数据结构,如下所示,这些数据够我们在照片上标注识别结果了:
@Data
@AllArgsConstructor
public class ObjectDetectionResult {
// 类别索引
int classId;
// 类别名称
String className;
// 置信度
float confidence;
// 物体在照片中的横坐标
int x;
// 物体在照片中的纵坐标
int y;
// 物体宽度
int width;
// 物体高度
int height;
}
把检测结果画在图片上
-
手里有了检测结果,接下来要做的就是将这些结果画在原图上,这样就有了物体识别的效果,画图分两部分,首先是左上角的总耗时,其次是每个物体识别结果
-
先在图片的上角画出本次检测的总耗时,效果如下图所示:

- 负责画出总耗时的是printTimeUsed方法,如下,可见总耗时是用多层网络的总次数除以频率得到的,注意,这不是网页上的接口总耗时,而是神经网络识别物体的总耗时,例外画图的putText是个本地方法,这也是OpenCV的常用方法之一:
/**
* 计算出总耗时,并输出在图片的左上角
* @param src
*/
private void printTimeUsed(Mat src) {
// 总次数
long totalNums = net.getPerfProfile(new DoublePointer());
// 频率
double freq = getTickFrequency()/1000;
// 总次数除以频率就是总耗时
double t = totalNums / freq;
// 将本次检测的总耗时打印在展示图像的左上角
putText(src,
String.format("Inference time : %.2f ms", t),
new Point(10, 20),
FONT_HERSHEY_SIMPLEX,
0.6,
new Scalar(255, 0, 0, 0),
1,
LINE_AA,
false);
}
- 接下来是画出每个物体识别的结果,有了ObjectDetectionResult对象集合,画图就非常简单了:调用画矩形和文本的本地方法即可:
/**
* 将每一个被识别的对象在图片框出来,并在框的左上角标注该对象的类别
* @param src
* @param results
*/
private void markEveryDetectObject(Mat src, List<ObjectDetectionResult> results) {
// 在图片上标出每个目标以及类别和置信度
for(ObjectDetectionResult result : results) {
log.info("类别[{}],置信度[{}%]", result.getClassName(), result.getConfidence() * 100f);
// annotate on image
rectangle(src,
new Point(result.getX(), result.getY()),
new Point(result.getX() + result.getWidth(), result.getY() + result.getHeight()),
Scalar.MAGENTA,
1,
LINE_8,
0);
// 写在目标左上角的内容:类别+置信度
String label = result.getClassName() + ":" + String.format("%.2f%%", result.getConfidence() * 100f);
// 计算显示这些内容所需的高度
IntPointer baseLine = new IntPointer();
Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, baseLine);
int top = Math.max(result.getY(), labelSize.height());
// 添加内容到图片上
putText(src, label, new Point(result.getX(), top-4), FONT_HERSHEY_SIMPLEX, 0.5, new Scalar(0, 255, 0, 0), 1, LINE_4, false);
}
}
展示结果
- 核心工作已经完成,接下来就是保存图片再跳转到展示网页:
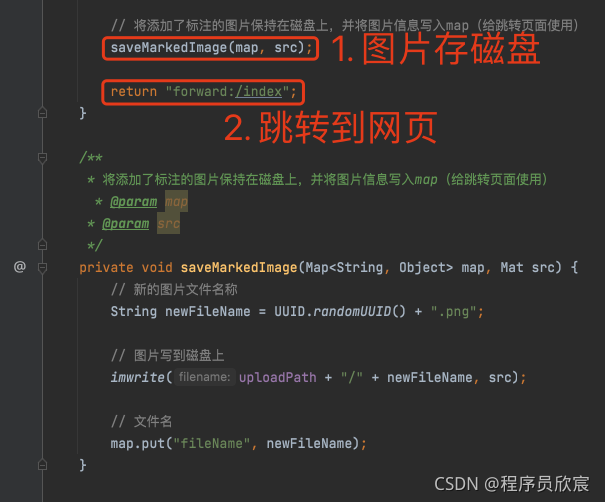
- 至此SpringBoot工程编码完成,接下来要做的就是将整个工程做成docker镜像
将SpringBoot工程做成docker镜像
-
前面[《制作JavaCV应用依赖的基础Docker镜像(CentOS7+JDK8+OpenCV4)》]做好了基础镜像,帮我们准备好了JDK和OpenCV库,使得接下来的操作格外简单,咱们一步一步来
-
先编写Dockerfile文件,Dockerfile文件请放在和pom.xml同一目录,内容如下:
# 基础镜像集成了openjdk8和opencv4.5.3
FROM bolingcavalry/opencv4.5.3:0.0.1
# 创建目录
RUN mkdir -p /app/images && mkdir -p /app/model
# 指定镜像的内容的来源位置
ARG DEPENDENCY=target/dependency
# 复制内容到镜像
COPY ${DEPENDENCY}/BOOT-INF/lib /app/lib
COPY ${DEPENDENCY}/META-INF /app/META-INF
COPY ${DEPENDENCY}/BOOT-INF/classes /app
ENV LANG C.UTF-8
ENV LANGUAGE zh_CN.UTF-8
ENV LC_ALL C.UTF-8
ENV TZ Asia/Shanghai
# 指定启动命令(注意要执行编码,否则日志是乱码)
ENTRYPOINT ["java","-Dfile.encoding=utf-8","-cp","app:app/lib/*","com.bolingcavalry.yolodemo.YoloDemoApplication"]
-
控制台进入pom.xml所在目录,执行命令mvn clean package -U,这是个普通的maven命令,会编译源码,在target目录下生成文件yolo-demo-1.0-SNAPSHOT.jar
-
执行以下命令,可以从jar文件中提取出制作docker镜像所需的内容:
mkdir -p target/dependency && (cd target/dependency; jar -xf ../*.jar)
- 执行以下命令即可构建镜像:
docker build -t bolingcavalry/yolodemo:0.0.1 .
- 构建成功:
will@willMini yolo-demo % docker images REPOSITORY TAG IMAGE ID CREATED SIZE bolingcavalry/yolodemo 0.0.1 d0ef6e734b53 About a minute ago 2.99GB bolingcavalry/opencv4.5.3 0.0.1 d1518ffa4699 6 days ago 2.01GB
-
此刻,具备完整物体识别能力的SpringBoot应用已经开发完成了,还记得application.properties中的那几个文件路径配置么?咱们要去下载这几个文件,有两种下载方式,您二选一即可
-
第一种是从官方下载,从下面这三个地址分别下下载:
- YOLOv4配置文件: https://raw.githubusercontent.com/AlexeyAB/darknet/master/cfg/yolov4.cfg
- YOLOv4权重: https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.weights
- 分类名称: https://raw.githubusercontent.com/AlexeyAB/darknet/master/data/coco.names
-
第二种是从csdn下载(无需积分),上述三个文件我已打包放在此:https://download.csdn.net/download/boling_cavalry/33229838
-
上述两种方式无论哪种,最终都会得到三个文件:yolov4.cfg、yolov4.weights、coco.names,请将它们放在同一目录下,我是放在这里:/home/will/temp/202110/19/model
-
新建一个目录用来存放照片,我这里新建的目录是:/home/will/temp/202110/19/images,注意要确保该目录可以读写
最终目录结构如下所示:
/home/will/temp/202110/19/
├── images
└── model
├── coco.names
├── yolov4.cfg
└── yolov4.weights
- 万事俱备,执行以下命令即可运行服务:
sudo docker run \ --rm \ --name yolodemo \ -p 8080:8080 \ -v /home/will/temp/202110/19/images:/app/images \ -v /home/will/temp/202110/19/model:/app/model \ bolingcavalry/yolodemo:0.0.1
-
服务运行起来后,操作过程和效果与[《三分钟:极速体验JAVA版目标检测(YOLO4)》]一文完全相同,就不多赘述了
-
至此,整个物体识别的开发实战就完成了,Java在工程化方面的便利性,再结合深度学习领域的优秀模型,为咱们解决视觉图像问题增加了一个备选方案,如果您是一位对视觉和图像感兴趣的Java程序员,希望本文能给您一些参考
我是欣宸,期待与您一同畅游Java世界…
-
2025 蛇年,J 人直播带货内容审核团队必备的办公软件有哪 6 款?01-10
-
高效运营背后的支柱:文档管理优化指南01-10
-
年末压力山大?试试优化你的文档管理01-10
-
跨部门协作中的进度追踪重要性解析01-10
-
总结 JavaScript 中的变体函数调用方式01-10
-
HR团队如何通过数据驱动提升管理效率?6个策略01-10
-
WBS实战指南:如何一步步构建高效项目管理框架?01-10
-
实现精准执行:团队协作新方法01-10
-
如何使用工具提升活动策划团队的工作效率?几个必备工具推荐01-10
-
WiX 标签使用介绍:打造专业安装程序的利器01-10
-
服装跨境电商SOP模板:优化运营效率的实战指南01-10
-
单行键盘:用 Java 解决键盘输入时间问题01-10
-
如何在市场推广活动中确保任务按时完成?5个进度管理技巧01-10
-
提升信息化工作效率的上下级分工策略01-10
-
灵活应对市场变化:经纪人如何高效协作01-10
