Java教程
BAT面试必问细节:关于Netty中的ByteBuf详解

在Netty中,还有另外一个比较常见的对象ByteBuf,它其实等同于Java Nio中的ByteBuffer,但是ByteBuf对Nio中的ByteBuffer的功能做了很作增强,下面我们来简单了解一下ByteBuf。
下面这段代码演示了ByteBuf的创建以及内容的打印,这里显示出了和普通ByteBuffer最大的区别之一,就是ByteBuf可以自动扩容,默认长度是256,如果内容长度超过阈值时,会自动触发扩容
public class ByteBufExample {
public static void main(String[] args) {
ByteBuf buf= ByteBufAllocator.DEFAULT.buffer();//可自动扩容
log(buf);
StringBuilder sb=new StringBuilder();
for (int i = 0; i < 32; i++) { //演示的时候,可以把循环的值扩大,就能看到扩容效果
sb.append(" - "+i);
}
buf.writeBytes(sb.toString().getBytes());
log(buf);
}
private static void log(ByteBuf buf){
StringBuilder builder=new StringBuilder()
.append(" read index:").append(buf.readerIndex()) //获取读索引
.append(" write index:").append(buf.writerIndex()) //获取写索引
.append(" capacity:").append(buf.capacity()) //获取容量
.append(StringUtil.NEWLINE);
//把ByteBuf中的内容,dump到StringBuilder中
ByteBufUtil.appendPrettyHexDump(builder,buf);
System.out.println(builder.toString());
}
}
ByteBuf创建的方法有两种
-
第一种,创建基于堆内存的ByteBuf
ByteBuf buffer=ByteBufAllocator.DEFAULT.heapBuffer(10);
-
第二种,创建基于直接内存(堆外内存)的ByteBuf(默认情况下用的是这种)
Java中的内存分为两个部分,一部分是不需要jvm管理的直接内存,也被称为堆外内存。堆外内存就是把内存对象分配在JVM堆意外的内存区域,这部分内存不是虚拟机管理,而是由操作系统来管理,这样可以减少垃圾回收对应用程序的影响
ByteBufAllocator.DEFAULT.directBuffer(10);
直接内存的好处是读写性能会高一些,如果数据存放在堆中,此时需要把Java堆空间的数据发送到远程服务器,首先需要把堆内部的数据拷贝到直接内存(堆外内存),然后再发送。如果是把数据直接存储到堆外内存中,发送的时候就少了一个复制步骤。
但是它也有缺点,由于缺少了JVM的内存管理,所以需要我们自己来维护堆外内存,防止内存溢出。
另外,需要注意的是,ByteBuf默认采用了池化技术来创建。关于池化技术在前面的课程中已经重复讲过,它的核心思想是实现对象的复用,从而减少对象频繁创建销毁带来的性能开销。
池化功能是否开启,可以通过下面的环境变量来控制,其中unpooled表示不开启。
-Dio.netty.allocator.type={unpooled|pooled}
public class NettyByteBufExample {
public static void main(String[] args) {
ByteBuf buf= ByteBufAllocator.DEFAULT.buffer();
System.out.println(buf);
}
}
ByteBuf的存储结构
ByteBuf的存储结构如图3-1所示,从这个图中可以看到ByteBuf其实是一个字节容器,该容器中包含三个部分
- 已经丢弃的字节,这部分数据是无效的
- 可读字节,这部分数据是ByteBuf的主体数据,从ByteBuf里面读取的数据都来自这部分; 可写字节,所有写到ByteBuf的数据都会存储到这一段
- 可扩容字节,表示ByteBuf最多还能扩容多少容量。
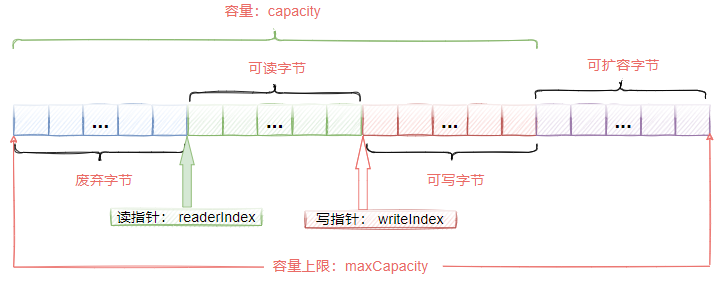
在ByteBuf中,有两个指针
- readerIndex: 读指针,每读取一个字节,readerIndex自增加1。ByteBuf里面总共有witeIndex-readerIndex个字节可读,当readerIndex和writeIndex相等的时候,ByteBuf不可读
- writeIndex: 写指针,每写入一个字节,writeIndex自增加1,直到增加到capacity后,可以触发扩容后继续写入。
- ByteBuf中还有一个maxCapacity最大容量,默认的值是
Integer.MAX_VALUE,当ByteBuf写入数据时,如果容量不足时,会触发扩容,直到capacity扩容到maxCapacity。
ByteBuf中常用的方法
对于ByteBuf来说,常见的方法就是写入和读取
Write相关方法
对于write方法来说,ByteBuf提供了针对各种不同数据类型的写入,比如
- writeChar,写入char类型
- writeInt,写入int类型
- writeFloat,写入float类型
- writeBytes, 写入nio的ByteBuffer
- writeCharSequence, 写入字符串
public class ByteBufExample {
public static void main(String[] args) {
ByteBuf buf= ByteBufAllocator.DEFAULT.heapBuffer();//可自动扩容
buf.writeBytes(new byte[]{1,2,3,4}); //写入四个字节
log(buf);
buf.writeInt(5); //写入一个int类型,也是4个字节
log(buf);
}
private static void log(ByteBuf buf){
System.out.println(buf);
StringBuilder builder=new StringBuilder()
.append(" read index:").append(buf.readerIndex())
.append(" write index:").append(buf.writerIndex())
.append(" capacity:").append(buf.capacity())
.append(StringUtil.NEWLINE);
//把ByteBuf中的内容,dump到StringBuilder中
ByteBufUtil.appendPrettyHexDump(builder,buf);
System.out.println(builder.toString());
}
}
扩容
当向ByteBuf写入数据时,发现容量不足时,会触发扩容,而具体的扩容规则是
假设ByteBuf初始容量是10。
- 如果写入后数据大小未超过512个字节,则选择下一个16的整数倍进行库容。 比如写入数据后大小为12,则扩容后的capacity是16。
- 如果写入后数据大小超过512个字节,则选择下一个2n。 比如写入后大小是512字节,则扩容后的capacity是210=1024 。(因为29=512,长度已经不够了)
- 扩容不能超过max capacity,否则会报错。
Reader相关方法
reader方法也同样针对不同数据类型提供了不同的操作方法,
- readByte ,读取单个字节
- readInt , 读取一个int类型
- readFloat ,读取一个float类型
public class ByteBufExample {
public static void main(String[] args) {
ByteBuf buf= ByteBufAllocator.DEFAULT.heapBuffer();//可自动扩容
buf.writeBytes(new byte[]{1,2,3,4});
log(buf);
System.out.println(buf.readByte());
log(buf);
}
private static void log(ByteBuf buf){
StringBuilder builder=new StringBuilder()
.append(" read index:").append(buf.readerIndex())
.append(" write index:").append(buf.writerIndex())
.append(" capacity:").append(buf.capacity())
.append(StringUtil.NEWLINE);
//把ByteBuf中的内容,dump到StringBuilder中
ByteBufUtil.appendPrettyHexDump(builder,buf);
System.out.println(builder.toString());
}
}
从下面结果中可以看到,读完一个字节后,这个字节就变成了废弃部分,再次读取的时候只能读取 未读取的部分数据。
read index:0 write index:7 capacity:256
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 05 06 07 |....... |
+--------+-------------------------------------------------+----------------+
1
read index:1 write index:7 capacity:256
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 02 03 04 05 06 07 |...... |
+--------+-------------------------------------------------+----------------+
Process finished with exit code 0
另外,如果想重复读取哪些已经读完的数据,这里提供了两个方法来实现标记和重置
public static void main(String[] args) {
ByteBuf buf= ByteBufAllocator.DEFAULT.heapBuffer();//可自动扩容
buf.writeBytes(new byte[]{1,2,3,4,5,6,7});
log(buf);
buf.markReaderIndex(); //标记读取的索引位置
System.out.println(buf.readInt());
log(buf);
buf.resetReaderIndex();//重置到标记位
System.out.println(buf.readInt());
log(buf);
}
另外,如果想不改变读指针位置来获得数据,在ByteBuf中提供了get开头的方法,这个方法基于索引位置读取,并且允许重复读取的功能。
ByteBuf的零拷贝机制
需要说明一下,ByteBuf的零拷贝机制和我们之前提到的操作系统层面的零拷贝不同,操作系统层面的零拷贝,是我们要把一个文件发送到远程服务器时,需要从内核空间拷贝到用户空间,再从用户空间拷贝到内核空间的网卡缓冲区发送,导致拷贝次数增加。
而ByteBuf中的零拷贝思想也是相同,都是减少数据复制提升性能。如图3-2所示,假设有一个原始ByteBuf,我们想对这个ByteBuf其中的两个部分的数据进行操作。按照正常的思路,我们会创建两个新的ByteBuf,然后把原始ByteBuf中的部分数据拷贝到两个新的ByteBuf中,但是这种会涉及到数据拷贝,在并发量较大的情况下,会影响到性能。
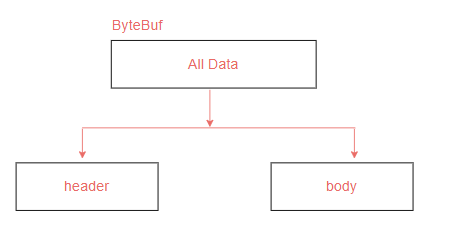
ByteBuf中提供了一个slice方法,这个方法可以在不做数据拷贝的情况下对原始ByteBuf进行拆分,使用方法如下
public static void main(String[] args) {
ByteBuf buf= ByteBufAllocator.DEFAULT.buffer();//可自动扩容
buf.writeBytes(new byte[]{1,2,3,4,5,6,7,8,9,10});
log(buf);
ByteBuf bb1=buf.slice(0,5);
ByteBuf bb2=buf.slice(5,5);
log(bb1);
log(bb2);
System.out.println("修改原始数据");
buf.setByte(2, 5); //修改原始buf数据
log(bb1);//再打印bb1的结果,发现数据发生了变化
}
在上面的代码中,通过slice对原始buf进行切片,每个分片是5个字节。
为了证明slice是没有数据拷贝,我们通过修改原始buf的索引2所在的值,然后再打印第一个分片bb1,可以发现bb1的结果发生了变化。说明两个分片和原始buf指向的数据是同一个。
Unpooled
在前面的案例中我们经常用到Unpooled工具类,它是同了非池化的ByteBuf的创建、组合、复制等操作。
假设有一个协议数据,它有头部和消息体组成,这两个部分分别放在两个ByteBuf中
ByteBuf header=... ByteBuf body= ...
我们希望把header和body合并成一个ByteBuf,通常的做法是
ByteBuf allBuf=Unpooled.buffer(header.readableBytes()+body.readableBytes()); allBuf.writeBytes(header); allBuf.writeBytes(body);
在这个过程中,我们把header和body拷贝到了新的allBuf中,这个过程在无形中增加了两次数据拷贝操作。那有没有更高效的方法减少拷贝次数来达到相同目的呢?
在Netty中,提供了一个CompositeByteBuf组件,它提供了这个功能。
public class ByteBufExample {
public static void main(String[] args) {
ByteBuf header= ByteBufAllocator.DEFAULT.buffer();//可自动扩容
header.writeCharSequence("header", CharsetUtil.UTF_8);
ByteBuf body=ByteBufAllocator.DEFAULT.buffer();
body.writeCharSequence("body", CharsetUtil.UTF_8);
CompositeByteBuf compositeByteBuf=Unpooled.compositeBuffer();
//其中第一个参数是 true, 表示当添加新的 ByteBuf 时, 自动递增 CompositeByteBuf 的 writeIndex.
//默认是false,也就是writeIndex=0,这样的话我们不可能从compositeByteBuf中读取到数据。
compositeByteBuf.addComponents(true,header,body);
log(compositeByteBuf);
}
private static void log(ByteBuf buf){
StringBuilder builder=new StringBuilder()
.append(" read index:").append(buf.readerIndex())
.append(" write index:").append(buf.writerIndex())
.append(" capacity:").append(buf.capacity())
.append(StringUtil.NEWLINE);
//把ByteBuf中的内容,dump到StringBuilder中
ByteBufUtil.appendPrettyHexDump(builder,buf);
System.out.println(builder.toString());
}
}
之所以CompositeByteBuf能够实现零拷贝,是因为在组合header和body时,并没有对这两个数据进行复制,而是通过CompositeByteBuf构建了一个逻辑整体,里面仍然是两个真实对象,也就是有一个指针指向了同一个对象,所以这里类似于浅拷贝的实现。
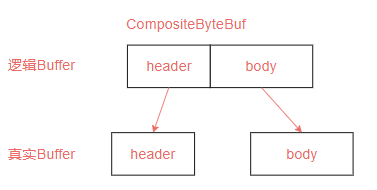
wrappedBuffer
在Unpooled工具类中,提供了一个wrappedBuffer方法,来实现CompositeByteBuf零拷贝功能。使用方法如下。
public static void main(String[] args) {
ByteBuf header= ByteBufAllocator.DEFAULT.buffer();//可自动扩容
header.writeCharSequence("header", CharsetUtil.UTF_8);
ByteBuf body=ByteBufAllocator.DEFAULT.buffer();
body.writeCharSequence("body", CharsetUtil.UTF_8);
ByteBuf allBb=Unpooled.wrappedBuffer(header,body);
log(allBb);
//对于零拷贝机制,修改原始ByteBuf中的值,会影响到allBb
header.setCharSequence(0,"Newer0",CharsetUtil.UTF_8);
log(allBb);
}
copiedBuffer
copiedBuffer,和wrappedBuffer最大的区别是,该方法会实现数据复制,下面代码演示了copiedBuffer和wrappedbuffer的区别,可以看到在case标注的位置中,修改了原始ByteBuf的值,并没有影响到allBb。
public static void main(String[] args) {
ByteBuf header= ByteBufAllocator.DEFAULT.buffer();//可自动扩容
header.writeCharSequence("header", CharsetUtil.UTF_8);
ByteBuf body=ByteBufAllocator.DEFAULT.buffer();
body.writeCharSequence("body", CharsetUtil.UTF_8);
ByteBuf allBb=Unpooled.copiedBuffer(header,body);
log(allBb);
header.setCharSequence(0,"Newer0",CharsetUtil.UTF_8); //case
log(allBb);
}
内存释放
针对不同的ByteBuf创建,内存释放的方法不同。
- UnpooledHeapByteBuf,使用JVM内存,只需要等待GC回收即可
- UnpooledDirectByteBuf,使用对外内存,需要特殊方法来回收内存
- PooledByteBuf和它的之类使用了池化机制,需要更复杂的规则来回收内存
如果ByteBuf是使用堆外内存来创建,那么尽量手动释放内存,那怎么释放呢?
Netty采用了引用计数方法来控制内存回收,每个ByteBuf都实现了ReferenceCounted接口。
- 每个ByteBuf对象的初始计数为1
- 调用release方法时,计数器减一,如果计数器为0,ByteBuf被回收
- 调用retain方法时,计数器加一,表示调用者没用完之前,其他handler即时调用了release也不会造成回收。
- 当计数器为0时,底层内存会被回收,这时即使ByteBuf对象还存在,但是它的各个方法都无法正常使用
版权声明:本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自
Mic带你学架构!
如果本篇文章对您有帮助,还请帮忙点个关注和赞,您的坚持是我不断创作的动力。
-
Springboot应用的多环境打包入门11-23
-
Springboot应用的生产发布入门教程11-23
-
Python编程入门指南11-23
-
Java创业入门:从零开始的编程之旅11-23
-
Java创业入门:新手必读的Java编程与创业指南11-23
-
Java对接阿里云智能语音服务入门详解11-23
-
Java对接阿里云智能语音服务入门教程11-23
-
JAVA对接阿里云智能语音服务入门教程11-23
-
Java副业入门:初学者的简单教程11-23
-
JAVA副业入门:初学者的实战指南11-23
-
JAVA项目部署入门:新手必读指南11-23
-
Java项目部署入门:新手必看指南11-23
-
Java项目部署入门:新手必读指南11-23
-
Java项目开发入门:新手必读指南11-23
-
JAVA项目开发入门:从零开始的实用教程11-23
