Python教程
老外最喜欢的美食圣地 是不是你家?python 分析20w数据 「附代码」

一、环境及依赖
语言:python3.8
抓取:selenium
代理:ipide
**注:**想要完整代码的在末尾,注意新手建议慢慢看完。在此提示一下本篇文章的编写步骤:1.获取数据、2.翻译、3.数据清洗、4.切词词权重、5.词云
1.1 selenium 准备
很多人学习蟒蛇,不知道从何学起。 很多人学习python,掌握了基本语法之后,不知道在哪里寻找案例上手。 很多已经做了案例的人,却不知道如何去学习更多高深的知识。 那么针对这三类人,我给大家提供一个好的学习平台,免费获取视频教程,电子书,以及课程的源代码! QQ群:101677771 欢迎加入,一起讨论一起学习!
为了简单,在这里我使用了selenium(菜鸟用selenium,我就是菜鸟)进行数据抓取,并且使用了ipidea的代理(反正有送稳妥),否则等着测试着调试太多次我IP就炸了。
selenium 可使用 pip 进行下载,命令是:
pip install selenium
下载了selenium之后还需要一个driver,需要查看你浏览器版本,仅支持火狐或者谷歌。
在此用谷歌距离,首先点击Chorm浏览器右上角三个点:
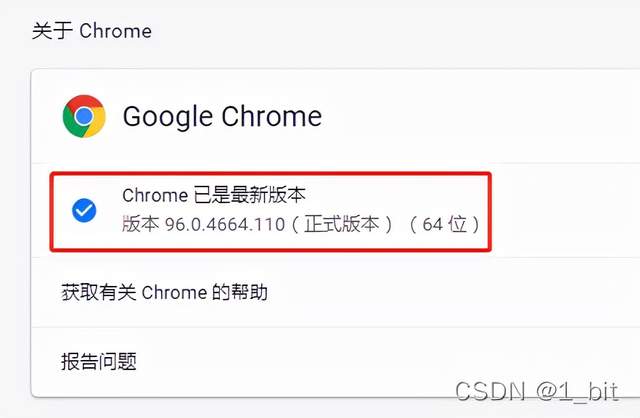
选择帮助,关于google进入 chrome://settings/help 页。随后找到对应的版本号:
接下来进入到driver的下载地址:
http://chromedriver.storage.googleapis.com/index.html
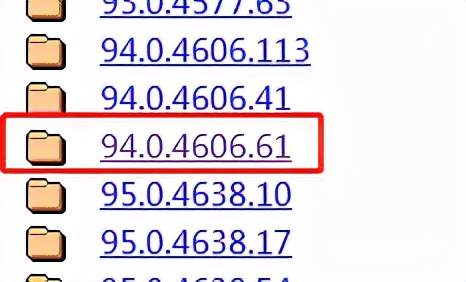
接着在对应的版本号中找到接近的driver进行下载:
随后点击后选择对应的版本即可:
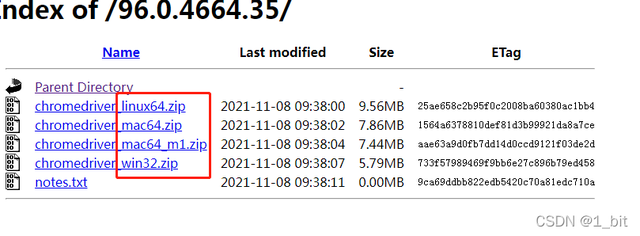
windows就用win32就可以了,下载后解压到一个目录就ok。
接着代理我使用的是IPIDE,官网是这个链接,免费使用就ok,够用了。
二、数据获取
2.1 代理
第一步咱们得拿到数据,那么通过代理去进行获取。
首先创建一个python文件名为 test1,当然名字自己随便取。
接着使用vscode(你可以用你的),头部引入:
from selenium import webdriver import requests,json,time
接着我们写一个头:
#代理
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0'}
基础做好后首先需要获取代理,我们写一个函数名为 ip_:
#代理获取
def ip_():
url=r"http://tiqu.ipidea.io:81/abroad?num=1&type=2&lb=1&sb=0&flow=1®ions=in&port=1"
r = requests.get(url, headers=headers,timeout=3)
data = json.loads(r.content)
ip_=data['data'][0]
return ip_
以上代码中 url 存储的
http://tiqu.ipidea.io:81/abroad?num=1&type=2&lb=1&sb=0&flow=1®ions=in&port=1
为代理获取的链接,有些小伙伴可能获取的时候会失败,原因是没有设置当前ip为白名单。
设置白名单的方式很简单,通过链接在末尾替换自己的白名单就可以了:
https://api.ipidea.net/index/index/save_white?neek=***&appkey=***************************&white=白名单ip
自己的白名单添加链接在
https://www.ipidea.net/getapi:
如果我公开出来我基本上大家都可以用我的了,所以打个码。
我们继续回到函数 ip_()中,r = requests.get(url, headers=headers,timeout=3) 将会获取到代理ip地址,接着我使用了 json 进行转化:data = json.loads(r.content),最终返回了 ip 地址。IP 获取的方式过于简单就不再讲解了。
接下来获取代理与组成 ip 代理字符串:
ip=ip_()#ip获取 proxy_str="http://"+str(ip['ip'])+':'+str(ip['port'])#ip proxy 组合
接着使用 webdriver 对谷歌浏览器设置代理:
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=%s" % proxy_str)
options.add_argument('--ignore-certificate-errors')
options.add_argument('-ignore -ssl-errors')
以上代码中 options.add_argument 为了给浏览器添加代理,之后的两句话只是为了忽略某些错误,当然你不加基本上也没事。
2.2 抓取数据
接着创建一个变量url存储需要抓取页的链接:
url='https://www.quora.com/topic/Chinese-Food?q=Chinese%20food'
接下来创建 谷歌浏览器 对象:
driver = webdriver.Chrome(executable_path=r'C:\webdriver\chromedriver.exe',options=options) driver.get(url) input()
webdriver.Chrome 中的 executable_path 为指定下载 driver 的地址,option 为代理的配置。
创建好后 driver 你就可以理解成是 Chrome 谷歌浏览器对象了,使用谷歌浏览器打开一个指定页面只需要使用 get方法,再get 方法内传递一个 url。
由于我们发现该页面是浏览器滑动到底部自动刷新,此时我们只需要使用循环重复一直往下滑动就可以了:
for i in range(0,500):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(10)
以上循环中的代码 driver.execute_script 表示执行script命令,其中 window.scrollTo(0,
document.body.scrollHeight); 就是对应的滑动命令。每次滑动过后就给他歇一下,不然一直划效果不是很好,所以就使用 sleep 休息10s 等待加载。
接着我们获取页面中一下一块块的数据:
为了防止遗漏出什么不好饿内容,在此我打了一下码。
此时我们可以使用右键检查,打开源码:
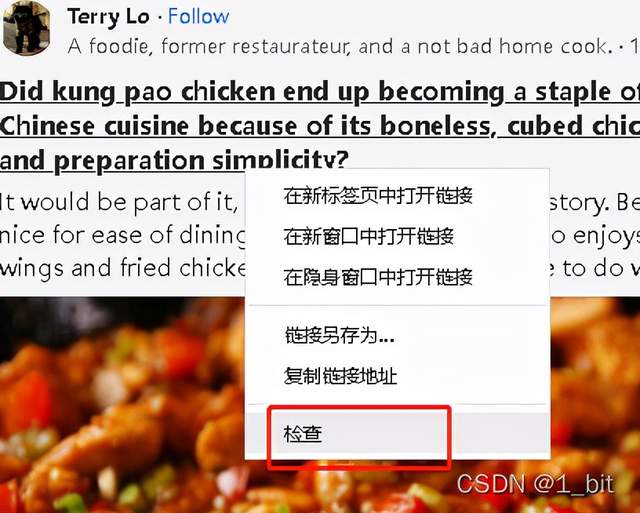
此时我们可以看到这一块 html 代码下就是对应的内容:
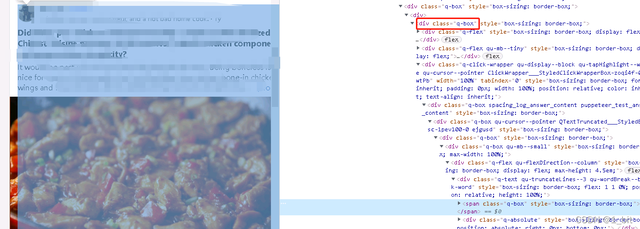
我们从中得知,这个部分的 class 的名称是q-box,我们可以通过driver中的
find_element_by_class_name 的方法,找到这个元素,并且得到对应的文本。
接着我们观看所有的内容块得知,都是使用q-box作为名称:
接下来我们只需要使用代码:
content=driver.find_element_by_class_name('q-box')
就可以抓取到这所有名为 q-box 的对象。
此时我们只需要对这个对象使用 .text 即可获取文本,再使用 f.write 将其写入到文本之中:
f = open(r'C:\Users\Administrator\Desktop\data\data.txt',mode='w',encoding='UTF-8') f.write(content.text) f.close()
该部分的完整代码如下:
from selenium import webdriver
import requests,json,time
#代理
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0'}
#代理获取
def ip_():
url=r"http://tiqu.ipidea.io:81/abroad?num=1&type=2&lb=1&sb=0&flow=1®ions=in&port=1"
r = requests.get(url, headers=headers,timeout=3)
data = json.loads(r.content)
print(data)
ip_=data['data'][0]
return ip_
ip=ip_()#ip获取
proxy_str="http://"+str(ip['ip'])+':'+str(ip['port'])#ip proxy 组合
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=%s" % proxy_str)
options.add_argument('--ignore-certificate-errors')
options.add_argument('-ignore -ssl-errors')
url='https://www.quora.com/topic/Chinese-Food?q=Chinese%20food'
driver = webdriver.Chrome(executable_path=r'C:\webdriver\chromedriver.exe',options=options)
driver.get(url)
input()
for i in range(0,500):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(10)
title=driver.find_element_by_class_name('q-box')
#title=driver.find_element_by_css_selector("[class='dtb-style-1 table-dragColumns']")
f = open(r'C:\Users\Administrator\Desktop\data\data.txt',mode='w',encoding='UTF-8')
f.write(title.text)
f.close()
三、切词统计
3.1 数据清洗
接着咱们可以对数据进行翻译,不过免费的库有每日限制,那么最好的办法,不花钱的办法就是复制内容去在线翻译去翻译,对的,虽然数据有点多,不过还好,问题不大。
翻译完成复制的一个文本之中,这个文本我命名为 datacn。
在此创建一个名称为cut的py文件,并且在头部引入:
import jieba,re,jieba.analyse #结巴分词 from wordcloud import WordCloud #词云 import matplotlib.pyplot as plt
引入之后创建一个函数用于读取翻译过来的文本 datacn 的内容:
def get_str(path):
f = open(path,encoding="utf-8" )
data = f.read()
f.close()
return data
代码很简单,就是 open文件,read读取就完成了,不过有些同学容易出现编码错误,记得一定要加 encoding=“utf-8”,如果还不信,你就将文本另存为,在另存为时选择编码为 utf-8就可以了:
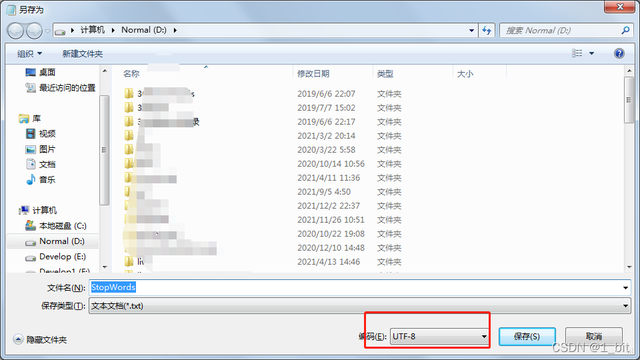
接着,咱们再创建一个清洗内容的函数:
def word_chinese(text):
pattern = re.compile(r'[^\u4e00-\u9fa5]')
clean= re.sub(pattern, '', text)
return clean
其实上面函数的作用就是找到中文字符返回,其他的内容就不要了,不然会影响效果,例如一些标点符号和英文字母等。
接着我们直接读取数据:
path=r"D:\datacn.txt" text=get_str(path) text=word_chinese(text)
其中 path 是路径,就是我翻译过来的文本存储的路径,然后传入参数 get_str 中就可以了,这样读到的数据就是text,急着再把text传入到清洗函数 word_chinese 中进行清洗,这样清除不好的数据就ok了。
3.2 词频权重统计
但是这个时候还是有一些不好的词语出现,例如 你、我、他、你好、知道…这些内容,怎么去掉呢?这个时候就使用结巴库设置一些词不要
jieba.analyse.set_stop_words,代码是:
jieba.analyse.set_stop_words(r'D:\StopWords.txt')
其中 D:\StopWords.txt 这个文本中记录了不要的词,我为了数据准确我自己调了一堆的词,想要的可以看评论区,数据太多不好直接复制上来。
设置好之后就可以自动过滤了,下一步就是切词统计词频,这一步的代码是:
words = jieba.analyse.textrank(text, topK=168,withWeight=True)
使用的方法是 jieba.analyse.textrank(),其中 text 就是我们清理过的文本,topk 是指你要得到词频前几,我这里是 topk=168 就是表示得到出现频率最多的钱 168 个词,函数其中 withWeight=True 表示结果中出现词频权重数值,例如不使用 withWeight=True 结果如下:

不开启 withWeight 结果则显示:

此时结果已经得到了,发现老外最喜欢、提的次数最高的竟然是酱油,然后是喜欢。看来是真的挺喜欢的。
接着咱们先做个词云,再做分析。词云需要字符串,不能使用数组,使用以下代码使其成为字符串:
wcstr = " ".join(words)
接着创建词云对象:
wc = WordCloud(background_color="white",
width=1000,
height=1000,
font_path='simhei.ttf'
)
在词云对象的配置中,background_color 是字符串,width 和 height 是词云宽度,font_path 是设置字体。在此注意,字体一定要设置,否则将会看不到任何文字。
接着将字符串传递给创建的词云对象 wc的generate函数:
wc.generate(wcstr)
接下来就使用plt显示就可以了:
plt.imshow(wc)
plt.axis("off")
plt.show()
完整代码如下:
import jieba,re,jieba.analyse
from wordcloud import WordCloud
import matplotlib.pyplot as plt
def get_str(path):
f = open(path,encoding="utf-8" )
data = f.read()
f.close()
return data
def word_chinese(text):
pattern = re.compile(r'[^\u4e00-\u9fa5]')
clean = re.sub(pattern, '', text)
return clean
path=r"D:\datacn.txt"
text=get_str(path)
text=word_chinese(text)
jieba.analyse.set_stop_words(r'D:\StopWords.txt')
words = jieba.analyse.textrank(text, topK=168)
print(words)
wcstr = " ".join(words)
wc = WordCloud(background_color="white",
width=1000,
height=1000,
font_path='simhei.ttf'
)
wc.generate(wcstr)
plt.imshow(wc)
plt.axis("off")
plt.show()
最终的结果如下:

四、从数据中找到TOP之最
由于数据太多,不方便用折线图之类统计,我从权重中找到了老外提到最Top的几个纬度。
所有排名如下:

老外提到最多 Top :
美食圣地依次是香港、澳门、广东、无锡、广州、北京、闽南;
提到食物最多的是:炒饭、米饭、豆腐、大豆、牛肉、面条、火锅、炒菜、饺子、蛋糕、包子
提到最多口味:糖醋、咸味
提到最多的厨具:火锅、陶罐、石锅、灶台
不过第一是酱油是啥情况,而且喜欢第二,看来大家都比较喜欢我们的食物呀!很赞!
-
用FastAPI掌握Python异步IO:轻松实现高并发网络请求处理01-03
-
封装学习:Python面向对象编程基础教程01-02
-
Python编程基础教程12-28
-
Python编程入门指南12-27
-
Python编程基础12-27
-
Python编程基础教程12-27
-
Python编程基础指南12-27
-
Python编程入门指南12-24
-
Python编程基础入门12-24
-
Python编程基础:变量与数据类型12-24
-
使用python部署一个usdt合约,部署自己的usdt稳定币12-23
-
Python编程入门指南12-20
-
Python编程基础与进阶12-20
-
Python基础编程教程12-19
-
python 文件的后缀名是什么 怎么运行一个python文件?-icode9专业技术文章分享12-19
