C/C++教程
excel数据处理一:巧妙使用openpyxl提取、筛选数据

本文主要是介绍excel数据处理一:巧妙使用openpyxl提取、筛选数据,对大家解决编程问题具有一定的参考价值,需要的程序猿们随着小编来一起学习吧!
目前openpyxl只支持[.xlsx / .xlsm / .xltx / .xltm]格式的文件,有人说,openpyxl是最好用的excel数据处理插件,这个excel的数据处理插件确实相当可以。主要是它的操作简单、并且处理数据的方式更容易理解。

openpyxl 官网地址
https://openpyxl.readthedocs.io/en/stable/
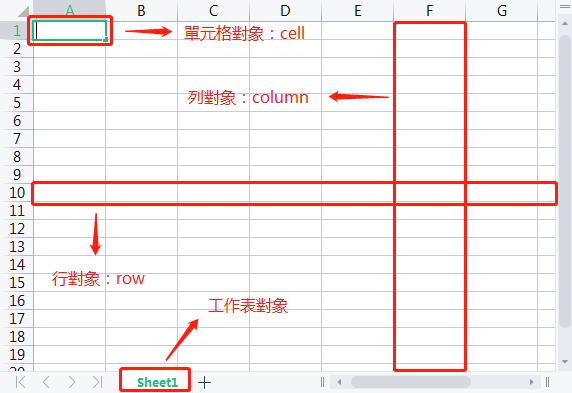
在openpyxl的excel数据处理中,一个单元格对象使用cell表示,每一行数据称之为row,每一列数据称之为column。excel文件中的工作空间称之为sheet,下面使用我准备好的一张图片来说明一下。
from openpyxl import load_workbook # 导入excel的处理对象
workbook = load_workbook(filename = "./data.xlsx") # 加载excel文件
print(workbook.sheetnames) # 获取当前excel表格中的所有的表空间
# 获取一个表工作空间对象
sheet = workbook["Sheet2"]
# 获取表空间对象的数据有几行几列
print(sheet.dimensions)
# 获取某个单元格的数据
cell_1 = sheet["A1"]
print('A1单元格的数据是:',cell_1.value)
通过定位到第几行第几列的方式获取某个单元格的数据。
cell_2 = sheet.cell(row = 2,column = 2)
获取某个区域的单元然后遍历
# 提取区域中的所有单元格对象
cell_3 = sheet["A1:C5"]
print('A1:C5 的数据对象是',cell_3)
for row in cell_3: # 遍历每一行的单元格
for column in row: # 遍历每一列的单元格
print(column.value) # 提取当前单元格的数据
行、列数据读取方式
'''
按行读取数据
iter_rows(min_row=1, max_row=10, min_col=1, max_col=5)
min_row: 设置最小行数
max_row: 设置最大行数
min_col: 设置最小列数
max_col: 设置最大列数
'''
for row in sheet.iter_rows(min_row=1, max_row=10, min_col=1, max_col=5):
for column in row:
print(column.value)
'''
按列读取数据
iter_cols(min_row=1, max_row=10, min_col=1, max_col=5)
min_row: 设置最小行数
max_row: 设置最大行数
min_col: 设置最小列数
max_col: 设置最大列数
'''
for column in sheet.iter_cols(min_row=1, max_row=10, min_col=1, max_col=5):
for row in column:
print(row.value)
'''
读取所有行数据
sheet.rows
'''
for row in sheet.rows:
print(row) # 打印每一行的数据
这篇关于excel数据处理一:巧妙使用openpyxl提取、筛选数据的文章就介绍到这儿,希望我们推荐的文章对大家有所帮助,也希望大家多多支持为之网!
您可能喜欢
-
怎么实现ansible playbook 备份代码中命名包含时间戳功能?-icode9专业技术文章分享11-22
-
ansible 的archive 参数是什么意思?-icode9专业技术文章分享11-22
-
ansible 中怎么只用archive 排除某个目录?-icode9专业技术文章分享11-22
-
exclude_path参数是什么作用?-icode9专业技术文章分享11-22
-
微信开放平台第三方平台什么时候调用数据预拉取和数据周期性更新接口?-icode9专业技术文章分享11-22
-
uniapp 实现聊天消息会话的列表功能怎么实现?-icode9专业技术文章分享11-22
-
在Mac系统上将图片中的文字提取出来有哪些方法?-icode9专业技术文章分享11-22
-
excel 表格中怎么固定一行显示不滚动?-icode9专业技术文章分享11-22
-
怎么将 -rwxr-xr-x 修改为 drwxr-xr-x?-icode9专业技术文章分享11-22
-
在Excel中怎么将小数向上取整到最接近的整数?-icode9专业技术文章分享11-22
-
Excel中常见的取整函数有哪些?-icode9专业技术文章分享11-22
-
错误信息:does not match the actual quantity supplied 提示是什么意思?-icode9专业技术文章分享11-22
-
WebSocket学习:初学者的简单指南11-21
-
获取apk的md5值有哪些方法?-icode9专业技术文章分享11-20
-
xml报文没有传 IdentCode ,为什么正常解析没报错呢?-icode9专业技术文章分享11-20
栏目导航
