Java教程
技术分析 | 通过DML语句浅谈binlog和redo log

- GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
1. 导言
我们在采用InnoDB引擎的情况下,编写SQL语句WHERE条件的时候,可以通过AND操作符来提高数据的过滤能力,当然,在使用AND操作符也有许多需要注意的地方,就好比一条更新语句:
mysql>update testtable set price = 52.0,name = 'test_name';
本意是将表内对应字段重置为指定信息,可是现在不小心写成了:
mysql>update testtable set price = 52.0 and name = 'test_name';
这个时候,我们查看表发现:
mysql> select * from testtable; +----+----------+------------+ | id | name | price | +----+----------+------------+ | 1 | old_name | 0.00 | | 2 | old_name | 0.00 | +----+----------+------------+
显然,系统会把AND当做判断条件进行逻辑判断,这里所有列都不满足条件,所以结果为0。此时,我们可以利用事务回滚特性,回滚这个update,而为了更好地理解,我们需要重新来看看这一条update语句
2. binlog和redo log
现有一条SQL语句:
mysql>update testtable set price = price + 1 where id = 5;
我们知道,这条语句在分析器是进行词法和语法解析,并且知道这是一条更新语句。并由优化器决定要使用id这个索引。然后,执行器负责具体执行,找到这一行,然后更新。说到更新流程,说到更新操作,我们不得不提到两个日志模块:binlog和redo log
2.1 binlog
先来说一说binlog,该日志存在于Server层次中,是使用存储引擎都可以使用的日志模块,binlog是逻辑日志,记录的是这个语句的原始逻辑,比如“给id=5这一行的price字段值加1”
binlog的日志文件是可以追加写入的。“追加写入”是指binlog日志文件写到一定大小后会切换到下一个文件进行写入,可以设置sync_binlog为1,让每次事务的binlog都持久化保存到磁盘中
2.2 redo log
而重做日志redo log是MySQL中InnoDB引擎才有的日志,它是物理日志,即记录的内容是“在某个数据页上做了什么修改“
MySQL对于每一次的更新操作如果都需要写进磁盘,然后磁盘也要找到对应的那条记录,然后再更新,过程中的IO成本、查找成本都很高。redo log有效的提升了更新效率
redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,那么总共就可以有4GB的空间去记录我们进行的操作。从头开始写,写到末尾就又回到开头循环写,如下图:
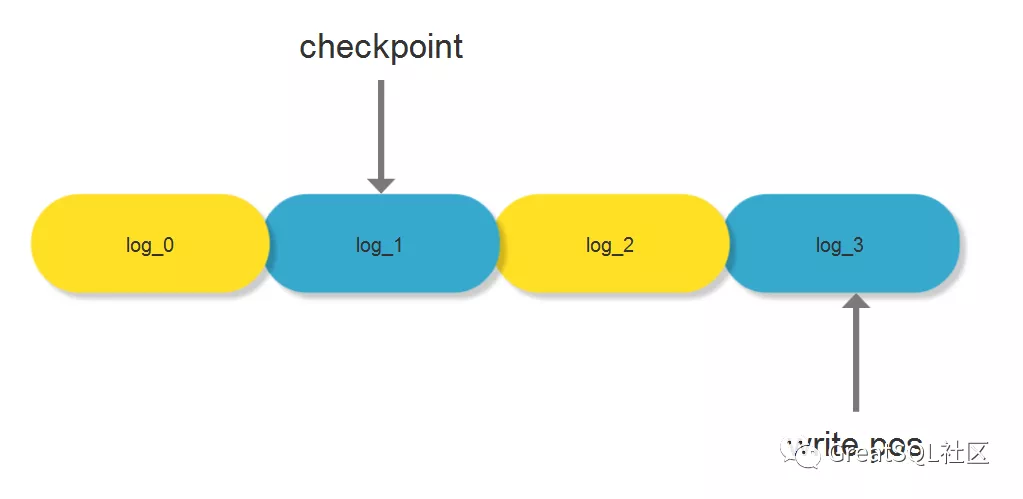
write pos是当前记录的位置,一边写一边后移,写到第log_3文件末尾后就回到log_0文件开头。checkpoint是当前要释放的位置,也是往后推移并且循环的,释放记录前要把记录更新到数据文件。如果write pos追上checkpoint,那就表明全部空间都满了,这时候不能再执行新的更新,得停下来先释放掉一些位置,让checkpoint继续推进
当有一条记录需要更新的时候,InnoDB引擎就会先将数据更新到内存,再把记录写到redo log里面,这个时候更新就算完成了。同时,InnoDB引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做,可以设置 innodb_flush_log_at_trx_commit为1,表示每次事务的redo log都直接持久化到磁盘中
2.3 binlog和redo log的区别

3. InnoDB引擎下模拟执行过程
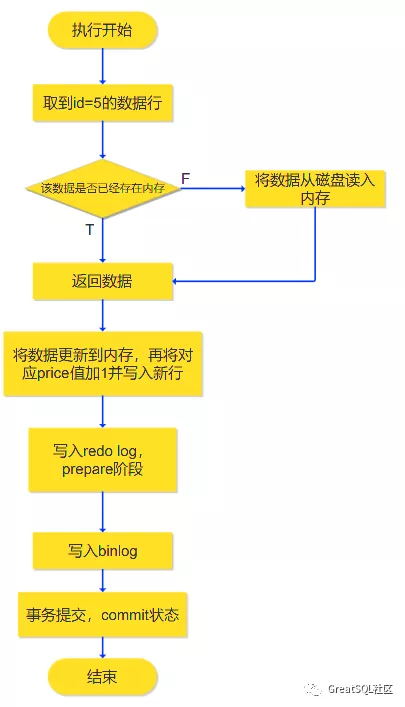
可参考下图:
-
执行器先通过引擎取到id=5的这一行。id是为该表主键,因此引擎根据BTREE索引查找找到id=5的这一行。如果该行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回
-
执行器拿到引擎给的行数据,把price值加上1,得到新的一行数据,再调用引擎接口写入这行新数据
-
引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务。执行器生成这个操作的binlog,并把binlog写入磁盘
-
执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交commit状态,更新完成
Enjoy GreatSQL :)
-
Springboot应用的多环境打包入门11-23
-
Springboot应用的生产发布入门教程11-23
-
Python编程入门指南11-23
-
Java创业入门:从零开始的编程之旅11-23
-
Java创业入门:新手必读的Java编程与创业指南11-23
-
Java对接阿里云智能语音服务入门详解11-23
-
Java对接阿里云智能语音服务入门教程11-23
-
JAVA对接阿里云智能语音服务入门教程11-23
-
Java副业入门:初学者的简单教程11-23
-
JAVA副业入门:初学者的实战指南11-23
-
JAVA项目部署入门:新手必读指南11-23
-
Java项目部署入门:新手必看指南11-23
-
Java项目部署入门:新手必读指南11-23
-
Java项目开发入门:新手必读指南11-23
-
JAVA项目开发入门:从零开始的实用教程11-23
