Java教程
面试必备的线程池知识-线程池的原理

前言
上一篇我们介绍了线程池的使用,这一篇我们接着分析下线程池的实现原理。首先从创建线程池的核心类ThreadPoolExecutor类说起。
ThreadPoolExecutor类的常量
//用来存放工作线程数量和线程池状态
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3; //32-3=29
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
//运行状态,可以执行任务
private static final int RUNNING = -1 << COUNT_BITS;
//不能接受新任务,但是可以执行完正在执行任务
private static final int SHUTDOWN = 0 << COUNT_BITS;
//不能接受新任务,也不能执行已有的任务
private static final int STOP = 1 << COUNT_BITS;
//所有任务都终止,工作线程数归零
private static final int TIDYING = 2 << COUNT_BITS;
//终止状态执行完成
private static final int TERMINATED = 3 << COUNT_BITS;
//获取线程池的状态
private static int runStateOf(int c) { return c & ~CAPACITY; }
//获取工作线程的数量
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }
ctl 变量主要是为了把工作线程数量和线程池状态放在一个整型变量存储而设置的一个原子类型的变量。在ctl中,低位的29位表示工作线程的数量,高位用来表示RUNNING,SHUTDOWN,STOP等线程池状态。上面定义的三个方法只是为了计算得到线程池的状态和工作线程的数量以及得到ctl。
下面是一段线程池的测试代码,定义线程池,并调用execute方法添加任务,并执行任务。
public class ExectorTest {
public static void main(String[] args) {
//给线程设置一个自定义名称
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat("测试线程-%d").build();
ThreadPoolExecutor executorService = new ThreadPoolExecutor(
3,
6,
10,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(5),
threadFactory
// , new ThreadPoolExecutor.CallerRunsPolicy()
);
for (int i=0;i<20;i++) {
executorService.execute(()->{
//模拟耗时的任务
System.out.println(Thread.currentThread().getName()+" 开始执行任务");
int j = 10000 * 10000;
while (j >0) {
j--;
}
System.out.println(Thread.currentThread().getName()+" 执行结束");
});
}
}
}
利用debug模式得到的调试栈如下:
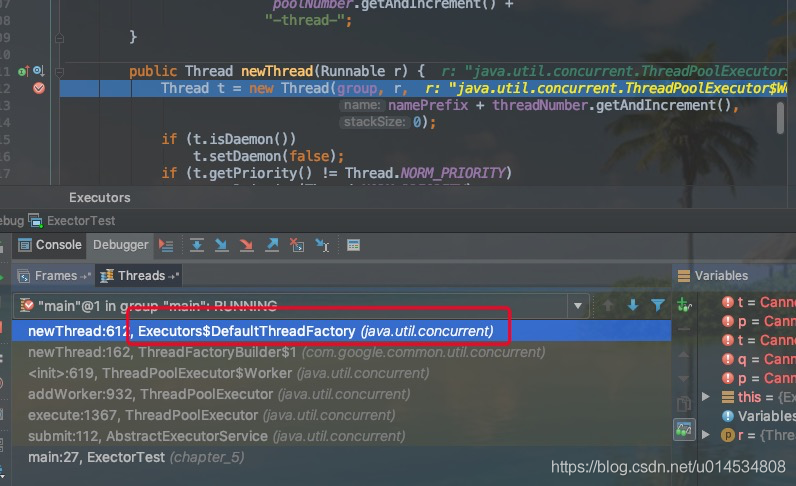
提交任务execute方法是整个线程池的执行入口,下面我就从它开始分析。
execute方法
public void execute(Runnable command) {
//如果任务为空,则抛出NPE异常
if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
*
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
*
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
*/
//获取线程池状态
int c = ctl.get();
//1.如果工作线程的数量小于核心线程数
if (workerCountOf(c) < corePoolSize) {
//调用addWorker增加一个新线程,并执行一个任务
if (addWorker(command, true))
return;
c = ctl.get();
}
//如果线程池的状态是运行状态,并且任务加入到了工作队列成功
if (isRunning(c) && workQueue.offer(command)) {
//双重检查,再次检查线程池的状态。
int recheck = ctl.get();
//如果线程池的状态不是运行状态并且移除任务成功则调用拒绝策略
if (! isRunning(recheck) && remove(command))
//调用RejectedExecutionHandler.rejectedExecution()方法。根据不同的拒绝策略去处理
reject(command);
//如果工作线程的数量为0,说明工作队列中可能有任务没有线程执行,此时则新建一个线程来执行任务,由于执行的是队列中已经堆积的任务,所以没有传入具体的任务。
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//如果前面的新增work,放入队列都失败,则会继续新增worker,此时线程池中的工作线程数达到corePoolSize,阻塞队列任务已满,只能基于maximumPoolSize来继续增加work,如果还是失败
else if (!addWorker(command, false))
//如果还是失败,则调用RejectedExecutionHandler.rejectedExecution()方法。根据不同的拒绝策略去处理
reject(command);
}
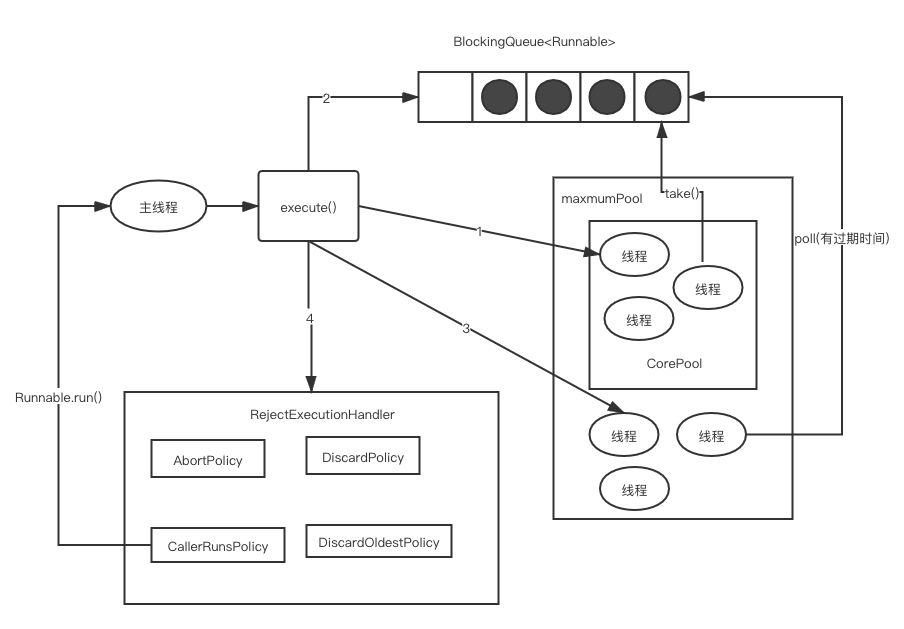
从上代码中,我们可以总结出execute方法主要有如下三个流程
- 如果线程池中当前工作线程数小于核心线程数(corePoolSize),则创建一个新线程来执行传入的任务(执行这一步骤需要获取全局锁)
- 如果工作线程数大于等于核心线程数,并且线程池是运行状态,则将传入的任务加入到工作队列(BlockingQueue)中。
- 如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务(执行这一步骤需要获取全局锁)
- 如果创建新线程将使得当前运行的线程超出maximumPoolSize,任务将被拒绝,并调用RejectedExecutionHandler.rejectedExecution()方法。根据不同的拒绝策略去处理
运行的流程图如下:
从execute()方法可以看到新增线程并且执行任务核心逻辑在addWorker方法中。
addWorker的方法
首先第一段代码,这段代码有两个死循环,外层的死循环主要是检查线程池的状态,更新线程池的状态。内层的死循环,是检查工作线程的数量,并且通过CAS的方式在ctl中更新工作线程的数量。
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
//检查线程池的状态是否是运行状态,并且队列不为空
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
//获取工作线程数
int wc = workerCountOf(c);
//工作线程数
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//通过CAS的方式来在ctl中增加工作线程的数量
if (compareAndIncrementWorkerCount(c))
break retry;
//再次获取状态
c = ctl.get(); // Re-read ctl
//如果状态更新失败,则循环更新
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
分析完了前置的一些检查工作的代码,接下来,来看下主流程的代码:
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
//1. 新建一个工作线程,Work后面会说
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
//加锁
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
//再次获取线程池的状态,在新建线程或者释放锁时,都会重新检查。
int rs = runStateOf(ctl.get());
//如果线程池的状态不是关闭状态,则进入下面的分支
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
//检查新建的线程是否是可运行状态
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//将工作线程添加到HashSet类型的集合中
workers.add(w);
int s = workers.size();
//如果工作线程的集合数大于largestPoolSize
if (s > largestPoolSize)
largestPoolSize = s;
//新建工作线程成功之后,将操作标志workerAdded设为true,表示新增工作线程成功,后续流程用
workerAdded = true;
}
} finally {
//释放锁
mainLock.unlock();
}
//如果新建工作线程成功,则调用start() 方法启动线程
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
//如果workerStarted为false,表示新建工作线程失败
if (! workerStarted)
//移除已经创建的工作线程
addWorkerFailed(w);
}
return workerStarted;
如上,该主流程的代码逻辑也是比较清晰的,首先是新建一个工作线程,然后就是在同步代码块中检查线程池的状态,如果不是SHUTDOWN状态,则将新增的线程放在HashSet类型线程的集合中,放入成功之后,将创建work的标识workerAdded改成true,然后释放锁。接着就是调用start()方法使得线程可以执行任务。接下来就来看看Worker的结构
Work 类
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask; //传入的任务
this.thread = getThreadFactory().newThread(this); //创建一个新线程
}
public void run() {
runWorker(this);
}
}
Worker类是ThreadPoolExecutor类的一个私有内部不变类,其实现了Runnable接口,内部的run()方法里面调用的runWorker()方法。所以,任务的最终执行时通过runWorker()方法的。 在介绍runWorker()之前,我们先看看创建线程的逻辑。
ThreadFactoryBuilder类
按照前面调用栈我们接着分析下ThreadFactoryBuilder。ThreadFactoryBuilder类用于生成ThreadFactory并且设置一些参数,比如线程名,线程的等级,是否是后台线程等信息。这里设置信息用到了建造者模式。代码如下:
public ThreadFactory build() {
return build(this);
}
private static ThreadFactory build(ThreadFactoryBuilder builder) {
final String nameFormat = builder.nameFormat;
final Boolean daemon = builder.daemon;
final Integer priority = builder.priority;
final UncaughtExceptionHandler uncaughtExceptionHandler = builder.uncaughtExceptionHandler;
//没有指定ThreadFactory实现类的话默认就是Executors.defaultThreadFactory()
final ThreadFactory backingThreadFactory =
(builder.backingThreadFactory != null)
? builder.backingThreadFactory
: Executors.defaultThreadFactory();
final AtomicLong count = (nameFormat != null) ? new AtomicLong(0) : null;
//匿名内部类
return new ThreadFactory() {
@Override
public Thread newThread(Runnable runnable) {
//调用 backingThreadFactory.newThread得到生成的工作线程
Thread thread = backingThreadFactory.newThread(runnable);
//重置线程名
if (nameFormat != null) {
thread.setName(format(nameFormat, count.getAndIncrement()));
}
//重置是否是后台线程
if (daemon != null) {
thread.setDaemon(daemon);
}
//重置线程的等级
if (priority != null) {
thread.setPriority(priority);
}
if (uncaughtExceptionHandler != null) {
thread.setUncaughtExceptionHandler(uncaughtExceptionHandler);
}
return thread;
}
};
}
这个类的逻辑比较简单,主要是两步
- 获取ThreadFactory的具体实现类
- 调用ThreadFactory的newThread方法,并重置线程名信息。
接下来我们看看Executors类的内部静态类DefaultThreadFactory类。
DefaultThreadFactory类
static class DefaultThreadFactory implements ThreadFactory {
private static final AtomicInteger poolNumber = new AtomicInteger(1);
private final ThreadGroup group;
private final AtomicInteger threadNumber = new AtomicInteger(1);
private final String namePrefix;
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
//直接new一个工作线程
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
//是否是后台线程
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}
上面DefaultThreadFactory的代码比较简单,就是new一个工作线程并设置工作线程的默认名。说完了创建工作线程的逻辑,接下来,我们来看看执行任务的runWorker方法的逻辑。
runWorker
final void runWorker(Worker w) {
//获取当前线程
Thread wt = Thread.currentThread();
//获取当前的任务
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//一般情况下,task都不会为空(特殊情况上面注释就是前面execute方法说的)或者可以从工作队列中取到任务,会直接进入循环体中。
while (task != null || (task = getTask()) != null) {
//加锁
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
//如果线程池正在停止,确保线程是被中断,
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//该方法是个空的实现,如果有需要用户可以自己继承该类进行实现
beforeExecute(wt, task);
Throwable thrown = null;
//调用任务的run方法,真正的任务执行逻辑
task.run();
.....省略部分代码
finally {
//该方法是个空的实现,如果有需要用户可以自己继承该类进行实现
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
//当指定任务执行完成,阻塞队列中也取不到可执行任务时,会进入这里,做一些善后工作,比如在corePoolSize跟maximumPoolSize之间的woker会进行回收
processWorkerExit(w, completedAbruptly);
}
}
work线程的执行流程就是首先执行初始化分配给的任务,执行完成之后会尝试从阻塞中获取可执行的任务,如果指定时间内仍然没有任务可以执行,则进入销毁逻辑,这里只会回收corePoolSize与maxmumPoolSize之间的那部分worker。
getTask方法
这里getTask方法的实现更我们构造参数设置存活时间有关,我们都知道构造参数设置的时间代表了线程池中的线程,即worker线程的存活时间,如果到期则回收worker线程,这个逻辑的实现就在getTask中。来不及执行的任务,线程池会放入一个阻塞队列(工作队列),getTask方法就是去工作队列中取任务,用户设置的存活时间,就是从这个阻塞队列中取任务等待的最大时间,如果getTask返回null,意思就是worker等待了指定时间仍然没有取到任务,此时就会跳过循环体,进入worker线程销毁逻辑。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
//线程池如果是SHUTDOWN或者STOP状态,则将work移除。
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// 对于allowCoreThreadTimeOut为true(设置了核心线程的存活时间),或者是在corePoolSize与maxmumPoolSize之间的那部分worker
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//如果timed为true,则需要在keepAliveTime时间内取任务,否则没有存活时间的限制
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
总结
本文对线程池添加任务,执行任务的源码做了重点解析,内部用到了很多设计模式,比如创建线程用到了工厂模式,设置线程的属性用到了建造者模式。同时还用到了锁等知识。了解其实现原理对我们更好的使用线程池大有好处。
-
JAVA语音识别项目项目实战入门教程11-25
-
JAVA云原生项目实战入门教程11-25
-
Java语音识别项目入门:新手必读指南11-25
-
Java语音识别项目入门:轻松开始你的第一个语音识别项目11-25
-
Java语音识别项目入门详解11-25
-
Java语音识别项目教程:从零开始的详细指南11-25
-
JAVA语音识别项目教程:初学者指南11-25
-
Java语音识别项目教程:初学者指南11-25
-
JAVA云原生入门:新手指南与基础教程11-25
-
Java云原生入门:从零开始的全面指南11-25
-
Java云原生入门:新手必读教程11-25
-
JAVA云原生教程:新手入门及实战指南11-25
-
Java云原生教程:新手入门指南11-25
-
Java云原生教程:入门与实践指南11-25
-
Java对接阿里云智能语音服务项目实战教程11-25
