MySql教程
5分钟搞定 MySQL 到 ElasticSearch 数据同步和宽表构建-CloudCanal实战

简述
CloudCanal 2.0.X 版本近期支持了宽表构建能力在数据预处理领域向前走了一步。
方案特点
- 相对灵活对业务数据和结构贴合性好
- 能很好的支持事实表与维表打宽表需求
本文以 MySQL 到 ElasticSearch6 单事实表双维表为案例介绍 CloudCanal 宽表构建和同步的操作步骤。
技术点
打宽表的必要性
关系型数据库为了应对在线业务对于并发、毫秒级响应同时操作相对趋向 kv 化,一般基于关系范式进行设计通过外键或约定外键非物理约束进行关联。
当业务需求涉及到多张关联表(业务运营、报表、BI 需求)查询表的先后顺序成为操作响应时间的关键要素但排列组合式种类随关联表数量(n)增加会膨胀非常快(n!)导致查询效率低下。
| 关联表数量 | 排列种类 |
|---|---|
| 2 | 2 |
| 3 | 6 |
| 4 | 24 |
| 5 | 120 |
| 6 | 720 |
| 7 | 5040 |
| 8 | 40320 |
| 10 | 403200 |
| 11 | 4435300 |
数据库或者数仓做 join 查询特别是5张表以上最难的事情变成了如何从这么多可能性中搜索空间找到最好的那一个。
数据迁移和同步 以相对比较小的代价将多张关联表进查询库或者数据仓库之前通过反查或者窗口等待变更数据做关联打成一张宽表写入对端显著减轻后续查询对于 SQL 优化器的要求。
宽表的种类和方式
这里的宽表种类指其数据来源表种类(常见但不全面)常见的我们分 事实表 和 维度表,比如订单表被定义成事实表用户表被定义成维度表商品表被定义成维度表。
一般事实表和维度表数据具备类似 n:1 的关系也就是 1 个用户会有 n 个订单 (1个订单属于1个用户)1 个商品也会存在 n 个订单 (1个订单会关联 1 个或有限个数商品)。
打宽表的方式有多种根据场景最常见的包含以下两种
- 多事实表 打宽表
- 一般场景是在有限的时间内关联的变更在这些表上发生多流join打宽表工具只要在一定的时间范围内等到这些数据window即可打成宽表数据。
- 单事实表和多维度表打宽表
- 一般场景是事实表变更但是维度表没有任何变化这时打宽表工具需要通过事实表变更数据反查维度表数据打成宽表。
CloudCanal 目前打宽表的方式主要通过反查实现对于多流 join , 实际上也可以通过反查实现只是可能缺乏数据一致性。
举个 ‘栗’ 子
前置条件:
- CloudCanal 社区版部署,参见 社区版安装文档
- 准备好 MySQL 数据库本例使用 5.7 版本和 ElasticSearch 数据库本例使用 6.x 版本
- MySQL 上创建 1 张事实表(order)和 2 张维表 (user 、product)
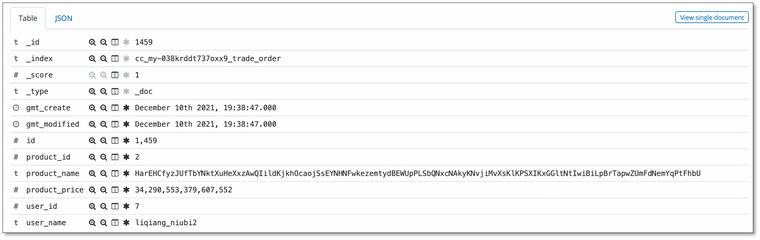
- ElasticSearch 上创建 1 个索引 order , 并额外包含两张维表相关数据
- user_id (关联user.id), user_name(对应user.name)
- product_id(关联product.id) ,product_name(对应product.name),product_price (对应product.price)
开发宽表代码
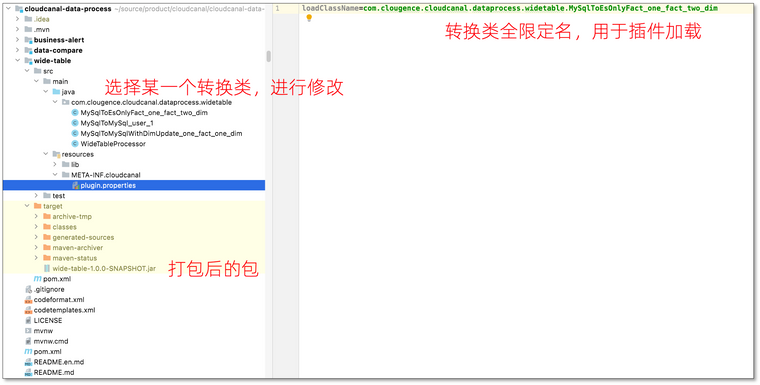
- 代码工程 cloudcanal-data-process 并找到代码类 MySqlToEsOnlyFact_one_fact_two_dim.java
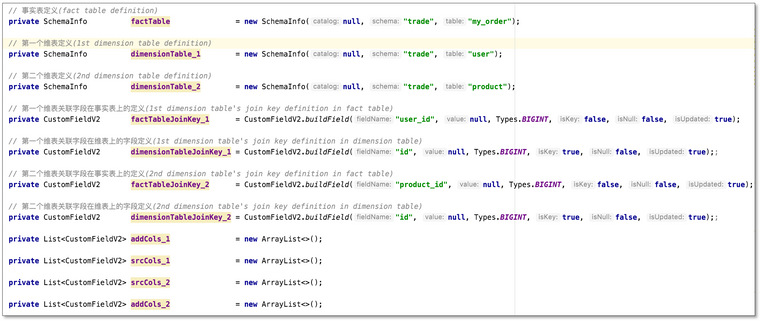
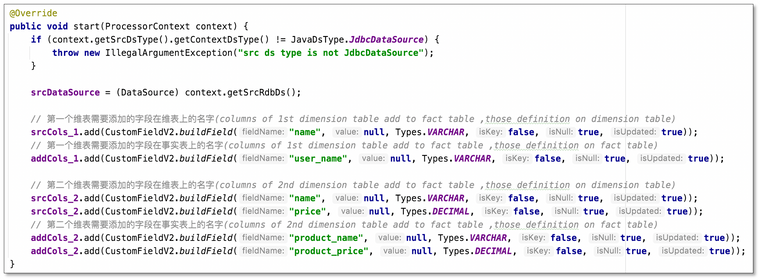
- 修改必要信息

打包
-
进入工程目录使用命令进行打包
% pwd /Users/zylicfc/source/product/cloudcanal/cloudcanal-data-process % mvn -Dtest -DfailIfNoTests=false -Dmaven.javadoc.skip=true -Dmaven.compile.fork=true clean package
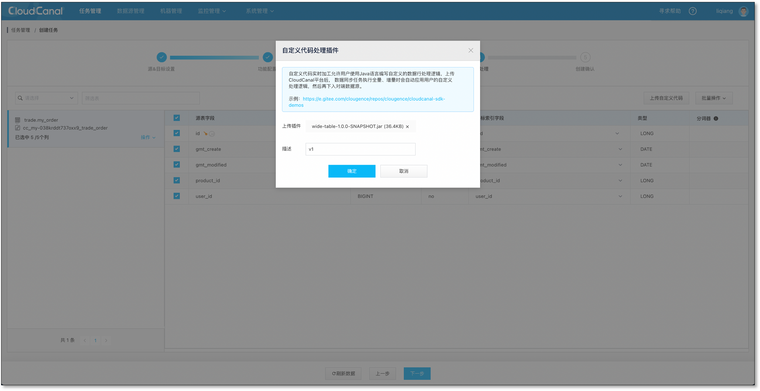
自定义代码包
- 打包命令后代码包位于工程目录下的 wide-table/target 目录

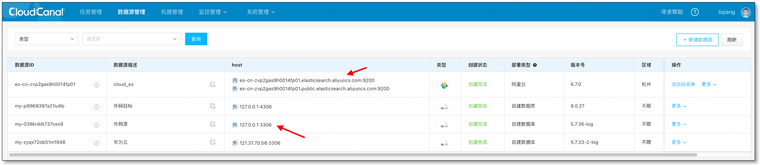
添加数据源
- 登录 CloudCanal 平台
- 数据源管理->新增数据源
- 将MySQL 和 ElasticSearch 分别添加
任务创建
- 任务管理->任务创建
- 选择 源 和 目标 数据源
- 选择 数据同步并勾选 全量数据初始化, 其他选项默认
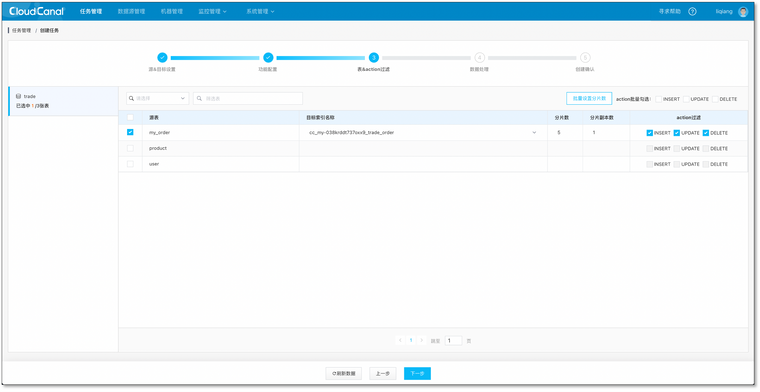
- 选择需要迁移同步的表, 此处只要选择事实表即可维表会通过自定义代码反查补充
- 选择列,默认全选%(#ea1f1f)[选择上传代码包(路径如上所示)]
- 确认创建,并自动运行

校验数据
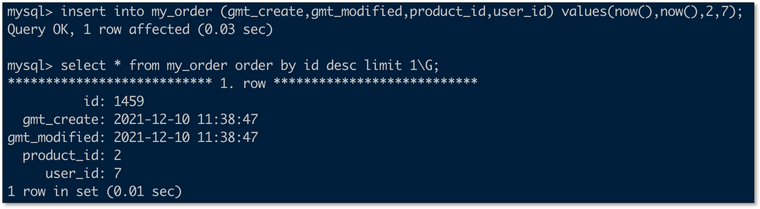
- 变更事实表数据
- 变更维表数据
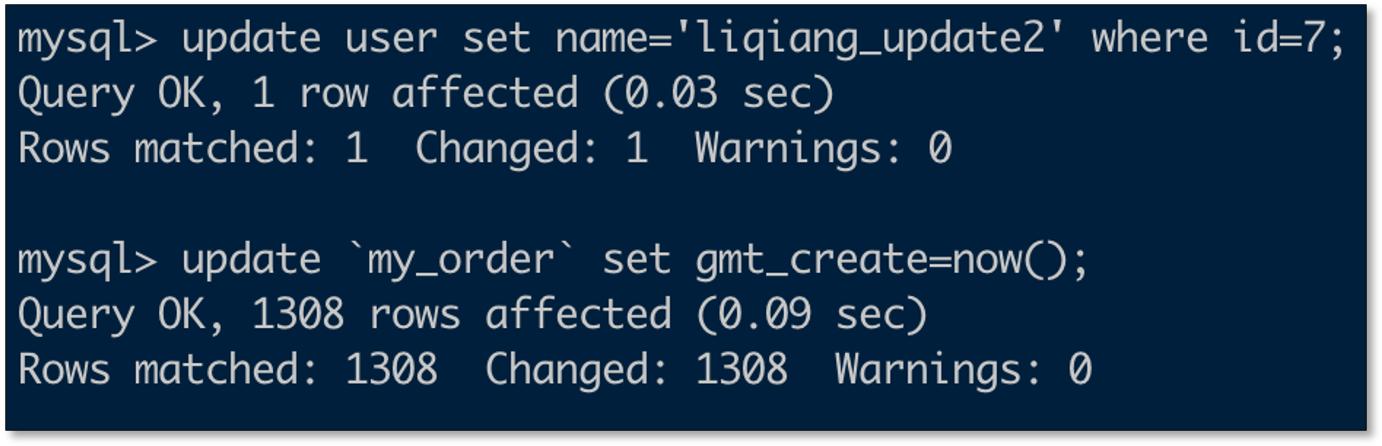
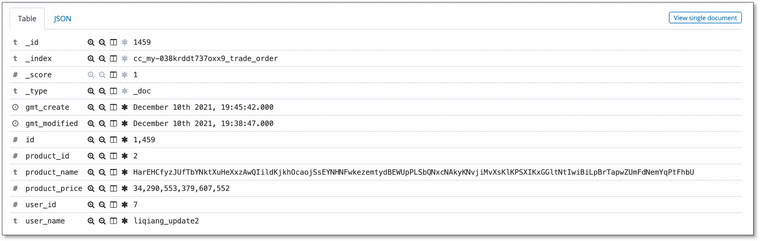
数据变化规律
- 事实表插入更新都会反查维表最新数据并写入对端
- 维表更新基础模式中需要触发事实表更新才能带上最新的维表变更数据写入对端
- 维表数据删除基础模式中如果触发事实表更新默认将会把对应的维表数据已删除置为null, 但是根据对端数据源不同效果可能会有所差别比如不会置空
FAQ
维表变化后怎么办
目前我们提供的基础模式维表变化不会直接触发事实表更新因为这个基本上意味着大规模对端数据变更可能影响对端数据服务稳定性。所以源端触发事实表更新比如变更一个时间字段带上最新的维表数据进行对端数据刷新。
另外对于维表数据的删除如果触发事实表更新从而刷新对端数据则默认置为null。
不会开发 java 代码怎么办
如果能打包不会 java 开发在 cloudcanal-data-process 寻找相应模版修改配置即可。
如果不能打包也不会开发找 CloudCanal 同学协助。
如果遇到出错或者问题怎么办
如果会 java 开发建议打开任务的 printCustomCodeDebugLog 观察输出的数据是否符合预期如果不符合预期可以打开任务的 debugMode 参数对数据转换逻辑进行调试。
如果不会 java 开发, 找 CloudCanal 同学协助。
还支持其他数据源么
这个是 CloudCanal 通用能力只要源和目标之间实现了全量迁移和增量同步即支持。
总结
本文简单介绍了如何使用 CloudCanal 进行 MySQL -> ElasticSearch 的宽表构建以最常见的单事实表多维表方式举例。各位小伙伴如果觉得还不错请点赞、评论加转发吧。
-
如何部署MySQL集群资料:新手入门教程12-25
-
MySQL集群部署资料:新手入门教程12-24
-
MySQL集群资料详解:新手入门教程12-24
-
MySQL集群部署入门教程12-24
-
部署MySQL集群学习:新手入门教程12-24
-
部署MySQL集群入门:一步一步搭建指南12-24
-
MySQL读写分离入门:轻松掌握数据库读写分离技术12-07
-
MySQL读写分离入门教程12-07
-
MySQL分库分表入门详解12-07
-
MySQL分库分表入门指南12-07
-
MySQL慢查询入门:快速掌握性能优化技巧12-07
-
MySQL入门:新手必读的简单教程12-07
-
MySQL入门:从零开始学习MySQL数据库12-07
-
MySQL索引入门:新手快速掌握MySQL索引技巧12-07
-
BinLog学习:MySQL数据库BinLog入门教程12-06
