Java教程
Flink State 又认识

大家好,我叫大圣。
上周没有及时更新 Flink 状态的文章,原因是我有点懒了,上周末放了一天假就想躺平,然后我就和我的手机过了一天。以后请小伙伴们监督,一定按时更新文章。话不多说,咱们进入今天的主题内容。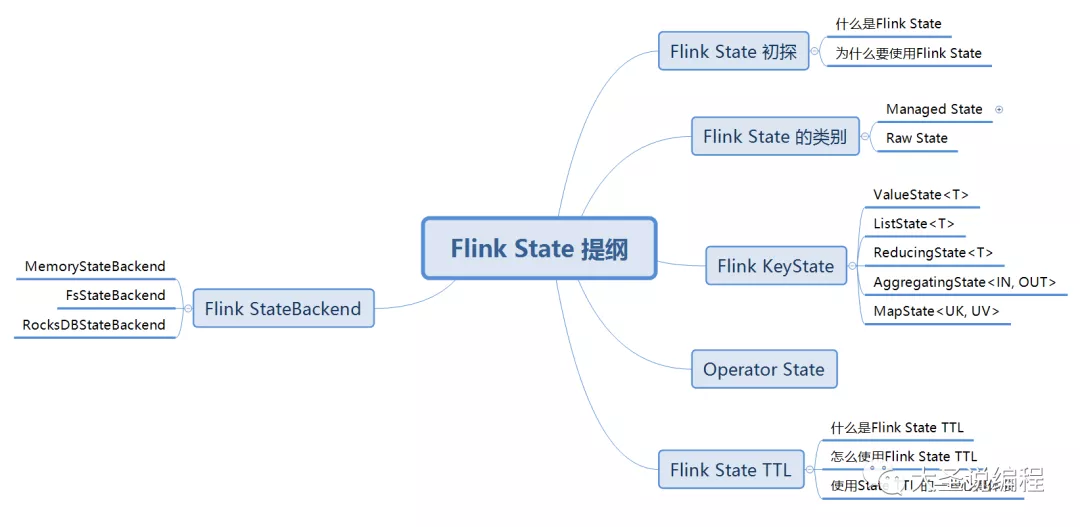
先来简单回顾一下,上一次的文章我们说了Flink 状态的基本概念,分类,以及KeyState的使用等。也就是上图Flink State 提纲中的 Flink State 初探、Flink State 的类别、Flink KeyState、Operator State这四个方面的知识,如果有小伙伴对上面这四个方面的知识还有不了解的可以去看Flink State 初认识这篇文章。那下面就开始说Flink State提纲中剩下的知识。
Flink State TTL
上文说到Managed State是托管状态,意思就是Managed State 是由Flink框架去管理的,比如你这个状态该怎么去存储,恢复,优化等都由Flink框架去管理。其中Managed State中又包括Keyed State和Operator State,Operator State的创建和清除是由Flink 框架去管理。但是Keyed State是作用于KeyedStream上的,是我们自己用户自己创建的状态,比如我创建一个MapState去保存连续五天登录的用户,那么我这个状态一般要保存五天的用户,但是此时你如果交给Flink框架去清除状态,很有可能Flink框架在第三天的时候就把你的状态的数据给清空了,这样显然是不行的。所以这里需要用户自己去指定我们自己创建的状态什么时候过期被清除,但是这里我刚开始疑惑,我们自己创建的这个Keyed State 永远不过期,一直保存着不行吗?答案是是不行的,因为这样的话状态会保存的数据越来越多,这是肯定不可取的,所以就有了我们说的这个 State TTL。
什么是Flink State TTL
State TTL 全称是 State Time-To-Live。其实就是Flink 状态的生存时间(下文简称过期时间),这里要注意的是我们这里说的State TTL是针对于Keyed State来说的,就是我们自己在代码里面定义的那些ValueState、MapState等,当你定义了这些状态的过期时间,当状态中的数据满足了过期时间的条件,这个状态的数据就会被清除。那么什么时候会满足这个过期时间的条件呢?在这里先说一个结论,当前时间的时间戳 > 上一次访问状态的时间戳 + TTL设置的过期时间的时间戳。这里不理解不用怕,后面我会配合具体的代码把这个结论说清楚。
怎么使用Flink State TTL
怎么使用Flink State TTL,话不多说,直接上代码
private transient ValueState valueStateTTL;
StateTtlConfig stateTtlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
// 设置状态的更新类型
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 已过期还未被清理掉的状态数据不返回给用户
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
// 过期对象的清理策略 增量清理
.cleanupIncrementally(1, true)
.build();
ValueStateDescriptor valueStateDescriptor =
new ValueStateDescriptor<>(“valueStateTTL”, String.class);
valueStateDescriptor.enableTimeToLive(stateTtlConfig);
valueStateTTL = getRuntimeContext().getState(valueStateDescriptor);
}
首先这里利用三部曲定义了一个ValueState:
第一,定义valueStateTTL;属性
第二,创建ValueStateDescriptor对象
第三,把状态描述符给设置到上下文对象中,我们创建的valueStateTTL属性就可以用了ValueStateDescriptor valueStateDescriptor =new ValueStateDescriptor<>(“valueStateTTL”, String.class);
然后我们重点来说状态TTL的定义:
StateTtlConfig stateTtlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
// 设置状态的更新类型
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 已过期还未被清理掉的状态数据不返回给用户
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
// 过期对象的清理策略 增量清理
.cleanupIncrementally(1, true)
.build();
newBuilder(Time.seconds(1)):表示这个状态的TTL是多少,就是这个状态的过期时间是多少;
setUpdateType():表示状态的时间戳的更新方式,主要有三种方式
setUpdateType
Disabled
表示TTL是禁用的,状态永远不过期。
OnCreateAndWrite
状态的时间戳只有在更新状态数据的时候才会更新,也就是调用update()方法的时候才更新。
OnReadAndWrite
更新状态的时间戳在读取状态数据和更新状态数据的时候会更新,也就是在调用value()方法和update()方法的时候会更新。
setStateVisibility():表示过期状态数据的可见性,主要有两种方式
setStateVisibility
ReturnExpiredIfNotCleanedUp
如果这个状态已经是过期了,但是这个状态的数据没有被清理(状态的清理只有在读取的时候才会被清理),就仍然返回给用户
NeverReturnExpired
只要这个状态已经过期,就永远不返回给用户
CleanupStrategies有三种清除清理策略:
cleanupFullSnapshot()
当发生checkpoint的时候对状态进行全量快照的时候才会清理过期状态,它只能保证在checkpoint的时候不存在过期的状态,但是对于TaskManager的堆内存中的状态不做处理,所以还是有发生OOM的风险。
cleanupIncrementally(int cleanupSize,boolean xxx )
这是增量清理过期状态,默认在每次访问状态的时候进行对过期数据的清理,将第二个参数设置为true,就可以在状态写入数据或者清除数据的时候进行清理。第一个参数是每次触发清理时要检查数据的条数。注意,这种清理方式只对于状态后端是堆的有效,也就是只对状态后端是Memory和FlieSystem,对RocksDB是无效的。
cleanupInRocksdbCompactFilter(long queryTimeAfterNumEntries)
该策略仅对RocksDB状态后端有效。
下面我们来实践一个状态过期的案例。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
String topic = "test";
String groupId = "user-login";
FlinkKafkaConsumer<String> kafkaSource = MyKafkaUtil.getKafkaSource(topic, groupId);
DataStreamSource<String> kafkaDS = env.addSource(kafkaSource);
kafkaDS
.flatMap(new FlatMapFunction<String, ValueBean>() {
@Override
public void flatMap(String value, Collector<ValueBean> out) throws Exception {
String[] s = value.split(" ");
ValueBean valueBean = new ValueBean();
valueBean.setUserId(s[0]);
valueBean.setTime(s[1]);
out.collect(valueBean);
}
})
.keyBy(value -> value.getUserId())
.process(new ValueProcessFunction());
env.execute();
public class ValueProcessFunction extends KeyedProcessFunction<String, ValueBean, ValueBean> {
private transient ValueState valueStateTTL;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
StateTtlConfig stateTtlConfig = StateTtlConfig
.newBuilder(Time.minutes(1))
// 设置状态的更新类型
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
// 已过期还未被清理掉的状态数据不返回给用户
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
// 过期对象的清理策略 增量清理
.cleanupIncrementally(1, true)
.build();
ValueStateDescriptor valueStateDescriptor =
new ValueStateDescriptor<>(“testValueStateTTL”, String.class);
valueStateTTL = getRuntimeContext().getState(valueStateDescriptor);
valueStateDescriptor.enableTimeToLive(stateTtlConfig);
}
@Override
public void processElement(ValueBean value,
KeyedProcessFunction<String, ValueBean, ValueBean>.Context ctx,
Collector out) throws Exception {
String s = valueStateTTL.value();
if (s == null) {
s = value.getUserId();
}
valueStateTTL.update(s);
System.out.println(valueStateTTL.value());
}
}
程序的逻辑就是从kafka消费数据,然后进行keyBy,再接一个process()函数对keyBy过后的数据进行处理,然后在process()函数里面定义了一个ValueState,对状态的TTL也进行了设置,这里主要讲两点:
第一,我们要主要这个ValueState是根据keyBy的值的不同去创建的,就是不同的key会有不同的ValueState。
第二,状态是什么时候过期?就是当前的时间戳 > 访问状态数据的时间戳 + 状态的TTL时间戳,举个例子你就会明白:
假如我们访问数据的时间是2021-12-04 15:20:27,我们设置的TTL是1分钟,那么如果当前时间来到了2021-12-04 15:21:28的时候,我们这个数据就会过期。虽然这个状态数据已经过期了,但是我们还能不能访问到这个状态是不一定的,这就看我们上面的几个参数是怎么配置的了。
如果你setStateVisibility指定的是NeverReturnExpired,你的状态后端是基于堆内存的,并且你设置的是清理方式是cleanupIncrementally,这样的话你再去访问这个状态的时候得到数据就是null。
使用State TTL 的一些心得体会
要结合自己的业务去设置合理的TTL
比如我在生产中就犯过一次很低级的错误,有个需求是统计连续五天登录的用户,我之前想到五天过后肯定前一天的状态数据就不需要了,然后我就把状态的TTL设置了1天,然后去生产环境跑了五天的数据,发现没有一个连续登录的用户,然后复盘业务和代码才发现这个问题。
选择的状态后端要和你配置的清理策略要匹配
就是如果你的状态后端是基于堆内存的,你就选择增量清理的方式;如果你的状态后端是RocketsDB,你就要选择cleanupInRocksdbCompactFilter清理方式。
合理配置你数据的可见性
就是setStateVisibility这个参数,你要根据你具体的业务判断你已经过期的数据是否还返回给用户。
MapState的状态的TTL
MapState的状态的TTL是针对于MapState里面的这个key过期的,就是你设置了TTL是10s,针对的是MapState<key,value>里面的这个key,不是你keyby时候的那个key,keyby不同的值有不同的MapState,但是这个MapState是否过期是针对你MapState<key,value>这里面的key来说的。
MapState是针对MapState里面的这个key过期的,这个我在本地测试过了,如果感兴趣的,可以加我,我把源码分享给你。
在这里多说一句,我看了网上几乎所有说Flink状态TTL的文章,他们给的状态过期的条件都是:那么如果上次访问的时间戳 + TTL 超过了当前时间,则表明状态过期了。然后我就觉得这种说法不对,然后自己写代码测试了很多遍才得出结论。
当前的时间戳 > 访问状态数据的时间戳 + 状态的TTL时间戳 状态才会过期。
Flink State TTL说了很多,如果上边的内容你都没有记得,那么我给你总结一下比较关键的几点,你记住几个关键的点也行:
Flink State TTL 的针对我们自己写的Keyed State,比如ValueState,MapState过期的,是为了避免内存OOM和让我们更灵活的使用状态。
使用Flink State TTL 的时候先走我们创建Flink 状态的三部曲,然后设置相对应的属性。
注意你的选择的状态后端和清理方式要匹配。
Flink StateBackend
前面说到Managed State 是由Flink框架进行保存管理的,但是为了用户更加灵活的使用Flink 状态,Flink提供了三种开箱即用状态后端来保存状态。我们前文说状态就是Flink 子任务实例中的一个本地变量,那这个本地变量保存在哪呢?其实就是保存在状态后端,状态后端就是用来保存状态的。这样说比较抽象,你可以这样理解状态就好比我们的货物,状态后端就是我们的仓库,仓库是用来保存货物的。Flink 提供了三种不同的状态后端来保存状态。
MemoryStateBackend
如果我们写Flink程序的时候没有配置状态后端的话,那默认用的状态后端就是MemoryStateBackend,这个时候状态是保存在MemoryStateBackend里面的,而MemoryStateBackend是保存在TaskManager堆内存中的,所以当我们使用MemoryStateBackend状态后端的时候,我们的状态是保存在TaskManager的堆内存里面的,当Checkpoint完成过后会把状态后端的状态保存在JobManager的内存中。
优点
速度快。
缺点
每个状态存储的数据大小有限制,最大为5MB
数据存储在内存中,程序宕机数据就没有了
使用场景
本地调试
FsStateBackend
FsStateBackend 也是把状态保存在TaskManager堆内存中的,然后当发生checkpoint的时候把状态存储到你指定的文件系统路径。我们可以在代码里面这样设置 :
env.setStateBackend(new FsStateBackend(“file:///xxx”));
也可以在flink-conf.yaml中进行全局的配置:
state.backend:filesystem
state.checkpoint.dir:hdfs://hadoop101:9000/checkpoints
其中:
filesystem 表示使用 FsStateBackend
jobmanager 表示使用 MemoryStateBackend
rocksdb 表示使用 RocksDBStateBackend
FsStateBackend适用场景:
大状态、长窗口、大key/value状态的的任务
RocksDBStateBackend
RocksDB是一个基于LSM实现的KV数据库,它是把状态一部分保存在磁盘里,一部分保存在内存中,当ckeckpoint完成过后把状态再更新到指定的地方。这里注意如果要使用RocksDBStateBackend的话,首先需要添加依赖包。
适用场景
大状态、长窗口、大key/value状态的的任务
总结一下keyedState 数据存储和Operator State 数据存储
keyedState 数据存储:
StateBackend类型 运行过程中存储位置 Checkpoint存储位置 适用场景
memory TM 内存中 JM 内存中 调试(生产环境严禁使用)
filesystem TM 内存中 hdfs 状态较小的场景,性能极高
Rocksdb TM 本地的 RocksDB 中 hdfs 大状态场景
Operator State 数据存储:
StateBackend类型 运行过程中存储位置 Checkpoint存储位置 适用场景
memory TM 内存中 JM 内存中 调试(生产环境严禁使用)
filesystem TM 内存中 hdfs 生产环境
Rocksdb TM 内存中 hdfs 生产环境
最后这个keyedState 数据存储和Operator State 数据存储来自公众号:大数据渣渣瑞,是一位来自大厂的非常厉害的大数据高级开发工程师,他的公众号里面有很多大数据的干货,感兴趣的可以去关注一下 大数据渣渣瑞 这个公众号。
好了,今天的内容就到这里了,今天讲了Flink 状态的TTL, Flink 状态后端这两块的内容。
-
消息中间件底层原理资料详解11-27
-
RocketMQ底层原理资料详解:新手入门教程11-27
-
MQ底层原理资料详解:新手入门教程11-27
-
MQ项目开发资料入门教程11-27
-
RocketMQ源码资料详解:新手入门教程11-27
-
本地多文件上传简易教程11-27
-
消息中间件源码剖析教程11-26
-
JAVA语音识别项目资料的收集与应用11-26
-
Java语音识别项目资料:入门级教程与实战指南11-26
-
SpringAI:Java 开发的智能新利器11-26
-
Java云原生资料:新手入门教程与实战指南11-26
-
JAVA云原生资料入门教程11-26
-
Mybatis官方生成器资料详解与应用教程11-26
-
Mybatis一级缓存资料详解与实战教程11-26
-
Mybatis一级缓存资料详解:新手快速入门11-26
