Java教程
Java8特性详解 lambda表达式(一):使用篇

在 Java 8之前,一个实现了只有一个抽象方法的接口的匿名类看起来更像Lambda 表达式。下面的代码中,anonymousClass方法调用waitFor方法,参数是一个实现接口的Condition类,实现的功能为,当满足某些条件,Server 就会关闭。 下面的代码是典型的匿名类的使用。
void anonymousClass() {
final Server server = new HttpServer();
waitFor(new Condition() {
@Override
public Boolean isSatisfied() {
return !server.isRunning();
}
}
复制代码
下面的代码用 Lambda 表达式实现相同的功能:
void closure() {
Server server = new HttpServer();
waitFor(() -> !server.isRunning());
}
复制代码
其实,上面的waitFor方法,更接近于下面的代码的描述:
class WaitFor {
static void waitFor(Condition condition) throws
InterruptedException {
while (!condition.isSatisfied())
Thread.sleep(250);
}
}
复制代码
一些理论上的区别 实际上,上面的两种方法的实现都是闭包,后者的实现就是Lambda 表示式。这就意味着两者都需要持有运行时的环境。在 Java 8 之前,这就需要把匿名类所需要的一切复制给它。在上面的例子中,就需要把 server 属性复制给匿名类。
因为是复制,变量必须声明为 final 类型,以保证在获取和使用时不会被改变。Java 使用了优雅的方式保证了变量不会被更新,所以我们不用显式地把变量加上 final 修饰。
Lambda 表达式则不需要拷贝变量到它的运行环境中,从而 Lambda 表达式被当做是一个真正的方法来对待,而不是一个类的实例。
Lambda 表达式不需要每次都要被实例化,对于 Java 来说,带来巨大的好处。不像实例化匿名类,对内存的影响可以降到最小。
总体来说,匿名方法和匿名类存在以下区别:
类必须实例化,而方法不必; 当一个类被新建时,需要给对象分配内存; 方法只需要分配一次内存,它被存储在堆的永久区内; 对象作用于它自己的数据,而方法不会; 静态类里的方法类似于匿名方法的功能。
一些具体的区别 匿名方法和匿名类有一些具体的区别,主要包括获取语义和覆盖变量。
获取语义 this 关键字是其中的一个语义上的区别。在匿名类中,this 指的是匿名类的实例,例如有了内部类为 Foo$InnerClass,当你引用内部类闭包的作用域时,像Foo.this.x的代码看起来就有些奇怪。 在 Lambda 表达式中,this 指的就是闭包作用域,事实上,Lambda 表达式就是一个作用域,这就意味着你不需要从超类那里继承任何名字,或是引入作用域的层级。你可以在作用域里直接访问属性,方法和局部变量。 例如,下面的代码中,Lambda 表达式可以直接访问firstName变量。
public class Example {
private String firstName = "Tom";
public void example() {
Function<String, String> addSurname = surname -> {
// equivalent to this.firstName
return firstName + " " + surname; // or even,
};
}
}
复制代码
这里的firstName就是this.firstName的简写。 但是在匿名类中,你必须显式地调用firstName,
public class Example {
private String firstName = "Jerry";
public void anotherExample() {
Function<String, String> addSurname = new Function<String,
String>() {
@Override
public String apply(String surname) {
return Example.this.firstName + " " + surname;
}
};
}
}
1.lambda表达式
Java8最值得学习的特性就是Lambda表达式和Stream API,如果有python或者javascript的语言基础,对理解Lambda表达式有很大帮助,因为Java正在将自己变的更高(Sha)级(Gua),更人性化。--------可以这么说lambda表达式其实就是实现SAM接口的语法糖。
lambda写的好可以极大的减少代码冗余,同时可读性也好过冗长的内部类,匿名类。
先列举两个常见的简化(简单的代码同样好理解)
- 创建线程

- 排序

lambda表达式配合Java8新特性Stream API可以将业务功能通过函数式编程简洁的实现。(为后面的例子做铺垫)
例如:

这段代码就是对一个字符串的列表,把其中包含的每个字符串都转换成全小写的字符串。注意代码第四行的map方法调用,这里map方法就是接受了一个lambda表达式。
1.1lambda表达式语法
1.1.1lambda表达式的一般语法
(Type1 param1, Type2 param2, ..., TypeN paramN) -> {
statment1;
statment2;
//.............
return statmentM;
}
这是lambda表达式的完全式语法,后面几种语法是对它的简化。
1.1.2单参数语法
param1 -> {
statment1;
statment2;
//.............
return statmentM;
}
当lambda表达式的参数个数只有一个,可以省略小括号
例如:将列表中的字符串转换为全小写
List proNames = Arrays.asList(new String[]{“Ni”,“Hao”,“Lambda”});
List lowercaseNames1 = proNames.stream().map(name -> {return name.toLowerCase();}).collect(Collectors.toList());
1.1.3单语句写法
param1 -> statment
当lambda表达式只包含一条语句时,可以省略大括号、return和语句结尾的分号
例如:将列表中的字符串转换为全小写
List proNames = Arrays.asList(new String[]{“Ni”,“Hao”,“Lambda”});
List lowercaseNames2 = proNames.stream().map(name -> name.toLowerCase()).collect(Collectors.toList());
1.1.4方法引用写法
(方法引用和lambda一样是Java8新语言特性,后面会讲到)
Class or instance :: method
例如:将列表中的字符串转换为全小写
List proNames = Arrays.asList(new String[]{“Ni”,“Hao”,“Lambda”});
List lowercaseNames3 = proNames.stream().map(String::toLowerCase).collect(Collectors.toList());
1.2lambda表达式可使用的变量
先举例:
//将为列表中的字符串添加前缀字符串
String waibu = “lambda :”;
List proStrs = Arrays.asList(new String[]{“Ni”,“Hao”,“Lambda”});
ListexecStrs = proStrs.stream().map(chuandi -> {
Long zidingyi = System.currentTimeMillis();
return waibu + chuandi + " -----:" + zidingyi;
}).collect(Collectors.toList());
execStrs.forEach(System.out::println);
输出:
lambda :Ni -----:1474622341604
lambda :Hao -----:1474622341604
lambda :Lambda -----:1474622341604
变量waibu :外部变量
变量chuandi :传递变量
变量zidingyi :内部自定义变量
lambda表达式可以访问给它传递的变量,访问自己内部定义的变量,同时也能访问它外部的变量。
不过lambda表达式访问外部变量有一个非常重要的限制:变量不可变(只是引用不可变,而不是真正的不可变)。
当在表达式内部修改waibu = waibu + " ";时,IDE就会提示你:
Local variable waibu defined in an enclosing scope must be final or effectively final
编译时会报错。因为变量waibu被lambda表达式引用,所以编译器会隐式的把其当成final来处理。
以前Java的匿名内部类在访问外部变量的时候,外部变量必须用final修饰。现在java8对这个限制做了优化,可以不用显示使用final修饰,但是编译器隐式当成final来处理。
1.3lambda表达式中的this概念
在lambda中,this不是指向lambda表达式产生的那个SAM对象,而是声明它的外部对象。
例如:
public class WhatThis {
public void whatThis(){
//转全小写
List proStrs = Arrays.asList(new String[]{“Ni”,“Hao”,“Lambda”});
List execStrs = proStrs.stream().map(str -> {
System.out.println(this.getClass().getName());
return str.toLowerCase();
}).collect(Collectors.toList());
execStrs.forEach(System.out::println);
}
public static void main(String[] args) {
WhatThis wt = new WhatThis();
wt.whatThis();
}
}
输出:
com.wzg.test.WhatThis
com.wzg.test.WhatThis
com.wzg.test.WhatThis
ni
hao
lambda
2.方法引用和构造器引用
本人认为是进一步简化lambda表达式的声明的一种语法糖。
前面的例子中已有使用到: execStrs.forEach(System.out::println);
2.1方法引用
objectName::instanceMethod
ClassName::staticMethod
ClassName::instanceMethod
前两种方式类似,等同于把lambda表达式的参数直接当成instanceMethod|staticMethod的参数来调用。比如System.out::println等同于x->System.out.println(x);Math::max等同于(x, y)->Math.max(x,y)。
最后一种方式,等同于把lambda表达式的第一个参数当成instanceMethod的目标对象,其他剩余参数当成该方法的参数。比如String::toLowerCase等同于x->x.toLowerCase()。
可以这么理解,前两种是将传入对象当参数执行方法,后一种是调用传入对象的方法。
2.2构造器引用
构造器引用语法如下:ClassName::new,把lambda表达式的参数当成ClassName构造器的参数 。例如BigDecimal::new等同于x->new BigDecimal(x)。
3.Stream语法
两句话理解Stream:
1.Stream是元素的集合,这点让Stream看起来用些类似Iterator;
2.可以支持顺序和并行的对原Stream进行汇聚的操作;
大家可以把Stream当成一个装饰后的Iterator。原始版本的Iterator,用户只能逐个遍历元素并对其执行某些操作;包装后的Stream,用户只要给出需要对其包含的元素执行什么操作,比如“过滤掉长度大于10的字符串”、“获取每个字符串的首字母”等,具体这些操作如何应用到每个元素上,就给Stream就好了!原先是人告诉计算机一步一步怎么做,现在是告诉计算机做什么,计算机自己决定怎么做。当然这个“怎么做”还是比较弱的。
例子:
//Lists是Guava中的一个工具类
List nums = Lists.newArrayList(1,null,3,4,null,6);
nums.stream().filter(num -> num != null).count();
上面这段代码是获取一个List中,元素不为null的个数。这段代码虽然很简短,但是却是一个很好的入门级别的例子来体现如何使用Stream,正所谓“麻雀虽小五脏俱全”。我们现在开始深入解刨这个例子,完成以后你可能可以基本掌握Stream的用法!

图片就是对于Stream例子的一个解析,可以很清楚的看见:原本一条语句被三种颜色的框分割成了三个部分。红色框中的语句是一个Stream的生命开始的地方,负责创建一个Stream实例;绿色框中的语句是赋予Stream灵魂的地方,把一个Stream转换成另外一个Stream,红框的语句生成的是一个包含所有nums变量的Stream,进过绿框的filter方法以后,重新生成了一个过滤掉原nums列表所有null以后的Stream;蓝色框中的语句是丰收的地方,把Stream的里面包含的内容按照某种算法来汇聚成一个值,例子中是获取Stream中包含的元素个数。如果这样解析以后,还不理解,那就只能动用“核武器”–图形化,一图抵千言!

使用Stream的基本步骤:
1.创建Stream;
2.转换Stream,每次转换原有Stream对象不改变,返回一个新的Stream对象(可以有多次转换);
3.对Stream进行聚合(Reduce)操作,获取想要的结果;
3.1怎么得到Stream
最常用的创建Stream有两种途径:
1.通过Stream接口的静态工厂方法(注意:Java8里接口可以带静态方法);
2.通过Collection接口的默认方法(默认方法:Default method,也是Java8中的一个新特性,就是接口中的一个带有实现的方法)–stream(),把一个Collection对象转换成Stream
3.1.1 使用Stream静态方法来创建Stream
1. of方法:有两个overload方法,一个接受变长参数,一个接口单一值
Stream integerStream = Stream.of(1, 2, 3, 5);
Stream stringStream = Stream.of(“taobao”);
2. generator方法:生成一个无限长度的Stream,其元素的生成是通过给定的Supplier(这个接口可以看成一个对象的工厂,每次调用返回一个给定类型的对象)
Stream.generate(new Supplier() {
@Override
public Double get() {
return Math.random();
}
});
Stream.generate(() -> Math.random());
Stream.generate(Math::random);
三条语句的作用都是一样的,只是使用了lambda表达式和方法引用的语法来简化代码。每条语句其实都是生成一个无限长度的Stream,其中值是随机的。这个无限长度Stream是懒加载,一般这种无限长度的Stream都会配合Stream的limit()方法来用。
3. iterate方法:也是生成无限长度的Stream,和generator不同的是,其元素的生成是重复对给定的种子值(seed)调用用户指定函数来生成的。其中包含的元素可以认为是:seed,f(seed),f(f(seed))无限循环
Stream.iterate(1, item -> item + 1).limit(10).forEach(System.out::println);
这段代码就是先获取一个无限长度的正整数集合的Stream,然后取出前10个打印。千万记住使用limit方法,不然会无限打印下去。
3.1.2通过Collection子类获取Stream
Collection接口有一个stream方法,所以其所有子类都都可以获取对应的Stream对象。
public interface Collection extends Iterable {
//其他方法省略
default Stream stream() {
return StreamSupport.stream(spliterator(), false);
}
}
3.2转换Stream
转换Stream其实就是把一个Stream通过某些行为转换成一个新的Stream。Stream接口中定义了几个常用的转换方法,下面我们挑选几个常用的转换方法来解释。
1. distinct: 对于Stream中包含的元素进行去重操作(去重逻辑依赖元素的equals方法),新生成的Stream中没有重复的元素;

2. filter: 对于Stream中包含的元素使用给定的过滤函数进行过滤操作,新生成的Stream只包含符合条件的元素;

3. map: 对于Stream中包含的元素使用给定的转换函数进行转换操作,新生成的Stream只包含转换生成的元素。这个方法有三个对于原始类型的变种方法,分别是:mapToInt,mapToLong和mapToDouble。这三个方法也比较好理解,比如mapToInt就是把原始Stream转换成一个新的Stream,这个新生成的Stream中的元素都是int类型。之所以会有这样三个变种方法,可以免除自动装箱/拆箱的额外消耗;

4. flatMap:和map类似,不同的是其每个元素转换得到的是Stream对象,会把子Stream中的元素压缩到父集合中;

flatMap给一段代码理解:
Stream
flatMap 把 input Stream 中的层级结构扁平化,就是将最底层元素抽出来放到一起,最终 output 的新 Stream 里面已经没有 List 了,都是直接的数字。
5. peek: 生成一个包含原Stream的所有元素的新Stream,同时会提供一个消费函数(Consumer实例),新Stream每个元素被消费的时候都会执行给定的消费函数;

6. limit: 对一个Stream进行截断操作,获取其前N个元素,如果原Stream中包含的元素个数小于N,那就获取其所有的元素;

7. skip: 返回一个丢弃原Stream的前N个元素后剩下元素组成的新Stream,如果原Stream中包含的元素个数小于N,那么返回空Stream;
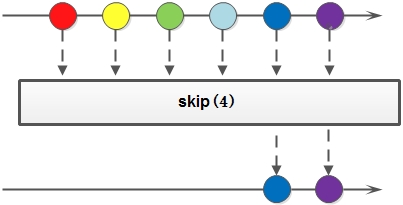
整体调用例子:
List nums = Lists.newArrayList(1,1,null,2,3,4,null,5,6,7,8,9,10);
System.out.println(“sum is:”+nums.stream().filter(num -> num != null).distinct().mapToInt(num -> num * 2).peek(System.out::println).skip(2).limit(4).sum());
这段代码演示了上面介绍的所有转换方法(除了flatMap),简单解释一下这段代码的含义:给定一个Integer类型的List,获取其对应的Stream对象,然后进行过滤掉null,再去重,再每个元素乘以2,再每个元素被消费的时候打印自身,在跳过前两个元素,最后去前四个元素进行加和运算(解释一大堆,很像废话,因为基本看了方法名就知道要做什么了。这个就是声明式编程的一大好处!)。大家可以参考上面对于每个方法的解释,看看最终的输出是什么。
可能会有这样的疑问:在对于一个Stream进行多次转换操作,每次都对Stream的每个元素进行转换,而且是执行多次,这样时间复杂度就是一个for循环里把所有操作都做掉的N(转换的次数)倍啊。其实不是这样的,转换操作都是lazy的,多个转换操作只会在汇聚操作(见下节)的时候融合起来,一次循环完成。我们可以这样简单的理解,Stream里有个操作函数的集合,每次转换操作就是把转换函数放入这个集合中,在汇聚操作的时候循环Stream对应的集合,然后对每个元素执行所有的函数。
3.3汇聚(Reduce)Stream
汇聚操作(也称为折叠)接受一个元素序列为输入,反复使用某个合并操作,把序列中的元素合并成一个汇总的结果。比如查找一个数字列表的总和或者最大值,或者把这些数字累积成一个List对象。Stream接口有一些通用的汇聚操作,比如reduce()和collect();也有一些特定用途的汇聚操作,比如sum(),max()和count()。注意:sum方法不是所有的Stream对象都有的,只有IntStream、LongStream和DoubleStream是实例才有。
下面会分两部分来介绍汇聚操作:
可变汇聚:把输入的元素们累积到一个可变的容器中,比如Collection或者StringBuilder;
其他汇聚:除去可变汇聚剩下的,一般都不是通过反复修改某个可变对象,而是通过把前一次的汇聚结果当成下一次的入参,反复如此。比如reduce,count,allMatch;
3.3.1可变汇聚
可变汇聚对应的只有一个方法:collect,正如其名字显示的,它可以把Stream中的要有元素收集到一个结果容器中(比如Collection)。先看一下最通用的collect方法的定义(还有其他override方法):
R collect(Supplier supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
先来看看这三个参数的含义:Supplier supplier是一个工厂函数,用来生成一个新的容器;BiConsumer accumulator也是一个函数,用来把Stream中的元素添加到结果容器中;BiConsumer combiner还是一个函数,用来把中间状态的多个结果容器合并成为一个(并发的时候会用到)。看晕了?来段代码!
List nums = Lists.newArrayList(1,1,null,2,3,4,null,5,6,7,8,9,10);
List numsWithoutNull = nums.stream().filter(num -> num != null).
collect(() -> new ArrayList(),
(list, item) -> list.add(item),
(list1, list2) -> list1.addAll(list2));
上面这段代码就是对一个元素是Integer类型的List,先过滤掉全部的null,然后把剩下的元素收集到一个新的List中。进一步看一下collect方法的三个参数,都是lambda形式的函数。
第一个函数生成一个新的ArrayList实例;
第二个函数接受两个参数,第一个是前面生成的ArrayList对象,二个是stream中包含的元素,函数体就是把stream中的元素加入ArrayList对象中。第二个函数被反复调用直到原stream的元素被消费完毕;
第三个函数也是接受两个参数,这两个都是ArrayList类型的,函数体就是把第二个ArrayList全部加入到第一个中;
但是上面的collect方法调用也有点太复杂了,没关系!我们来看一下collect方法另外一个override的版本,其依赖[Collector](Collector (Java Platform SE 8 ))。
<R, A> R collect(Collector<? super T, A, R> collector);
这样清爽多了!Java8还给我们提供了Collector的工具类–[Collectors](Collectors (Java Platform SE 8 )),其中已经定义了一些静态工厂方法,比如:Collectors.toCollection()收集到Collection中, Collectors.toList()收集到List中和Collectors.toSet()收集到Set中。这样的静态方法还有很多,这里就不一一介绍了,大家可以直接去看JavaDoc。下面看看使用Collectors对于代码的简化:
List numsWithoutNull = nums.stream().filter(num -> num != null).
collect(Collectors.toList());
3.3.2其他汇聚
– reduce方法:reduce方法非常的通用,后面介绍的count,sum等都可以使用其实现。reduce方法有三个override的方法,本文介绍两个最常用的。先来看reduce方法的第一种形式,其方法定义如下:
Optional reduce(BinaryOperator accumulator);
接受一个BinaryOperator类型的参数,在使用的时候我们可以用lambda表达式来。
List ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println(“ints sum is:” + ints.stream().reduce((sum, item) -> sum + item).get());
可以看到reduce方法接受一个函数,这个函数有两个参数,第一个参数是上次函数执行的返回值(也称为中间结果),第二个参数是stream中的元素,这个函数把这两个值相加,得到的和会被赋值给下次执行这个函数的第一个参数。要注意的是:第一次执行的时候第一个参数的值是Stream的第一个元素,第二个参数是Stream的第二个元素。这个方法返回值类型是Optional,这是Java8防止出现NPE的一种可行方法,后面的文章会详细介绍,这里就简单的认为是一个容器,其中可能会包含0个或者1个对象。
这个过程可视化的结果如图:

reduce方法还有一个很常用的变种:
T reduce(T identity, BinaryOperator accumulator);
这个定义上上面已经介绍过的基本一致,不同的是:它允许用户提供一个循环计算的初始值,如果Stream为空,就直接返回该值。而且这个方法不会返回Optional,因为其不会出现null值。下面直接给出例子,就不再做说明了。
List ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println(“ints sum is:” + ints.stream().reduce(0, (sum, item) -> sum + item));
– count方法:获取Stream中元素的个数。比较简单,这里就直接给出例子,不做解释了。
List ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println(“ints sum is:” + ints.stream().count());
– 搜索相关
– allMatch:是不是Stream中的所有元素都满足给定的匹配条件
– anyMatch:Stream中是否存在任何一个元素满足匹配条件
– findFirst: 返回Stream中的第一个元素,如果Stream为空,返回空Optional
– noneMatch:是不是Stream中的所有元素都不满足给定的匹配条件
– max和min:使用给定的比较器(Operator),返回Stream中的最大|最小值
下面给出allMatch和max的例子,剩下的方法读者当成练习。
查看源代码打印帮助
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println(ints.stream().allMatch(item -> item < 100));
ints.stream().max((o1, o2) -> o1.compareTo(o2)).ifPresent(System.out::println);
参考文章
Java 中的 Lambda 表达式 - 掘金
Java8特性详解 lambda表达式 Stream - aoeiuv - 博客园
微信公众号【程序员黄小斜】作者是前蚂蚁金服Java工程师,专注分享Java技术干货和求职成长心得,不限于BAT面试,算法、计算机基础、数据库、分布式、spring全家桶、微服务、高并发、JVM、Docker容器,ELK、大数据等。关注后回复【book】领取精选20本Java面试必备精品电子书。
-
Java中定时任务实现方式及源码剖析11-24
-
Java中定时任务实现方式及源码剖析11-24
-
鸿蒙原生开发手记:03-元服务开发全流程(开发元服务,只需要看这一篇文章)11-24
-
细说敏捷:敏捷四会之每日站会11-24
-
Springboot应用的多环境打包入门11-23
-
Springboot应用的生产发布入门教程11-23
-
Python编程入门指南11-23
-
Java创业入门:从零开始的编程之旅11-23
-
Java创业入门:新手必读的Java编程与创业指南11-23
-
Java对接阿里云智能语音服务入门详解11-23
-
Java对接阿里云智能语音服务入门教程11-23
-
JAVA对接阿里云智能语音服务入门教程11-23
-
Java副业入门:初学者的简单教程11-23
-
JAVA副业入门:初学者的实战指南11-23
-
JAVA项目部署入门:新手必读指南11-23
