云计算
中通大数据平台在大促中的进化

一年一度的双十一又双叒叕来了,给技术人最好的礼物就是大促技术指南! 而经过这些年的发展,大促早已不仅仅局限于电商行业,现在各行各业其实都会采用类似方式做运营活动,汽车界有 818,电商有 618 、11.11 等等,各种各样的大促场景,对包括数据库在内的基础软件提出了很多新挑战,同时也积累了诸多最佳实践。
在双十一到来前,PingCAP 与汽车之家、易车网、京东、中通等用户展开一系列深入探讨,希望为大家揭秘逐年飙升的销量背后隐藏着什么样的技术难题?用什么技术架构才能平稳地扛住流量洪峰?
点击此处观看完整采访参与互动,有机会获得 TiDB 定制周边!
大促中,大家买买买后最期盼的事情就是收到快递。成立于 2002 年的中通快递,是一家以快递为主体,以国际、快运、云仓、商业、冷链、金融、智能、星联、传媒为辅的综合物流服务品牌。2020年,中通完成业务量 170 亿件,市场占有份额达到 20.4%。
整个快递的生命周期、转运周期可以用五个字来概括——收、发、到、派、签:
而支撑整个快递生命周期的平台就是中通大数据平台。中通从离线到实时的数据兼容再到数仓,有着一套比较完善的大数据平台体系。ETL 建模也会依托该大数据平台,最终通过大数据平台对外提供数据应用的支持以及基于离线 OLAP 分析的支持,整个数据建模的频率可以支持到半小时级别。在这个完善的大数据平台基础上,中通开始更多地思考如何增强实时多维分析能力。
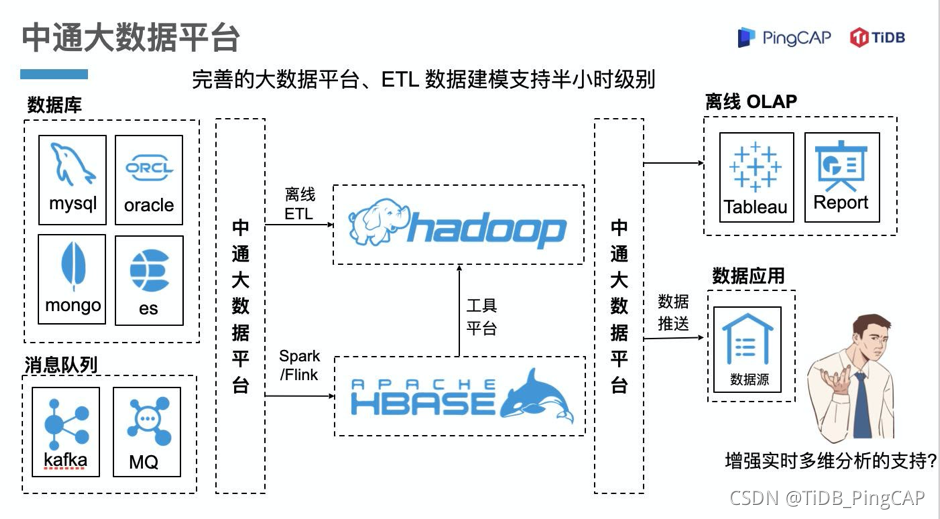
中通与 TiDB 的结缘是在 2017 年调研分库分表场景时开始的。当时中通分库分表达到 16000 张表,业务上已经无法再继续扩展下去。2018 年底,中通开始测试 TiDB 2.0,主要关注的是大数据量的存储,以及分析性能。2019 年年初,中通上线了生产应用的支持。目前生产上稳定的版本是 TiDB 3.0.14 。2020 年底,中通开始测试 TiFlash,目标期望有两点:一是提高时效,二是降低硬件使用情况。
1.0 时代——满足需求
1.0 是满足需求的时代,业务需求主要包含以下几点:
- 业务发展非常快,数据量非常大,每笔订单更新有 5-6 次,操作有峰值;
- 做过调研的技术方案,很难支撑多维分析的需求;
- 业务方对数据分析的周期要求比较长;
- 对分析时效要求也很高;
- 单机性能瓶颈,包括单点故障、风险高,这些也是在业务上不能忍受的;
- 除此之外,QPS 也很高,应用要求毫秒级响应。
技术需求方面,中通需要打通多个业务场景 + 多个业务指标;需要强一致的分布式事务,在原有业务模式下切换的代价很小;还需要对整个分析计算工程化,下线原来的存储过程;能够支持高并发的读写、更新;能够支持在线的维护,保证单点的故障对业务是没有影响;同时,还要与现有的大数据技术生态紧密结合在一起,做到分钟级的统计分析;最后是中通一直在探索的,即要建立 100 + 列以上的大宽表,基于这张宽表,要做到多维度的查询分析。
目前 TiDB 在中通应用的一些落地场景
时效系统应用场景
其中,时效系统是中通原有的一套系统,现在已经进行了重构。这套系统原来的存储和计算主要是依赖 Oracle 设计的,计算依赖存储过程。这套架构也比较简单,一边是消息的接入,一边是负载。
随着业务体量的增长,这一套架构的性能已经逐渐出现瓶颈。在对这套系统进行架构升级时,中通把整个存储迁移到 TiDB 上,整个计算迁移到 TiSpark。消息接入依赖于 Spark Link,通过消息队列最终到 TiDB。TiSpark 会提供分钟级的一些计算,轻度汇总会到 Hive,中度汇总会到 MySQL。基于 Hive,通过 Presto 对外提供应用的服务。相较原来关系型数据库的分表,无论是 OLTP 还是 OLAP 都极大地降低了开发的工作量,并且和现有的大数据生态技术栈相融合。
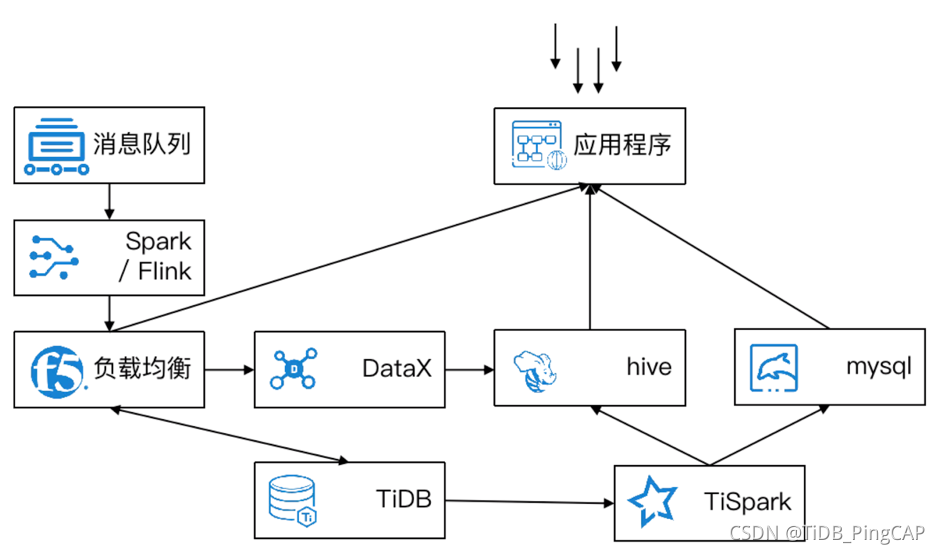
1.0 时代中通的数据库系统架构
迁移带来的收益有很多:第一是容量的增长,原来的数据中心有三倍的富余,已有系统数据存储周期增加到三倍以上;第二,在可扩展性方面,支持在线横向扩展,运维可以随时上下计算和存储节点,应用的感知很小;第三,满足了高性能的 OLTP 业务需求,查询性能虽略有降低的,但是符合业务需求;第四,数据库单点压力没有了,OLTP 和 OLAP 实现“分离”,互不干扰;第五,支持了更多维度的分析需求;第六,整体架构看起来比原来更清晰,可维护性增强,系统的可扩展性也增强了许多。
大宽表应用场景
另一个场景是中通一直在做的宽表的建设与摸索。其实之前中通测过很多系统,包括 Hbase、Kudu。Kudu 的写入性能还是很不错的,但是其社区活跃度在国内一般。同时,中通使用 impala 作为 OLAP 查询引擎,但主流使用的是 Presto,兼容性有待考虑,也很难满足所有业务场景需求。此外,中通的业务特性要求系统能够快速地计算分析几十亿的数据,并能同步到离线的集群里与 T+1 数据做融合,还要能提供给数据产品和数据服务直连拉取明细数据。最后是海量数据的处理,中通有很多消息源的接入,需要针对每一票进行全链路路由和时效的预测,定位到每一票的转运环节,数据量很大,对时效的要求也很高。
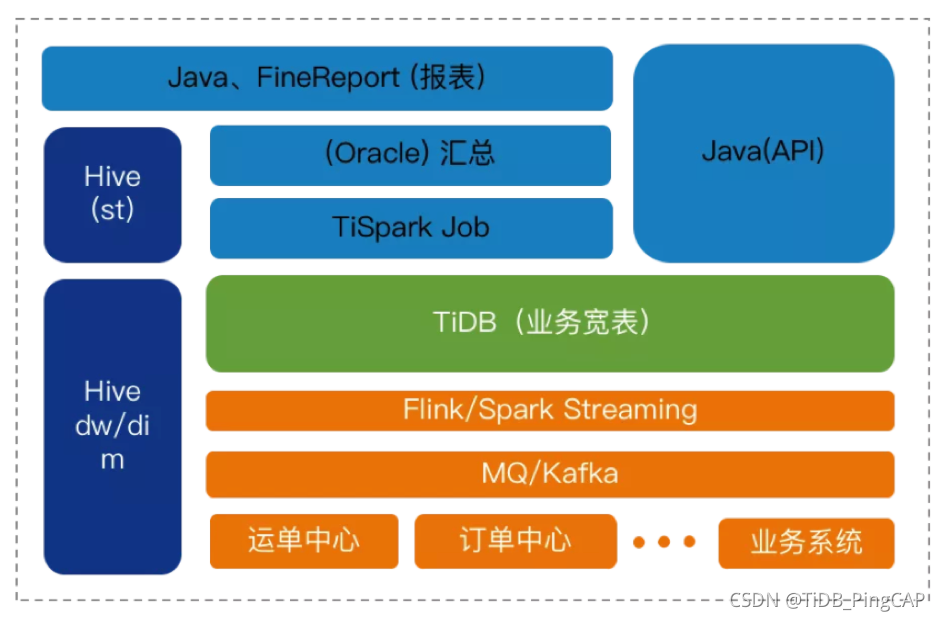
中通的大宽表建设
目前,宽表已经建设有 150 多个字段。数据来源于 10 多个 Topic 。主要的项目接入是通过 Flink 和 Spark ,打通了各个业务产生的数据,汇总到 TiDB 形成业务宽表。额外一部分,依赖于 TiSpark,从业务宽表输出分析结果,同步 3 亿条数据到 Hive。此外,还提供了十分钟级别的实时数据建设和离线 T+1 的整合。
中通目前的集群规模在使用过程中,中通也遇到了一些问题,总结起来就是量变引起质变。第一,热点问题。索引热点在目前情况下表现较为突出,因为中通的业务量规模十分大,操作存在高峰,在大时候该热点问题表现特别明显。第二,内存碎片化问题。在之前的低版本里,在稳定运行了一段时间后,因为有业务特性和大量的更新和删除,导致内存碎片化比较严重,这个在反馈给了 TiDB 后,已经修复了这个问题。第三,着重介绍一个参数——TiFlash 读取 index 的参数。通过测试,当读取的数据量/总数据量大于 1/10 的时候,建议该参数关闭。为什么这么说?因为 Test 数可能会变少,但是单位 Test 过渡的时间会变长。
运维监控
使用 TiDB 后会发现它的监控指标特别丰富,使用了流行的 Prometheus + Grafana ,多而全。之前,中通因为在支持线上业务的同时,还会有开发人员来查数据,遇到了 SQL 把 TiKV Server 拉挂的情况。针对这个问题以及监控的问题,中通进行了一些开发定制。第一,兼容线上特殊帐号的慢 SQL,会自动杀掉,并通知到相应的应用负责人。第二,中通开发了支持 Spark SQL 去查询 TiDB 的工具,并发和安全性在开发的过程中得到一些保障。此外,中通还会把一些额外的核心指标,接入到自研的监控体系。核心的告警会电话通知到相关的值班人员。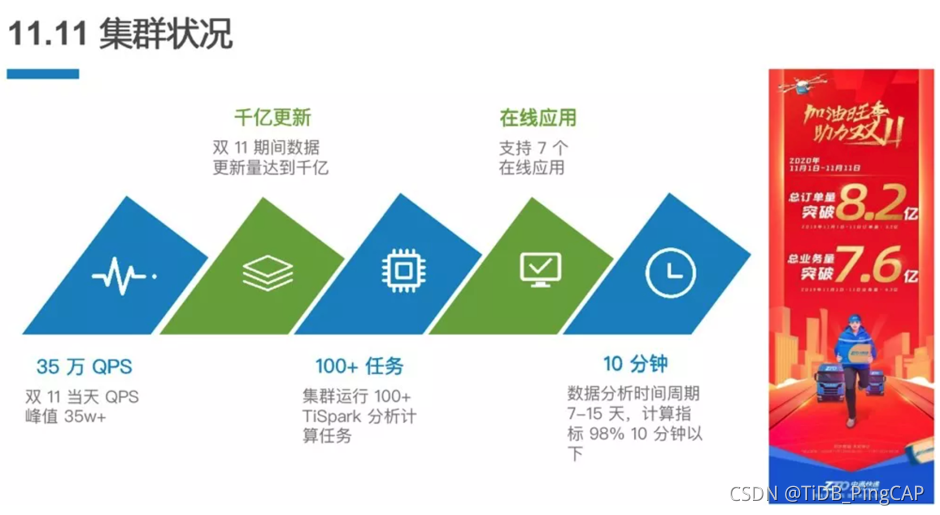
去年双十一期间,中通订单量突破 8.2 亿,整个业务规模突破 7.6 亿,双十一当天的 QPS 峰值达到 35 万 +。整个双十一期间,数据的更新体量达到了数千亿级别,整个集群上运行的 TiSpark 任务是 100 多个,支持的在线应用 7 个。整个分析的时效在 10 分钟以下达到了 98% ,整个分析的数据周期达到 7-15 天。
2.0 时代——HTAP 提升
2.0 时代的主要特点是 HTAP 的提升。中通应用 HTAP 主要来自于业务方需求的升级:
基于业务方的需求,中通在 2.0 时代进行了一次架构再升级。首先,**引入了 TiFlash 和 TiCDC **。这带来的收益其实是增强了时效,部分分析进入了分钟级级别,降低了 Spark 集群资源的使用情况。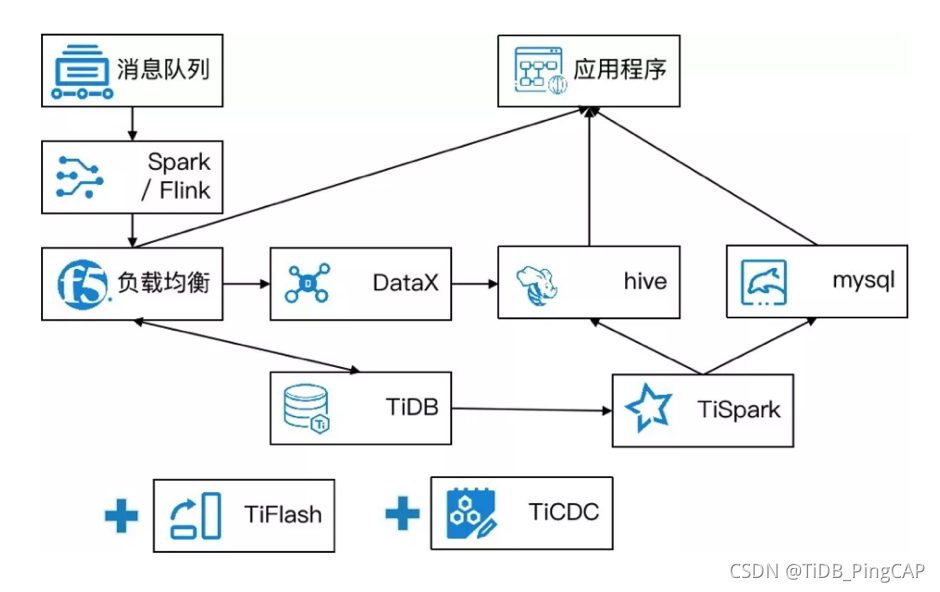
2.0 时代中通的数据系统架构
下图是 TiSpark 和 TiFlash 的对比,中通线上有两套集群,一个基于 3.0,一个基于 5.0。简单地对比一下 3.0 和 5.0 的情况:3.0 主要的分析是基于 TiSpark,5.0 是基于 TiFlash 。目前 3.0 集群有 137 个物理节点, 5.0 有 97 个节点。整个运行的周期中,3.0 是 5 - 15 分钟,基于 5.0 的 TiFlash 已经做到 1-2 分钟,整个 TiKV 的负载降低是比较明显的。另外, 在 3.0 上 Spark 的资源大概有 60 台,而在 5.0 上,线上的加上在测试的,大概有 10 台就足够了。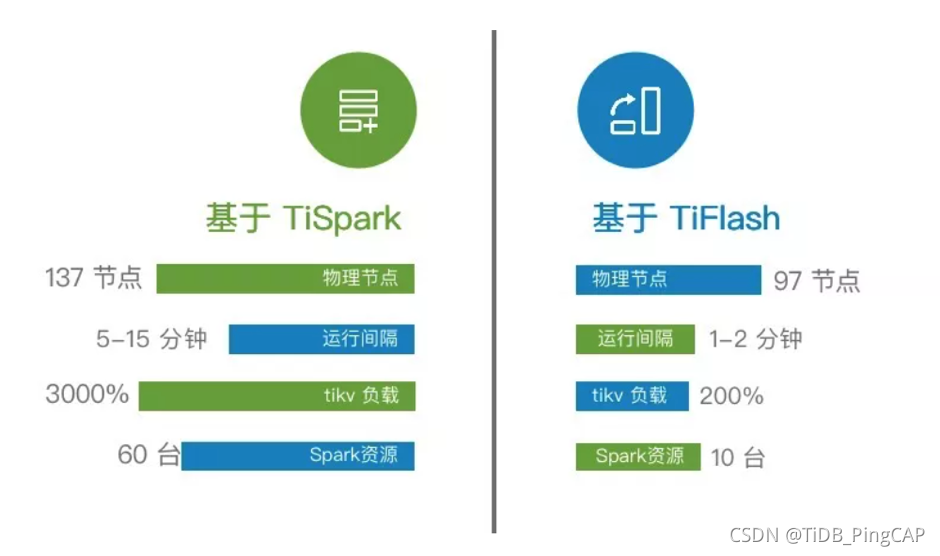
在整个测试周期中,生产的集群是 3.0 ,4.0 的测试周期其实是非常短的。在测试时,业务的场景有一些维表 Join 的情况,当时 4.0 对 MPP 没有支持,对一些函数的支持可能也不是那么完善,测试结果不是很理想。对 HTAP 的测试主要是在 5.0 阶段,5.0 已经支持 MPP ,对函数的支持也越来越丰富。目前中通生产上应用的版本是 TiDB 5.1 。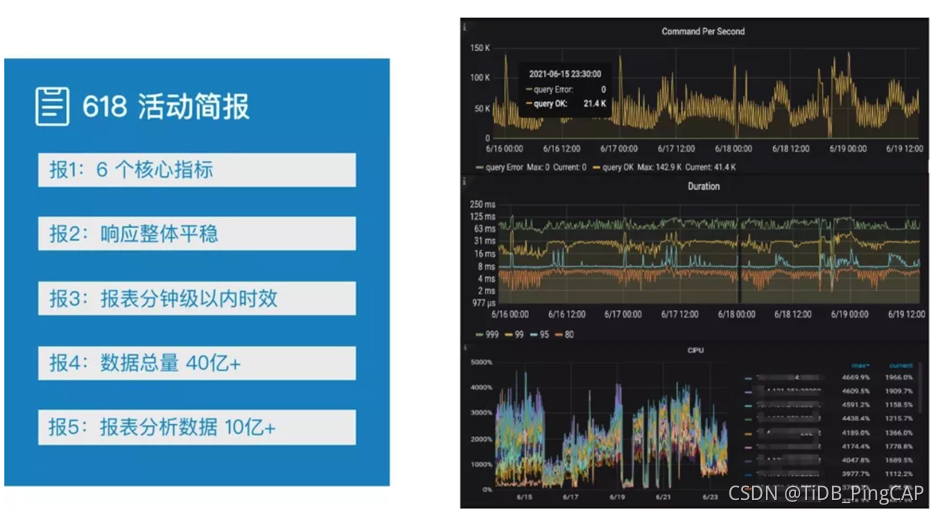
上图右侧是整个 5.0 集群在 618 期间的负载情况。在刚刚结束的 618 中, 5.0 上线的一些任务已经在支持 618 移动端的大促看板。中通有 6 个核心的指标是基于 TiFlash 计算的。集群响应整体平稳,报表达到了分钟级以内的时效。整体的数据体量在 40 亿 - 50 亿 +,报表分析数据达到 10 亿 +。
3.0 时代——展望未来

- 第一是监控。提到监控,由于中通的集群比较大,所以面临的问题和遇到的问题可能会多一点。大集群的实例多,指标加载慢,排查问题的效率得不到保障。监控虽然很全,但是出了问题的时候无法快速定位到问题;
- 第二是解决执行计划偶发不准的问题。这种偶发不准有时候会影响到一些线上的负载相互影响,拉高集群的指标,导致业务相互影响。
- 第三是实现自动清理。目前中通数据的清理是通过自己写成 SQL 清理的,但是过期数据清理比较麻烦。希望之后可以支持旧数据自动 TTL。
- 第四,随着 5.0 列式存储的引入,中通计划把 TiSpark 的任务逐渐全部切到 TiFlash 上面,期望达成提高时效和降低硬件成本的目标。
大促对于企业而言,除了支持业务创新,也是一次对自身技术架构的大练兵和全链路演练。通过大促的极致考验,企业的 IT 架构、组织流程、人才技能都获得了大幅提升。而在大促中的经验和思考,也会加速企业日常的业务创新节奏,提升技术驱动的创新效率,打造增长新引擎。
-
从 LB Ingress 到 ZTM:集群服务暴露新思路01-04
-
从入门到精通:AWS认证攻略指南01-03
-
DevOps和平台工程,哪个更适合你?01-03
-
Spark聚合优化:我们如何通过解决GroupBy性能瓶颈和避免使用spark EXPAND命令,将运行时间从4小时缩减至40分钟。01-03
-
彼得·德西斯在AWS reinvent 2024大会上的精彩演讲要点01-03
-
开源商业化 Sealos 如何做到月入 160万01-03
-
数据仓库、数据湖与湖仓架构:一站式数据处理进化论01-03
-
Fluss 与数据湖的深度解析(二)01-02
-
阿里云部署方案项目实战:新手入门教程01-02
-
阿里云RDS项目实战:新手入门教程01-02
-
阿里云部署方案资料详解:新手入门指南01-02
-
阿里云RDS资料入门教程:新手必读指南01-02
-
阿里云服务器端口怎么开放?云服务器端口开通图文教程(2025最新)12-31
-
阿里云部署方案教程:新手快速入门指南12-30
-
阿里云RDS教程:新手入门指南12-30
