Java教程
Flink State 初认识

大家好,我是大圣。
最近工作中使用Flink 状态比较多,但是遇到了各种各样的问题,比如应该什么时候使用KeyedState,什么时候应该使用Operator State,还有StateTTL过期的问题。趁着周末有时间,就把Flink 状态给总结一下。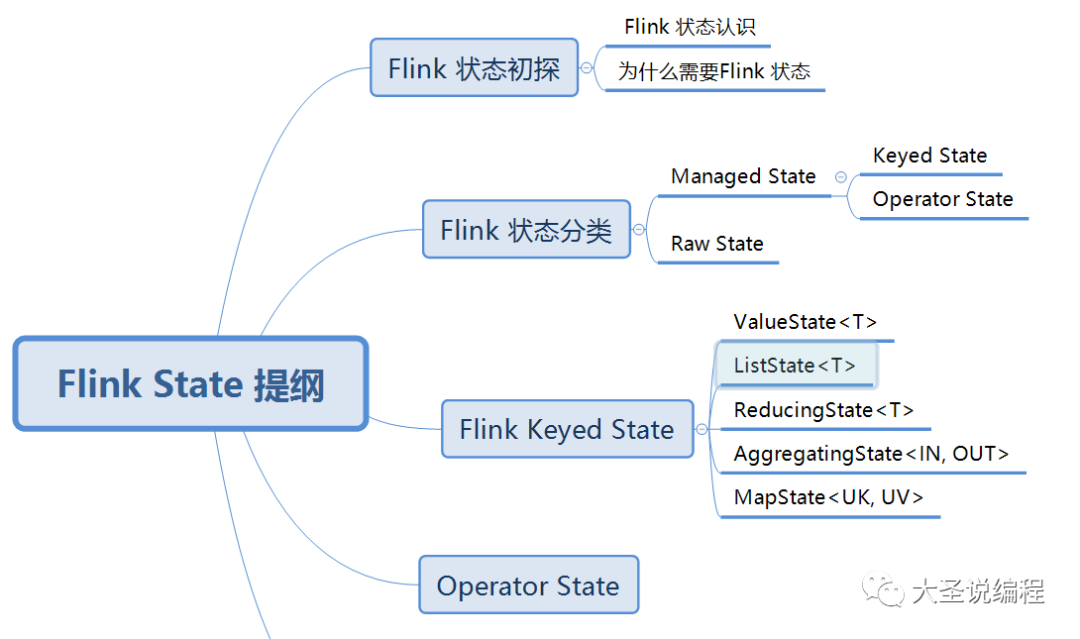
Flink 状态初探
熟悉Flink框架的小伙伴都知道Flink是一个实时流处理计算引擎,什么是流处理呢?我们来举个生活中的案例,大圣小时候在河边长大,坐船上学的时候经常看到水流从上流不停的往下流,而且是不会停止流动的。对比到Flink是一个实时流处理来说就是Flink流处理就像水流一样,一直流动,不会停止。在河流里面流动的水,而在Flink流里面流动的是数据,Flink就会针对这些流动的数据进行计算。
Flink 状态认识
Flink 状态官方的解释是在一个Flink任务的各个子任务里面,每一个子任务都会维护一个本地变量,这个本地变量就是Flink 状态。这里面的各个子任务的意思是说Flink是个并行运行的程序,当你启动Flink程序的时候,会传入并行度 -p 这个参数,比如你传入的是 -p 6 这就表示你写的这个Flink 任务会被复制成6份,6个线程同时在处理数据,这6个线程就相当于6个子任务。如下图: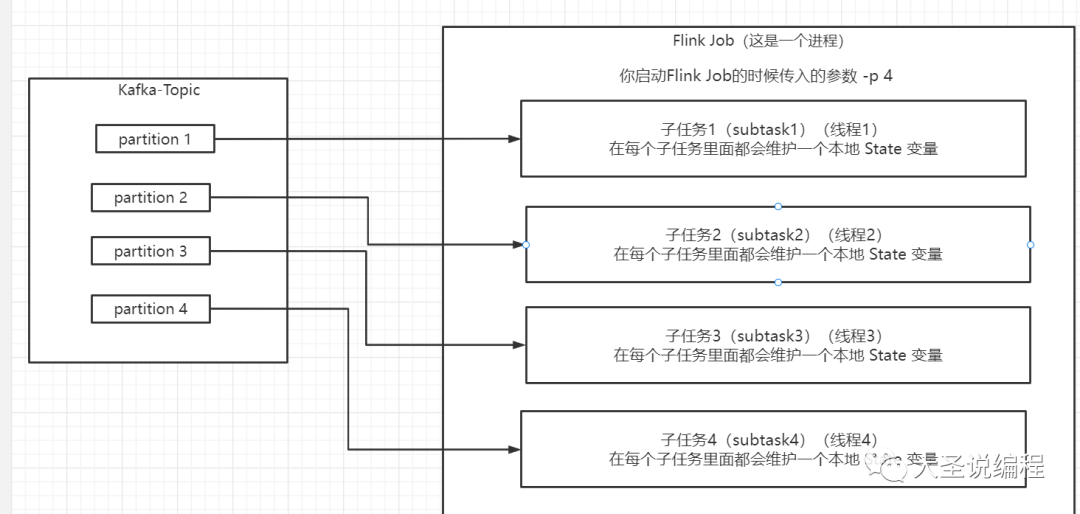
这个变量里面保存可能是流入的数据或者基于窗口计算的数据,这就是Flink State。
为什么需要Flink 状态
大家可以想象这样一个场景,我现在想计算数字1-50累加起来的和是多少。前面介绍Flink 是一个流处理的计算引擎,它的计算就是你每来一条数据我把当前来的数据给累加起来,如果你不对这些数据进行保存,这些数据就没有了。假如此次进来的数据是10,把数字10累加上去得到的累加值就是55,但是此时程序异常退出了,那么此时我再把程序启动起来,再进来的数字应该就是11了,那么就是55 + 11 = 66 。但是如果你如果不把此时这个累加值55保存下来的话,当程序异常退出过后再重新启动的时候,这个累计值就是0了,其实这也是流处理的特征,数据转瞬即逝,如果这个数据在你的程序处理中留下了痕迹,那么这个痕迹就是状态,就是前面累加的值56。说到这里总结起来就是Flink 状态是为了做容错的,当程序发生异常或者有些特定的场景需要对处理过后的数据进行再次使用的时候,这个时候我们就需要状态去实现。
Flink 状态的分类
有了上面知识的铺垫,下面我们就正式讲一下Flink State的细节知识了。
Flink 状态分为两种:托管状态(Managed State)和原生状态(Raw State)。其中两者的区别:Managed State 是由Flink框架去管理的,比如你这个状态该怎么去存储,恢复,优化等,其中Managed State中又包括Keyed State和Operator State。而Raw State 是需要你自己去维护,自己去定义存储,计算管理的,需要自己开发。
这两种状态的对比,大家可以参考生活中的一个场景:比如张三现在想提升一下学历,然后他就有两种选择,一种是托管的就是你找一个机构,然后按时给机构钱,报名,作业,考试啥都不用管了;还有一种就是你不找机构,你自己去做这些事。对比到Flink状态里面是一样的,Flink里面的托管状态就是你只管用就行了,原生状态就是你什么都要操心。
Keyed State
Managed State中又包括Keyed State和Operator State,下面我们先来说Keyed State。
Keyed State是必须作用于KeyedStream上的,就是说如果我们想使用Keyed State的话,我们在使用之前必须进行keyBy操作。假如我们把输入流按照userId进行了keyBy,这样的话就会形成一个KeyedStream,在数据流中所有userId为1的数据都会共享这一个状态,userId为2的会共享另外一个状态,就是说它会根据你keyBy的值去把输入进来的数据和状态绑定起来,你keyBy的值不同,这个数据就会绑定在不同的状态中。总结一句话就是Keyed State 是根据你keyBy的值去绑定数据的,如下图: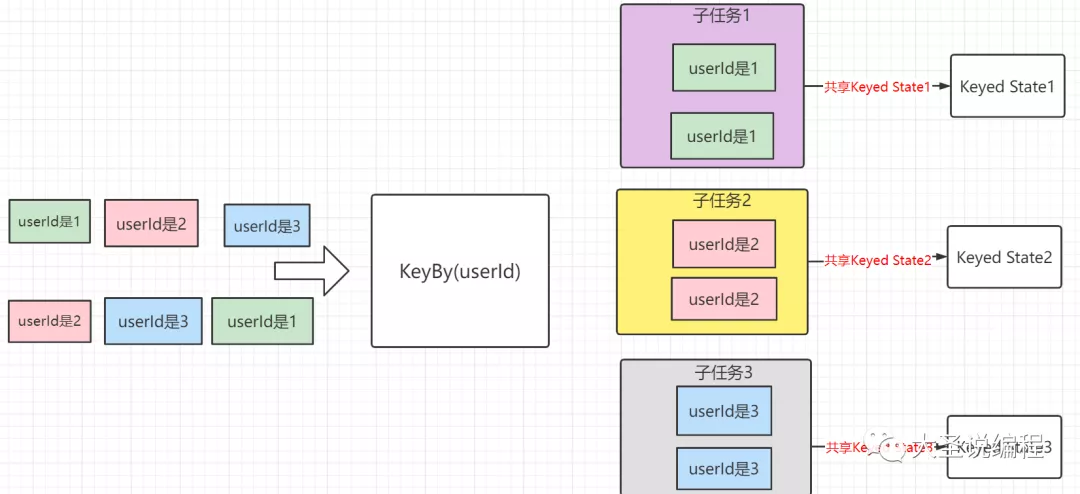
下面我们看看Keyed State在代码中怎么去使用,他总共有下面几种类型:
ValueState:其实这个State大家可以把它和Java里面的基本数据类型做比较,
我觉得它就是一个什么类型都可以存储的基本数据或者引用类型类型的状态,比如int,long,float,String等。
然后根据你输入的keyBy的值不同,就会有多个值,就是你一个key对应一个值。
ListState:
ReducingState
AggregatingState<IN, OUT>
MapState<UK, UV>:这个大家帮它当初Java里面的Map来使用,还是根据你输入的keyBy的值不同,就会有多个值,
就是你一个key对应一个值,但是不同的是一个key所对应的值是一个Map
下面重点来说ValueState和MapState<UK, UV>的实战。
ValueState:
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception {
// access the state value
Tuple2<Long, Long> currentSum = sum.value();
if (currentSum == null) {
currentSum = Tuple2.of(0L, 0l);
}
// update the count
currentSum.f0 += 1;
// add the second field of the input value
currentSum.f1 += value.f1;
// update the state
sum.update(currentSum);
// if the count reaches 2, emit the average and clear the state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(value.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
ValueStateDescriptor<Tuple2<Long, Long>> descriptor = new ValueStateDescriptor<>(
"average",
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {
}));
sum = getRuntimeContext().getState(descriptor);
}
}
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(value -> value.f0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)
大家一下子看到这么多代码,不用很烦,我给你讲解一遍就很简单了,先说一下这个代码的结构:
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(value -> value.f0)
.flatMap(new CountWindowAverage())
.print();
这是构建了一个二元组的数据源,然后根据二元组里面的第一个元素就行keyBy,这里所有二元组的第一个元素都是1L;接着进行flatMap()算子的操作,这里面自己实现了一个类去继承了RichFlatMapFunction;最后进行print()打印。
下面重点说CountWindowAverage 类里面的方法。
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
/**
* The ValueState handle. The first field is the count, the second field a running sum.
*/
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// access the state value
Tuple2<Long, Long> currentSum = sum.value();
if (currentSum == null) {
currentSum = Tuple2.of(0L, 0l);
}
// update the count
currentSum.f0 += 1;
// add the second field of the input value
currentSum.f1 += value.f1;
// update the state
sum.update(currentSum);
// if the count reaches 2, emit the average and clear the state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(value.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor = new ValueStateDescriptor<>(
"average",
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {
})); // default value of the state, if nothing was set
sum = getRuntimeContext().getState(descriptor);
}
}
首先定义了private transient ValueState<Tuple2<Long, Long>> sum; 状态属性,然后在open()方法里面创建了ValueStateDescriptor 对象,在创建这个对象的时候传入三个参数,第一个参数是你定义的这个状态的名字,第二个参数是你这个ValueStateDescriptor 对象的泛型,最后把你定义的这个对象给放到上下文的状态里面,这样你就可以使用你定义的这个sum状态了。
接着在flatMap 方法中首先获取我们输入key所对应的状态,像我们上面这个程序第一条数据它的key是1L,进来的话肯定这个状态里面的值是空的,因为还没有对状态里面的值进行初始化,如果sum状态里面的值为空的话就把这个状态里面的值进行初始化,接着把这个key的数量进行加1,然后把二元组里面的第二个值累加到sum状态中,当1这个key的状态sum第一个值到2时,就做平平均数,然后清空这个状态。这就是上面这段代码的逻辑。
在这里面要注意的有三点:
第一,Flink处理数据的时候是一条数据一条数据处理的,就是Tuple2.of(1L, 3L)这条数据先把上面的程序跑一遍,然后第二条数据Tuple2.of(1L, 5L)再把上面的数据跑一遍,一次类推。
第二,这个sum状态是和输入元素key来绑定的,就是我们上面这个输入元素的key都为1,所以后面进入的元素里面sum状态里面的value都不为空的,如果我们有多个key的话,那么每个key是和sum状态绑定的,每个key共享一个状态。
第三,其实我们在用状态的时候,可以考虑只有一个key的情况,然后我这个方法里怎么去组织这个逻辑实现我们的业务,因为我当初刚开始用状态的时候总是考虑有多个key,然后每个key怎么办,但是随着对flink框架的理解加深之后,你就会发现每一个key和keyed State共享都是一样的,所以我觉得这样可以帮忙捋顺逻辑关系。
MapState<UK, UV>:分享一个用Flink MapState实现过滤五天连续登录用户的需求,代码如下:
package com.jsdesign.bigdata.utils.processutil;
import com.jsdesign.bigdata.bean.useraction.UserActionBean;
import com.jsdesign.bigdata.common.TimeExchange;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import java.util.List;
public class ContinuousLProcessFunction extends KeyedProcessFunction<String, UserActionBean, UserActionBean> {
private MapState<String, Long> mapState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
StateTtlConfig stateTtlConfig = StateTtlConfig
// 状态有效时间 6天过期
.newBuilder(Time.days(6))
// 设置状态的更新类型
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 已过期还未被清理掉的状态数据不返回给用户
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
// 过期对象的清理策略 全量清理
.cleanupIncrementally(10, true)
.build();
MapStateDescriptor descriptor = new MapStateDescriptor("MapDescriptor", String.class, Long.class);
descriptor.enableTimeToLive(stateTtlConfig);
mapState = getRuntimeContext().getMapState(descriptor);
}
@Override
public void processElement(UserActionBean userActionBean,
KeyedProcessFunction<String, UserActionBean, UserActionBean>.Context context,
Collector<UserActionBean> out) throws Exception {
try {
System.out.println("timestamp:" + userActionBean.getTimestamp() + "\t" + "userId:" + userActionBean.getUserId());
boolean flag = true;
//根据数据发生的时间,拿到前面四天的时间
List<String> preDateByDate = TimeExchange.getPreDateByDate(userActionBean.getTimestamp());
for (String s : preDateByDate) {
if (!mapState.contains(s)) {
flag = false;
break;
}
}
if (!mapState.contains(userActionBean.getTimestamp())) {
mapState.put(userActionBean.getTimestamp(), 1L);
if (flag) {
out.collect(userActionBean);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Data
public class UserActionBean {
private String userId; private String timestamp;
}
你要使用状态还是之前的三部曲:
第一,定义private MapState<String, Long> mapState;属性
第二,创建MapStateDescriptor对象,传进去两个参数MapStateDescriptor descriptor = new MapStateDescriptor(“MapDescriptor”, String.class, Long.class);
第三,把状态描述符给设置到上下文对象中,我们创建的mapState属性就可以用了mapState = getRuntimeContext().getMapState(descriptor);
这里需要说明一点是MapStateDescriptor里面第二个参数的泛型需要和mapState属性的泛型保持一致。
然后你把MapState当成Java里面的Map集合用就行了。
Operator State
这个Operator State 其实就是上文说的在一个Flink任务的各个子任务里面,每一个子任务都会维护一个本地变量,这个本地变量就是Flink 状态。Operator State 是和一个Flink 任务的各个子任务去绑定在一起的,比如我们用Flink 从Kafka消费数据的时候,一个Flink的各个子任务会和Kafka的分区去对应着消费,然后我们每个子任务都会绑定一个Operator State状态去记录消费Kafa的分区和offset。还可以在子任务个数发生变化的时候重新分配各个Operator State 状态,可以理解Operator State是宏观上的状态,Keyed State 是微观上的状态,Operator State不用我们去管理,比如它会保存一些窗口里面的数据,当这个窗口结束,Operator State保存的数据也会被清除,但是当我们使用Keyed State 的时候,Flink框架是不会主动帮我们清除的,需要我们调用clear方法或者设置状态的TTL属性。
今天的文章就写到这里了,总结一下,主要讲了以下几个方面:
第一,Flink框架流式处理的概念,就像水流一样永不停息,每来一条数据处理一下去执行我们写的逻辑。
第二,什么是Flink 的状态,以及Flink为什么需要状态,状态就是每个子任务的一个变量,状态是为了留下痕迹。
第三,Flink 状态的分类 Managed State 托管状态;Raw State自定义状态(什么都要操心),其中Managed State 又包括Keyed State和Operator State。
第四,Flink Keyed State的认识和使用。
第五,Operator State的概念。
后续的计划是接着说Flink 状态的TTL,状态后端,Checkpoint等这一系列的知识。其中有一点想说一下,文章中的许多概念是我自己先翻译了Flink官网,然后根据自己翻译的官网再加上自己对Flink的认识,跟生活中的场景进行了整合与思考,因为我觉得学一个东西要有自己独立的部分,面试的时候面试官想听到的也是关于这个框架你自己的理解与思考。
最后希望大家能通过这一系列的文章让大家对大数据有不一样的认知,我们一起努力,提高独立思考的能力。
-
消息中间件底层原理资料详解11-27
-
RocketMQ底层原理资料详解:新手入门教程11-27
-
MQ底层原理资料详解:新手入门教程11-27
-
MQ项目开发资料入门教程11-27
-
RocketMQ源码资料详解:新手入门教程11-27
-
本地多文件上传简易教程11-27
-
消息中间件源码剖析教程11-26
-
JAVA语音识别项目资料的收集与应用11-26
-
Java语音识别项目资料:入门级教程与实战指南11-26
-
SpringAI:Java 开发的智能新利器11-26
-
Java云原生资料:新手入门教程与实战指南11-26
-
JAVA云原生资料入门教程11-26
-
Mybatis官方生成器资料详解与应用教程11-26
-
Mybatis一级缓存资料详解与实战教程11-26
-
Mybatis一级缓存资料详解:新手快速入门11-26
