C/C++教程
如果你还不知道Apache Zookeeper?你凭什么拿大厂Offer!!

很多同学或多或少都用到了Zookeeper,并知道它能实现两个功能
- 配置中心,实现表分片规则的统一配置管理
- 注册中心,实现sharding-proxy节点的服务地址注册
那么Zookeeper到底是什么?以及为什么能实现这样的功能?接下来我们就来了解一下Zookeeper。
Zookeeper的前世今生
Apache ZooKeeper是一个高可靠的分布式协调中间件。它是Google Chubby的一个开源实现,那么它主要是解决什么问题的呢?那就得先了解Google Chubby
Google Chubby是谷歌的一个用来解决分布式一致性问题的组件,同时,也是粗粒度的分布式锁服务。
分布式一致性问题
什么是分布式一致性问题呢?简单来说,就是在一个分布式系统中,有多个节点,每个节点都会提出一个请求,但是在所有节点中只能确定一个请求被通过。而这个通过是需要所有节点达成一致的结果,所以所谓的一致性就是在提出的所有请求中能够选出最终一个确定请求。并且这个请求选出来以后,所有的节点都要知道。
这个就是典型的拜占庭将军问题
拜占庭将军问题说的是:拜占庭帝国军队的将军们必须通过投票达成一致来决定是否对某一个国家发起进攻。但是这些将军在地里位置上是分开的,并且在将军中存在叛徒。叛徒可以通过任意行动来达到自己的目标:
-
欺骗某些将军采取进攻行动
-
促使一个不是所有将军都统一的决定,比如将军们本意是不希望进攻,但是叛徒可以促成进攻行动
-
迷惑将军使得他们无法做出决定
如果叛徒达到了任意一个目标,那么这次行动必然失败。只有完全达成一致那么这次进攻才可能胜利
拜占庭问题的本质是,由于网络通信存在不可靠的问题,也就是可能存在消息丢失,或者网络延迟。如何在这样的背景下对某一个请求达成一致。
为了解决这个问题,很多人提出了各种协议,比如大名鼎鼎的Paxos; 也就是说在不可信的网络环境中,按照paxos这个协议就能够针对某个提议达成一致。
所以:分布式一致性的本质,就是在分布式系统中,多个节点就某一个提议如何达成一致
这个和Google Chubby有什么关系呢
在Google有一个GFS(google file system),他们有一个需求就是要从多个gfs server中选出一个master server。这个就是典型的一致性问题,5个分布在不同节点的server,需要确定一个master server,而他们要达成的一致性目标是:确定某一个节点为master,并且所有节点要同意。
而GFS就是使用chubby来解决这个问题的。
实现原理是:所有的server通过Chubby提供的通信协议到Chubby server上创建同一个文件,当然,最终只有一个server能够获准创建这个文件,这个server就成为了master,它会在这个文件中写入自己 的地址,这样其它的server通过读取这个文件就能知道被选出的master的地址。
分布式锁服务
从另外一个层面来看,Chubby提供了一种粗粒度的分布式锁服务,chubby是通过创建文件的形式来提供锁的功能,server向chubby中创建文件其实就表示加锁操作,创建文件成功表示抢占到了锁。
由于Chubby没有开源,所以雅虎公司基于chubby的思想,开发了一个类似的分布式协调组件Zookeeper,后来捐赠给了Apache。
所以,大家一定要了解,zookeeper并不是作为注册中心而设计,他是作为分布式锁的一种设计,而注册中心只是他能够实现的一种功能而已。
Zookeeper的安装和部署
安装
zookeeper有两种运行模式:集群模式和单击模式。
下载zookeeper安装包:https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
下载完成,通过tar -zxvf解压
常用命令
- 启动ZK服务:
bin/zkServer.sh start
- 查看ZK服务状态:
bin/zkServer.sh status
- 停止ZK服务:
bin/zkServer.sh stop
- 重启ZK服务:
bin/zkServer.sh restart
- 连接服务器
zkCli.sh -timeout 0 -r -server ip:port
单机环境安装
一般情况下,在开发测试环境,没有这么多资源的情况下,而且也不需要特别好的稳定性的前提下,我们可以使用单机部署;
初次使用zookeeper,需要将conf目录下的zoo_sample.cfg文件copy一份重命名为zoo.cfg
修改dataDir目录,dataDir表示日志文件存放的路径(关于zoo.cfg的其他配置信息后面会讲)
集群环境安装(后续再讲)
在zookeeper集群中,各个节点总共有三种角色,分别是:leader,follower,observer
集群模式我们采用模拟3台机器来搭建zookeeper集群。分别复制安装包到三台机器上并解压,同时copy一份zoo.cfg。
-
修改配置文件
- 修改端口
- server.1=IP1:2888:3888 【2888:访问zookeeper的端口;3888:重新选举leader的端口】
- server.2=IP2.2888:3888
- server.3=IP3.2888:2888
-
server.A=B:C:D:其 中
- A 是一个数字,表示这个是第几号服务器;
- B 是这个服务器的 ip地址;
- C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;
- D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
- 在集群模式下,集群中每台机器都需要感知到整个集群是由哪几台机器组成的,在配置文件中,按照格式server.id=host:port:port,每一行代表一个机器配置。id: 指的是server ID,用来标识该机器在集群中的机器序号
-
新建datadir目录,设置myid
在每台zookeeper机器上,我们都需要在数据目录(dataDir)下创建一个myid文件,该文件只有一行内容,对应每台机器的Server ID数字;比如server.1的myid文件内容就是1。【必须确保每个服务器的myid文件中的数字不同,并且和自己所在机器的zoo.cfg中server.id的id值一致,id的范围是1~255】
-
启动zookeeper
Zookeeper的数据模型
如果我们把zookeeper当成是一个内存数据库的话,那么crud就是对zookeeper内存数据库进行一个数据的增删改查操作,那zookeeper的数据结构是什么样的呢?如图9-4所示,zookeeper的视图结构和标准的文件系统非常类似,每一个节点称之为ZNode, 是zookeeper的最小单元。每个znode上都可以保存数据以及挂载子节点,构成一个层次化的树形结构
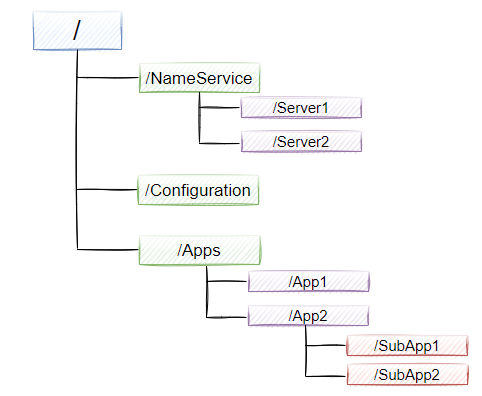
节点类型
Zookeeper中包含4种类型的节点,分别说明如下。
持久化节点
持久化节点可以细分为两种节点,分别是:
-
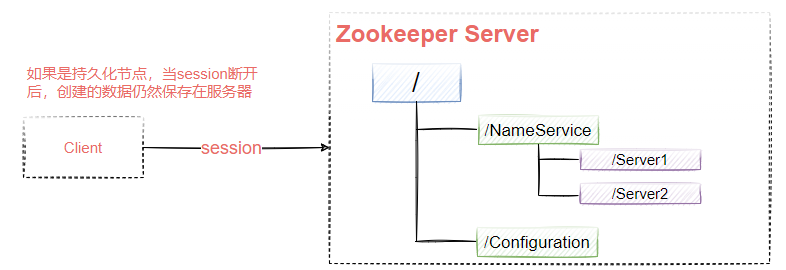
PERSISTENT:持久化,不会随客户端的断开而自动删除,默认类型,如图9-5所示

图9-5 -
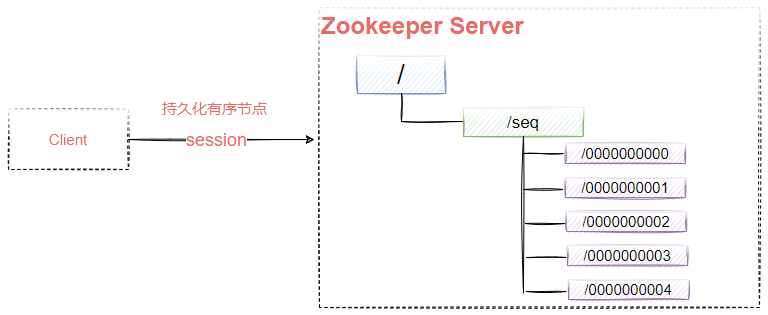
PERSISTENT_SEQUENTIAL:带序号的持久化,znode的名字将被附加一个单调递增的数字,如图9-6所示
临时节点
-
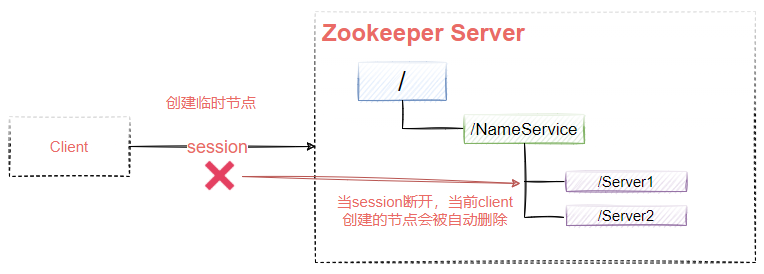
EPHEMERAL:临时节点,当客户端断开时自动删除,如图9-6所示,如果该Client创建了/Server1和/Server2这两个节点,当Client的session断开后,这两个节点会被Zookeeper自动删除。
图9-6 -
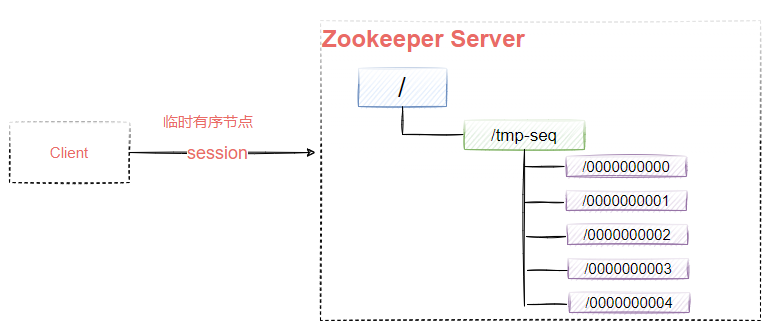
EPHEMERAL_SEQUENTIAL:带序号的临时节点,znode的名字将被附加一个单调递增的数字,如图9-7所示
注意,临时节点不能存在子节点
Container节点
CONTAINER:container节点是一个特殊用途的节点,它是为Leader、Lock等操作而设计的节点类型,它的作用是: 当容器节点的最后一个子节点被删除后,容器节点将会被标注并且在一段时间后删除。
由于容器节点存在这个特性,所以当我们在容器节点下创建一个子节点时,需要捕获KeeperException.NoNodeException异常,如果捕获到这个异常,就需要重新创建容器节点。
TTL节点
如果某个节点设置为TTL节点类型,那么这个节点在指定TTL时间(单位为毫秒)段内没有修改并且没有子节点时,该节点会在一段时间后被删除。
- PERSISTENT_WITH_TTL:zookeeper的扩展类型,如果znode在给定的TTL内没有被修改,它将在没有子节点时被删除。要想使用该类型,必须在zookeeper的bin/zkService.sh中的启动zookeeper的java环境中设置环境变量zookeeper.extendedTypesEnabled=true(具体做法在下边),否则KeeperErrorCode = Unimplemented for /**。
设置zookeeper.extendedTypesEnabled=true
打开zookeeper bin/zkServer.sh(win是zkService.cmd),修改启动zookeeper的命令,加上**-Dzookeeper.extendedTypesEnabled=true**,也就是设置java的一个环境变量。
nohup "$JAVA" $ZOO_DATADIR_AUTOCREATE "-Dzookeeper.log.dir=${ZOO_LOG_DIR}" \
"-Dzookeeper.log.file=${ZOO_LOG_FILE}" "-Dzookeeper.extendedTypesEnabled=true" "-Dzookeeper.root.logger=${ZOO_LOG4J_PROP}" \
-XX:+HeapDumpOnOutOfMemoryError -XX:OnOutOfMemoryError='kill -9 %p' \
-cp "$CLASSPATH" $JVMFLAGS $ZOOMAIN "$ZOOCFG" > "$_ZOO_DAEMON_OUT" 2>&1 < /dev/null &
- PERSISTENT_SEQUENTIAL_WITH_TTL:同上,是不过是带序号的
Zookeeper的操作命令
创建节点
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
[-s]:sequential 序列化的,即可以重复创建,在路径后面加上序列号
[-e]:ephemeral 临时的,断开连接后自动失效
[-c] :表示container node(容器节点),
[-t ttl]:表示TTL Nodes(带超时时间的节点)
[acl]:是针对这个节点创建一个权限的,如果创建权限了,则拥有权限的才可以访问
删除节点
删除节点,-v表示版本号,实现乐观锁机制
delete [-v version] path
更新节点
给节点赋值 -s返回节点状态
set [-s] [-v version] path data
查询节点信息
获取指定节点的值
get [-s] [-w] path
节点状态信息stat
节点除了存储数据内容以外,还存储了数据节点本身的一些状态信息,通过get命令可以获得状态信息的详细内容,如图9-8所示。
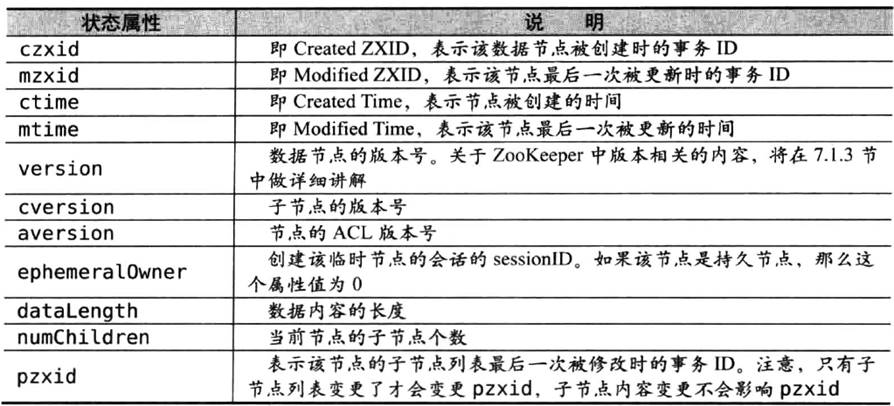
版本-保证分布式数据原子性
zookeeper为数据节点引入了版本的概念,每个数据节点都有三类版本信息,对数据节点任何更新操作都会引起版本号的变化

版本有点和我们经常使用的乐观锁类似。这里有两个概念说一下,一个是乐观锁,一个是悲观锁
悲观锁:是数据库中一种非常典型且非常严格的并发控制策略。假如一个事务A正在对数据进行处理,那么在整个处理过程中,都会将数据处于锁定状态,在这期间其他事务无法对数据进行更新操作。
乐观锁:乐观锁和悲观锁正好想法,它假定多个事务在处理过程中不会彼此影响,因此在事务处理过程中不需要进行加锁处理,如果多个事务对同一数据做更改,那么在更新请求提交之前,每个事务都会首先检查当前事务读取数据后,是否有其他事务对数据进行了修改。如果有修改,则回滚事务
再回到zookeeper,version属性就是用来实现乐观锁机制的“写入校验”
Watcher监听节点事件变化
zookeeper提供了分布式数据的发布/订阅功能,zookeeper允许客户端向服务端注册一个watcher监听,当服务端的一些指定事件触发了watcher,那么服务端就会向客户端发送一个事件通知。zookeeper提供以下几种命令来对指定节点设置监听。
- get [-s] [-w] path:监听指定path节点的修改和删除事件。同样该事件也是一次性触发。
get -w /node # 在其他窗口执行下面命令,会触发相关事件 set /node 123 delete /node
- ls [-s] [-w] [-R] path : 监控指定path的子节点的添加和删除事件。
ls -w /node # 在其他窗口执行下面命令,会触发相关事件 create /node/node1 delete /node/node1
注意: 当前命令设置的监听是一次性的,就是说一旦触发了一次事件监听,后续的事件都不会响应。当然我们可以通过重复订阅来解决
-
stat [-w] path:作用和get完全相同。
-
addWatch [-m mode] path # optional mode is one of [PERSISTENT, PERSISTENT_RECURSIVE] - default is PERSISTENT_RECURSIVE
addWatch的作用是针对指定节点添加事件监听,支持两种模式
- PERSISTENT,持久化订阅,针对当前节点的修改和删除事件,以及当前节点的子节点的删除和新增事件。
- PERSISTENT_RECURSIVE,持久化递归订阅,在PERSISTENT的基础上,增加了子节点修改的事件触发,以及子节点的子节点的数据变化都会触发相关事件(满足递归订阅特性)
Session会话机制
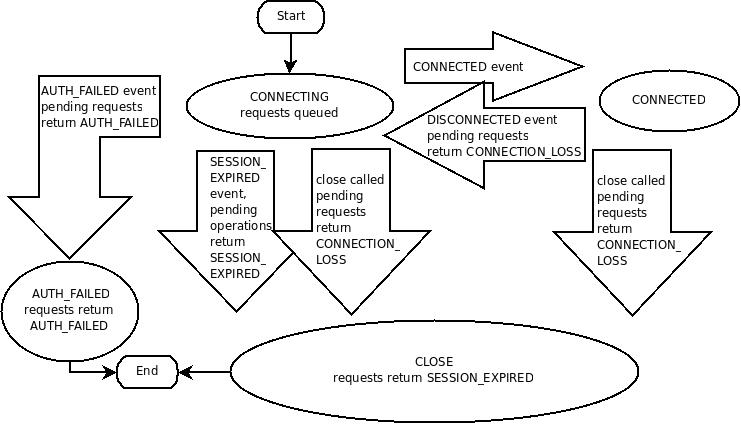
如图9-10所示,表示Zookeeper的session会话状态机制。
- 首先,客户端向Zookeeper Server发起连接请求,此时状态为CONNECTING
- 当连接建立好之后,Session状态转化为CONNECTED,此时可以进行数据的IO操作。
- 如果Client和Server的连接出现丢失,则Client又会变成CONNECTING状态
- 如果会话过期或者主动关闭连接时,此时连接状态为CLOSE
- 如果是身份验证失败,直接结束
Zookeeper的应用场景
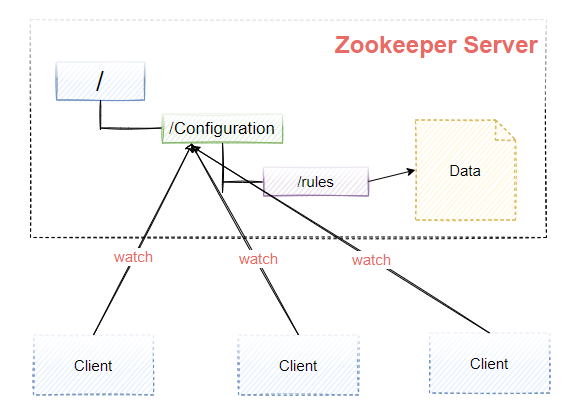
配置中心
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。好吧,现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。
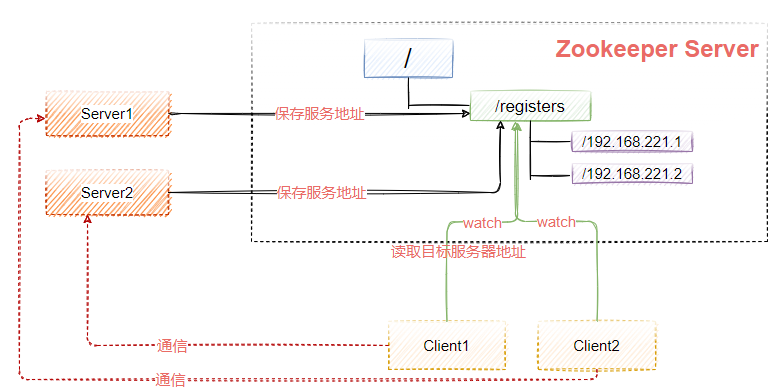
服务注册中心
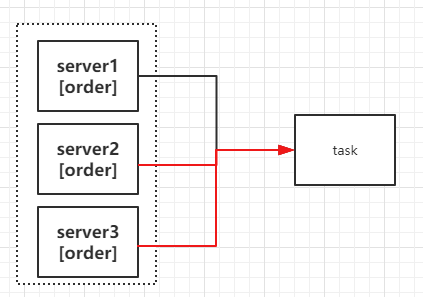
如图9-12所示,Zookeeper可以用来实现服务注册中心,简单来说就是管理目标服务端的地址,客户端调用目标服务端之前,从zookeeper上获得地址进行访问。
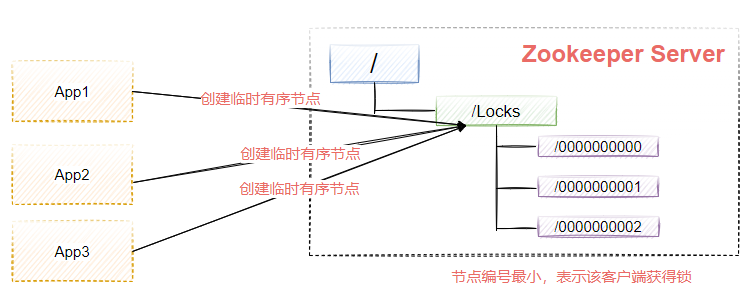
分布式锁
利用临时有序节点实现分布式锁,如图9-13所示,每个App节点要抢占分布式锁,可以先去Zookeeper上创建一个临时有序节点,节点最小的表示该客户端获得了锁,其他没获得锁的客户端先等待,直到获得锁的客户端删除了该节点或者断开会话连接。
-
【机器学习(二)】分类和回归任务-决策树(Decision Tree,DT)算法-Sentosa_DSML社区版11-25
-
增量更新怎么做?-icode9专业技术文章分享11-23
-
压缩包加密方案有哪些?-icode9专业技术文章分享11-23
-
用shell怎么写一个开机时自动同步远程仓库的代码?-icode9专业技术文章分享11-23
-
webman可以同步自己的仓库吗?-icode9专业技术文章分享11-23
-
在 Webman 中怎么判断是否有某命令进程正在运行?-icode9专业技术文章分享11-23
-
如何重置new Swiper?-icode9专业技术文章分享11-23
-
oss直传有什么好处?-icode9专业技术文章分享11-23
-
如何将oss直传封装成一个组件在其他页面调用时都可以使用?-icode9专业技术文章分享11-23
-
怎么使用laravel 11在代码里获取路由列表?-icode9专业技术文章分享11-23
-
怎么实现ansible playbook 备份代码中命名包含时间戳功能?-icode9专业技术文章分享11-22
-
ansible 的archive 参数是什么意思?-icode9专业技术文章分享11-22
-
ansible 中怎么只用archive 排除某个目录?-icode9专业技术文章分享11-22
-
exclude_path参数是什么作用?-icode9专业技术文章分享11-22
-
微信开放平台第三方平台什么时候调用数据预拉取和数据周期性更新接口?-icode9专业技术文章分享11-22
