Javascript
【JS 逆向百例】浏览器插件 Hook 实战,亚航加密参数分析


声明
本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
逆向目标
- 目标:亚航 airasia 航班状态查询,请求头 Authorization 参数
- 主页:
aHR0cHM6Ly93d3cuYWlyYXNpYS5jb20vZmxpZ2h0c3RhdHVzLw== - 接口:
aHR0cHM6Ly9rLmFwaWFpcmFzaWEuY29tL2ZsaWdodHN0YXR1cy9zdGF0dXMvb2QvdjMv - 逆向参数:
- Request Headers:
authorization: Bearer eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI......
- Request Headers:
逆向过程
抓包分析
来到航班状态查询页面,随便输入出发地和目的地,点击查找航班,例如查询澳门到吉隆坡的航班,MFM 和 KUL 分别是澳门和吉隆坡国际机场的代码,查询接口由最基本的 URL + 机场代码 + 日期组成,类似于:https://xxxxxxxxxx/MFM/KUL/28/09/2021 ,其中请求头 Request Headers 里有个 authorization 参数,通过观察发现,不管是清除 cookie 还是更换浏览器,此参数的值是一直不变的,经过测试,直接复制该参数到代码里也是可行的,但本次我们的目的是通过编写浏览器插件来 Hook 这个参数,找到它生成的地方。
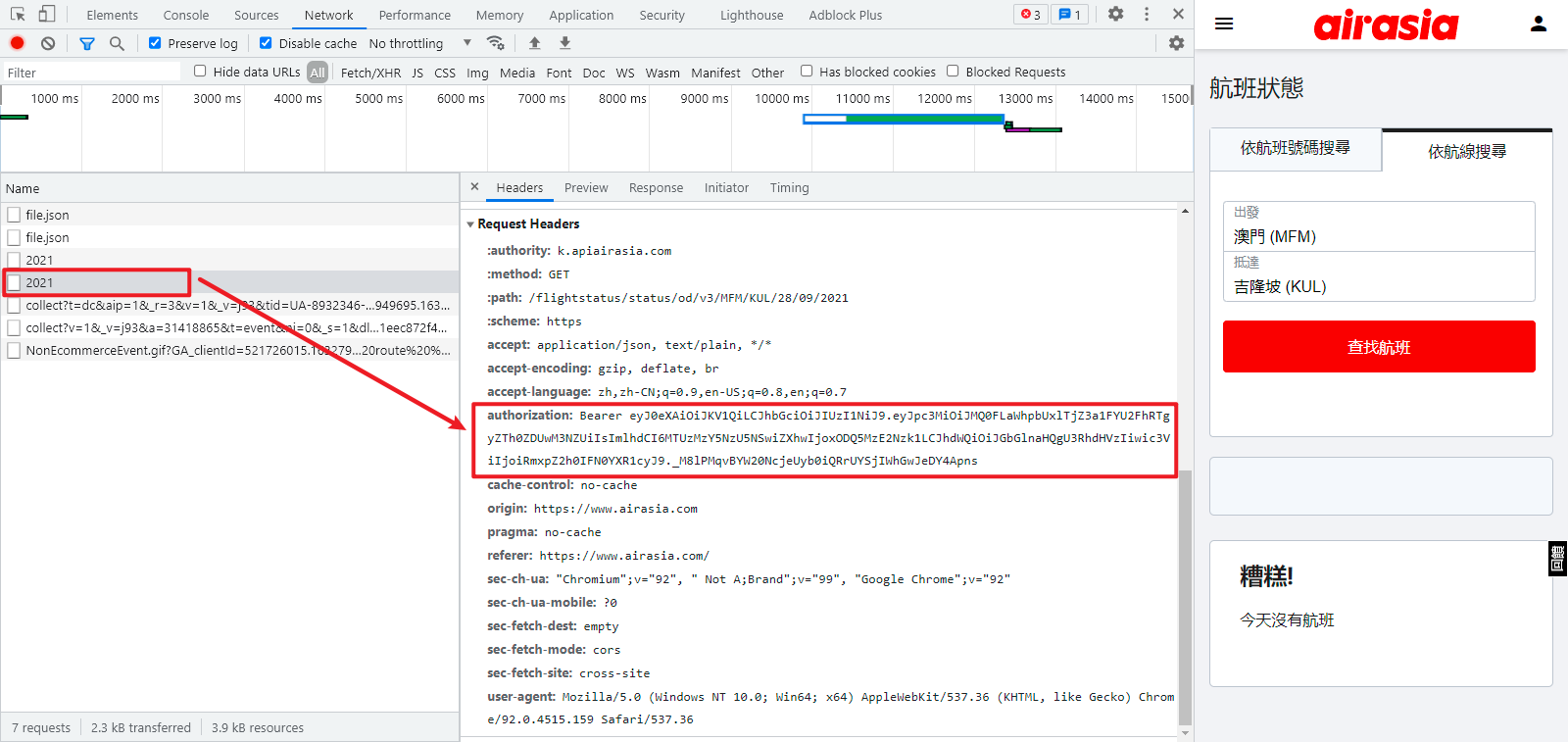
浏览器插件 Hook
浏览器插件事实上叫做浏览器扩展(extensions),它能够增强浏览器功能,比如屏蔽广告、管理浏览器代理、更改浏览器外观等。
既然是通过编写浏览器插件的方式进行 Hook,那么首先我们肯定是要简单了解一下如何编写浏览器插件了,编写浏览器插件也有对应的规范,在以前,不同浏览器的插件编写方式都不太一样,到现在基本上都和 Google Chrome 插件的编写方式一样了,Google Chrome 的插件除了能运行在 Chrome 浏览器之外,还可以运行在所有 webkit 内核的国产浏览器,比如 360 极速浏览器、360 安全浏览器、搜狗浏览器、QQ 浏览器等等,另外,Firefox 火狐浏览器也有很多人使用,火狐浏览器插件的开发方式变化了很多次,但是从 2017 年 11 月底开始,插件必须使用 WebExtensions APIs 进行构建,其目的也是为了和其他浏览器统一,一般的 Google Chrome 插件也能直接运行在火狐浏览器上,但是火狐浏览器插件需要要经过 Mozilla 签名后才能安装,否则只能临时调试,重启浏览器后插件就没有了,这一点较为不便。
一个浏览器插件的开发说简单也简单,说复杂也复杂,不过对于我们做爬虫逆向的开发人员来说,我们主要是利用插件对代码进行 Hook,我们只需要知道一个插件是由一个 manifest.json 和一个 JavaScript 脚本文件组成的就够了,接下来 K 哥以本案例中请求头的 authorization 参数为例,带领大家开发一个 Hook 插件。当然,如果你想深入研究浏览器插件的开发,可以参考 Google Chrome 扩展文档和 Firefox Browser 扩展文档。
按照 Google Chrome 插件的开发规范,首先新建一个文件夹,该文件夹下包含一个 manifest.json 文件和一个 JS Hook 脚本,当然,如果你想为你的插件配置一个图标的话,也可以将图标放到该文件夹下,图标格式官方建议 PNG,也可以是 WebKit 支持的任何格式,包括 BMP、GIF、ICO 和 JPEG 等,注意:manifest.json 文件名不可更改!正常的插件目录类似如下结构:
JavaScript Hook
├─ manifest.json // 配置文件,文件名不可更改
├─ icons.png // 图标
└─ javascript_hook.js // Hook 脚本,文件名顺便取
manifest.json
manifest.json 是一个 Chrome 插件中最重要也是必不可少的文件,它用来配置所有和插件相关的配置,必须放在根目录。其中,manifest_version、name、version 这 3 个参数是必不可少的,本案例中,manifest.json 文件配置如下:(完整配置参考 Chrome manifest file format)
{
"name": "JavaScript Hook", // 插件名称
"version": "1.0", // 插件版本
"description": "JavaScript Hook", // 插件描述
"manifest_version": 2, // 清单版本,必须是2或者3
"icons": { // 插件图标
"16": "/icons.png", // 图标路径,插件图标不同尺寸也可以是同一张图
"48": "/icons.png",
"128": "/icons.png"
},
"content_scripts": [{
"matches": ["<all_urls>"], // 匹配所有地址
"js": ["javascript_hook.js"], // 注入的代码文件名和路径,如果有多个,则依次注入
"all_frames": true, // 允许将内容脚本嵌入页面的所有框架中
"permissions": ["tabs"], // 权限申请,tabs 表示标签
"run_at": "document_start" // 代码注入的时间
}]
}
这里需要注意以下几点:
- manifest_version:配置清单版本,目前支持 2 和 3,2 将会在将来被逐步淘汰,将来也可能推出 4 或者更高版本。可以在官网查看 Manifest V2 和 Manifest V3 的区别,3 有更高的隐私安全要求,这里推荐使用 2。
- content_scripts:Chrome 插件中向页面注入脚本的一种形式,包括地址匹配(支持正则表达式),要注入的 JS、CSS 脚本,代码注入的时间(建议 document_start,网页开始加载时就注入)等。
javascript_hook.js
javascript_hook.js 文件里就是 Hook 代码了:
var hook = function () {
var org = window.XMLHttpRequest.prototype.setRequestHeader;
window.XMLHttpRequest.prototype.setRequestHeader = function (key, value) {
if (key == 'Authorization') {
debugger;
}
return org.apply(this, arguments);
}
}
var script = document.createElement('script');
script.textContent = '(' + hook + ')()';
(document.head || document.documentElement).appendChild(script);
script.parentNode.removeChild(script);
XMLHttpRequest.setRequestHeader() 是设置 HTTP 请求头部的方法,定义了一个变量 org 来保存原始方法,window.XMLHttpRequest.prototype.setRequestHeader 这里有个原型对象 prototype,所有的 JavaScript 对象都会从一个 prototype 原型对象中继承属性和方法,具体可以参考菜鸟教程 JavaScript prototype 的介绍。一旦程序在设置请求头中的 Authorization 时,就会进入我们的 Hook 代码,通过 debugger 断下,最后依然将所有参数返回给 org,也就是 XMLHttpRequest.setRequestHeader() 这个原始方法,保证数据正常传输。然后创建 script 标签,script 标签内容是将 Hook 函数变成 IIFE 自执行函数,然后将其插入到网页中。
到此我们浏览器插件就编写完成了,接下来介绍如何在 Google Chrome 和 Firefox Browser 中使用。
Google Chrome
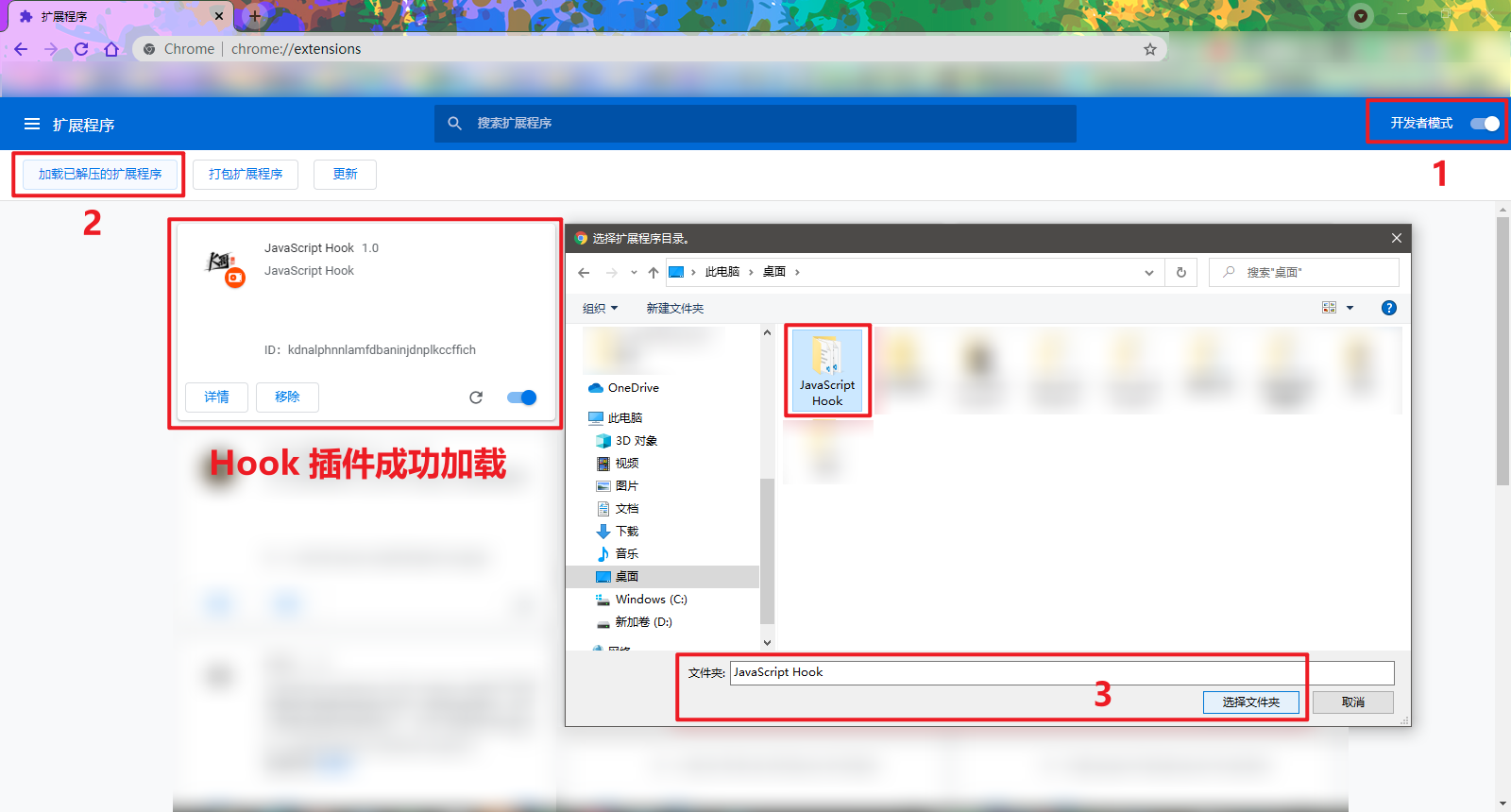
在浏览器地址栏输入 chrome://extensions 或者依次点击右上角【自定义及控制 Google Chrome】—>【更多工具】—>【扩展程序】,进入扩展程序页面,再依次选择开启【开发者模式】—>【加载已解压的扩展程序】,选择整个 Hook 插件文件夹(文件夹里应包含 manifest.json、javascript_hook.js 和图标文件),如下图所示:
Firefox Browser
火狐浏览器不能直接安装未经过 Mozilla 签名认证的插件,只能通过调试附加组件的方式进行安装。插件的格式必须是 .xpi、.jar、.zip 的,所以需要我们将 manifest.json、javascript_hook.js 和图标文件一起打包,打包需要注意不要包含顶层目录,直接全选右键压缩即可,否则在安装时会提示 does not contain a valid manifest。
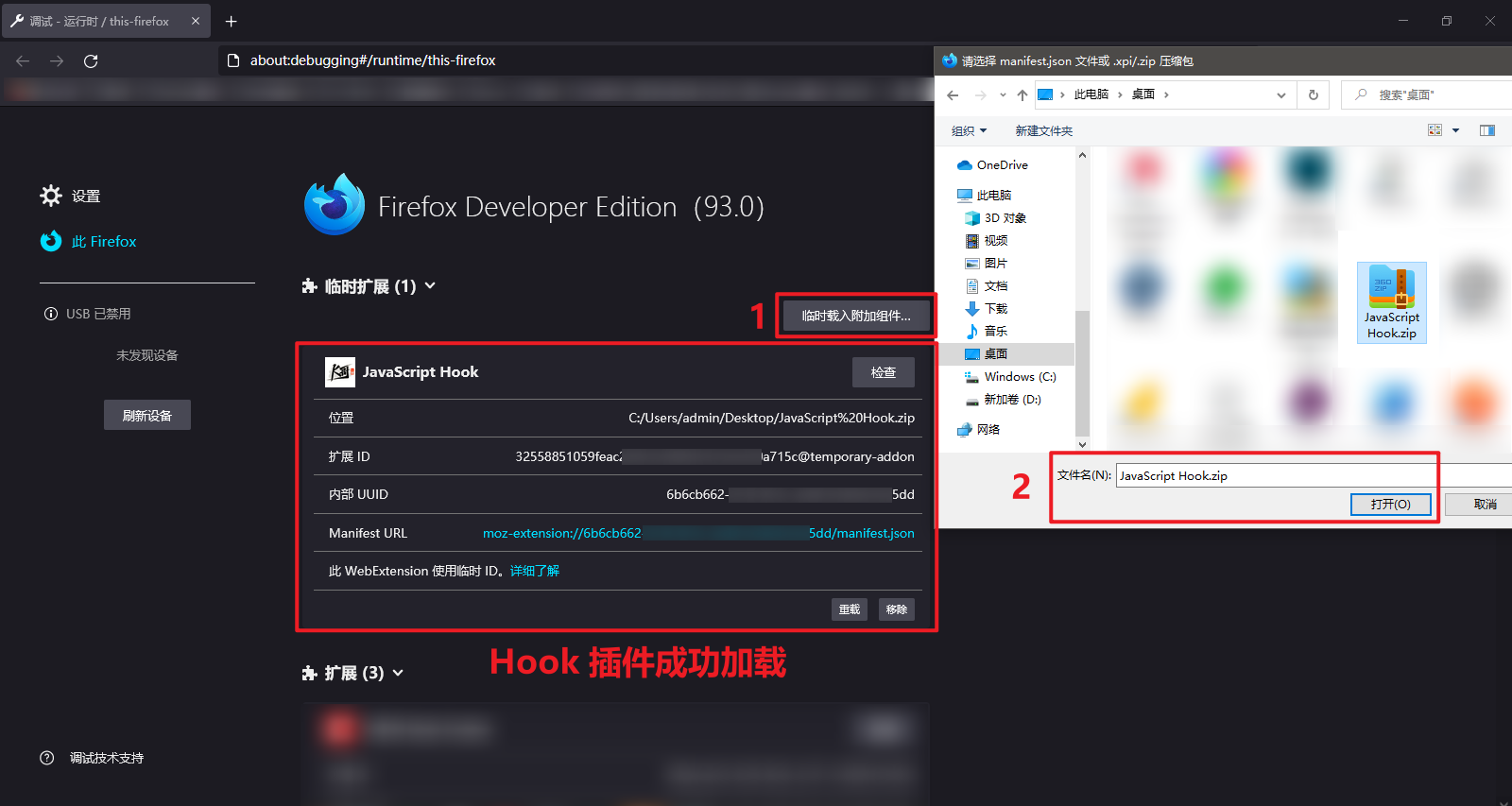
在浏览器地址栏输入 about:addons 或者依次点击右上角【打开应用程序菜单】—>【扩展和主题】,也可以直接使用快捷键 Ctrl + Shift + A 来到扩展页面,在管理您的扩展目录旁有个设置按钮,点击选择【调试附加组件】,在临时扩展项目下,选择【临时载入附加组件】,选择 Hook 插件的压缩包即可。
也可以直接在浏览器地址栏输入 about:debugging#/runtime/this-firefox,直接进入到临时扩展页面,如下图所示:
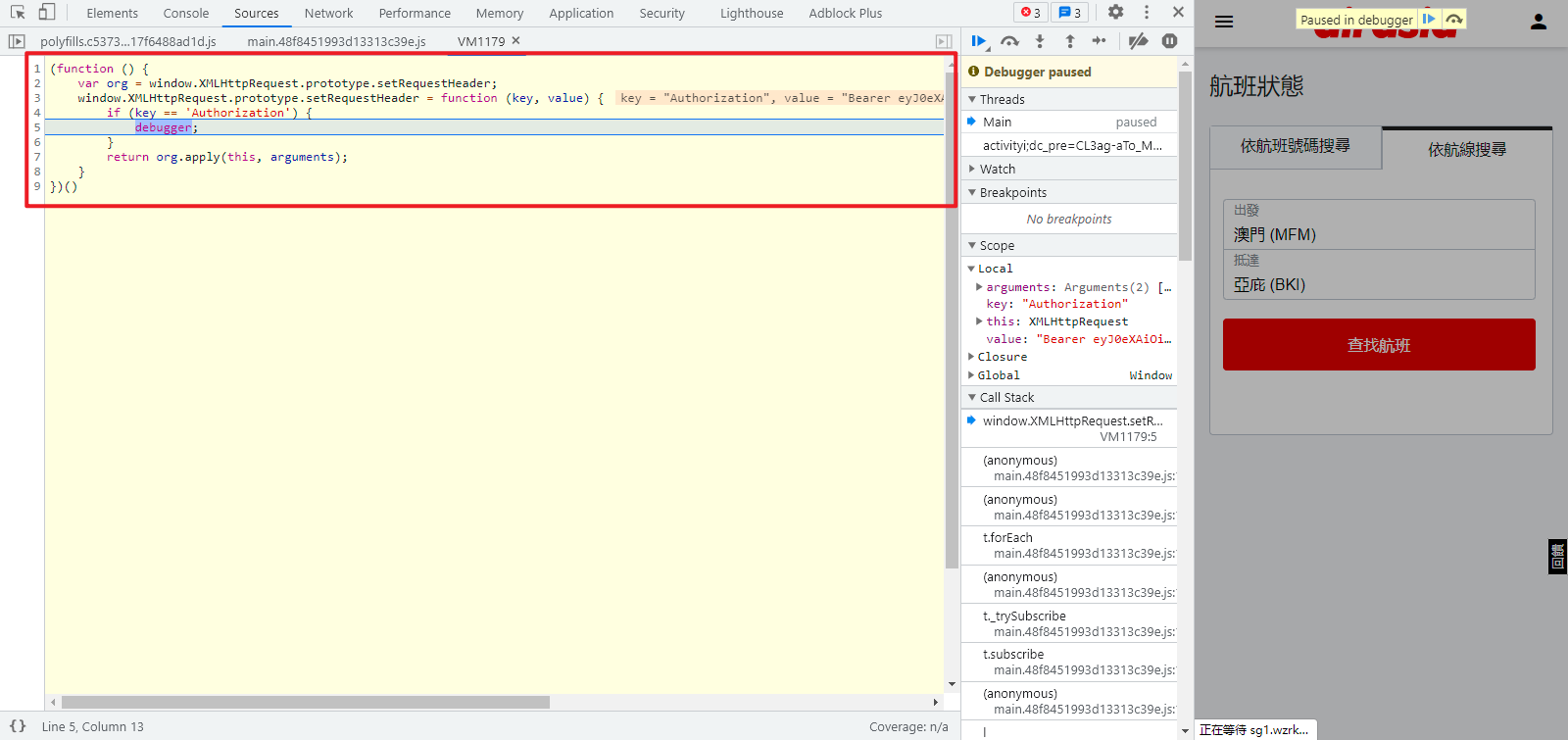
自此,浏览器 Hook 插件我们就开发安装完毕了,重新来到航班查询页面,随便输入出发地和目的地,点击查找航班,就可以看到此时已经成功断下:
TamperMonkey 插件 Hook
前面我们已经介绍了如何自己编写一个浏览器插件,但是不同浏览器插件的编写始终是大同小异的,有可能你编写的某个插件在其他浏览器上运行不了,而 TamperMonkey 就可以帮助我们解决这个问题,TamperMonkey 俗称油猴插件,它本身就是一个浏览器扩展,是最为流行的用户脚本管理器,基本上支持所有带有扩展功能的浏览器,实现了脚本的一次编写,所有平台都能运行,用户可以在 GreasyFork、OpenUserJS 等平台直接获取别人发布的脚本,功能众多且强大,同样的,我们也可以利用 TamperMonkey 来实现 Hook。
TamperMonkey 可以直接在各大浏览器扩展商店里面安装,也可以去 TamperMonkey 官网进行安装,安装过程这里不再赘述。
安装完成后点击图标,添加新脚本,或者点击管理面板,再点击加号新建脚本,写入以下 Hook 代码:
// ==UserScript==
// @name JavaScript Hook
// @namespace http://tampermonkey.net/
// @version 0.1
// @description JavaScript Hook 脚本
// @author K哥爬虫
// @include *://*airasia.com/*
// @icon https://profile.csdnimg.cn/1/B/8/3_kdl_csdn
// @grant none
// @run-at document-start
// ==/UserScript==
(function () {
'use strict';
var org = window.XMLHttpRequest.prototype.setRequestHeader;
window.XMLHttpRequest.prototype.setRequestHeader = function (key, value) {
if (key == 'Authorization') {
debugger;
}
return org.apply(this, arguments);
};
})();
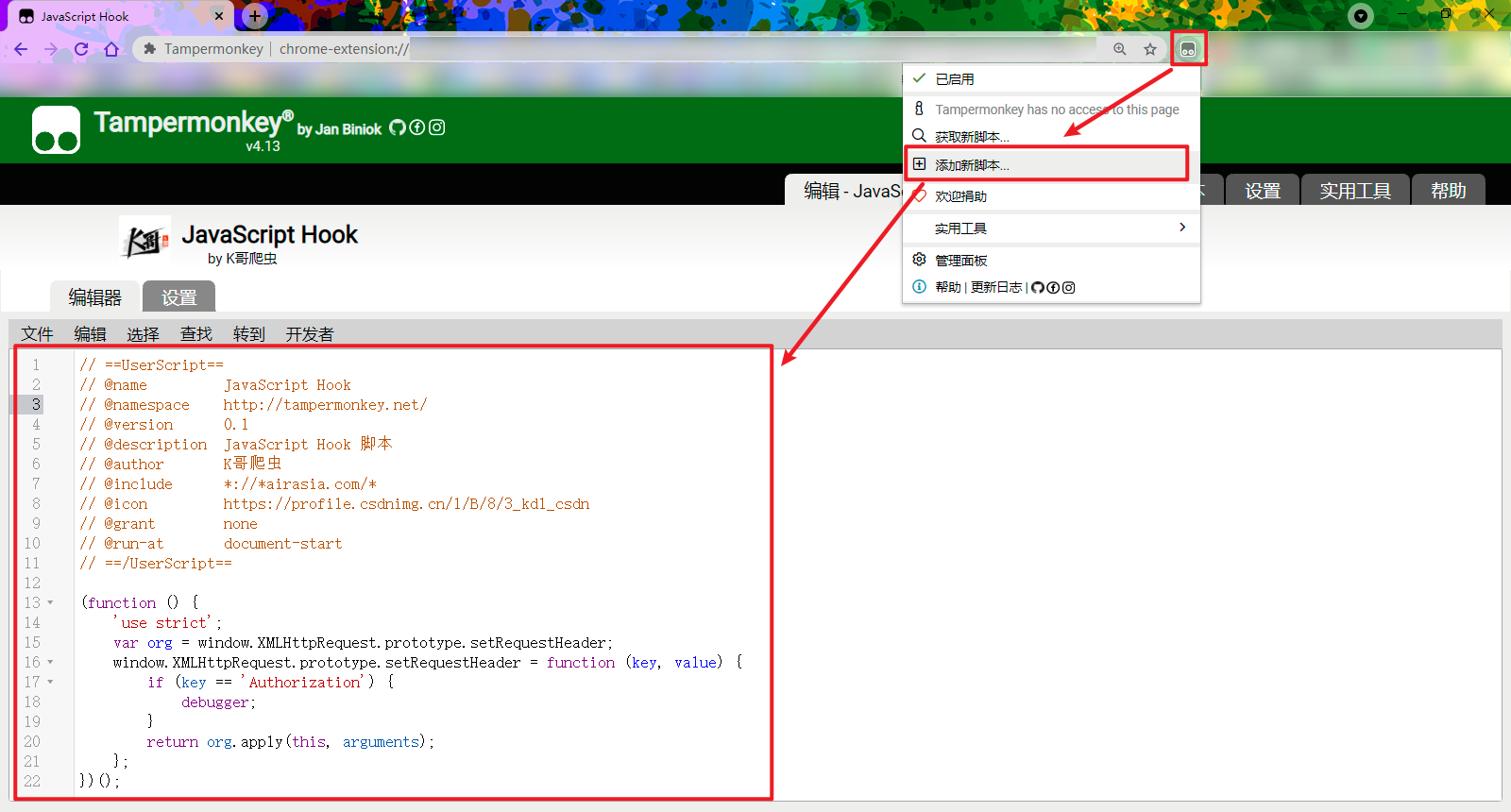
整个代码 JavaScript 部分是个 IIFE 立即执行函数,具体含义就不解释了,前面浏览器插件开发时已经讲过,重要的是上面几行注释,千万不要以为这只是简单的注释,可有可无,在 TamperMonkey 中,可以将这部分视为基本的配置选项,各项都有其具体含义,完整的配置选项参考 TamperMonkey 官方文档,常见配置项如下表所示(其中需要特别注意 @match、@include 和 @run-at 选项):
| 选项 | 含义 |
|---|---|
| @name | 脚本的名称 |
| @namespace | 命名空间,用来区分相同名称的脚本,一般写作者名字或者网址就可以 |
| @version | 脚本版本,油猴脚本的更新会读取这个版本号 |
| @description | 描述这个脚本是干什么用的 |
| @author | 编写这个脚本的作者的名字 |
@match |
从字符串的起始位置匹配正则表达式,只有匹配的网址才会执行对应的脚本,例如 * 匹配所有,https://www.baidu.com/* 匹配百度等,可以参考 Python re 模块里面的 re.match() 方法,允许多个实例 |
@include |
和 @match 类似,只有匹配的网址才会执行对应的脚本,但是 @include 不会从字符串起始位置匹配,例如 *://*baidu.com/* 匹配百度,具体区别可以参考 TamperMonkey 官方文档 |
| @icon | 脚本的 icon 图标 |
| @grant | 指定脚本运行所需权限,如果脚本拥有相应的权限,就可以调用油猴扩展提供的 API 与浏览器进行交互。如果设置为 none 的话,则不使用沙箱环境,脚本会直接运行在网页的环境中,这时候无法使用大部分油猴扩展的 API。如果不指定的话,油猴会默认添加几个最常用的 API |
| @require | 如果脚本依赖其他 JS 库的话,可以使用 require 指令导入,在运行脚本之前先加载其它库 |
@run-at |
脚本注入时机,该选项是能不能 hook 到的关键,有五个值可选:document-start:网页开始时;document-body:body出现时;document-end:载入时或者之后执行;document-idle:载入完成后执行,默认选项;context-menu:在浏览器上下文菜单中单击该脚本时,一般将其设置为 document-start |
重新来到航班查询页面,启用 TamperMonkey 脚本,如果配置正确的话,就可以看到我们编写的 Hook 脚本已开启,随便输入出发地和目的地,点击查找航班,就可以看到此时已经成功断下:
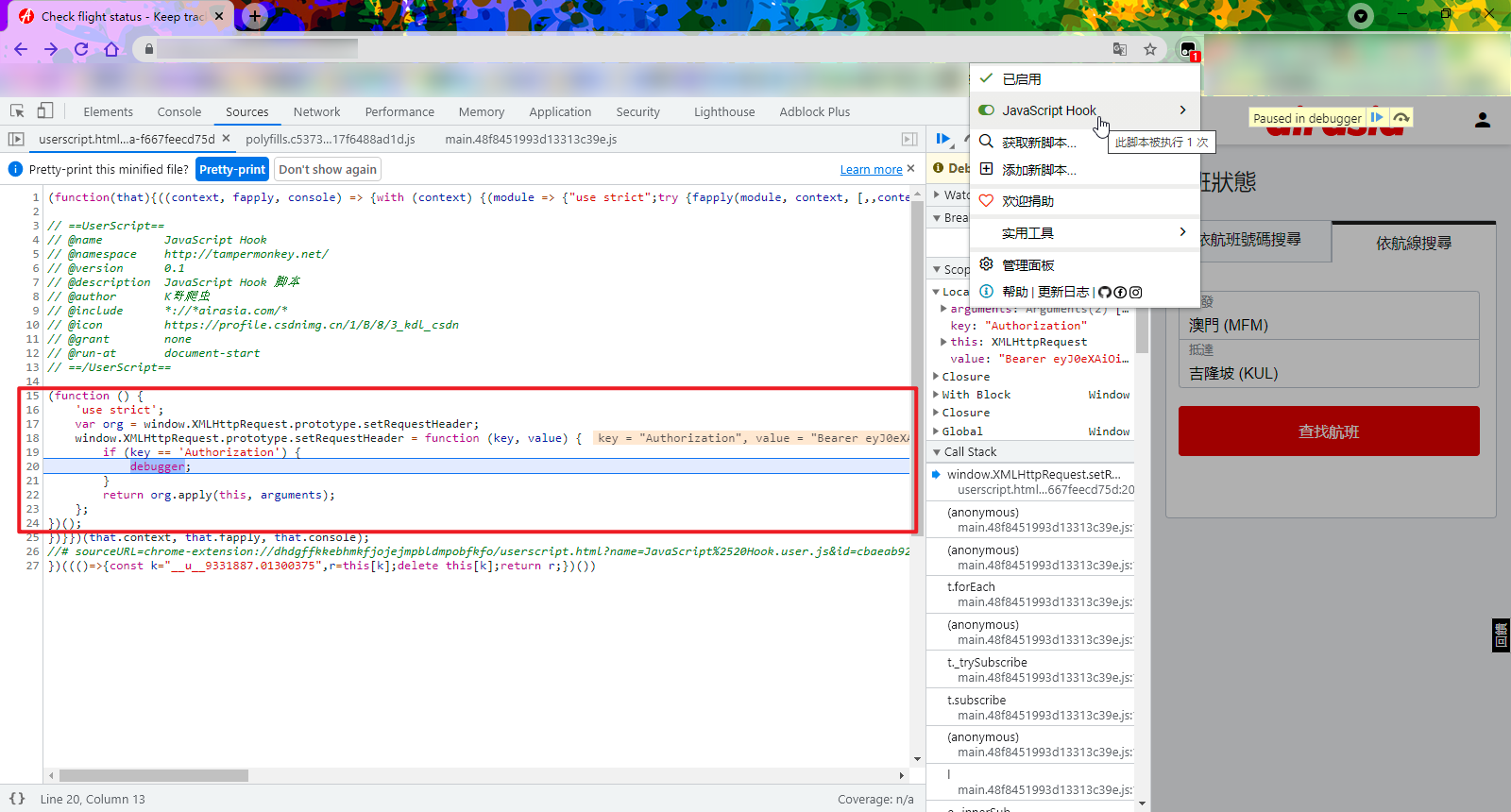
参数逆向
不管你是使用浏览器插件还是 TamperMonkey 进行 Hook,此时 Hook 到的是设置请求头 Authorization 的地方,也就是说 Authorization 的值是产生肯定经过了之前的某个函数或者方法,那么我们跟进开发者工具的 Call Stack 调用栈,就一定能够找到这个方法,跟调用栈是一个考验耐心的过程,花费时间也比较多。
通常情况下,我们是挨个函数查看其传递的参数有没有包含我们目标参数,如果上一个函数里没有而下一个函数里出现了,那么大概率加密过程就在这两个函数之间,进入上一个函数再进行单步调试,一般就能找到加密代码,在本案例中,我们跟到 t.getData 函数埋下断点进行单步调试,可以看到其实后面在反复调用 t.subscribe 和 t.call,之所以不在这两个函数处埋下断点,是因为循环过多不好调试,而且 t.getData 通过名称判断也比较可疑。
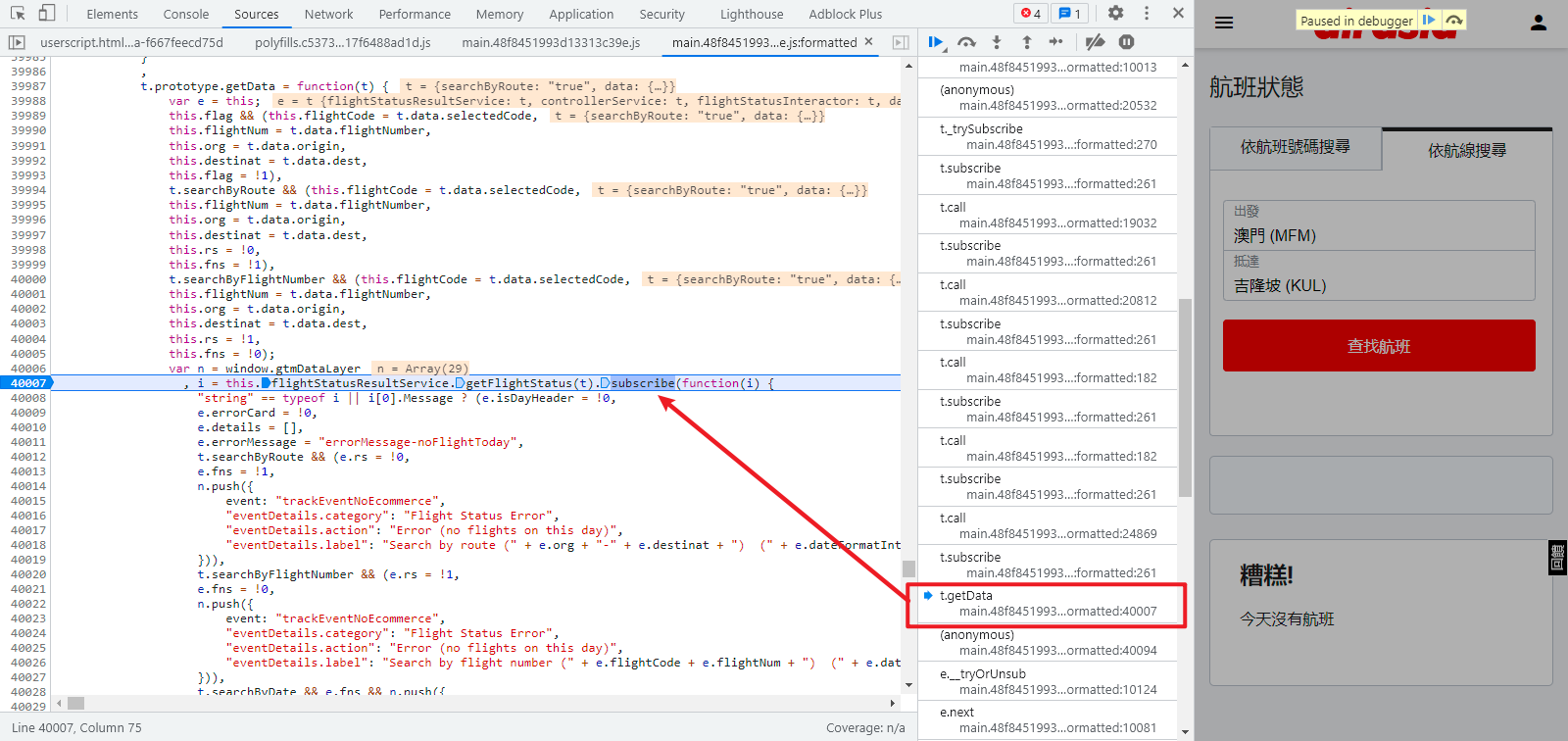
重新点击登陆,来到我们刚刚埋下断点的地方,F11 或者点击向下箭头,进入函数内部进行单步调试,调试大约 7 步后,来到一个 t.getHttpHeader 函数,可以看到 Authorization 的值就是 "Bearer " + r.accessToken,我们在控制台打印 r.accessToken 可以看到就是我们想要的值,如下图所示:
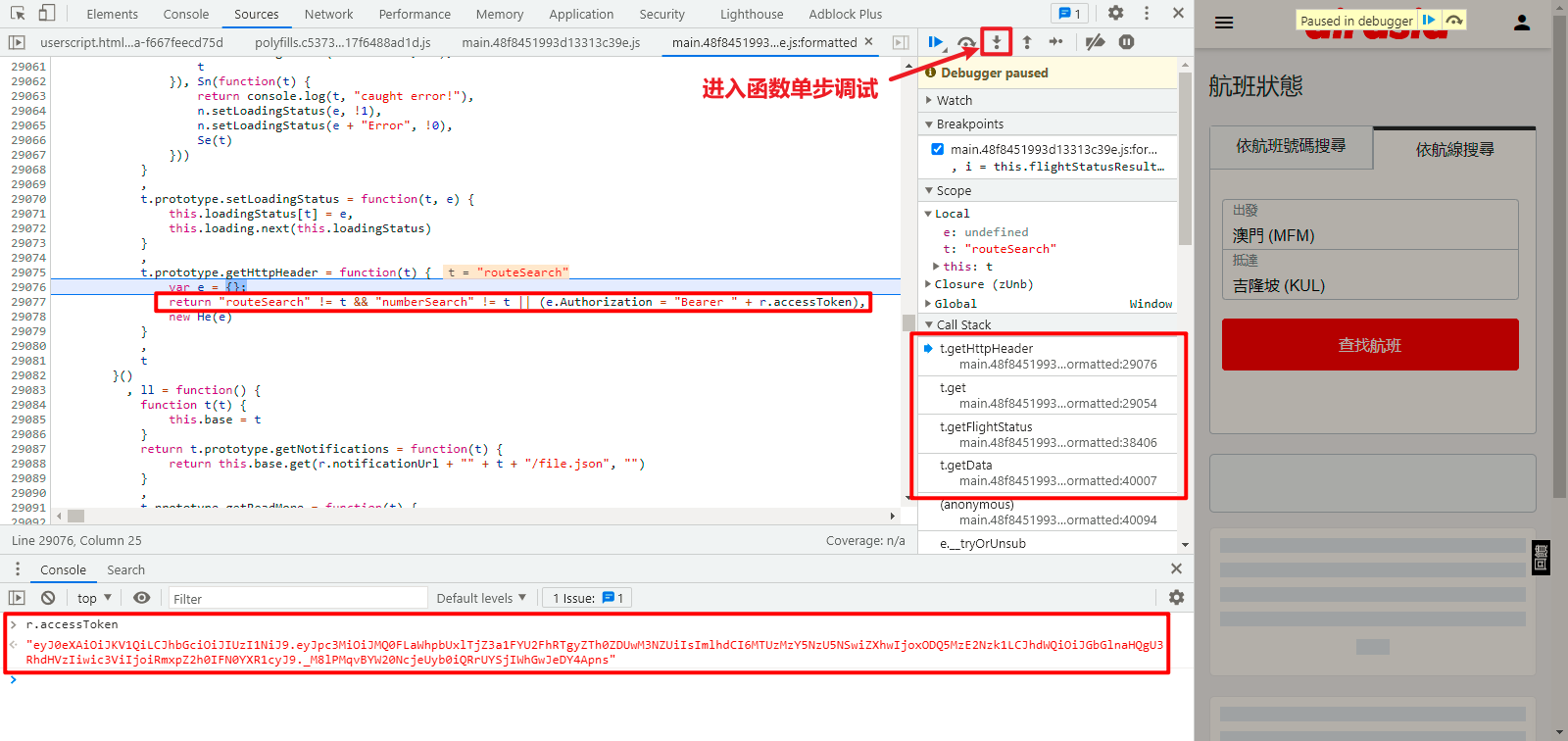
那么重点是这个 r.accessToken,如果你尝试直接往上找,你会发现找了很多行也没有找到,直接搜索关键字 accessToken,可以发现在 zUnb 对象里面是直接定义死了的,直接拿来用即可,如下图所示:
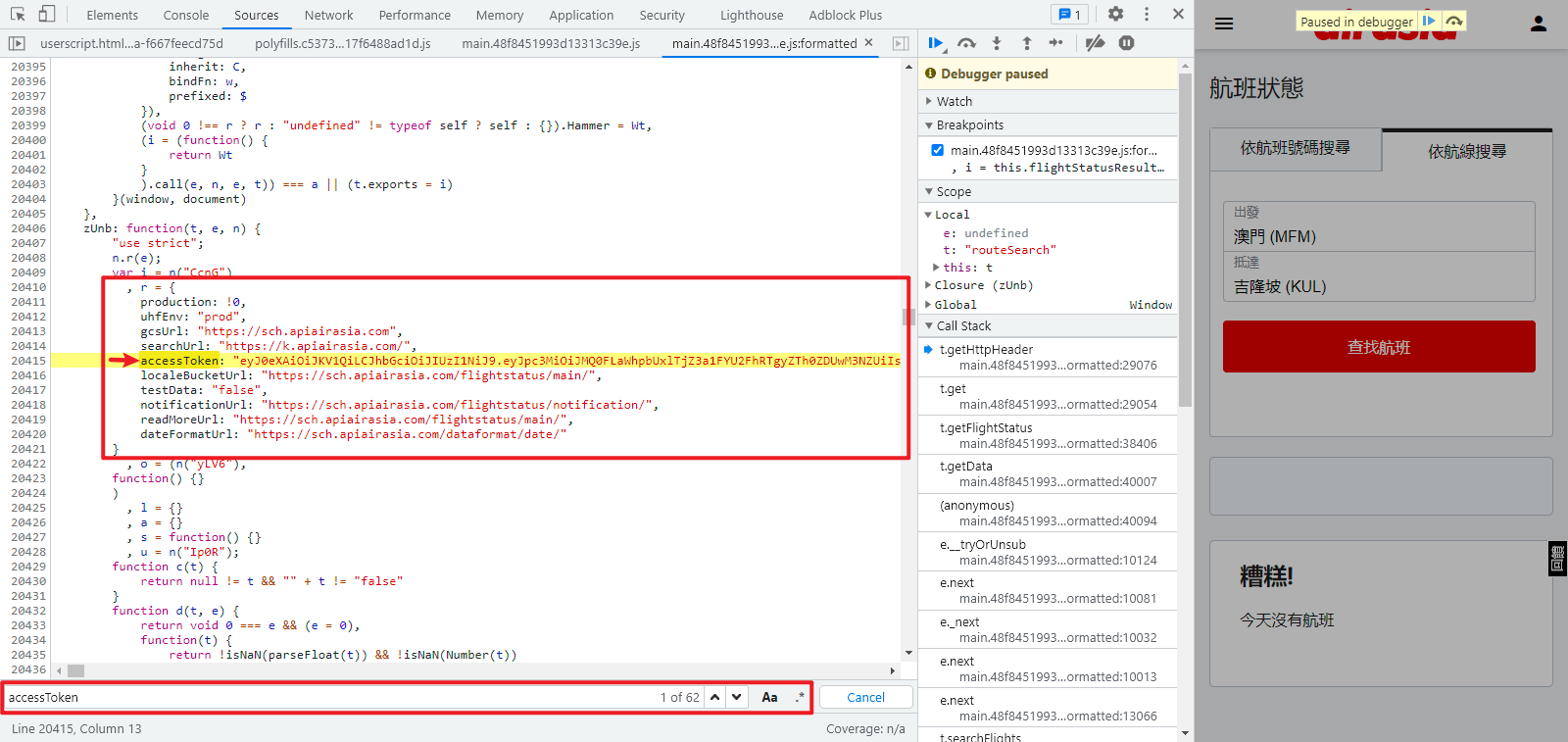
关于出发地、目的地的各个地方的代码,是通过 JSON 传递过来的,很容易找到,可根据实际需求灵活处理,如下图所示:
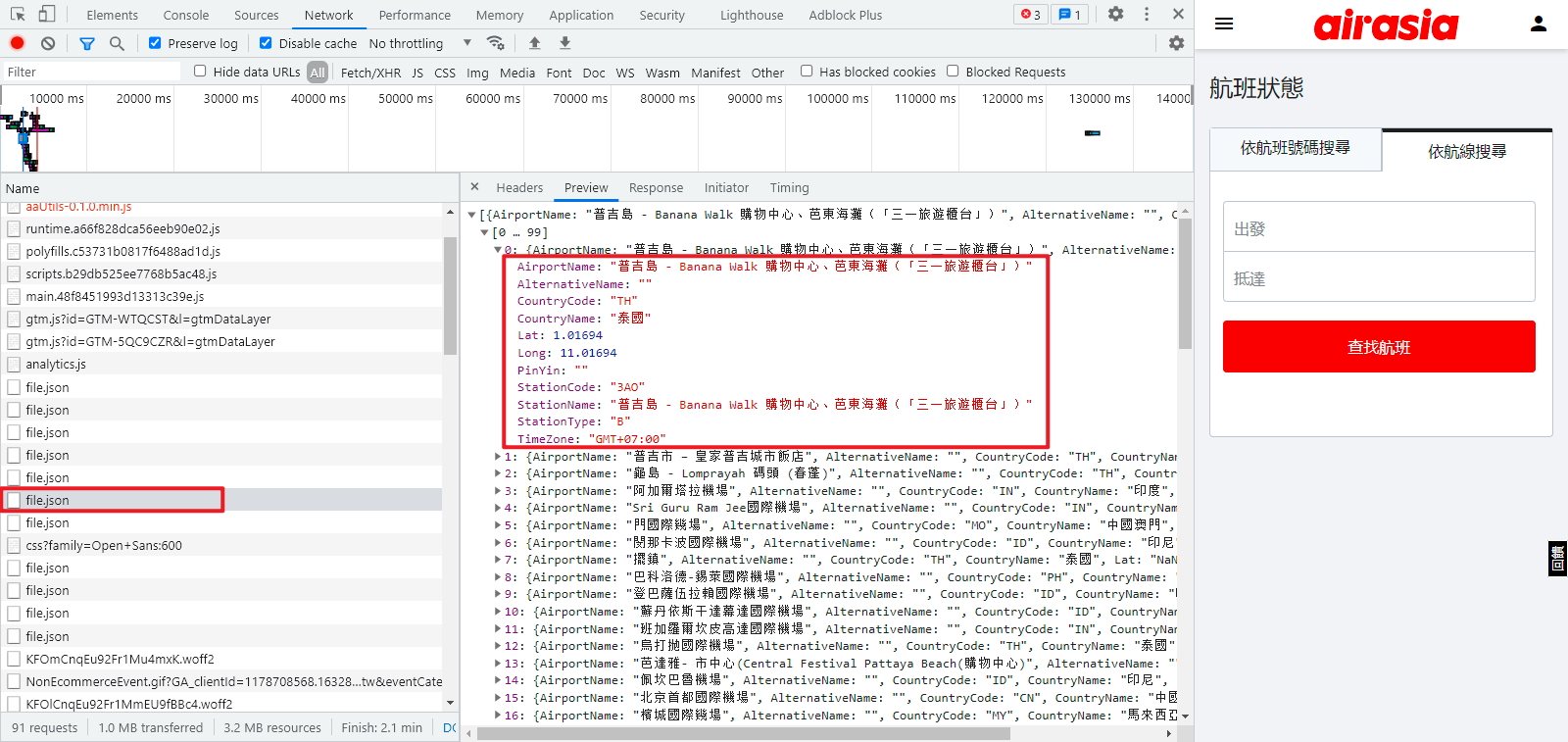
这个案例本身不难,直接搜索还能更快定位参数位置,但是本案例重点在于如何使用浏览器插件进行 Hook 操作,这对于某些无法经过搜索得到的参数,或者搜索结果太多难以定位的情况来说,是一个很好的解决方法。
完整代码
GitHub 关注 K 哥爬虫,持续分享爬虫相关代码!欢迎 star !https://github.com/kgepachong/
**以下只演示部分关键代码,不能直接运行!**完整代码仓库地址:https://github.com/kgepachong/crawler/
Python 示例代码
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import requests
status_url = '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
def get_flight_status(departure, destination, date):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'authorization': '脱敏处理,完整代码关注 GitHub:https://github.com/kgepachong/crawler'
}
complete_url = status_url + departure + '/' + destination + '/' + date
response = requests.get(url=complete_url, headers=headers)
print(response.text)
if __name__ == '__main__':
departure = input('请输入出发地代码:')
destination = input('请输入目的地代码:')
date = input('请输入日期(例如:29/09/2021):')
# departure = 'MFM'
# destination = 'KUL'
# date = '29/09/2021'
get_flight_status(departure, destination, date)
-
Vue CLI教程:新手入门与实践指南11-26
-
Vue3+Vite教程:新手入门到项目实践11-26
-
Vue3阿里系UI组件教程:新手入门指南11-26
-
Vue3的阿里系UI组件教程:简单易懂的入门指南11-26
-
Vue3公共组件教程:零基础入门到实战11-26
-
Vue3公共组件教程:入门与实践指南11-26
-
Vue3核心功能响应式变量教程:轻松入门与实践11-26
-
Vue3核心功能响应式变量教程:新手快速入门11-26
-
Vue3教程:新手入门与初级实践指南11-26
-
集成Ant Design Vue的图标项目实战11-26
-
集成Ant Design Vue图标项目实战11-26
-
Vue CLI多环境配置项目实战:新手入门教程11-25
-
Vue CLI项目实战:新手入门教程11-25
-
Vue3+Vite项目实战:新手入门教程11-25
-
Vue3阿里系UI组件项目实战入门教程11-25
