Java教程
JDK成长记14:(深度好文)你能从3个层面分析volatile底层原理么?(下)


上一节我们基本了解Volatile的作用,从JMM层面简单分析了下volatile可见性的实现要求。发现JMM设定了一些操作要求,在这些要求下,可以保证线程间的可见性。可是具体实现是怎么实现的呢?
但是你要想理解这个实现是比较难的,之前提到按照三个层面给大家讲解。如下图所示:

其实上一节通过JMM分析volatile是归于JVM层面分析的一部分而已。
你要想完全弄清楚volatile的可见性和有序性,你还要继续分析字节码层面的JVM指令标记是什么?Hotspot实现的JSR内存屏障是什么意思?最终实现的C++代码发出的汇编指令是什么?以及硬件层面如何实现可见性和有序性的?
所以这一节我们来继续研究其余的部分。首先从最简单的一个例子看起,之后手写出一个DCL单例,通过这个例子我们来真正的弄清楚java代码层面到JVM层面再到CPU层面的volatile原理。
让我们开始吧!
从手写一个DCL单例开始分析volatile
从手写一个DCL单例开始分析volatile
在写DCL单例前我们先简单写一个volatile的例子,从java代码和字节码层面分析volatile底层原理。代码如下:
public class DCLVolatile {
volatile int i = 10;
}
你可以在IntelliJ中通过jclasslib插件(自行百度安装)可以看到编译后的字节码格式,这个volatile变量int i对应的格式如下:
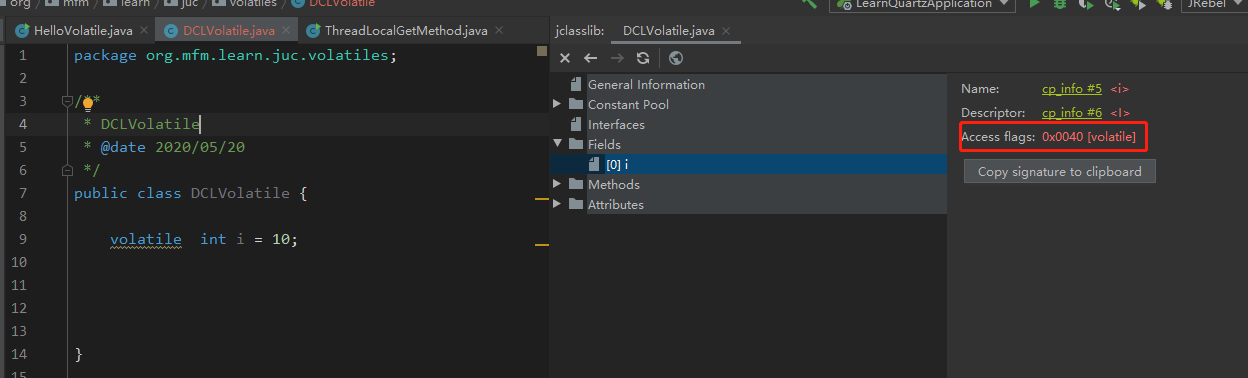
而通常不加volatile的变量,比如int m 的字节码标识如下所示:
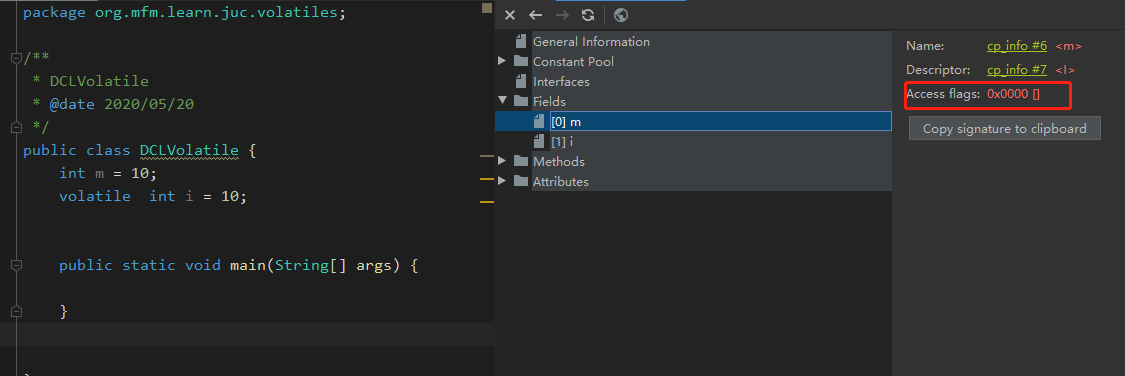
可以看出在java代码层面volatile修饰的变量通过javac静态编译后,变成了带有Access flags 0x0040这个特殊标记的变量,这样之后就可以被JVM识别出来。这里是常量,如果是静态的instance对象是0x004a,非静态的是0x0042。
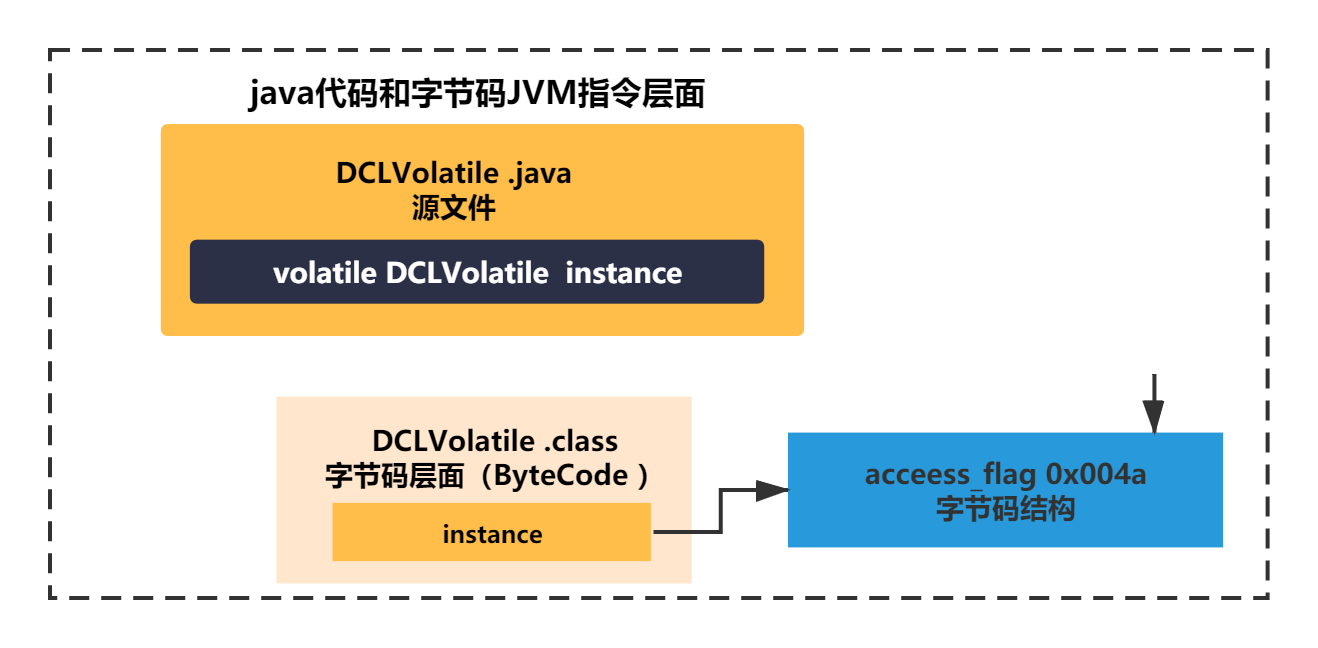
手写DCL单例,第一步你需要应该声明一个volatile的实例变量。(后面会将为什么是volatile的,大家不要着急)。
代码如下:
public class DCLVolatile {
private static volatile DCLVolatile instance; //0x004a
}
所以在这个层面你可以得到如下的一张图:
接着你需要了解一个对象创建的时候的字节码指令,以便于之后分析指令重排序的问题。代码如下:
public class DCLVolatile {
/**
* ByteCode:Access Flag 0x004a
*/
private static volatile DCLVolatile instance;
private DCLVolatile(){
}
/**
* ByteCode:
* 0 new #2 <org/mfm/learn/juc/volatiles/DCLVolatile>
* 3 dup
* 4 invokespecial #3 <org/mfm/learn/juc/volatiles/DCLVolatile.<init>>
* 7 astore_0
* 8 aload_0
* 9 areturn
* @return
*/
public static DCLVolatile getInstance() {
DCLVolatile instance = new DCLVolatile();
return instance;
}
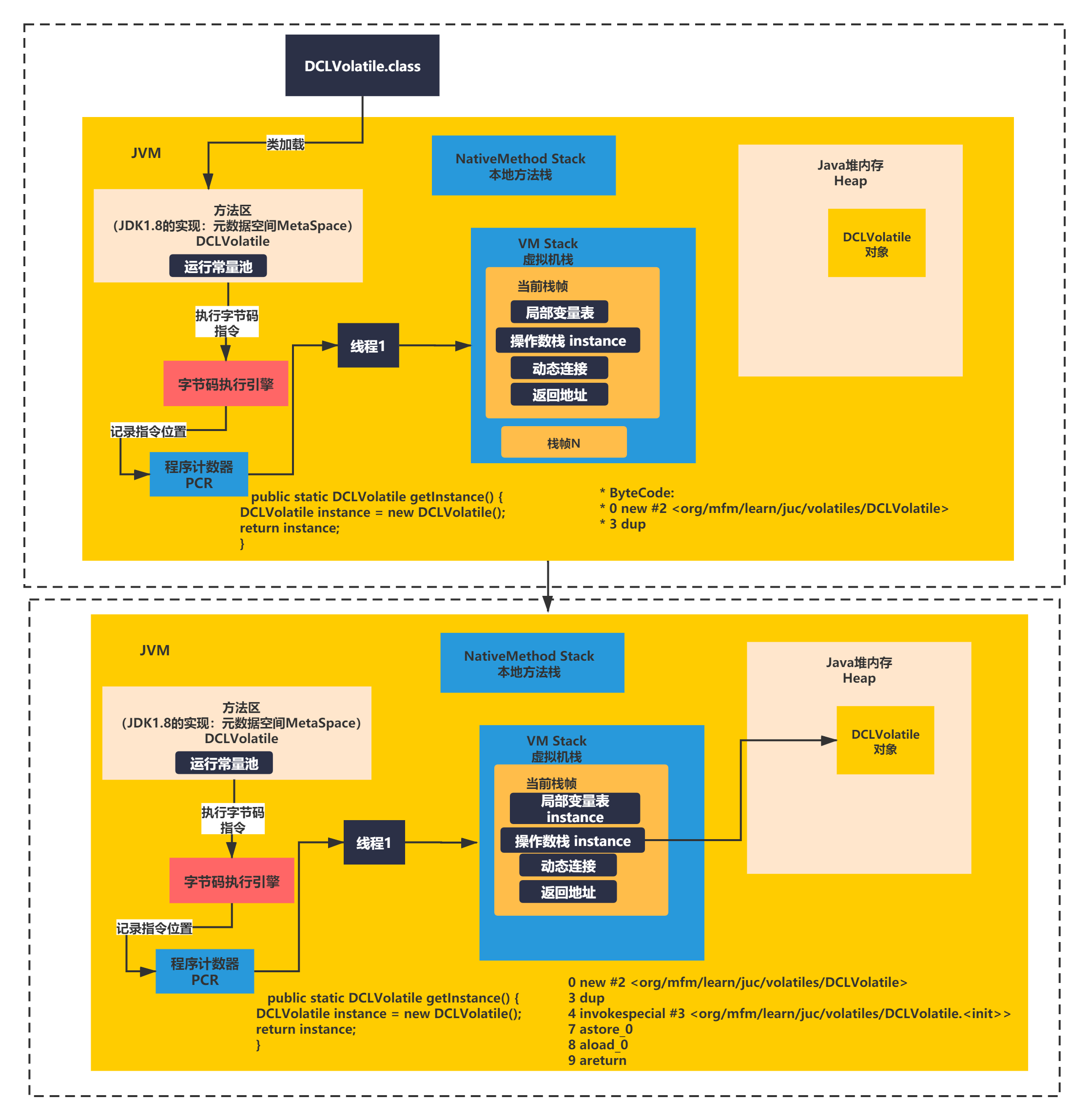
从上面的代码可以看出 DCLVolatile instance = new DCLVolatile();的字节码主要是如下几行:
0 new #2 <org/mfm/learn/juc/volatiles/DCLVolatile> 3 dup 4 invokespecial #3 <org/mfm/learn/juc/volatiles/DCLVolatile.<init>> 7 astore_0
如果这几条字节码实际就是JVM指令,具体意思可以查阅官方的JVM指令手册。这里我直接用大白话给大家解释下:
new 肯定就是创建一个对象。注意这里只是在堆中分配空间,(叫半初始化)此时instance = null,并没有指向堆空间
dup其实就是入操作数栈一个变量instance。
invokespecial其实执行了初始化操作,使用instance引用指向堆分配的空间。
astore_0将一个数值从操作数栈存储到局部变量表。
JVM指令 JVM除了对底层硬件内存模型进行了抽象,对执行CPU指令同样进行了抽象,这样可以更好地做到跨平台性。 既然JVM将底层CPU执行指令的过程进行了抽象,这里我们不去细讲JVM,抽象的内容大致可以概况为如下一句话: 执行class文件的时候是通过在内存结构,一套复杂的入栈出栈机制执行class中的各个JVM指令,在执行指令层面,它有自己一套独特的JVM指令集,而这写JVM指令就是来源于我们写好的Java代码。
上面过程如下图所示:
你可以接着完善DCL单例最终为:
public class DCLVolatile {
private static volatile DCLVolatile instance;
private DCLVolatile(){
}
public static DCLVolatile getInstance()
if( instance == null){
synchronized (DCLVolatile.class){
if(instance == null){
instance = new DCLVolatile();
}
}
}
return instance;
}
}
上面这段代码,double判断+ synchronized+valotile这就是典型的 DCL单例,线程安全的。可以保证多个线程获取instance是线程安全,且是同一个对象。synchronized是为了保证多线程同时创建对象的这个操作的安全性,double判断+volotile是为了保证这个创建操作的可见性和有序性。
上面的输出结果证明了这个是线程安全的单例。
你可以测试下:
public static void main(String[] args) {
new Thread(()->{
DCLVolatile instance = DCLVolatile.getInstance();
System.out.println(instance);
}).start();
new Thread(()->{
DCLVolatile instance = DCLVolatile.getInstance();
System.out.println(instance);
}).start();
}
输出如下:
org.mfm.learn.juc.volatiles.DCLVolatile@71219ecd
org.mfm.learn.juc.volatiles.DCLVolatile@71219ecd
上面的输出结果证明了这个是线程安全的单例。
Java代码+字节码层面分析:为什么会乱序?
Java代码+字节码层面分析:为什么会乱序?
volatile的可见性体现:
instance == null是volatile的读,instance = new DCLVolatile();是volatile的写,线程之间是可见的。
volatile的有序性体现:
要想知道为什么它保证了有序性,需要了解为什么会有乱序、DCL中,字节码乱序了会怎么样。
一个一个来看下,首先是为什么会乱序?
所有的编程语言最终会变成01的机器码,让CPU硬件可以认识。你写的java代码也一样,java代码到CPU执行指令的过程如下图所示:
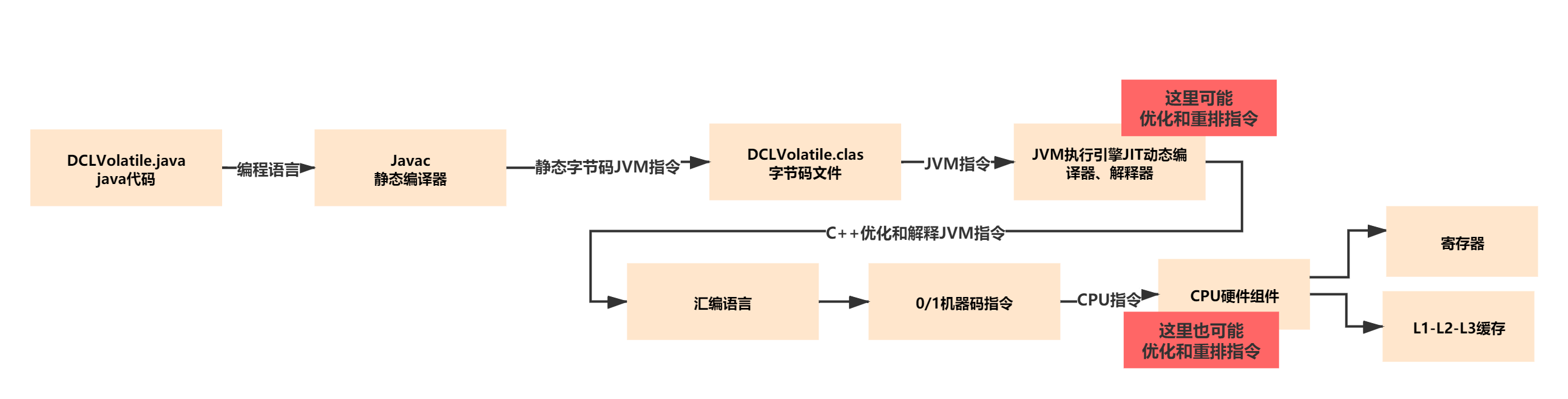
图中标红色的就是可能指令重排的地方, 因为了提高并发度和指令执行速度,CPU或者编译器会进行指令的优化和重排。但是我们有时候不希望指令重排,打乱顺序可能造成一些有序性问题。这时候就需要一些方法来控制和实现这一点了。Java中volatile关键字就是一种方法。
书曰重排序:是指编译器和处理器为了优化程序性能而对指令序列进行重新排序的一种手段。 在单线程程序中,对存在控制依赖的操作重排序,不会改变执行结果(这也是as-if-serial语义允许对存在控制依赖的操作做重排序的原因);但在多线程程序中,对存在控制依赖的操作重排序,可能会改变程序的执行结果。 其实可以理解为,就是cpu为了优化代码的执行效率,它不会按顺序执行代码,会打乱代码的执行顺序,前提是不影响单线程顺序执行的结果。(当然了,只考虑cpu级别的重排序,还有其他的)
Java代码+字节码层面分析:字节码乱序了会怎么样?
Java代码+字节码层面分析:字节码乱序了会怎么样?
了解了为什么会乱序后,接着我们看下字节码乱序了会怎么样?
回到上面的DCL单例的代码中,上面你了解了创建一个对象的字节码后,你需要分析下完善后的getInstance方法字节码,如下:
0 getstatic #7 <org/mfm/learn/juc/volatiles/DCLVolatile.instance> 3 ifnonnull 37 (+34) 6 ldc #8 <org/mfm/learn/juc/volatiles/DCLVolatile> 8 dup 9 astore_0 10 monitorenter 11 getstatic #7 <org/mfm/learn/juc/volatiles/DCLVolatile.instance> 14 ifnonnull 27 (+13) 17 new #8 <org/mfm/learn/juc/volatiles/DCLVolatile> 20 dup 21 invokespecial #9 <org/mfm/learn/juc/volatiles/DCLVolatile.<init>> 24 putstatic #7 <org/mfm/learn/juc/volatiles/DCLVolatile.instance> 27 aload_0 28 monitorexit 29 goto 37 (+8) 32 astore_1 33 aload_0 34 monitorexit 35 aload_1 36 athrow 37 getstatic #7 <org/mfm/learn/juc/volatiles/DCLVolatile.instance> 40 areturn
你可以抓大放小,只关心创建对象的字节码:
10 monitorenter 11 getstatic #7 <org/mfm/learn/juc/volatiles/DCLVolatile.instance> 14 ifnonnull 27 (+13) 17 new #8 <org/mfm/learn/juc/volatiles/DCLVolatile> 20 dup 21 invokespecial #9 <org/mfm/learn/juc/volatiles/DCLVolatile.<init>> 24 putstatic #7 <org/mfm/learn/juc/volatiles/DCLVolatile.instance> 27 aload_0 28 monitorexit 29 goto 37 (+8) 32 astore_1 33 aload_0 34 monitorexit
monitorenter是synchronized的指令,现在可以先忽略,后面我们讲Synchronized的时候会详细讲解。
创建对象的字节核心还是3步
1) 分配空间,半初始化 new
2) 之后进行赋值操作 invokespecial
3) 再之后进行引用指向对象 astore_1
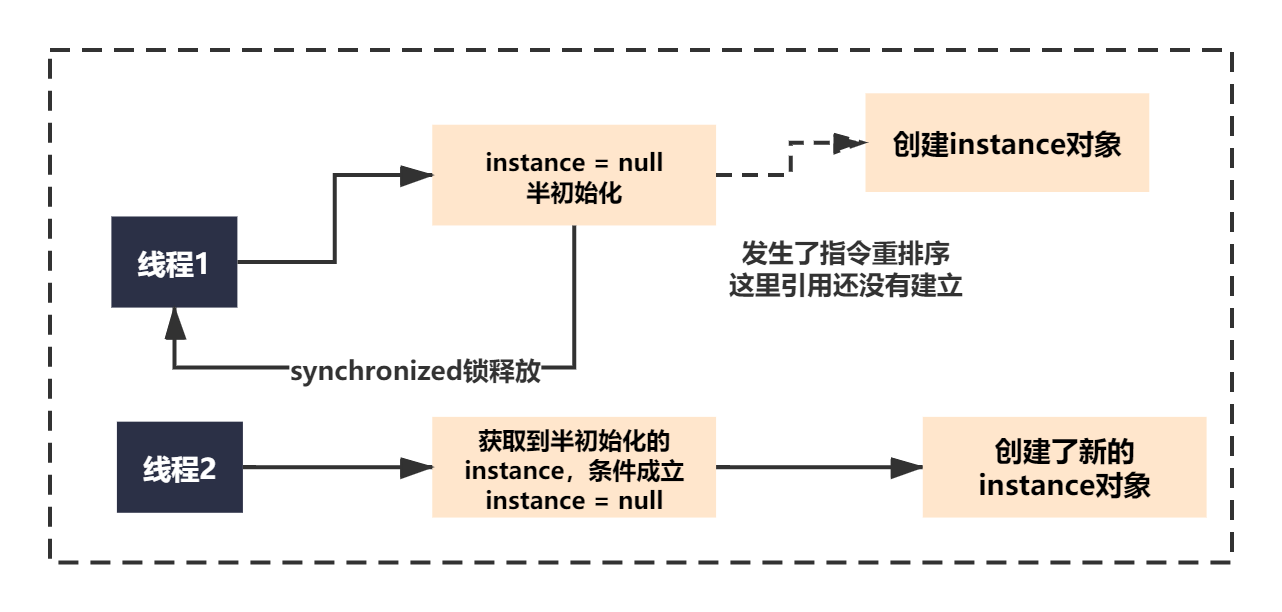
大家可以想象下,如果两个线程同时调用getInstance方法。
线程1获取到sychronized的锁,第一次创建instance的时候,如果2)3)步的指令发生了重排序,如果没有volatile禁止重排序的话。如下代码创建的instance就可能不是同一个对象了。
public static DCLVolatile getInstance() {
if( instance == null){
synchronized (DCLVolatile.class){
if(instance == null){
instance = new DCLVolatile();
}
}
}
return instance;
}
线程2获取到了instance可能是一个半初始化的对象,也就是null,直接使用的话肯定会有问题,就会创建一个新的instance,不是单例了,这就是有序性造成的问题。
如下图所示:
再次从JVM层面分析:JVM指令怎么执行的?
再次从JVM层面分析:JVM指令怎么执行的?
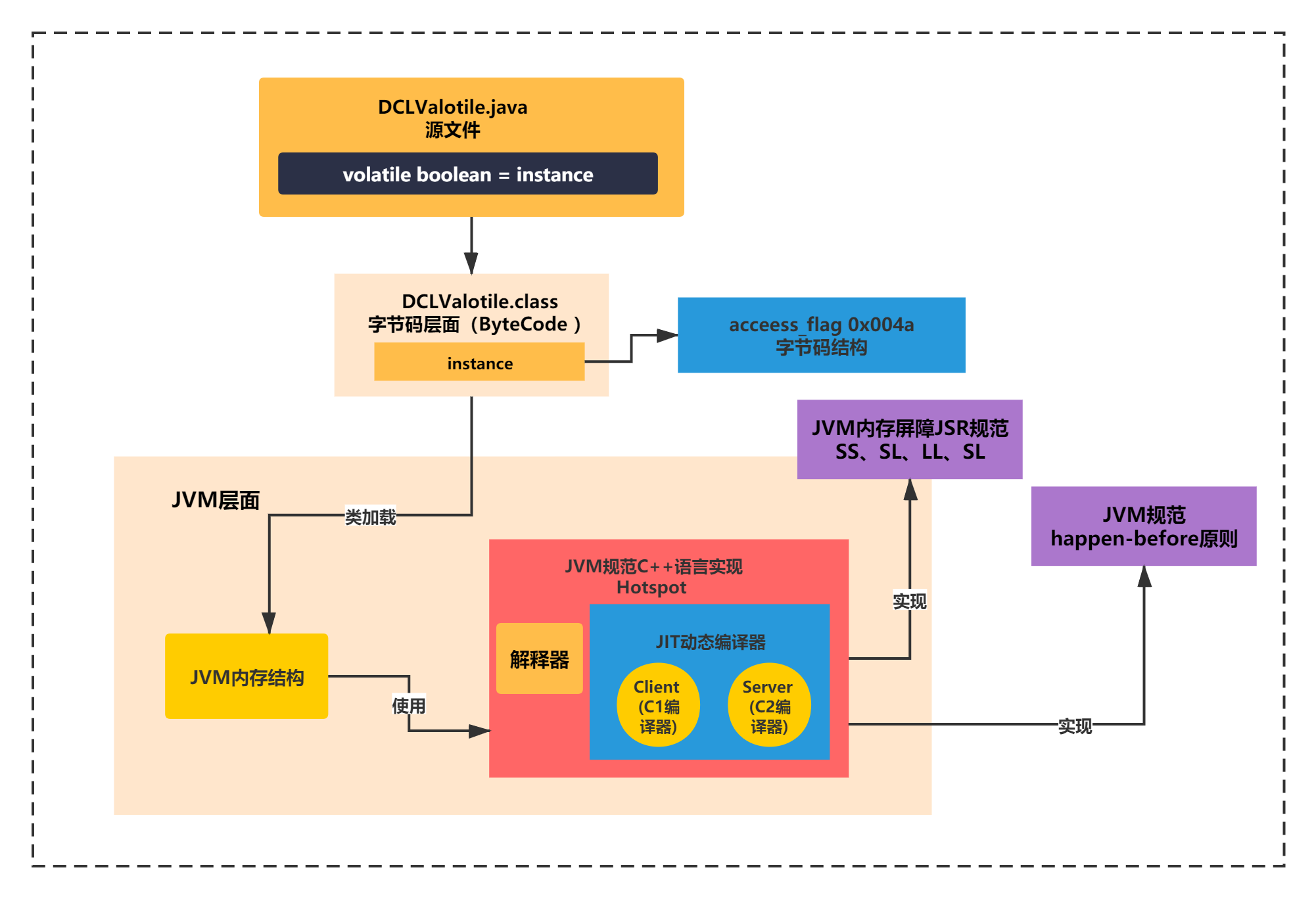
经过上面DCL单例的例子,相信你已经对java代码到字节码的volatile的作用有了进一步了解,具体怎么实现可见性和有序性的根本原理呢?这还是在JVM层面实现的,所以下面,我们接着进入JVM层面来分析。
接下来你会明白上面的JVM指令具体如何执行,由谁执行,又遵循哪些规范和规则?
让我们来一一看下。
JVM指令具体如何执行
JVM首先就是通过类加载器加载class到JVM内存区域,之后又通过执行引擎来执行JVM指令。
不同的过JDK版本有不同的的JVM实现。有耳熟能详的HotSpot,有淘宝自己的JVM实现,还有J9、OpenJDK等其他的JVM实现……
但JDK1.8后,最常见的就是HotSpot的JVM的实现。它是一套主要以C++代码为主实现的JVM虚拟机。我们就以HotSpot举例。
上述过程如下图所示:
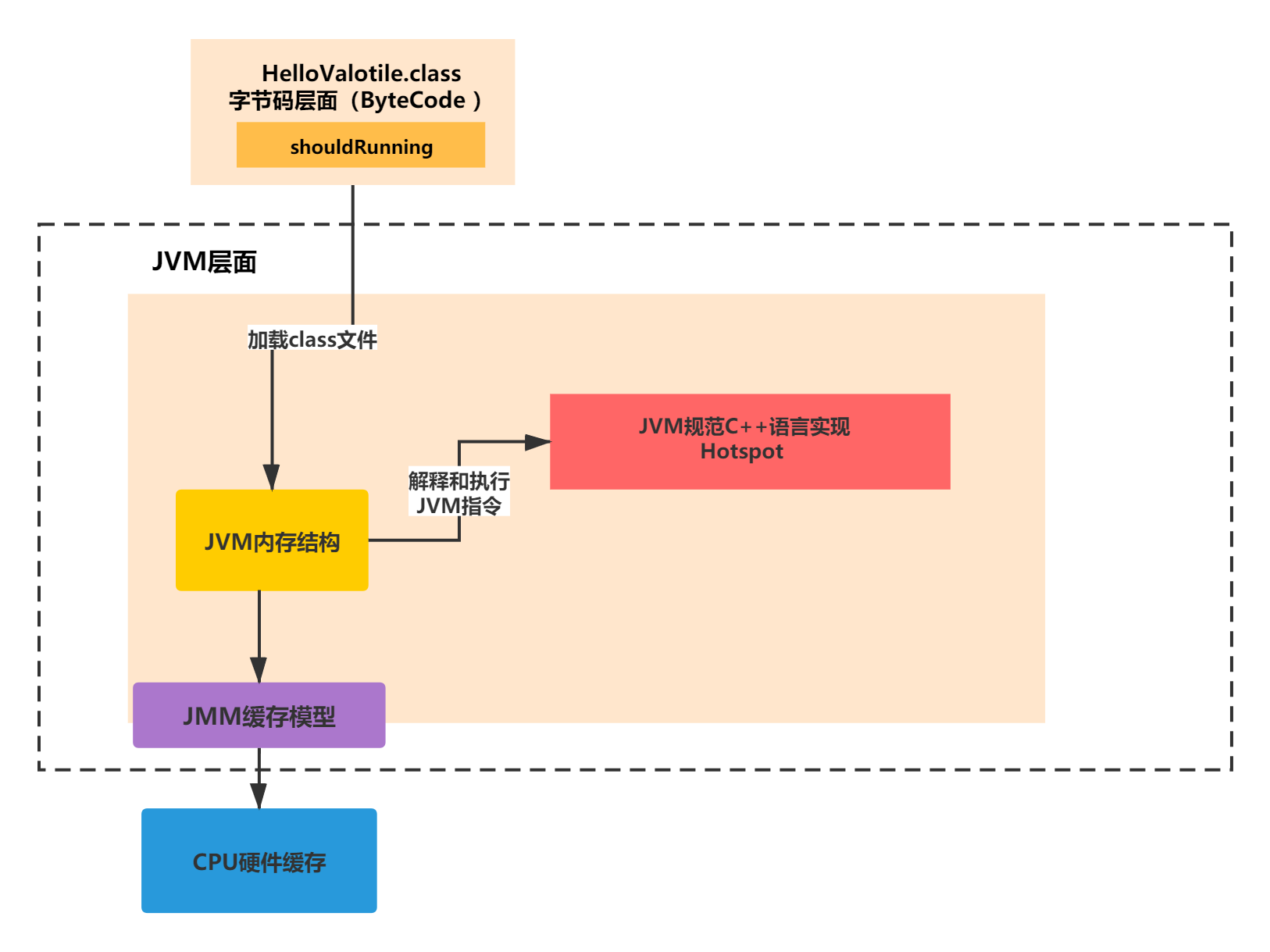
那么,编译好的字节码文件被JVM通过类加载器加载到内存结构之后,会被HotSpot来进行调度和执行对应的JVM指令。
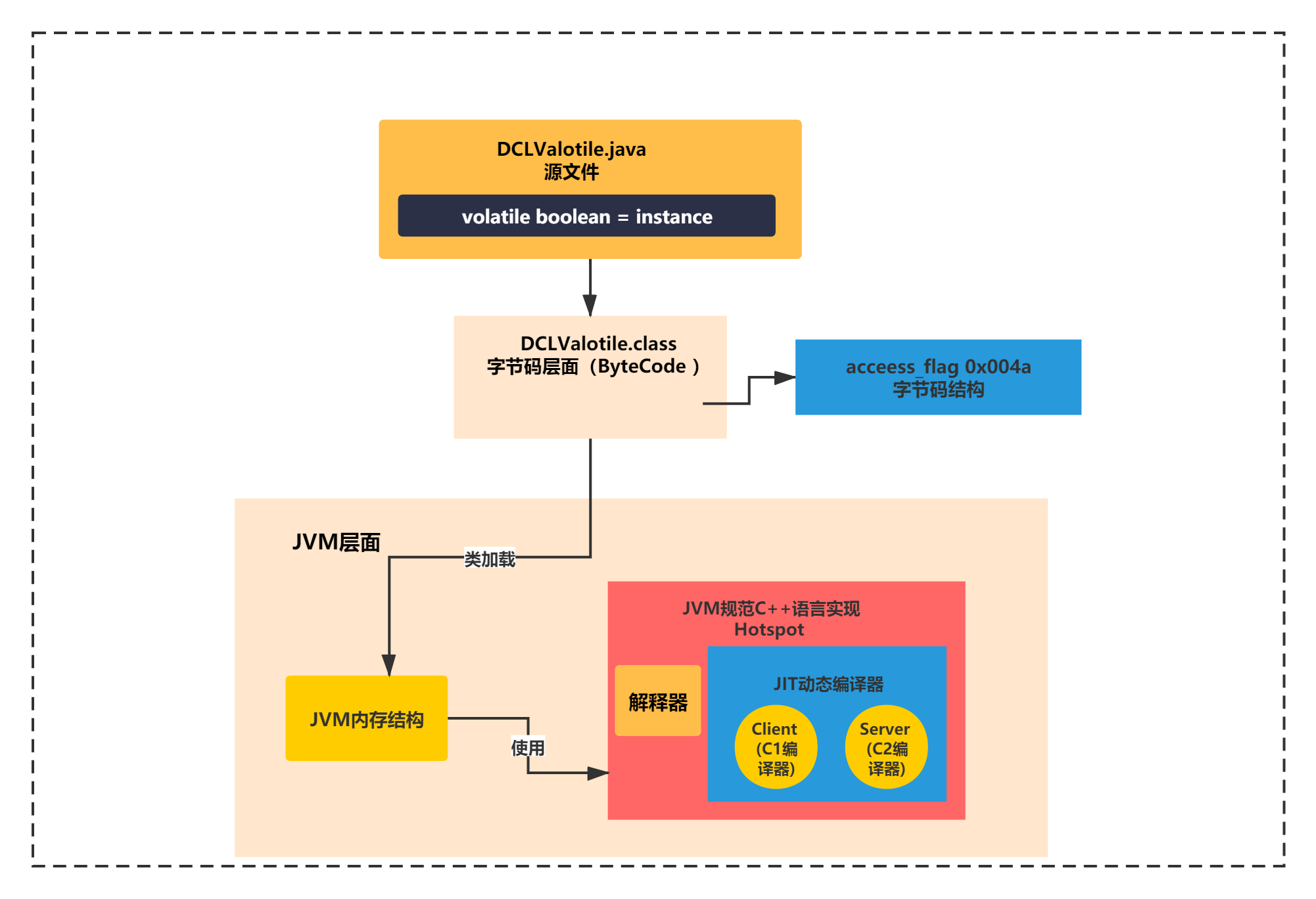
怎么执行的呢?
HotSpot是通过内部的解释器、JIT动态编译器(含Client(C1)编译器、Server(C2)编译器)来执行JVM指令。
如下图所示:
HotSpot是JVM规范的一个实现,它遵循了很多JVM虚拟机规范和JSR规范。
什么是规范? 规范可以打个比喻,规范就好比插座的插槽、插头,它们定义了2孔和3孔的间距等等。所有的厂家都得遵循这个规范,才能让所有的插头插入插板,只要这个插头符合规范,可以是任何牌子,也就是任何厂商的实现。而Java领域有很多规范,一般是由一个公共组织JCP来定义的,定义的规范是JSR-XXX。这个其实也有点像java中的接口和实现类的感觉,说白了就是具体事物的抽象定义。
JVM的虚拟机规范定义了一些规则,和可见性和有序性有关的规则是**happen-before 规则:要求8种情况不能乱序执行。(可以自行百度)**其中有一条很重要的规则就是:
volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作。volatile变量写,再是读,必须保证是先写,再读。
Java中,其中有一个JSR规范,描述了内存屏障相关规范:
-
**LoadLoad****屏障:**对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
-
**StoreStore****屏障:**对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
-
**LoadStore****屏障:**对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
-
**StoreLoad****屏障:**对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。
网上有很多博客讲解volatile的原理,里面写的乱七八糟的,让人看到头晕眼花。搞不清楚内存屏障,JVM指令各种关系。真心让人看到有些累。4种内存屏障其实是规范定义而已,这一点大家一定要搞明白。
在volatile的JVM实现中,是这么使用屏障的。
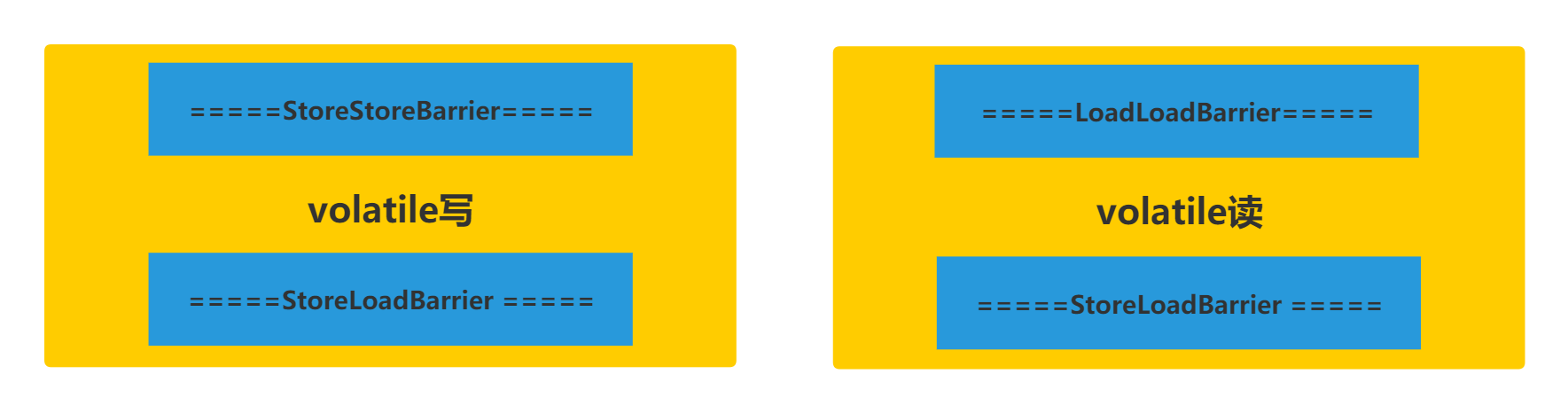
上面四种内存屏障结合happen-before原则,其实就是一句话:
比如LoadLoadBarrier,就是表示上面一条Load指令(读指令),下面一条Load指令,不能重排序。
那你肯定就知道了StoreLoadBarrier屏障是什么意思。就是表示上面一条Store指令(写指令),下面一条Load指令,不能重排序。
注意,上面这些规范只是定义,类似于接口,具体怎么实现就得看HotSpot的C++代码了。 如下图所示:
Java代码+字节码层面分析:字节码乱序了会怎么样?
再次从JVM层面分析:HotSpot到底怎么禁止重排序的呢?
再次从JVM层面分析:HotSpot到底怎么禁止重排序的呢?
实际是通过一些C++的fense方法,生成一些汇编语言,最终转换为机器码,执行CPU指令。所谓的内存屏障实际是一条特殊的指令,要求不能换顺序。
如下图所示:
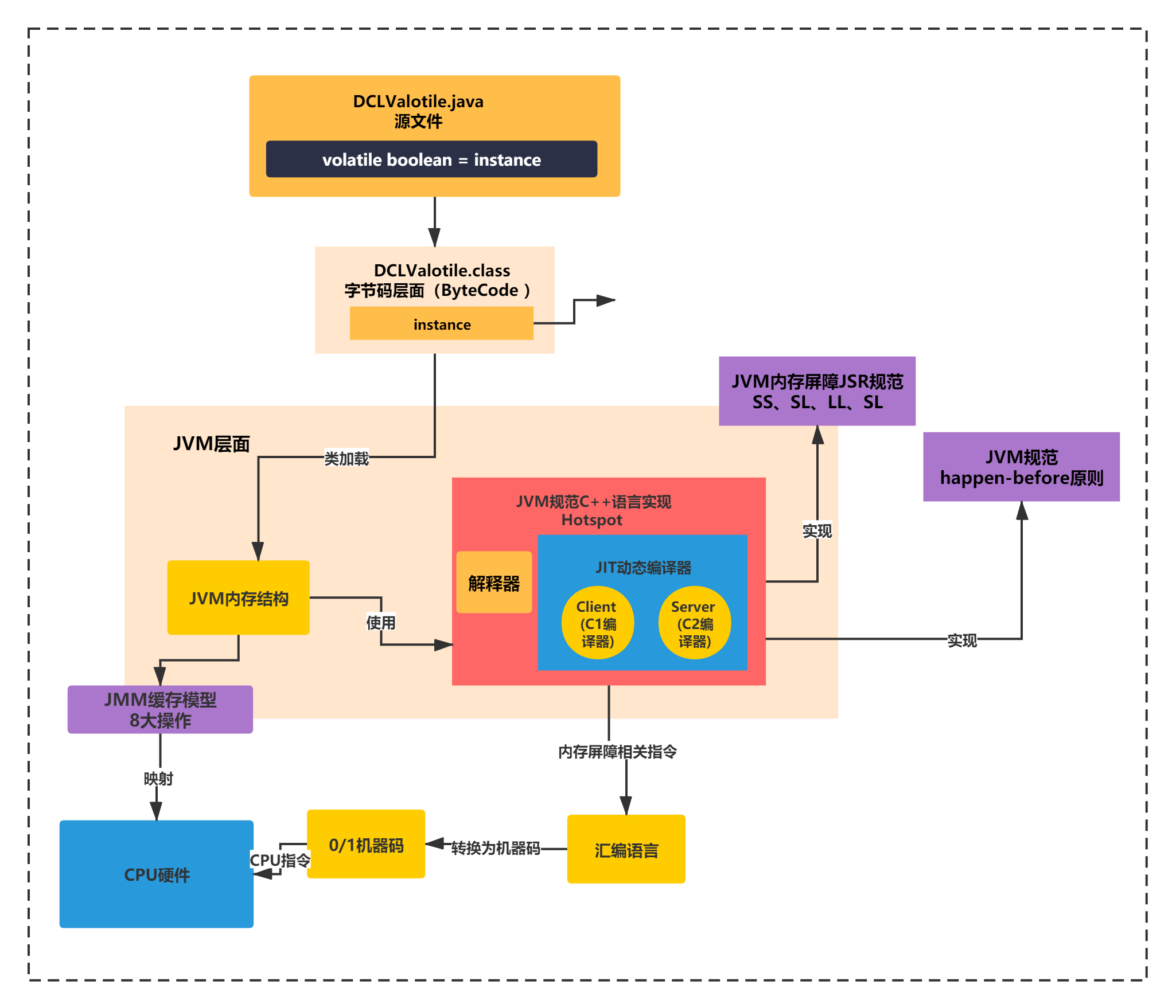
这里我们不去深入HotSopt源码,在里面也看不出来发送给CPU的指令,需要通过工具才能看出来。你可以通过JIT生成代码反汇编工具:(HSDIS),看出来发送给CPU的汇编代码指令,注意,汇编代码是给人看到,实际CPU还是识别0/1的机器码,来执行Cpu指令的。
通过HSDIS工具,可以执行得到如下JIT反汇编语言:!

好了到了这里,基本JVM这一层面的volatile原理,就给大家分析清楚了。可以看到,volatile最终会转换为一条CPU的lock前缀指令。
从CPU层面分析:volatile底层原理
从CPU层面分析:volatile底层原理
JVM不同的实现,对发送给CPU的指令实际都一些差异,而且在历史上,CPU实现方式也可能不同,主要有如下三种机制:

前一个小节提到了lock前缀指令,是最常提到的的方式,适用于所有CPU,所有CPU都支持这个指令。lock前缀指令的之前是锁总线这个硬件的传输,由于性能太差,后面优化成了总线嗅探机制+MESI协议。这样好处是可以跨平台,没有CPU硬件的各种限制。
据我所知,起码OpenJDK和HotSpot是使用lock这种方式的这样的(这个考证起来比较困难,如果这里写的不对,欢迎各位大神指出!)
除了lock前缀指令,也可以通过一些fence指令做到可见性和有序性的保证,当然耳熟能详的通过MESI协议也可以做到。
下面我们分别来看下这3种机制。
在了解之前,这里需要回顾下计算机的组成和CPU的硬件缓存结构,之前也提到过,CPU的硬件缓存结构实际是可以和JMM内存逻辑模型对应上的。
我们先来看下,计算机的组成如下图:
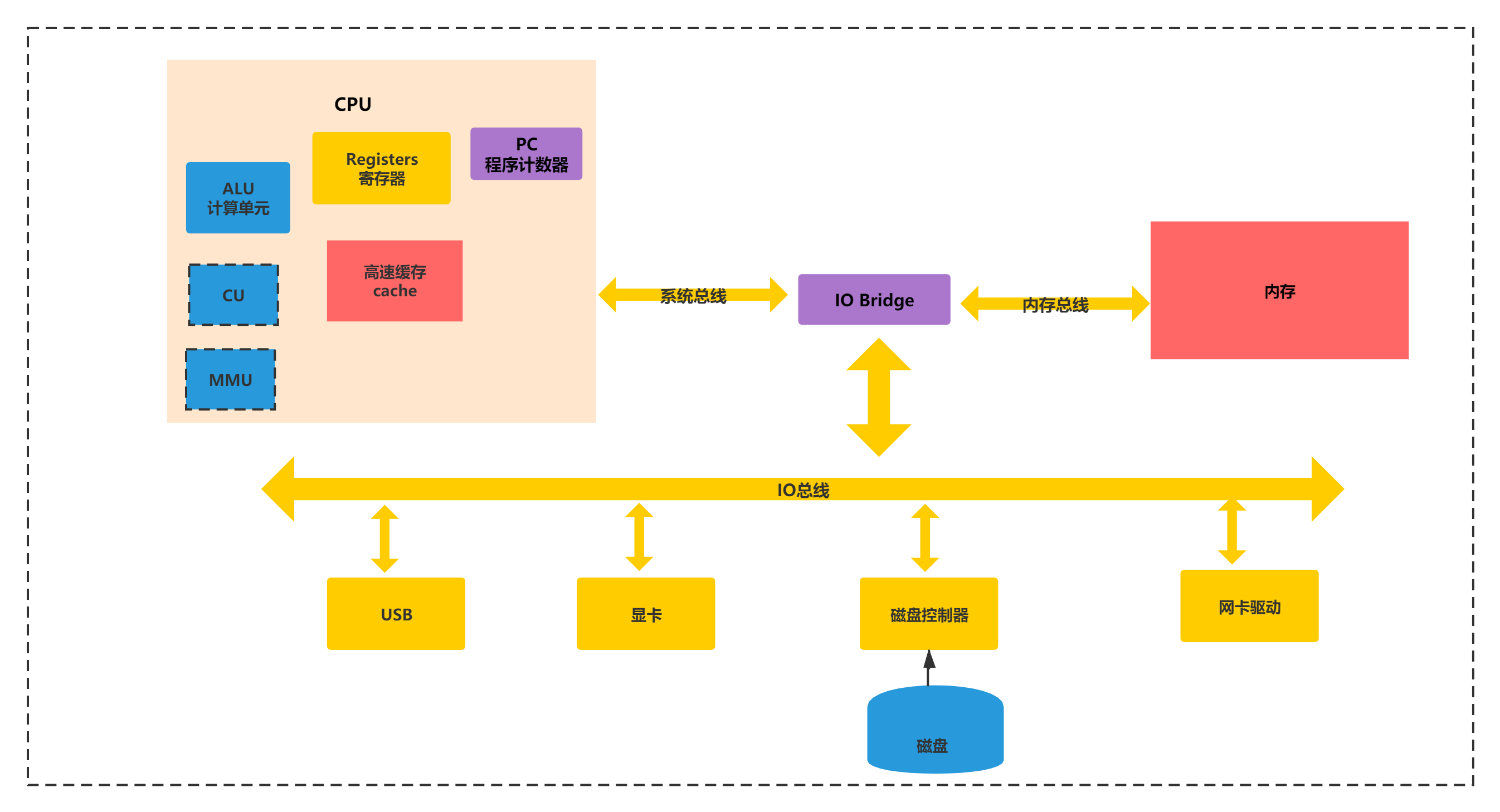
再来看下CPU核心组件图:
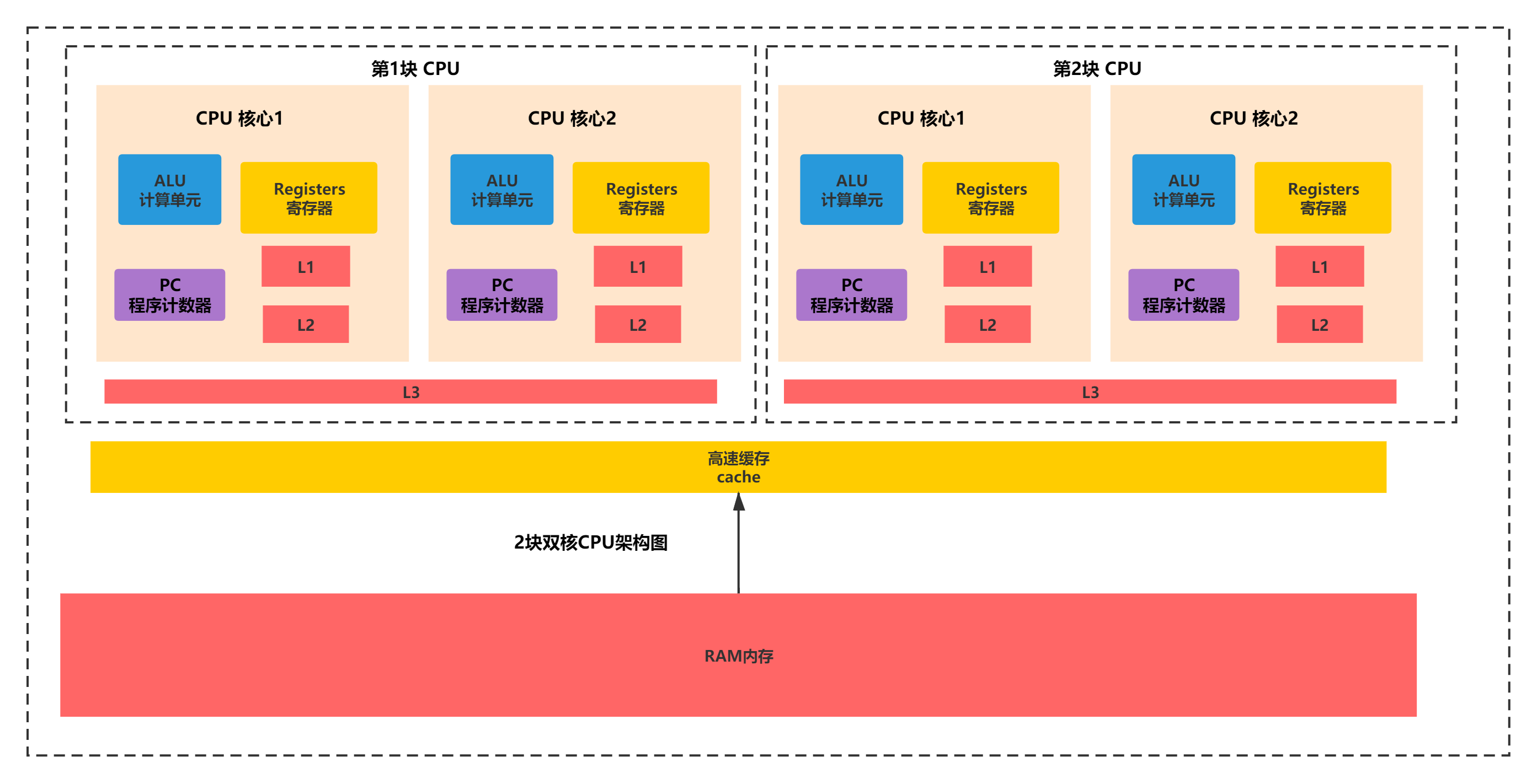
有了上面的2张图,你就可以知道,实际CPU执行的是通过共享的内存:高速缓存、RAM内存、L3,CPU内部线程私有的内存L1、L2缓存,通过总线从逐层将缓存读入每一级缓存。如下流程所示:
RAM内存->高速缓存(L4一般位于总线)->L3级缓存(CPU共享)->L2级缓存(CPU内部私有)->L1级缓存(CPU内部私有)。
这样当java中多个线程执行的时候,实际是交给CPU的每个寄存器执行每一个线程。一套寄存器+程序计数器可以执行一个线程,平常我们说的4核8线程,实际指的是8个寄存器。所以Java多线程执行的逻辑对应CPU组件如下图所示:
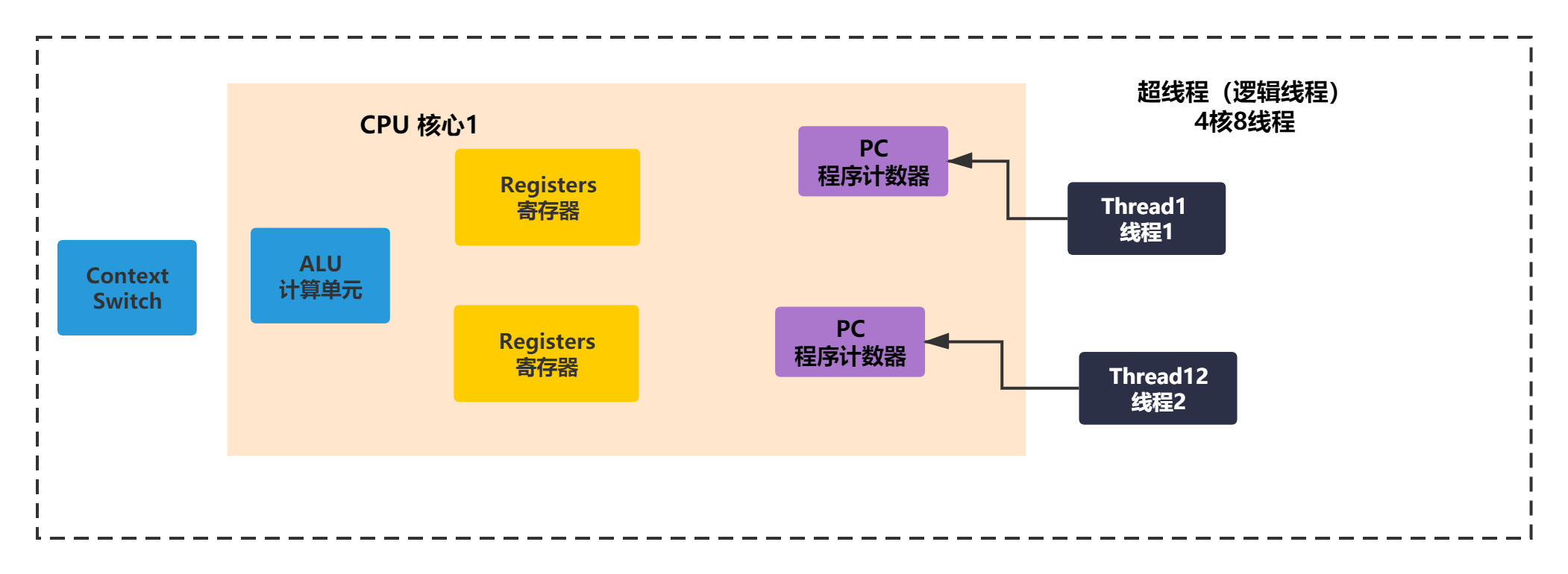
当你有了上面几张图的概念,就可以理解指令在不同CPU和缓存直接作用。
CPU硬件实现可见性和有序性3种机制
系统fence类指令
X86 CPU的可以通过fence类指令实现类似内存屏障的操作:
a) sfence:在sfence指令前的写操作当必须在sfence指令后的写操作前完成。
b) lfence:在lfence指令前的读操作当必须在lfence指令后的读操作前完成。
c) mfence:在mfence指令前的读写操作当必须在mfence指令后的读写操作前完成。
这种机制不太适用于所有CPU,所以目前不怎么采用了。
- locc前缀指令
IntelCPU lock前缀汇编指令保证有序性。Lock前缀指令几乎适用于所有CPU。
它的原子指令,如X86的Intel上,local addl XX指令是一个Full Barraier,会锁住内存子系统来确保执行顺序,甚至跨多个CPU。SoftwareLocks通常使用了内存屏障或者原子指令,来实现变量可见性和保持程序顺序。
上面看上去有点难懂,大家这么理解就行:
这个指令最早的时候,其实人家用的是一个叫做总线加锁机制。目前应该已经没有人来用了,他大概的意思是说,某个cpu如果要读一个数据,会通过一个总线,对这个数据加一个锁,其他的cpu就没法通过总线去读和写这个数据了,只有当这个cpu修改完了以后,其他cpu可以读到最新的数据。
但是由于这样多线程下会造成串行化,性能低,后来结合lock前缀指令+总线嗅探机制+广为人知的MESI协议进行了优化。(这里如果说的不准确,大家可以提出来)。
所以我们来具体研究下MESI到底通过哪些指令来实现,MESI的机制流程有时如何的。
MESI协议
缓存一致性协议有很多,比如除了MESI之外的缓存一致性协议还有MSI、MOSI、Synapse Firefly Dragon等等。
这里用的最多的就是MESI这个协议。
什么是MESI协议?
MESI协议规定:对一个共享变量的读操作可以是多个处理器并发执行的,但是如果是对一个共享变量的写操作,只有一个处理器可以执行,其实也会通过排他锁的机制保证就一个处理器能写。
要想理解这个协议需要具备两个前提:
-
熟悉MESI的4个指令
-
熟悉CUP结构和缓存行的数据结构
首先先来了解下缓存行的概念:
缓存行默认是64字节Byte,(程序局部性原理,当读取一条数据的时候,也会读取它附近的元素,很大可能会用到)经过工业界实践,可以充分发挥总线CPU针脚等一次性读取数据的能力,提高效率。
一般情况,缓存行的基本单位是一个64字节的数据,用于在L1、L2、L3、高速缓存Cache间传输数据。
处理器高速缓存的底层数据结构实际是一个拉链散列表的结构,就是有很多个bucket,每个bucket挂了很多的cache entry,每个cache entry由三个部分组成:tag、cache line和flag,其中的cache line就是缓存的数据。
tag指向了这个缓存数据在主内存中的数据的地址,flag标识了缓存行的状态,另外要注意的一点是,cache line中可以包含多个变量的值。
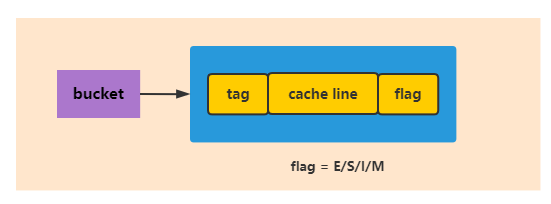
接着再来了解下MESI的4个指令:
MESI协议规定了一组消息,就说各个处理器在操作内存数据的时候,都会往总线发送消息,而且各个处理器还会不停的从总线嗅探最新的消息,通过这个总线的消息传递来保证各个处理器的协作。
之前说过那个cache entry的flag代表了缓存数据的状态,MESI协议中划分为:
(1)invalid:无效的,标记为I,这个意思就是当前cache entry无效,里面的数据不能使用
(2)shared:共享的,标记为S,这个意思是当前cache entry有效,而且里面的数据在各个处理器中都有各自的副本,但是这些副本的值跟主内存的值是一样的,各个处理器就是并发的在读而已
(3)exclusive:独占的,标记为E,这个意思就是当前处理器对这个数据独占了,只有他可以有这个副本,其他的处理器都不能包含这个副本
(4)modified:修改过的,标记为M,只能有一个处理器对共享数据更新,所以只有更新数据的处理器的cache entry,才是exclusive状态,表明当前线程更新了这个数据,这个副本的数据跟主内存是不一样的
到底底层是如何实现这套MESI的机制,通过哪些指令,这个指令干了什么事情,才能保证说,我刚才说的那种效果,修改本地缓存,立马刷主存,其他cpu本地缓存立马工期,重新从主存加载。
下面来详细的图解MESI协议的工作原理:
读I->S
处理器0读取某个变量的数据时,首先会根据index、tag和offset从高速缓存的拉链散列表读取数据,如果发现状态为I,也就是无效的,此时就会发送read消息到总线
接着主内存会返回对应的数据给处理器0,处理器0就会把数据放到高速缓存里,同时cache entry的flag状态是S。如下图所示:
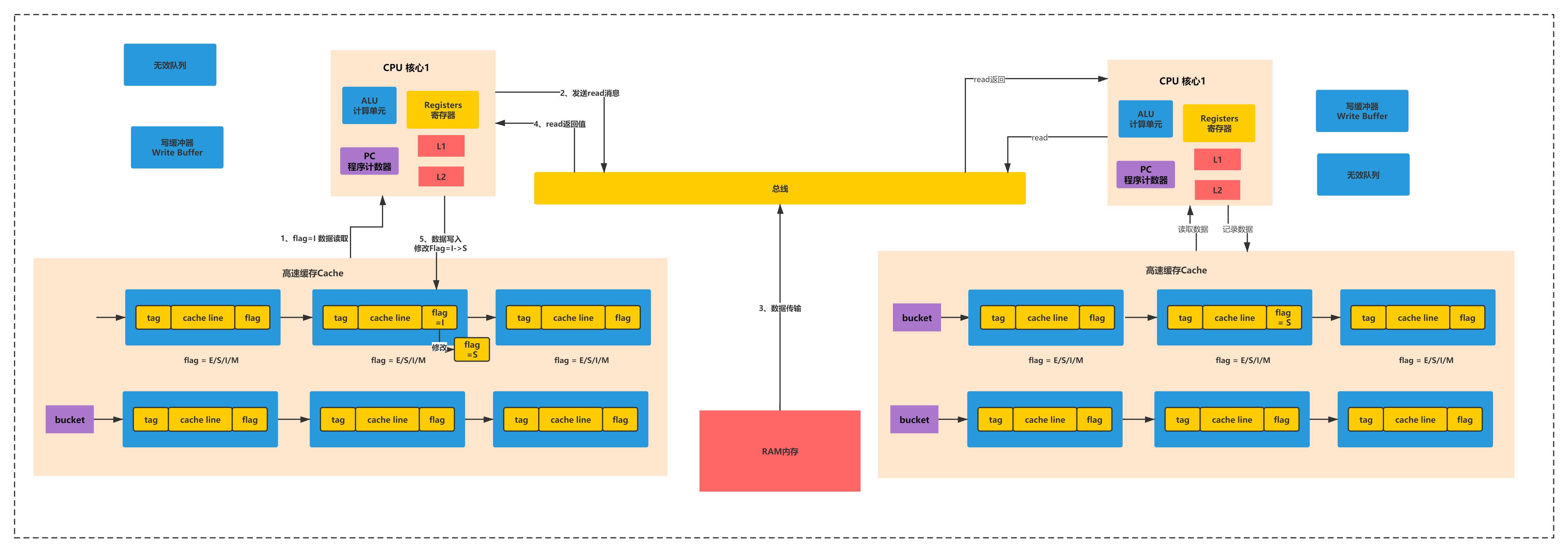
CPU1:S->I->I-ack
在处理器0对一个数据进行更新的时候,如果数据状态是S,则此时就需要发送一个invalidate消息到总线,尝试让其他的处理器的高速缓存的cache entry全部变为I,以获得数据的独占锁。
其他的处理器1会从总线嗅探到invalidate消息,此时就会把自己的cache entry设置为I,也就是过期掉自己本地的缓存,然后就是返回invalidate ack消息到总线,传递回处理器0,处理器0必须收到所有处理器返回的ack消息
CPU0:S->I-ack->E->M
接着处理器0就会将cache entry先设置为E,独占这条数据,在独占期间,别的处理器就不能修改数据了,因为别的处理器此时发出invalidate消息,这个处理器0是不会返回invalidate ack消息的,除非他先修改完再说
接着处理器0就是修改这条数据,接着将数据设置为M,也有可能是把数据此时强制写回到主内存中,具体看底层硬件实现
然后其他处理器此时这条数据的状态都是I了,那如果要读的话,全部都需要重新发送read消息,从主内存(或者是其他处理器)来加载,这个具体怎么实现要看底层的硬件了,都有可能的。
上述过程如下图所示:
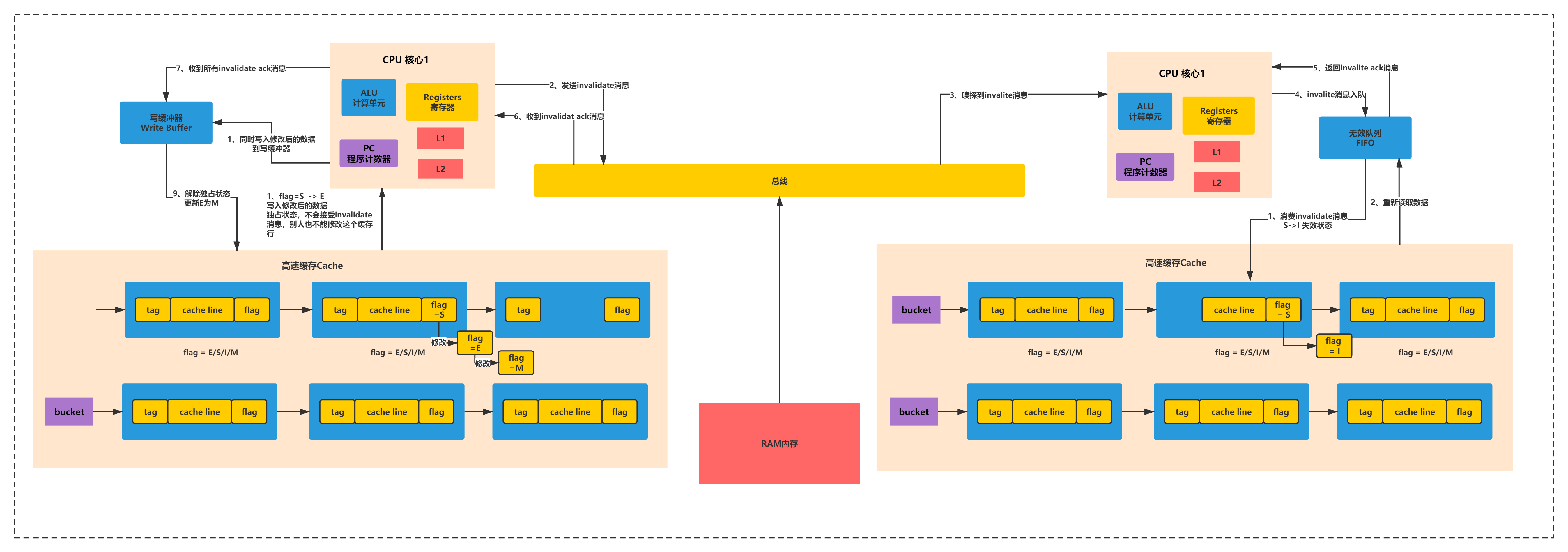
这套机制其实就是缓存一致性在硬件缓存模型下的完整的执行原理。
小结
到这里我们从三个层面,Java代码和字节码->JVM层->CPU硬件原理层面,剖析了Volatile底层原理,相信大家对它的可见性、有序性深刻的理解。
这一节涉及的知识特别多,也特别烧脑,大家理解了它的原理之后,更重要的是记住它的使用场景。我给大家总结如下:
原理:
一句话简单概括volatile的原理:就是刷新主内存,强制过期其他线程的工作内存。你可以在不同层面解释:
在java代码层面
场景:
1、 多个线程对同一个变量有读有写的时候
2、 多个线程需要保证有序性和可见性的时候
除了DCL单例,还有线程的优雅关闭这些场景,大家可以在评论去发表自己遇见过的场景。
-
JAVA语音识别项目资料的收集与应用11-26
-
Java语音识别项目资料:入门级教程与实战指南11-26
-
SpringAI:Java 开发的智能新利器11-26
-
Java云原生资料:新手入门教程与实战指南11-26
-
JAVA云原生资料入门教程11-26
-
Mybatis官方生成器资料详解与应用教程11-26
-
Mybatis一级缓存资料详解与实战教程11-26
-
Mybatis一级缓存资料详解:新手快速入门11-26
-
SpringBoot3+JDK17搭建后端资料详尽教程11-26
-
Springboot单体架构搭建资料:新手入门教程11-26
-
Springboot单体架构搭建资料详解与实战教程11-26
-
Springboot框架资料:新手入门教程11-26
-
Springboot企业级开发资料入门教程11-26
-
SpringBoot企业级开发资料详解与实战教程11-26
-
Springboot微服务资料:新手入门全攻略11-26
