C/C++教程
DTCC 2021 黄东旭:从 DB 到 DBaaS,数据库技术的当前和未来

10 月 18 日~ 20 日,第 12 届中国数据库技术大会(DTCC2021)在北京国际会议中心隆重召开。PingCAP 联合创始人兼 CTO 黄东旭受邀在主会场进行了以 “TiDB Cloud:from Product to Platform” 为主题的演讲,分享了云原生时代数据库产品平台化的重要性,以及 TiDB 从 DB 到 DBaaS 的经验和体会。以下为分享实录。
在最近数据库行业的发展中,比起 “代码写得好不好” 这样的工程技术问题,科学问题更加突出:有一件事情非常深刻地改变了整个数据库的行业,那就是数据库底层发生了变化。以往大家去思考数据库软件和系统软件,都会先做一个假设:软件是跑在计算机等具体的硬件上的,即使是分布式数据库,每个节点都还是一个普通的计算机。现在这个假设改变了:我们的下一代到能够学编程或者写代码的年纪,不会再像我们现在这样能够看到 CPU、硬盘、网络,他们看到的可能就是 AWS 提供的一个 S3 的 API 。其实这种改变并不仅是软件载体的改变,更重要的是架构、编程的底层逻辑发生了变化。云对基础设施和软件的影响和改变是深远的。具体到 PingCAP 身上,最大的感受就是比起做数据库内核, 现在在云上做 TiDB Cloud 服务的投入可能多得多。这也是我今天要分享的主题,From Product to Platform —— 从 DB 到 DBaaS,数据库技术的当前和未来。
PingCAP 的创业初心
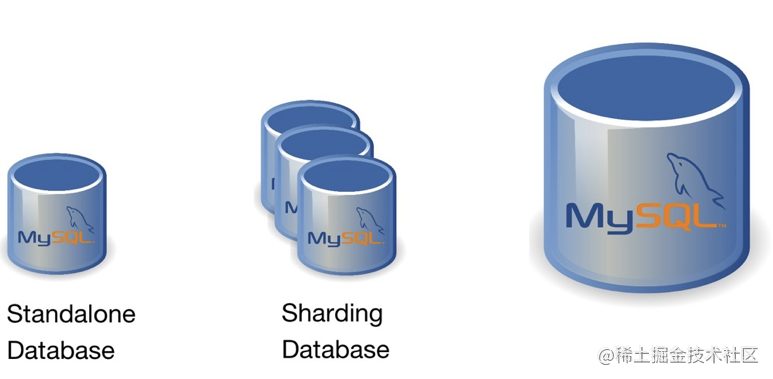
上图是我理解的数据库发展历程。追溯到十几年前,我们开始使用单机 MySQL,这个时期我们对数据库的需求只有朴素的增删改查,2010 年前后直到今天,爆发的数据量让单机数据库难以为继,大家只能通过分库分表或者中间件来实现分布式部署。

然而分库分表对业务的入侵性太大,那能不能有这样一个数据库,用起来和单机 MySQL 一样简单,但是扩容时不需要考虑分片,而是通过系统本身的机制来实现弹性、舒适、业务无入侵的拓展?这就是 PingCAP 创业的初心。
PingCAP 创业六年多以来,为了达成这个小目标,也总结了几点心得:
易用优先:协议大于实现
MySQL 协议比 MySQL 具体软件更重要。如果一款数据库能够兼容 MySQL 协议,能让用户在数据库的选型过程中无需考虑对应用和业务的影响,就能拥有最大的用户群。我们无需发明一种新的使用方式,就像电动车还是会通过方向盘和油门来操控,虽然引擎下的世界和汽油车完全不同。
用户体验优先
数据库的性能指标比如 TPS、QPS 等固然重要,但是用户的体验才是一款数据库成功的关键。因此,TiDB 在做所有技术决策的时候都是通过用户体验(Usability matters)来判断。从我过去的经验来看,许多互联网公司需要维护的数据库种类非常多,每启用一种新的数据库就会多一个数据孤岛。因此,在满足用户数据处理需求的同时,简化的技术栈可能才是真正的用户痛点。无论是 OLTP、OLAP 还是 HTAP,TiDB 希望做的事就是让大家的生活变得好一点。
开源优先

PingCAP 始终坚持开源战略,也因此受益颇多。从生态角度,开源的研发模式能够迅速积累用户。TiDB 1.0 版本 2017 年 11 月发布,从诞生到现在,我们知道名字的用户有 2000 多家,贡献者有 1500 多个,CNCF 开源组织的 Contribution Rank 中,PingCAP 排名全球第六。
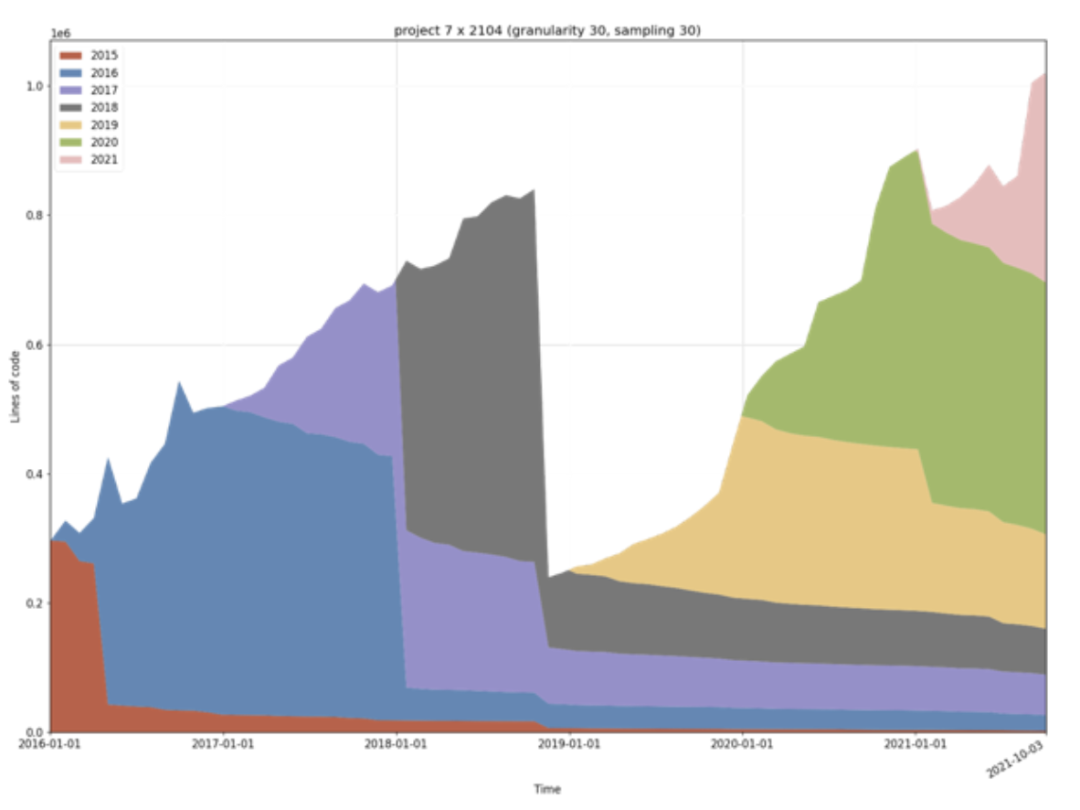
从技术角度,开源加速了产品的迭代速度。这张图的纵轴是代码量,横轴是时间,不同色块是代表某一年写的代码量。从图中我们能够看出,基本上每年 TiDB 的代码都在被重写,几乎没有一年是跟去年的代码一样。这个迭代的速度就是通过开源社区来实现的,是任何一个团队、任何一个公司、任何一个企业从头开始做一个数据库都无法达到的进化速度。
Why DBaaS
TiDB 的产品能力不是今天分享的重点,我今天想谈的是把一个产品变成云服务到底有多重要。首先抛出一个最终结论,现在这个时代对 CIO 尤其是海外的客户来说,数据库产品对云的适配成为了一个必选项。
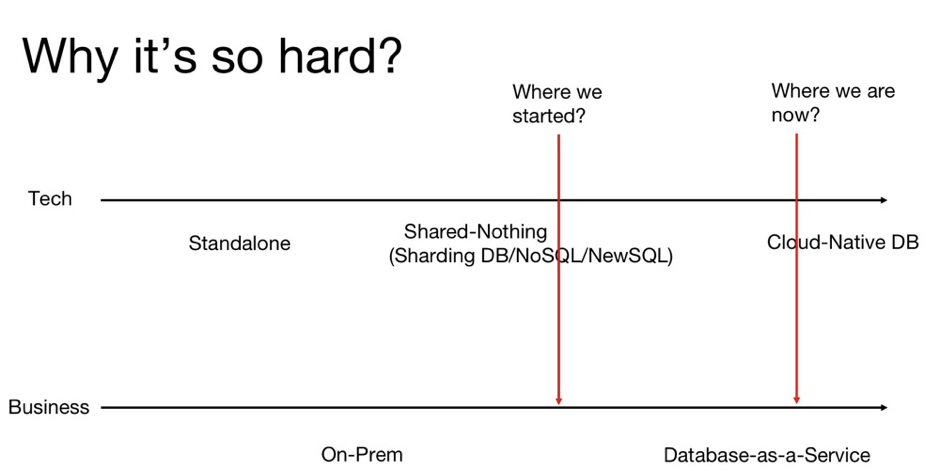
现在我们正好站在时代的交界点上。从技术上来讲,数据库的发展就是从 Standalone(单机)到 Cloud-Native(云原生)的进程。现在我们处在第二条红线的位置,就是从 Shared-Nothing 到 Cloud-Native 的边界。从商业角度看,整个数据库和基础软件行业的商业模式也正在发生特别大的变化:过去我们希望通过售卖 license 进行私有化部署,到现在希望能够实现规模化的扩张,这也正是 On-Prem 到 DBaaS 变革。作为一家成功将数据库商业化的公司,MongoDB 走出了一条很有代表性的道路。MongoDB 每年的市值都在翻番,现在已经到达了 300 多亿美金。从 MongoDB 的财报可以看出,DBaaS 产品 MongoDB Atlas 基本上每年都保持着超过 100% 的年复合增长率,这就是云服务的价值所在。
TiDB 在云上的平台化之路
最近两年我也重新定义了一下我们的愿景和使命:全世界的开发者享受到我们的服务,Anywhere with Any Scale。想要实现这个目标,从 DB 到 DBaaS 是个必选项。只有云上的服务才能突破地域的限制,并提供无限的算力。从 DB 到 DBaaS,远不止将底层资源换成云这么简单,需要考虑的还有很多。技术上,要实现降本增效、运维自动化、多租户管理,合规上要考虑数据安全,商业上,计价模式、商业化策略等都是需要纳入考虑的范围。接下来我将从技术角度谈谈 TiDB 在 DBaaS 进程中付出的努力。
成本节约:分离的架构设计
云原生技术最终要解决的就是成本的问题。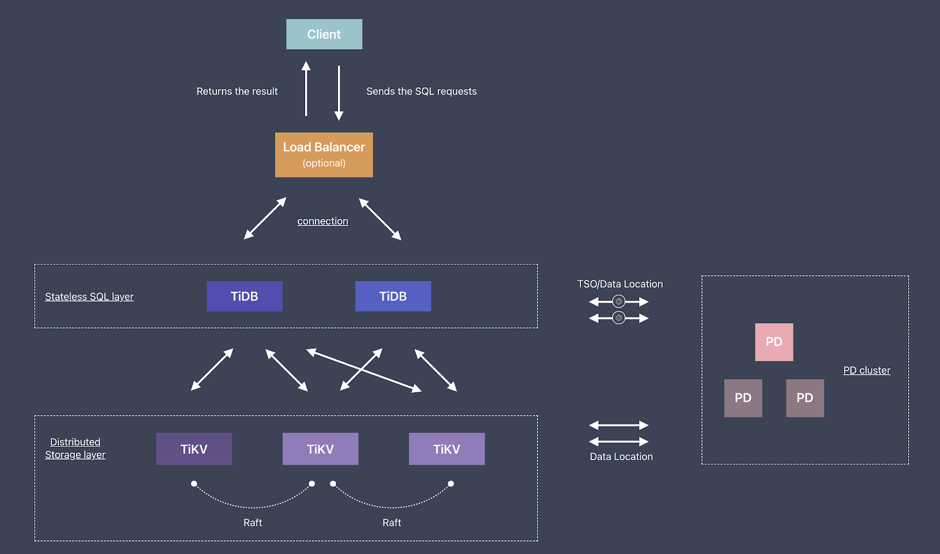 在过去,TiDB 有一个 TiDB + TiKV 的协处理引擎,计算和存储的边界是非常模糊的,很难处理不同负载率的场景。本地部署的情况下,如果需要增加存储容量,就需要增加存储节点,因为硬件的限制,除了磁盘,CPU 及网络带宽也会同步增加,这就造成了资源的浪费,这是所有 Shared-Nothing 的数据库都要面临的问题。
在过去,TiDB 有一个 TiDB + TiKV 的协处理引擎,计算和存储的边界是非常模糊的,很难处理不同负载率的场景。本地部署的情况下,如果需要增加存储容量,就需要增加存储节点,因为硬件的限制,除了磁盘,CPU 及网络带宽也会同步增加,这就造成了资源的浪费,这是所有 Shared-Nothing 的数据库都要面临的问题。
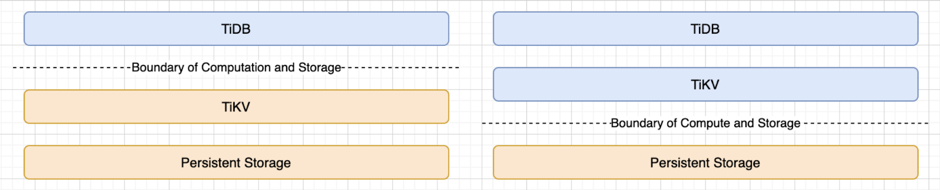
而到了云上,一切就截然不同。比如 AWS 的块存储设备的服务 EBS,特别是 GP3 系列,能够在不同的机器上运行,且达到同样的 IOPS 和 Cost,性能和对云原生的整合都非常好。为了利用 GP3 的特性,我们是否可以把计算和存储的边界往下移,从原来的 TiKV 到存储,到现在 TiDB、TiKV 的大部分都可以是计算单元,更加灵活。
云带来的成本节约不止于此。云上真正值钱的东西是 CPU,瓶颈会是计算,而不是容量。集群和实例可以基于资源共享池进行优化(Spot instances & Clusters based on shared resource pools)、按需选择存储服务的类型、对不同类型的 EC2 实例在特定场景组合交付、无服务器计算、弹性的计算资源都将成为可能。此外,根据我的判断,除了计算存储分离,网络、内存,甚至 CPU 缓存都会是分离的。因为对一个应用程序来说,尤其是分布式程序,硬件资源的要求是不一样的。不管是做什么业务,就像做菜一样,手上只有一颗菜肯定做不出什么花来,但原材料很多,就可以按照口味去做组合,云带来的就是这样的机会。
安全性
除了成本,云的安全性也是重要课题。TiDB 官方支持的公有云是 AWS 和 GCP。云上网络用户使用的都是自己的 VPC,中间也会有 VPC Peering 打通的环节,我们看不到用户的数据,但用户可以很高性能地访问自己的业务,安全性要怎么保证?
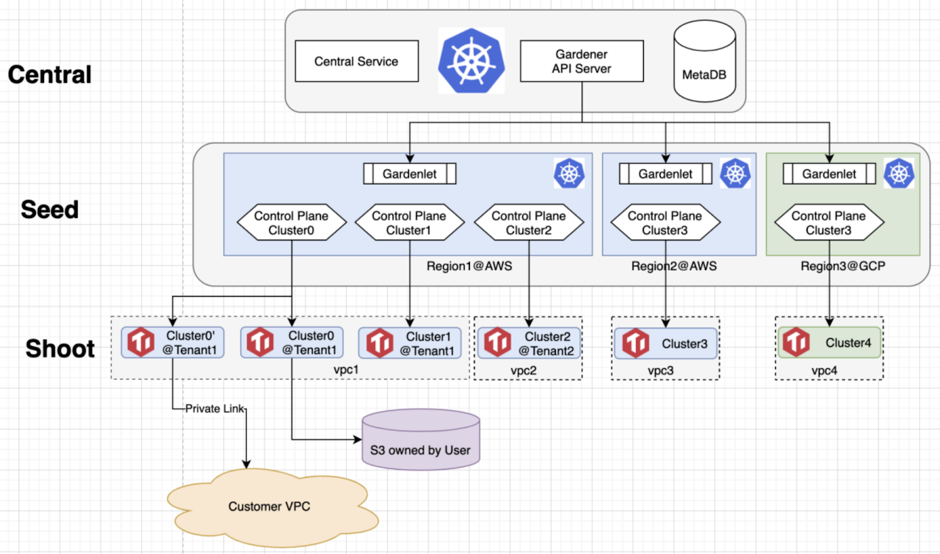
图中是 TiDB 的安全体系,云上的安全体系和我们云下的思考完全不同。举个特别简单的例子:云下只需要考虑 RBAC 数据库内部的权限,但在云上就非常复杂,需要考虑从网络到存储一整套的用户健全安全的体系。做好云上安全的关键点是千万不要自己重复发明,因为基本都有安全漏洞。所以我们现在就是要充分利用云本身提供的一套完整的安全机制,比如密钥管理和规则等。当然,最好的地方都是这些服务都能够明码标价,只要做出计费模型就好了。
运维自动化
关于 DBaaS 的构建还有一点很重要,其实也和成本有关,就是运维自动化。云是一个规模化的生意,而现在国内数据库生意最麻烦的部分之一就是交付。一个大客户恨不得派二十个人驻场,但这件事情可持续吗?。我们要实现的就是可以通过 10 个人的交付团队去支持有 1000 个客户的系统,这是规模化的前提。
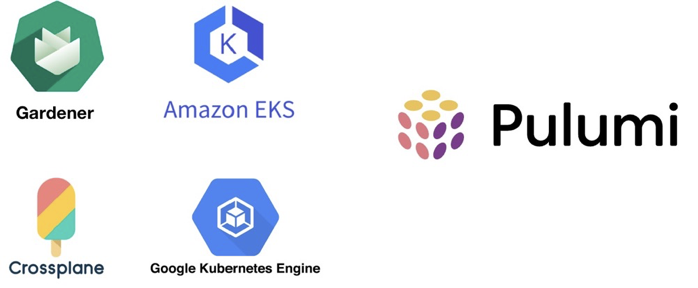
这些是 TiDB 自己的云服务技术选型,通过 Kubernetes 实现云上部署,通过 Gardener 进行联邦管理,管控多个 Kubernetes 集群,Pulumi 是一个基础架构即代码的自动化工具。
Kubernetes
要把 TiDB 变成云服务总共分为几步?第一步就是人肉运维全部变成代码。TiDB 要扩容了,不要人肉扩容,系统自己能不能扩容?TiDB 故障恢复,人参与不了,机器能不能参与?我们把所有 TiDB 的运维全部变成了 Kubernetes Operator,相当于我们实现了自动运维 TiDB。Kubernetes 能够屏蔽所有云厂商的接口复杂性,每个云厂商都会提供 Kubernetes 服务。
Pulumi
刚才说过这些东西的部署、运维、调度的逻辑,如果都是靠人写脚本,一是不稳定,二是不可维护。我们的理念就是只要能够变成代码的东西就固化下来,千万不要依赖人,包括去开一个服务器,或者去买一个虚拟机,我们都会把它变成 Pulumi 编程语言的脚本。
Gardener
TiDB 通过 Gardener 的 API 来管控多个不同 Region 里的 Kubernetes 集群,每个 Kubernetes 集群再去划分不同租户的 TiDB 集群,形成一个多云、多区域、多 AZ 的大的系统。这个架构有一个好处:用户可以在自己应用程序所在的云服务商和地理区域按需启用 TiDB,保持技术栈的统一。
商业 SLA
SLA 里面要考虑的东西也很多,这是 TiDB 要做的且正在做的东西。TiDB 的海外客户特别多,海外用户对数据库的需求与国内用户有很大不同,跨数据中心是一个刚需。由于现在各国的数据安全需求,数据的传输有了诸多限制,合规的、跨数据中心的能力对数据库来说十分重要。比如面对欧洲的 GDPR 管控,如果能把一部分数据就放在欧洲,不要出来,只有不在管控范围内的东西能出来,就会省去很多麻烦。相信接下来这个能力对于中国的厂商和客户,包括做出海以及在国内做合规都会变成刚需。这个功能在云上很容易实现,比如 AWS 本身就是多 AZ、多 Region 的架构,无需考虑底层,在另外一个数据中心开几台机器,用户只需要在界面上点一下鼠标数据就过去了,但对于无法在云端部署的数据库来说,如果要去处理全局的数据分布或者全局 Transaction 和 Local Transaction,需要考虑的东西就多得多。现在 TiDB 就是未雨绸缪,这项功能已经马上就要发布了。
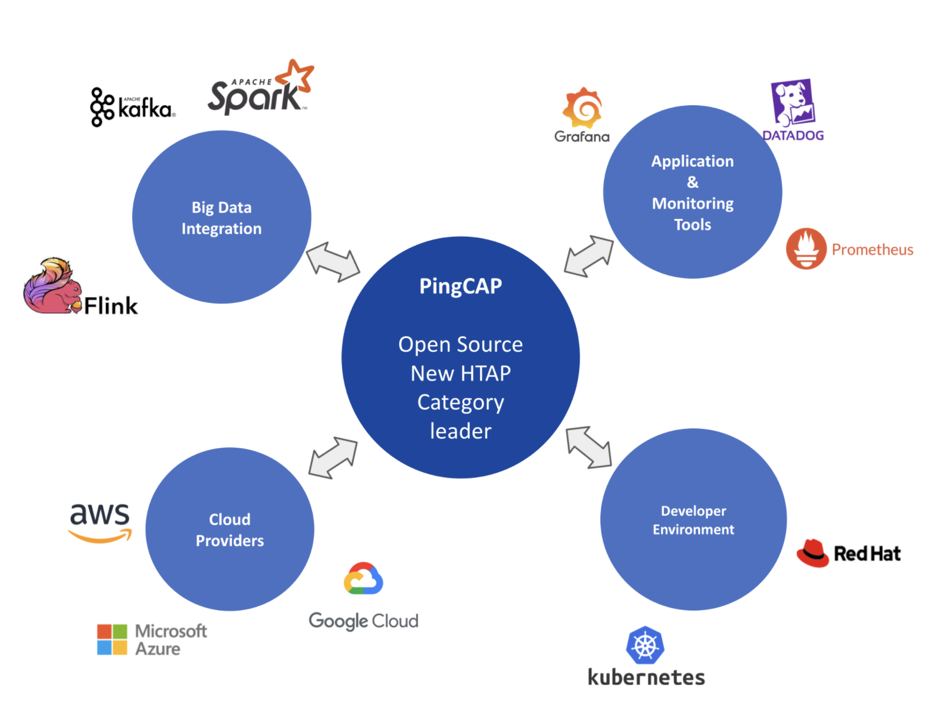
想要在云上提供服务,技术固然重要,合规是个前提。云上的生态整合有一个主线,就是跟着数据走,数据的上游、下游和管控是最重要的三个点。TiDB 的上游就是 MySQL、S3 里面的数据文件,下游只需要支持与 Kafka 或其他消息队列服务的同步即可。在数据的管控层面,在云上尤其是对海外用户来说,比起通过数据库厂商去做整体的管控,更希望和类似 DataDog、Confluent 这样的平台打通。最后打个广告,TiDB 在 Q4 会推出对开发者的为期 12 个月的免费体验版,能够快速部署,默认支持 HTAP 功能,通过容器实现计算隔离,同时具有专用的块存储,大家在云上可以随意使用。我们的网址是 tidbcloud.com,未来也会支持国内的云,期待大家的体验和反馈。希望 PingCAP 能够真正做到:让全世界的开发者享受到我们的服务,Anywhere with Any Scale。
-
【机器学习(二)】分类和回归任务-决策树(Decision Tree,DT)算法-Sentosa_DSML社区版11-25
-
增量更新怎么做?-icode9专业技术文章分享11-23
-
压缩包加密方案有哪些?-icode9专业技术文章分享11-23
-
用shell怎么写一个开机时自动同步远程仓库的代码?-icode9专业技术文章分享11-23
-
webman可以同步自己的仓库吗?-icode9专业技术文章分享11-23
-
在 Webman 中怎么判断是否有某命令进程正在运行?-icode9专业技术文章分享11-23
-
如何重置new Swiper?-icode9专业技术文章分享11-23
-
oss直传有什么好处?-icode9专业技术文章分享11-23
-
如何将oss直传封装成一个组件在其他页面调用时都可以使用?-icode9专业技术文章分享11-23
-
怎么使用laravel 11在代码里获取路由列表?-icode9专业技术文章分享11-23
-
怎么实现ansible playbook 备份代码中命名包含时间戳功能?-icode9专业技术文章分享11-22
-
ansible 的archive 参数是什么意思?-icode9专业技术文章分享11-22
-
ansible 中怎么只用archive 排除某个目录?-icode9专业技术文章分享11-22
-
exclude_path参数是什么作用?-icode9专业技术文章分享11-22
-
微信开放平台第三方平台什么时候调用数据预拉取和数据周期性更新接口?-icode9专业技术文章分享11-22
