Java教程
尚硅谷数仓实战之3数仓搭建

B站直达:2021新版电商数仓V4.0丨大数据数据仓库项目实战
百度网盘:https://pan.baidu.com/s/1FGUb8X0Wx7IWAmKXBRwVFg ,提取码:yyds
阿里云盘:https://www.aliyundrive.com/s/F2FuMVePj92 ,提取码:335o
第4章 数仓搭建-ODS层
1)保持数据原貌不做任何修改,起到备份数据的作用。
2)数据采用LZO压缩,减少磁盘存储空间。100G数据可以压缩到10G以内。
3)创建分区表,防止后续的全表扫描,在企业开发中大量使用分区表。
4)创建外部表。在企业开发中,除了自己用的临时表,创建内部表外,绝大多数场景都是创建外部表。
4.2 ODS层(业务数据)
ODS层业务表分区规划如下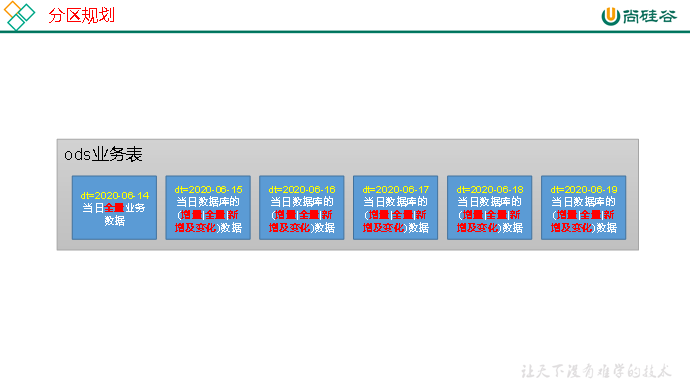
ODS层业务表数据装载思路如下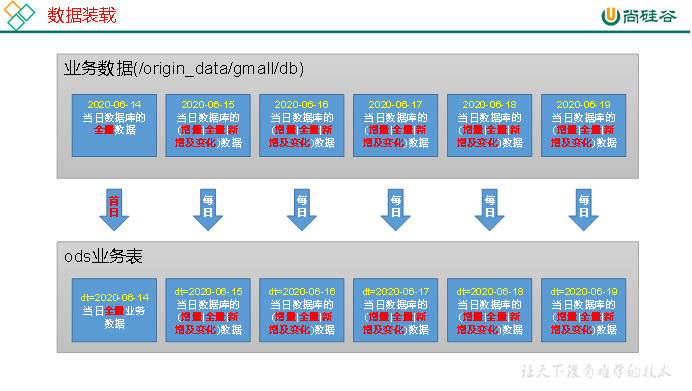
4.2.1 活动信息表
DROP TABLE IF EXISTS ods_activity_info; CREATE EXTERNAL TABLE ods_activity_info( `id` STRING COMMENT '编号', `activity_name` STRING COMMENT '活动名称', `activity_type` STRING COMMENT '活动类型', `start_time` STRING COMMENT '开始时间', `end_time` STRING COMMENT '结束时间', `create_time` STRING COMMENT '创建时间' ) COMMENT '活动信息表' PARTITIONED BY (`dt` STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS INPUTFORMAT 'com.hadoop.mapred.DeprecatedLzoTextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION '/warehouse/gmall/ods/ods_activity_info/';
第5章 数仓搭建-DIM层
5.1 商品维度表(全量)
1.建表语句
DROP TABLE IF EXISTS dim_sku_info;
CREATE EXTERNAL TABLE dim_sku_info (
`id` STRING COMMENT '商品id',
`price` DECIMAL(16,2) COMMENT '商品价格',
`sku_name` STRING COMMENT '商品名称',
`sku_desc` STRING COMMENT '商品描述',
`weight` DECIMAL(16,2) COMMENT '重量',
`is_sale` BOOLEAN COMMENT '是否在售',
`spu_id` STRING COMMENT 'spu编号',
`spu_name` STRING COMMENT 'spu名称',
`category3_id` STRING COMMENT '三级分类id',
`category3_name` STRING COMMENT '三级分类名称',
`category2_id` STRING COMMENT '二级分类id',
`category2_name` STRING COMMENT '二级分类名称',
`category1_id` STRING COMMENT '一级分类id',
`category1_name` STRING COMMENT '一级分类名称',
`tm_id` STRING COMMENT '品牌id',
`tm_name` STRING COMMENT '品牌名称',
`sku_attr_values` ARRAY<STRUCT<attr_id:STRING,value_id:STRING,attr_name:STRING,value_name:STRING>> COMMENT '平台属性',
`sku_sale_attr_values` ARRAY<STRUCT<sale_attr_id:STRING,sale_attr_value_id:STRING,sale_attr_name:STRING,sale_attr_value_name:STRING>> COMMENT '销售属性',
`create_time` STRING COMMENT '创建时间'
) COMMENT '商品维度表'
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dim/dim_sku_info/'
TBLPROPERTIES ("parquet.compression"="lzo");
2.分区规划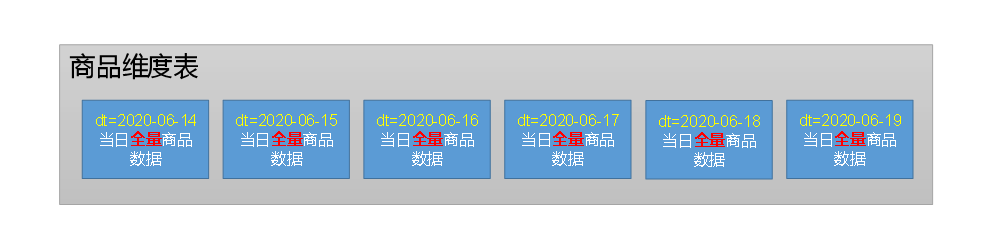
3.数据装载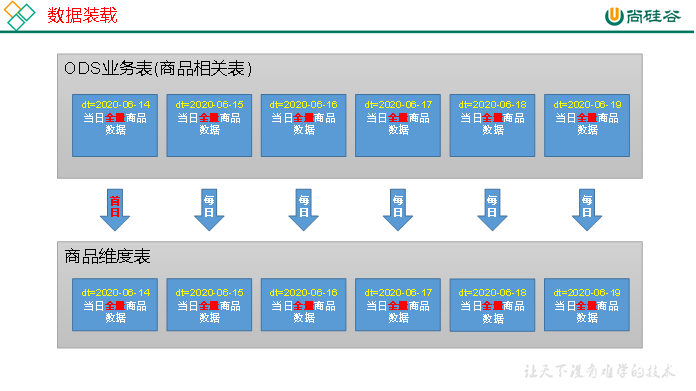
5.6 用户维度表(拉链表)
5.6.1 拉链表概述
1)什么是拉链表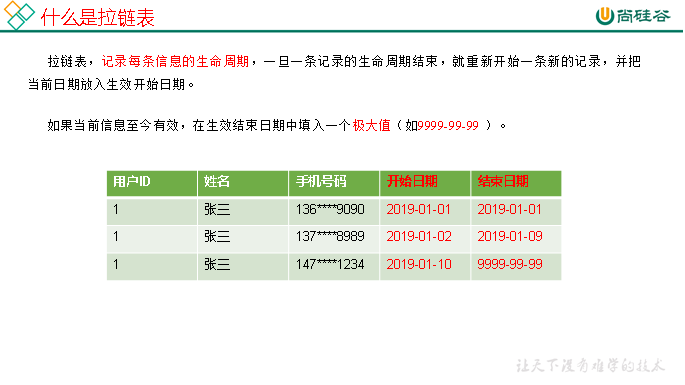
2)为什么要做拉链表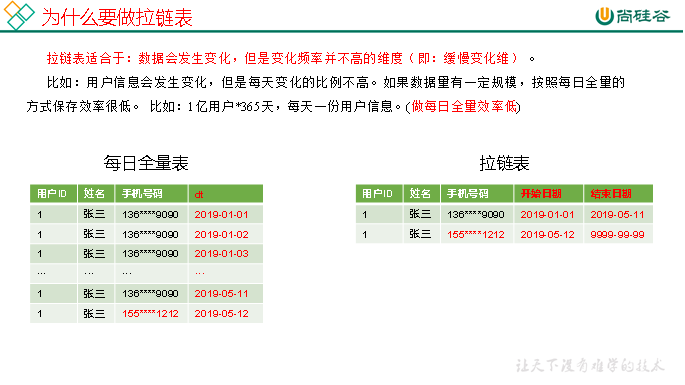
3)如何使用拉链表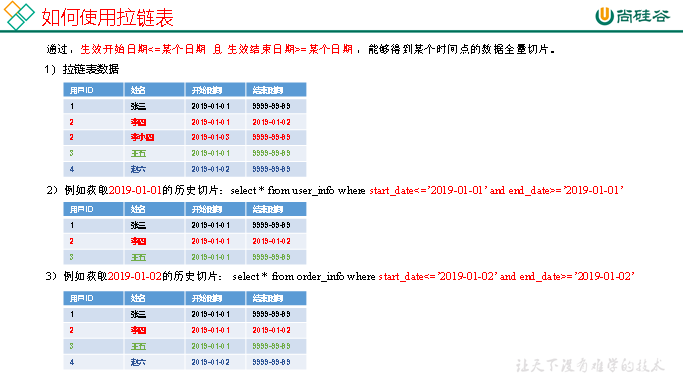
4)拉链表形成过程
5.6.2 制作拉链表
1.建表语句
DROP TABLE IF EXISTS dim_user_info;
CREATE EXTERNAL TABLE dim_user_info(
`id` STRING COMMENT '用户id',
`login_name` STRING COMMENT '用户名称',
`nick_name` STRING COMMENT '用户昵称',
`name` STRING COMMENT '用户姓名',
`phone_num` STRING COMMENT '手机号码',
`email` STRING COMMENT '邮箱',
`user_level` STRING COMMENT '用户等级',
`birthday` STRING COMMENT '生日',
`gender` STRING COMMENT '性别',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '操作时间',
`start_date` STRING COMMENT '开始日期',
`end_date` STRING COMMENT '结束日期'
) COMMENT '用户表'
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dim/dim_user_info/'
TBLPROPERTIES ("parquet.compression"="lzo");
2.分区规划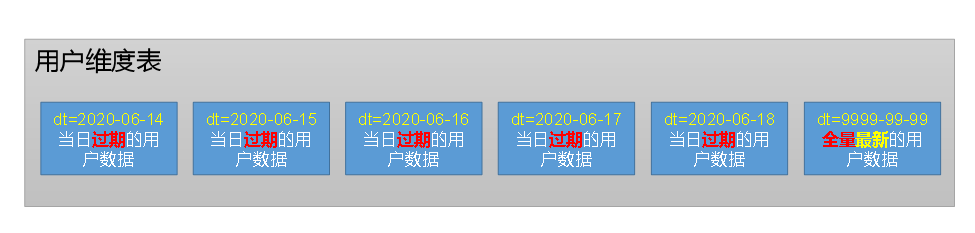
3.数据装载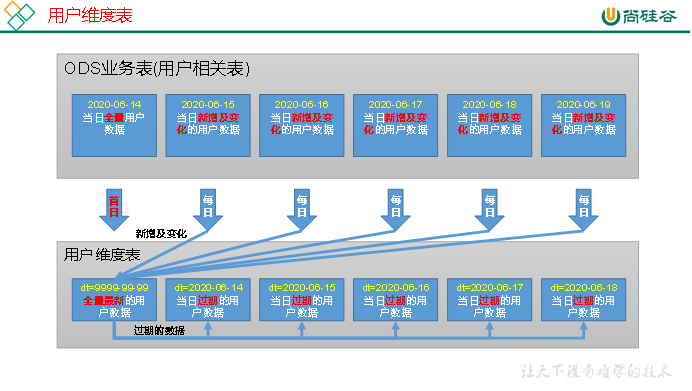
1)首日装载
拉链表首日装载,需要进行初始化操作,具体工作为将截止到初始化当日的全部历史用户导入一次性导入到拉链表中。目前的ods_user_info表的第一个分区,即2020-06-14分区中就是全部的历史用户,故将该分区数据进行一定处理后导入拉链表的9999-99-99分区即可。
2)每日装载
(1)实现思路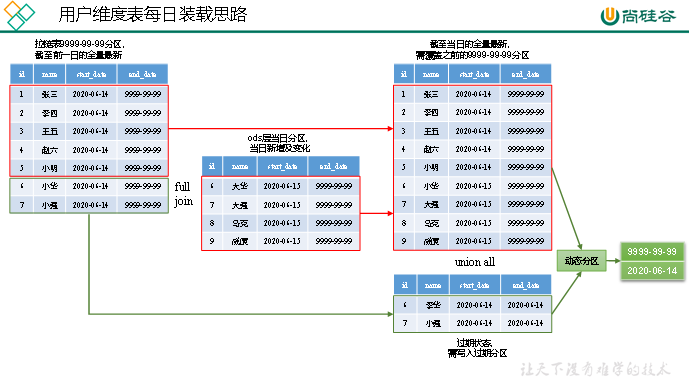
第6章 数仓搭建-DWD层
1)对用户行为数据解析。
2)对业务数据采用维度模型重新建模。
6.1 DWD层(用户行为日志)
6.1.1 日志解析思路
1)日志结构回顾
(1)页面埋点日志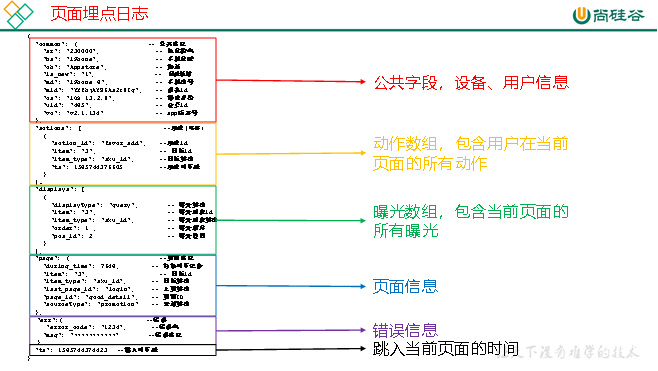
(2)启动日志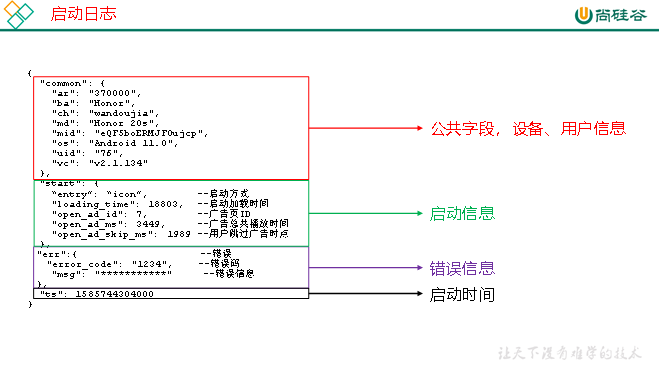
2)日志解析思路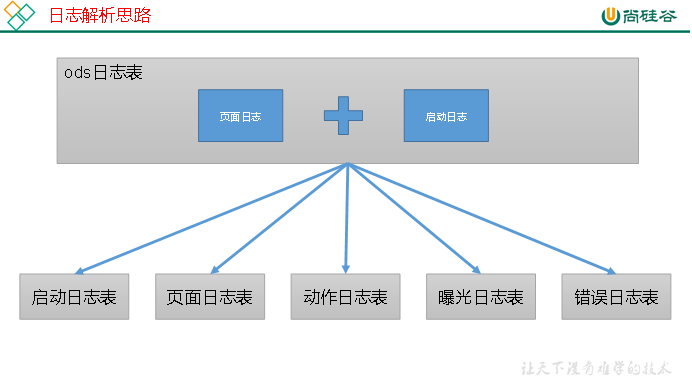
6.1.2 json_object函数使用
Mysql中也有响应的JSON处理函数,不过性能没有hive高。
6.1.3 启动日志表
启动日志解析思路:启动日志表中每行数据对应一个启动记录,一个启动记录应该包含日志中的公共信息和启动信息。先将所有包含start字段的日志过滤出来,然后使用get_json_object函数解析每个字段。
1)建表语句
DROP TABLE IF EXISTS dwd_start_log;
CREATE EXTERNAL TABLE dwd_start_log(
`area_code` STRING COMMENT '地区编码',
`brand` STRING COMMENT '手机品牌',
`channel` STRING COMMENT '渠道',
`is_new` STRING COMMENT '是否首次启动',
`model` STRING COMMENT '手机型号',
`mid_id` STRING COMMENT '设备id',
`os` STRING COMMENT '操作系统',
`user_id` STRING COMMENT '会员id',
`version_code` STRING COMMENT 'app版本号',
`entry` STRING COMMENT 'icon手机图标 notice 通知 install 安装后启动',
`loading_time` BIGINT COMMENT '启动加载时间',
`open_ad_id` STRING COMMENT '广告页ID ',
`open_ad_ms` BIGINT COMMENT '广告总共播放时间',
`open_ad_skip_ms` BIGINT COMMENT '用户跳过广告时点',
`ts` BIGINT COMMENT '时间'
) COMMENT '启动日志表'
PARTITIONED BY (`dt` STRING) -- 按照时间创建分区
STORED AS PARQUET -- 采用parquet列式存储
LOCATION '/warehouse/gmall/dwd/dwd_start_log' -- 指定在HDFS上存储位置
TBLPROPERTIES('parquet.compression'='lzo') -- 采用LZO压缩
;
6.1.4 页面日志表
页面日志解析思路:页面日志表中每行数据对应一个页面访问记录,一个页面访问记录应该包含日志中的公共信息和页面信息。先将所有包含page字段的日志过滤出来,然后使用get_json_object函数解析每个字段。
6.1.5 动作日志表
动作日志解析思路:动作日志表中每行数据对应用户的一个动作记录,一个动作记录应当包含公共信息、页面信息以及动作信息。先将包含action字段的日志过滤出来,然后通过UDTF函数,将action数组“炸开”(类似于explode函数的效果),然后使用get_json_object函数解析每个字段。
6.1.7 错误日志表
错误日志解析思路:错误日志表中每行数据对应一个错误记录,为方便定位错误,一个错误记录应当包含与之对应的公共信息、页面信息、曝光信息、动作信息、启动信息以及错误信息。先将包含err字段的日志过滤出来,然后使用get_json_object函数解析所有字段。
6.2 DWD层(业务数据)
业务数据方面DWD层的搭建主要注意点在于维度建模。这边只是展示一个订单明细的实例,全部的文档请下载尚硅谷数仓实战笔记。
6.2.2 订单明细事实表(事务型事实表)
1)建表语句
DROP TABLE IF EXISTS dwd_order_detail;
CREATE EXTERNAL TABLE dwd_order_detail (
`id` STRING COMMENT '订单编号',
`order_id` STRING COMMENT '订单号',
`user_id` STRING COMMENT '用户id',
`sku_id` STRING COMMENT 'sku商品id',
`province_id` STRING COMMENT '省份ID',
`activity_id` STRING COMMENT '活动ID',
`activity_rule_id` STRING COMMENT '活动规则ID',
`coupon_id` STRING COMMENT '优惠券ID',
`create_time` STRING COMMENT '创建时间',
`source_type` STRING COMMENT '来源类型',
`source_id` STRING COMMENT '来源编号',
`sku_num` BIGINT COMMENT '商品数量',
`original_amount` DECIMAL(16,2) COMMENT '原始价格',
`split_activity_amount` DECIMAL(16,2) COMMENT '活动优惠分摊',
`split_coupon_amount` DECIMAL(16,2) COMMENT '优惠券优惠分摊',
`split_final_amount` DECIMAL(16,2) COMMENT '最终价格分摊'
) COMMENT '订单明细事实表表'
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dwd/dwd_order_detail/'
TBLPROPERTIES ("parquet.compression"="lzo");
2)分区规划
3)数据装载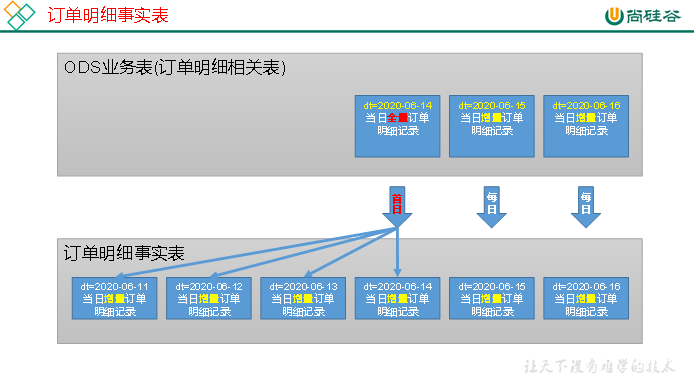
6.2.4 加购事实表(周期型快照事实表,每日快照)
1)建表语句
DROP TABLE IF EXISTS dwd_cart_info;
CREATE EXTERNAL TABLE dwd_cart_info(
`id` STRING COMMENT '编号',
`user_id` STRING COMMENT '用户ID',
`sku_id` STRING COMMENT '商品ID',
`source_type` STRING COMMENT '来源类型',
`source_id` STRING COMMENT '来源编号',
`cart_price` DECIMAL(16,2) COMMENT '加入购物车时的价格',
`is_ordered` STRING COMMENT '是否已下单',
`create_time` STRING COMMENT '创建时间',
`operate_time` STRING COMMENT '修改时间',
`order_time` STRING COMMENT '下单时间',
`sku_num` BIGINT COMMENT '加购数量'
) COMMENT '加购事实表'
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dwd/dwd_cart_info/'
TBLPROPERTIES ("parquet.compression"="lzo");
2)分区规划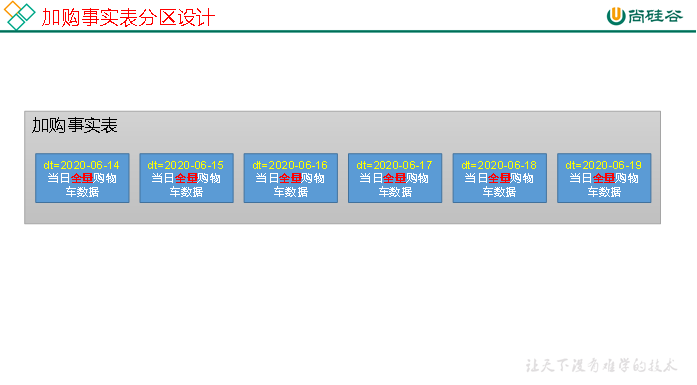
3)数据装载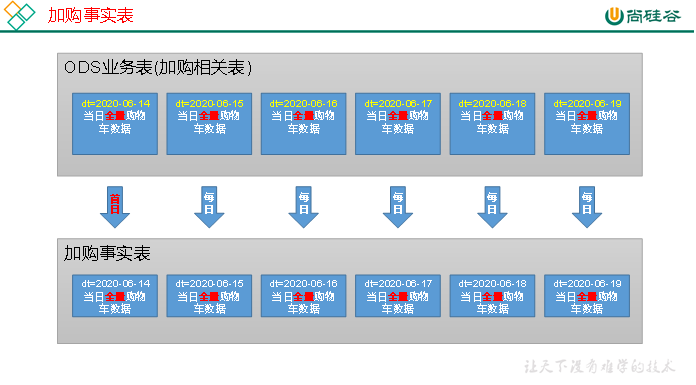
6.2.7 支付事实表(累积型快照事实表)
1)建表语句
DROP TABLE IF EXISTS dwd_payment_info;
CREATE EXTERNAL TABLE dwd_payment_info (
`id` STRING COMMENT '编号',
`order_id` STRING COMMENT '订单编号',
`user_id` STRING COMMENT '用户编号',
`province_id` STRING COMMENT '地区ID',
`trade_no` STRING COMMENT '交易编号',
`out_trade_no` STRING COMMENT '对外交易编号',
`payment_type` STRING COMMENT '支付类型',
`payment_amount` DECIMAL(16,2) COMMENT '支付金额',
`payment_status` STRING COMMENT '支付状态',
`create_time` STRING COMMENT '创建时间',--调用第三方支付接口的时间
`callback_time` STRING COMMENT '完成时间'--支付完成时间,即支付成功回调时间
) COMMENT '支付事实表表'
PARTITIONED BY (`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dwd/dwd_payment_info/'
TBLPROPERTIES ("parquet.compression"="lzo");
2)分区规划
3)数据装载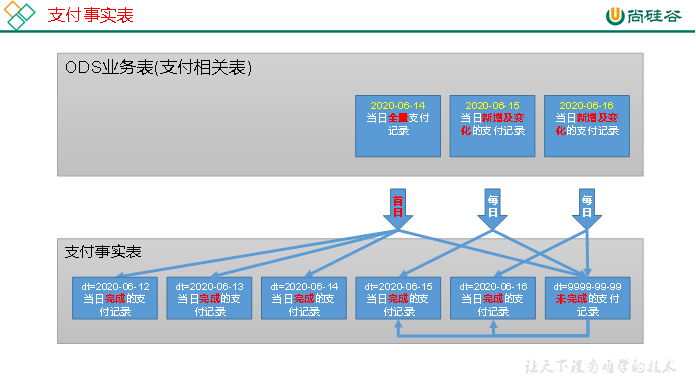
第7章 数仓搭建-DWS层
7.2 DWS层
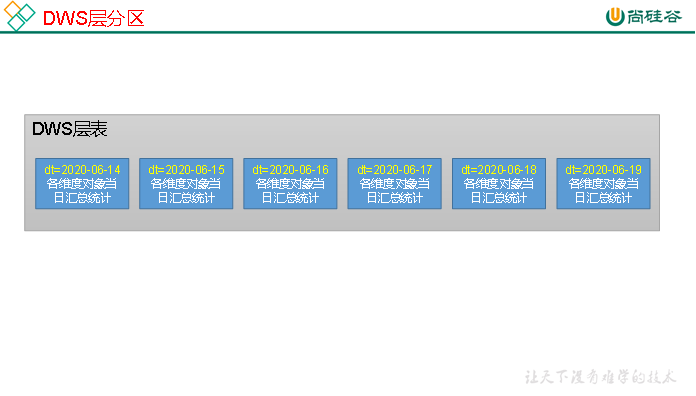
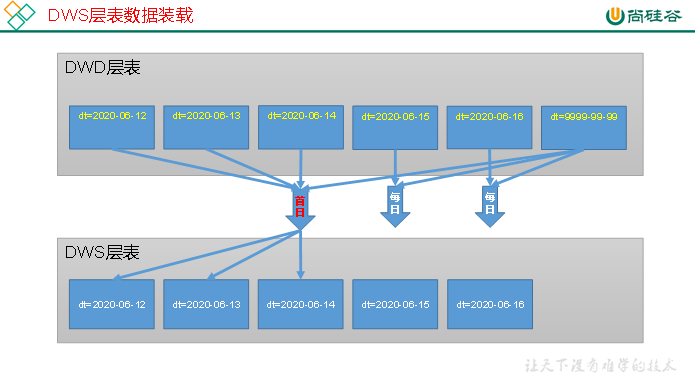
7.2.1 访客主题
1)建表语句
DROP TABLE IF EXISTS dws_visitor_action_daycount;
CREATE EXTERNAL TABLE dws_visitor_action_daycount
(
`mid_id` STRING COMMENT '设备id',
`brand` STRING COMMENT '设备品牌',
`model` STRING COMMENT '设备型号',
`is_new` STRING COMMENT '是否首次访问',
`channel` ARRAY<STRING> COMMENT '渠道',
`os` ARRAY<STRING> COMMENT '操作系统',
`area_code` ARRAY<STRING> COMMENT '地区ID',
`version_code` ARRAY<STRING> COMMENT '应用版本',
`visit_count` BIGINT COMMENT '访问次数',
`page_stats` ARRAY<STRUCT<page_id:STRING,page_count:BIGINT,during_time:BIGINT>> COMMENT '页面访问统计'
) COMMENT '每日设备行为表'
PARTITIONED BY(`dt` STRING)
STORED AS PARQUET
LOCATION '/warehouse/gmall/dws/dws_visitor_action_daycount'
TBLPROPERTIES ("parquet.compression"="lzo");
第8章 数仓搭建-DWT层
第9章 数仓搭建-ADS层
9.1 建表说明
ADS层不涉及建模,建表根据具体需求而定。
9.3 用户主题
9.3.1 用户统计
该需求为用户综合统计,其中包含若干指标,以下为对每个指标的解释说明。
| 指标 | 说明 | 对应字段 |
|---|---|---|
| 新增用户数 | 统计新增注册用户人数 | new_user_count |
| 新增下单用户数 | 统计新增下单用户人数 | new_order_user_count |
| 下单总金额 | 统计所有订单总额 | order_final_amount |
| 下单用户数 | 统计下单用户总数 | order_user_count |
| 未下单用户数 | 统计活跃但未下单用户数 | no_order_user_count |
1.建表语句
DROP TABLE IF EXISTS ads_user_total; CREATE EXTERNAL TABLE `ads_user_total` ( `dt` STRING COMMENT '统计日期', `recent_days` BIGINT COMMENT '最近天数,0:累积值,1:最近1天,7:最近7天,30:最近30天', `new_user_count` BIGINT COMMENT '新注册用户数', `new_order_user_count` BIGINT COMMENT '新增下单用户数', `order_final_amount` DECIMAL(16,2) COMMENT '下单总金额', `order_user_count` BIGINT COMMENT '下单用户数', `no_order_user_count` BIGINT COMMENT '未下单用户数(具体指活跃用户中未下单用户)' ) COMMENT '用户统计' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/warehouse/gmall/ads/ads_user_total/';
9.3.2 用户变动统计
该需求包括两个指标,分别为流失用户数和回流用户数,以下为对两个指标的解释说明。
| 指标 | 说明 | 对应字段 |
|---|---|---|
| 流失用户数 | 之前活跃过的用户,最近一段时间未活跃,就称为流失用户。此处要求统计7日前(只包含7日前当天)活跃,但最近7日未活跃的用户总数。 | user_churn_count |
| 回流用户数 | 之前的活跃用户,一段时间未活跃(流失),今日又活跃了,就称为回流用户。此处要求统计回流用户总数。 | new_order_user_count |
1.建表语句
DROP TABLE IF EXISTS ads_user_change; CREATE EXTERNAL TABLE `ads_user_change` ( `dt` STRING COMMENT '统计日期', `user_churn_count` BIGINT COMMENT '流失用户数', `user_back_count` BIGINT COMMENT '回流用户数' ) COMMENT '用户变动统计' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/warehouse/gmall/ads/ads_user_change/';
9.3.3 用户行为漏斗分析
漏斗分析是一个数据分析模型,它能够科学反映一个业务过程从起点到终点各阶段用户转化情况。由于其能将各阶段环节都展示出来,故哪个阶段存在问题,就能一目了然。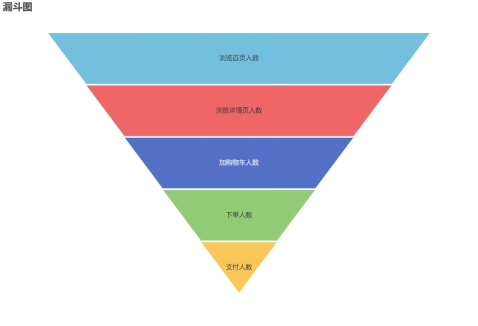
该需求要求统计一个完整的购物流程各个阶段的人数。
1.建表语句
DROP TABLE IF EXISTS ads_user_action; CREATE EXTERNAL TABLE `ads_user_action` ( `dt` STRING COMMENT '统计日期', `recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天', `home_count` BIGINT COMMENT '浏览首页人数', `good_detail_count` BIGINT COMMENT '浏览商品详情页人数', `cart_count` BIGINT COMMENT '加入购物车人数', `order_count` BIGINT COMMENT '下单人数', `payment_count` BIGINT COMMENT '支付人数' ) COMMENT '漏斗分析' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/warehouse/gmall/ads/ads_user_action/';
9.3.4 用户留存率
留存分析一般包含新增留存和活跃留存分析。
新增留存分析是分析某天的新增用户中,有多少人有后续的活跃行为。活跃留存分析是分析某天的活跃用户中,有多少人有后续的活跃行为。
留存分析是衡量产品对用户价值高低的重要指标。
此处要求统计新增留存率,新增留存率具体是指留存用户数与新增用户数的比值,例如2020-06-14新增100个用户,1日之后(2020-06-15)这100人中有80个人活跃了,那2020-06-14的1日留存数则为80,2020-06-14的1日留存率则为80%。
要求统计每天的1至7日留存率,如下图所示。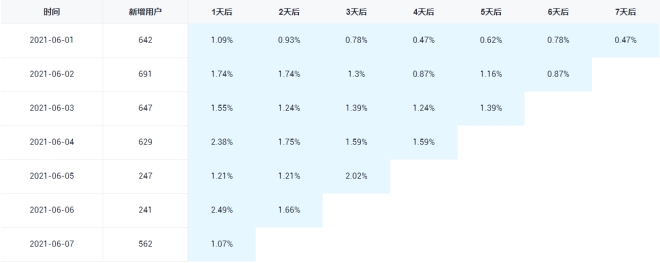
1.建表语句
DROP TABLE IF EXISTS ads_user_retention; CREATE EXTERNAL TABLE ads_user_retention ( `dt` STRING COMMENT '统计日期', `create_date` STRING COMMENT '用户新增日期', `retention_day` BIGINT COMMENT '截至当前日期留存天数', `retention_count` BIGINT COMMENT '留存用户数量', `new_user_count` BIGINT COMMENT '新增用户数量', `retention_rate` DECIMAL(16,2) COMMENT '留存率' ) COMMENT '用户留存率' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/warehouse/gmall/ads/ads_user_retention/';
9.5 订单主题
9.5.1 订单统计
该需求包含订单总数,订单总金额和下单总人数。
1.建表语句
DROP TABLE IF EXISTS ads_order_total; CREATE EXTERNAL TABLE `ads_order_total` ( `dt` STRING COMMENT '统计日期', `recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天', `order_count` BIGINT COMMENT '订单数', `order_amount` DECIMAL(16,2) COMMENT '订单金额', `order_user_count` BIGINT COMMENT '下单人数' ) COMMENT '订单统计' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/warehouse/gmall/ads/ads_order_total/';
9.5.2 各地区订单统计
该需求包含各省份订单总数和订单总金额。
1.建表语句
DROP TABLE IF EXISTS ads_order_by_province; CREATE EXTERNAL TABLE `ads_order_by_province` ( `dt` STRING COMMENT '统计日期', `recent_days` BIGINT COMMENT '最近天数,1:最近1天,7:最近7天,30:最近30天', `province_id` STRING COMMENT '省份ID', `province_name` STRING COMMENT '省份名称', `area_code` STRING COMMENT '地区编码', `iso_code` STRING COMMENT '国际标准地区编码', `iso_code_3166_2` STRING COMMENT '国际标准地区编码', `order_count` BIGINT COMMENT '订单数', `order_amount` DECIMAL(16,2) COMMENT '订单金额' ) COMMENT '各地区订单统计' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LOCATION '/warehouse/gmall/ads/ads_order_by_province/';
第10章 全流程调度
-
Java中定时任务实现方式及源码剖析11-24
-
Java中定时任务实现方式及源码剖析11-24
-
鸿蒙原生开发手记:03-元服务开发全流程(开发元服务,只需要看这一篇文章)11-24
-
细说敏捷:敏捷四会之每日站会11-24
-
Springboot应用的多环境打包入门11-23
-
Springboot应用的生产发布入门教程11-23
-
Python编程入门指南11-23
-
Java创业入门:从零开始的编程之旅11-23
-
Java创业入门:新手必读的Java编程与创业指南11-23
-
Java对接阿里云智能语音服务入门详解11-23
-
Java对接阿里云智能语音服务入门教程11-23
-
JAVA对接阿里云智能语音服务入门教程11-23
-
Java副业入门:初学者的简单教程11-23
-
JAVA副业入门:初学者的实战指南11-23
-
JAVA项目部署入门:新手必读指南11-23
