Java教程
SpringBoot成长记10:Bean实例化的流程和设计


之前我们已经分析SpringBoot在run方法时,它会执行的refresh()容器的操作。
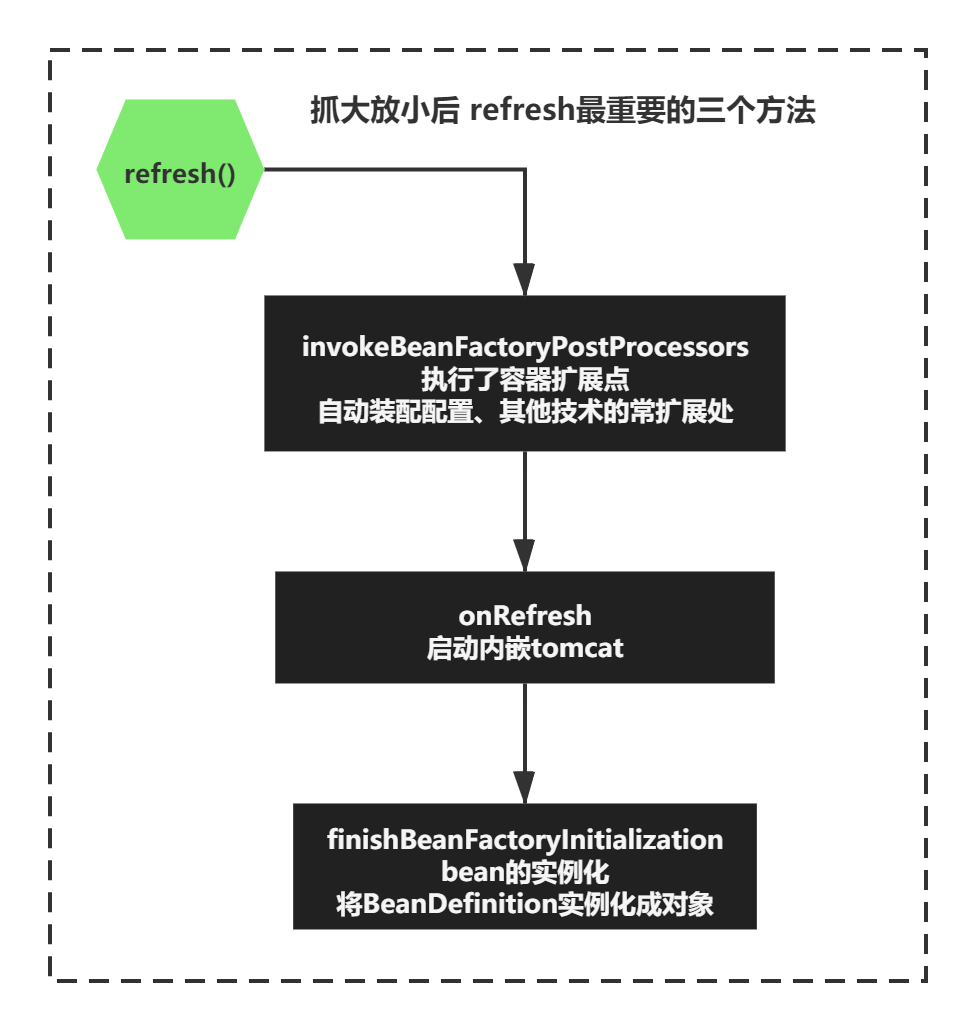
在SpringBoot中,refresh()有十几个方法,每个方法的大重要程度是不一样的,我们通过抓大放小的方式,分析处理上图3个核心逻辑。
并且已经研究完了invokeBeanFactoryPostProcessors和onRefresh的逻辑,分析它们的原理和设计思想。
之前主要分析的:
原理有对SpringBoot的自动装配配置如何做到的、第三方技术如何进行扩展的、tomcat如何启动的
设计思想有SpringBoot扩展接口设计、有对Tomcat组件的扩展设计、Spring容器抽象思想的设计、SpringBoot和第三方技术整合的扩展设计等等。
refresh()还有一个非常关键的操作,就是bean的实例化,今天我们就来看下refresh最后一个方法—finishBeanFactoryInitialization。
看看它如何执行Bean实例化的流程和设计的。
finishBeanFactoryInitialization之前和之后的操作概况
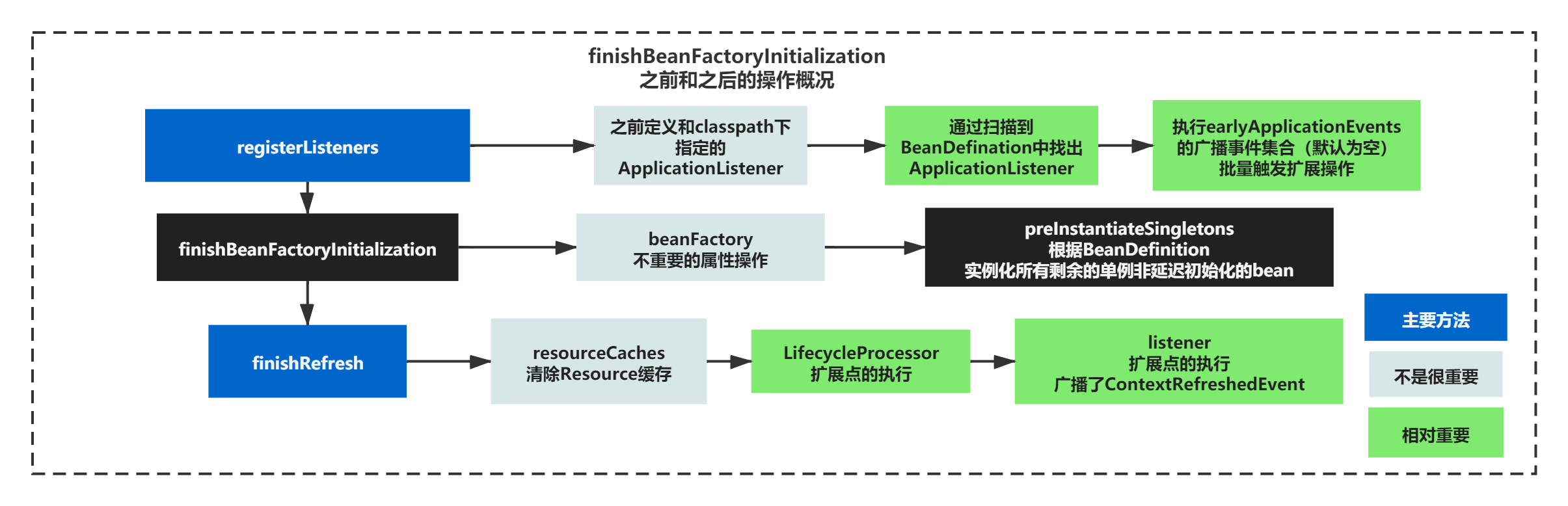
可以看到,bean的实例化前后,还是做了一些事情的,主要执行的是一些扩展点,比如listener的扩展点执行、LifycycleProcessor的执行。
这一节我们核心关系的是bean创建流程和设计,所以我们抓大放小,过就可以。直接来看下面创建bean吧。
preInstantiateSingletons方法的核心脉络
其实bean的实例化大家或多或少都知道一些。所以我不会特别详细的每一个方法都带大家看。
我们还是本着先脉络后细节,最后思考的思想来分析Bean的实例化,当你用这种方法分析玩后,和你之前分析对吧下有什么区别,可以感受下。
如果之后大家有诉求需要精读Bean实例化的逻辑,我之后可以考虑放在Spring成长记中为大家仔细带来Bean实例化的分析。
这里我们主要过下它的核心源码就可以了。
由于SpringBoot是为了更好的使用Spring,它是基于Spring的。如果你懂Spring实例化,这块其实非常好理解的。
让我们来看下吧!
finishBeanFactoryInitialization主要的代码如下所示:
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
// Initialize conversion service for this context.
if (beanFactory.containsBean(CONVERSION_SERVICE_BEAN_NAME) &&
beanFactory.isTypeMatch(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class)) {
beanFactory.setConversionService(
beanFactory.getBean(CONVERSION_SERVICE_BEAN_NAME, ConversionService.class));
}
// Register a default embedded value resolver if no bean post-processor
// (such as a PropertyPlaceholderConfigurer bean) registered any before:
// at this point, primarily for resolution in annotation attribute values.
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver(strVal -> getEnvironment().resolvePlaceholders(strVal));
}
// Initialize LoadTimeWeaverAware beans early to allow for registering their transformers early.
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
for (String weaverAwareName : weaverAwareNames) {
getBean(weaverAwareName);
}
// Stop using the temporary ClassLoader for type matching.
beanFactory.setTempClassLoader(null);
// Allow for caching all bean definition metadata, not expecting further changes.
beanFactory.freezeConfiguration();
// Instantiate all remaining (non-lazy-init) singletons.
beanFactory.preInstantiateSingletons();
}
这个方法的脉络其实比较清楚,其实最关键的只有一句话:
// Instantiate all remaining (non-lazy-init) singletons. beanFactory.preInstantiateSingletons();
其余的都是给beanFactory补充点东西而已,不是很关键。
这句话从注释很清楚的说了,是根据BeanDefinition实例化所有剩余的单例非延迟初始化的bean。
整个方法我通过先脉络的思想,给大家概括了下:
public void preInstantiateSingletons() throws BeansException {
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
//遍历所有beanDefinition,基于beanDefinition创建bean
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (isFactoryBean(beanName)) {
//做一些处理FactoryBean
//再从容器中获取bean,如果不存在就创建
getBean(beanName);
}else{
//从容器中获取bean,如果不存在就创建
getBean(beanName);
}
}
// 执行Bean的扩展操作
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
if (singletonInstance instanceof SmartInitializingSingleton) {
smartSingleton.afterSingletonsInstantiated();
}
}
}
上面的代码是我对源码精简后的逻辑,它的脉络非常清晰了整体如下图所示:
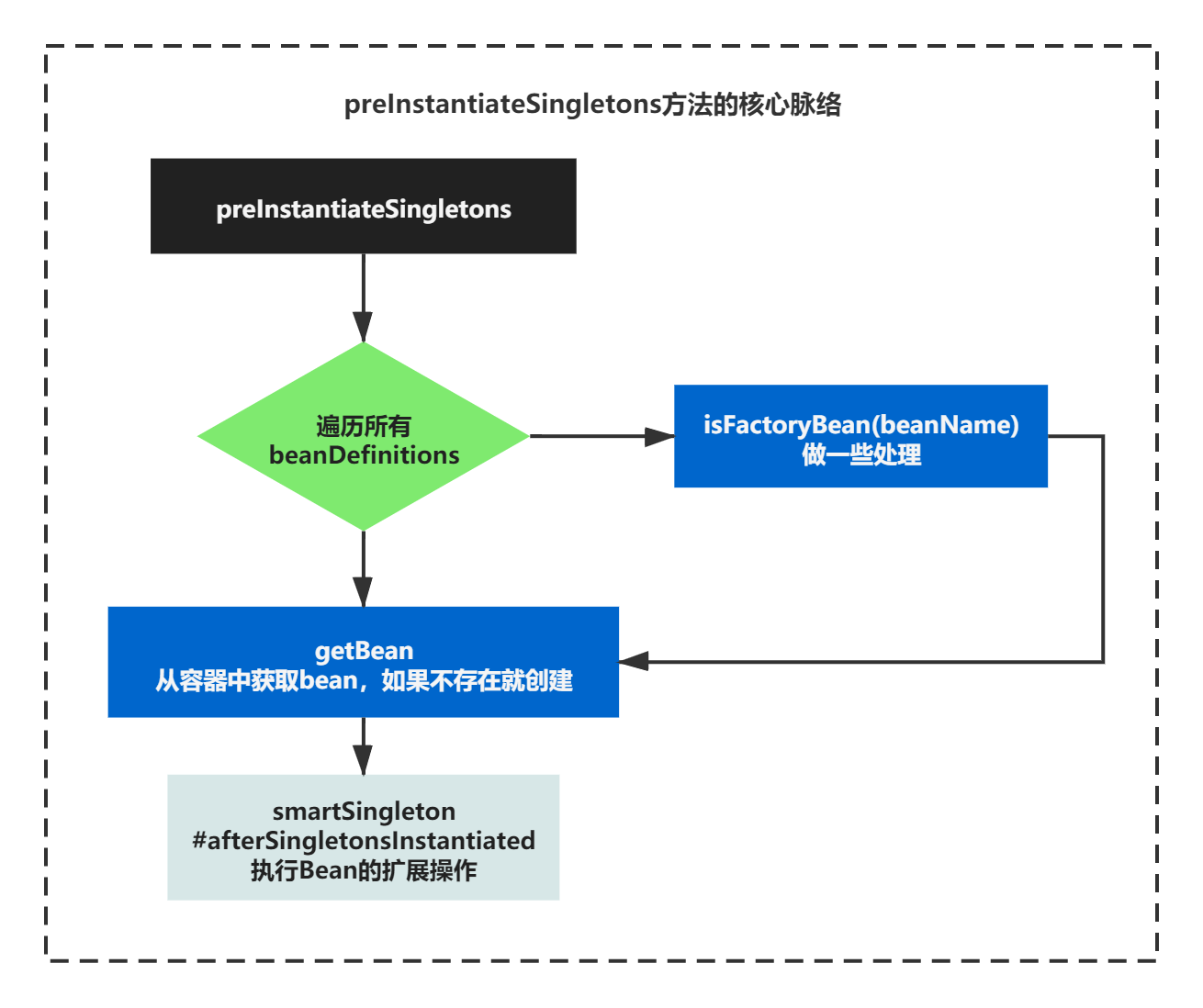
创建bean的核心流程
当你知道了preInstantiateSingletons方法的核心脉络后,它主要触发的是getBean方法,之后触发了doGetBean。
doGetBean整个方法还是比较复杂的,我还是通过先脉络的思想,抓大放小后,给大家精简了下源码,精简后如下:
@Overrid
public Object getBean(String name) throws BeansException {
return doGetBean(name, null, null, false);
}
protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType,
@Nullable final Object[] args, boolean typeCheckOnly) throws BeansException {
final String beanName = transformedBeanName(name);
Object bean;
//尝试获取bean,如果容器中有了,就不需要创建了
Object bean = getSingleton(beanName);
if(bean == nul){
//getFromParentBeanfacotry 当前容器没有bean对应的单例对象,尝试从父容器获取,如果父容器为空,则不做处理
//默认父容器空,这里略过
//当前bean的依赖dependsOn处理,递归调用getBean
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName);
String[] dependsOn = mbd.getDependsOn();
if (dependsOn != null) {
getBean(dep);
}
// 单例还是多例的方式创建bean
if (mbd.isSingleton()) {
bean = createBean(beanName, mbd, args);
}else if (mbd.isPrototype()) {
bean = createBean(beanName, mbd, args);
}else {
String scopeName = mbd.getScope();
final Scope scope = this.scopes.get(scopeName);
bean = createBean(beanName, mbd, args);
}
}
//bean的扩展,使用转换器处理bean
T convertedBean = getTypeConverter().convertIfNecessary(bean, requiredType);
return (T) bean;
}
doGetBean整体代码方法通过,抓大放小,分析脉络后,其实已经很清晰了。主要做了这么几件事:
1)getSingleton从容器Beanfactory中的map属性,获取bean,如果非空,直接就可以使用
2)如果容器中没有这个bean,通过判断是否单例,来执行对应的创建bean方法createBean
3)如果当前bean的依赖dependsOn处理,递归调用getBean
4)最后执行了bean的扩展,使用转换器处理bean
doGetBean方法的大体脉络,基本上就是这四步,如下图所示:
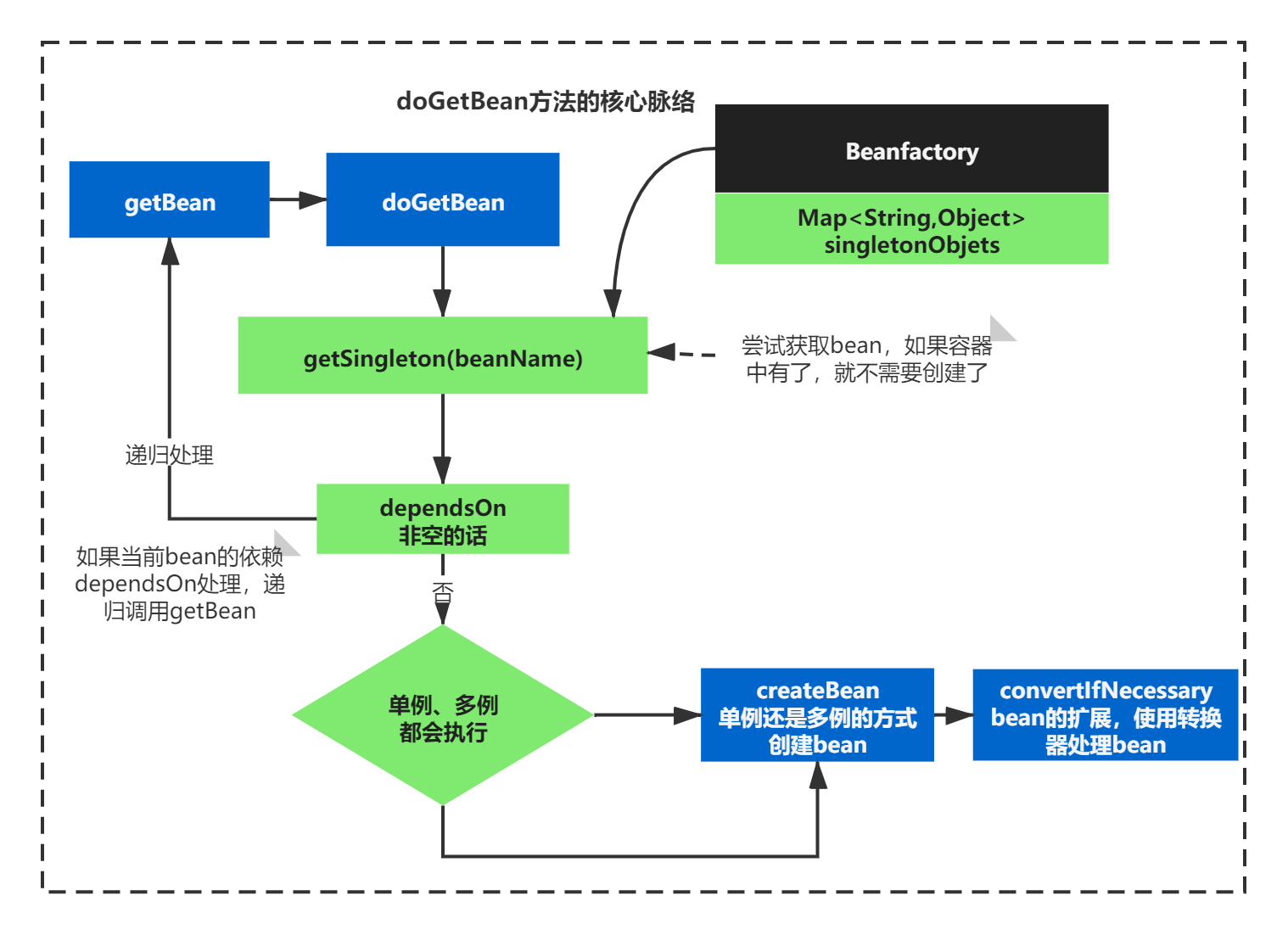
真正创建bean的逻辑,到现在我们还是没有看到,需要继续向下找。doGetBean之后下面就会执行createBean
同理我们使用之前的方法继续梳理脉络、抓大放小得到如下代码:
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {、
//Give BeanPostProcessors a chance to return a proxy instead of the target bean instance.
Object bean = resolveBeforeInstantiation(beanName, mbdToUse);
if (bean != null) {
return bean;
}
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
return beanInstance;
}
这里createBean其实主要执行了resolveBeforeInstantiation和doCreateBean方法。
1)resolveBeforeInstantiation方法从注解上看,是给动态代理创建一个对象的机会,也就说,可以通过BeanPostProcessor使用动态代理对某些bean直接进行创建。这个非常有意思,也很关键,你想想是不是有的技术就是利用这里进行创建的呢?
2)如果不满足第一个条件,就会使用doCreateBean来创建Bean
整个逻辑如下图所示:
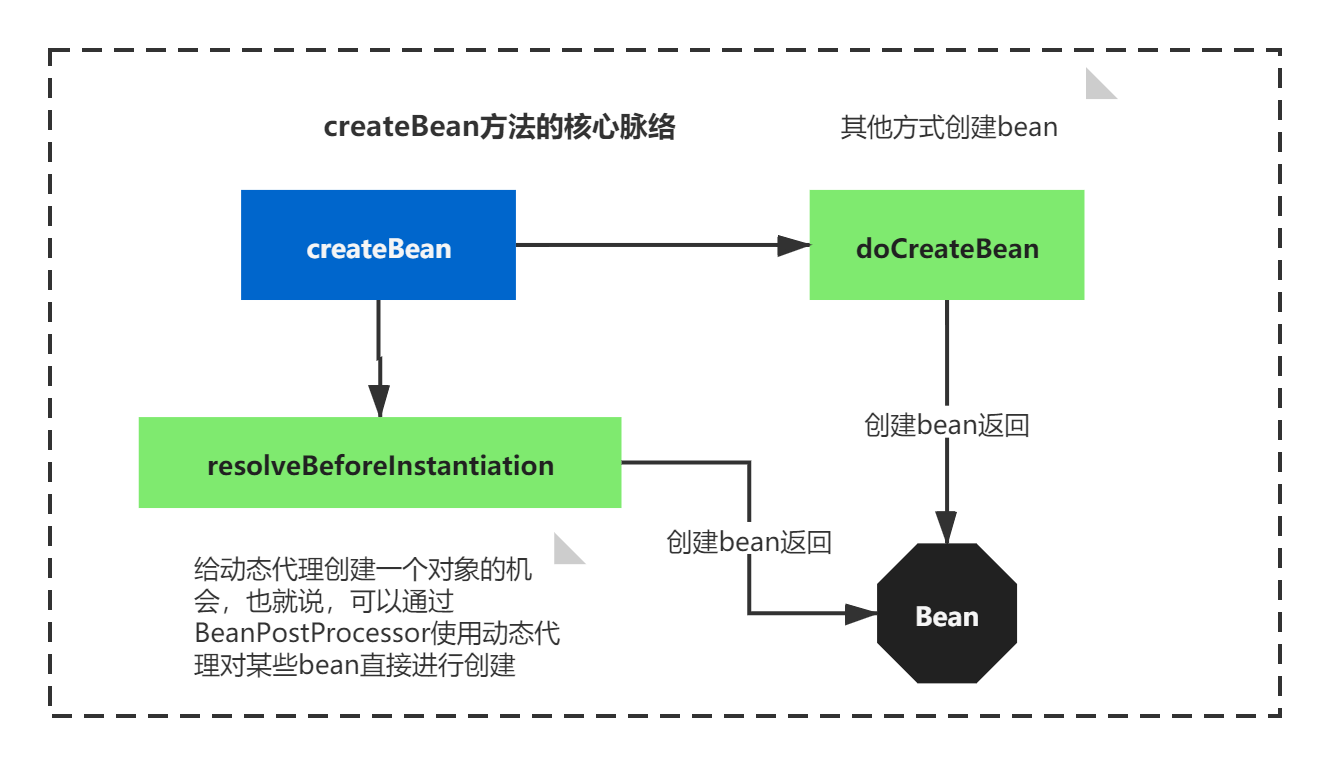
这里终于找到了一种bean创建的方式了,之后应该还有其他方式,比如反射。我们继续来看doCreateBean。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final @Nullable Object[] args)
throws BeanCreationException {
BeanWrapper instanceWrapper = null;
//创建bean,bean的实例化
if (instanceWrapper == null) {
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
//bean属性的填充
populateBean(beanName, mbd, instanceWrapper);
//bean 扩展点的触发
initializeBean(beanName, exposedObject, mbd);
//bean 扩展点的添加
registerDisposableBeanIfNecessary(beanName, bean, mbd);
return exposedObject;
}
整个doCreateBean方法,通过我们之前的思路,一样精简完后,脉络也很清楚。主要有:
1)创建bean,bean的实例化
2)bean属性的处理
3)bean 扩展点的触发
4)bean 扩展点的添加
doCreateBean的脉络如下图所示:
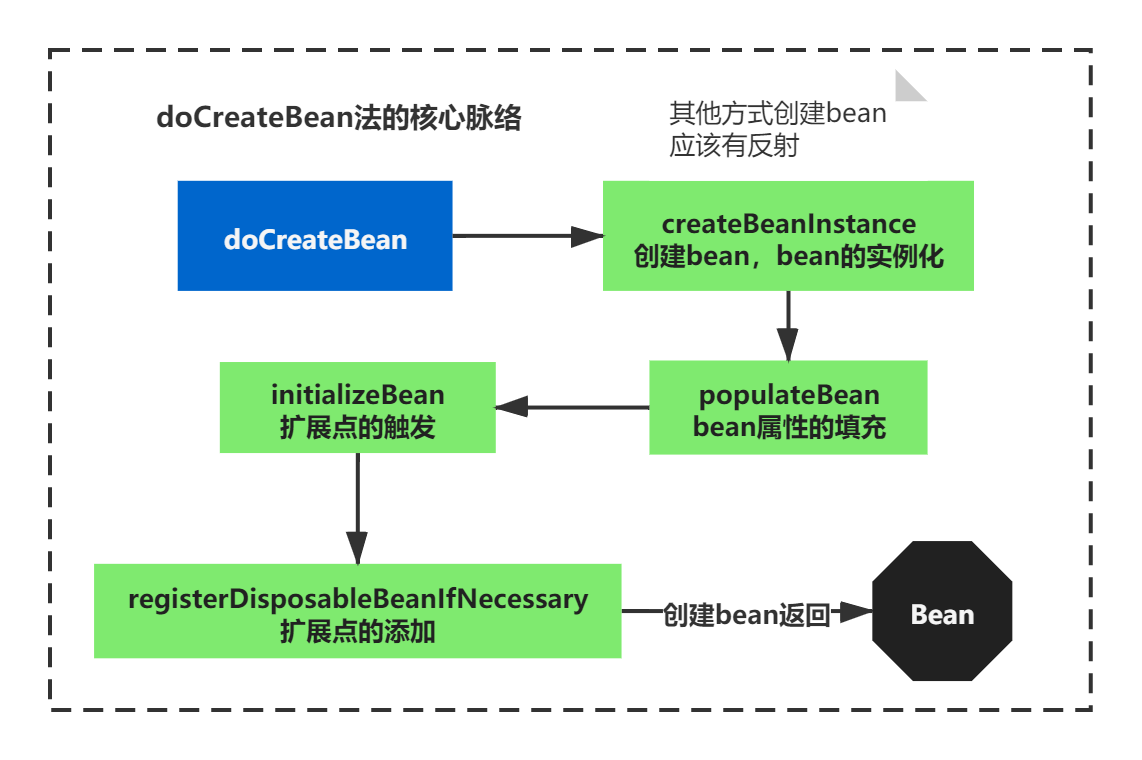
这里可以看到,除了之前动态代理的截胡,终于找到了bean实例化,创建bean的地方了。
其余对bean属性处理和扩展点,我们先不看。重点研究清楚bean的创建再说。
createBeanInstance同样被我们抓大放小后的代码如下:
protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) {
// Make sure bean class is actually resolved at this point.
Class<?> beanClass = resolveBeanClass(mbd, beanName);
//instanceSupplier方式创建bean
Supplier<?> instanceSupplier = mbd.getInstanceSupplier();
if (instanceSupplier != null) {
return obtainFromSupplier(instanceSupplier, beanName);
}
//FactoryMethod方式创建bean
if (mbd.getFactoryMethodName() != null) {
return instantiateUsingFactoryMethod(beanName, mbd, args);
}
//反射的方式创建bean
if (resolved) {
if (autowireNecessary) {
return autowireConstructor(beanName, mbd, null, null);
}
else {
return instantiateBean(beanName, mbd);
}
}
return instantiateBean(beanName, mbd);
}
你会发现有多种创建的bean的方式,并不是只有反射,方式主要有:
1)instanceSupplier方式创建bean
2)FactoryMethod方式创建bean
3)反射的方式创建bean
那么再算上之前动态代理创建bean、Factorybean创建的bean。一共已经有5种可以创建bean的方式, 但是一般我们还都是通过反射创建的居多。
你可能没有见过其他的方式创建的bean,但是我在一些技术中也见过一些,给大家分享下:
比如
Shiro框架使用Factorybean创建的就比较多
动态代理创建bean、dubbo就有很多这么创建的
FactoryMethod创建的bean,SpringBoot自动装配的时候有时候会用到,之前tomcat启动的时候,TomcatServletWebServerFactory是不是就用到了。
instanceSupplier是Spring5之后才有的,目前我还没有见到啥框架用到过…
好了不管如何,最终你获得了如下的一张图,总结bean的创建方式:
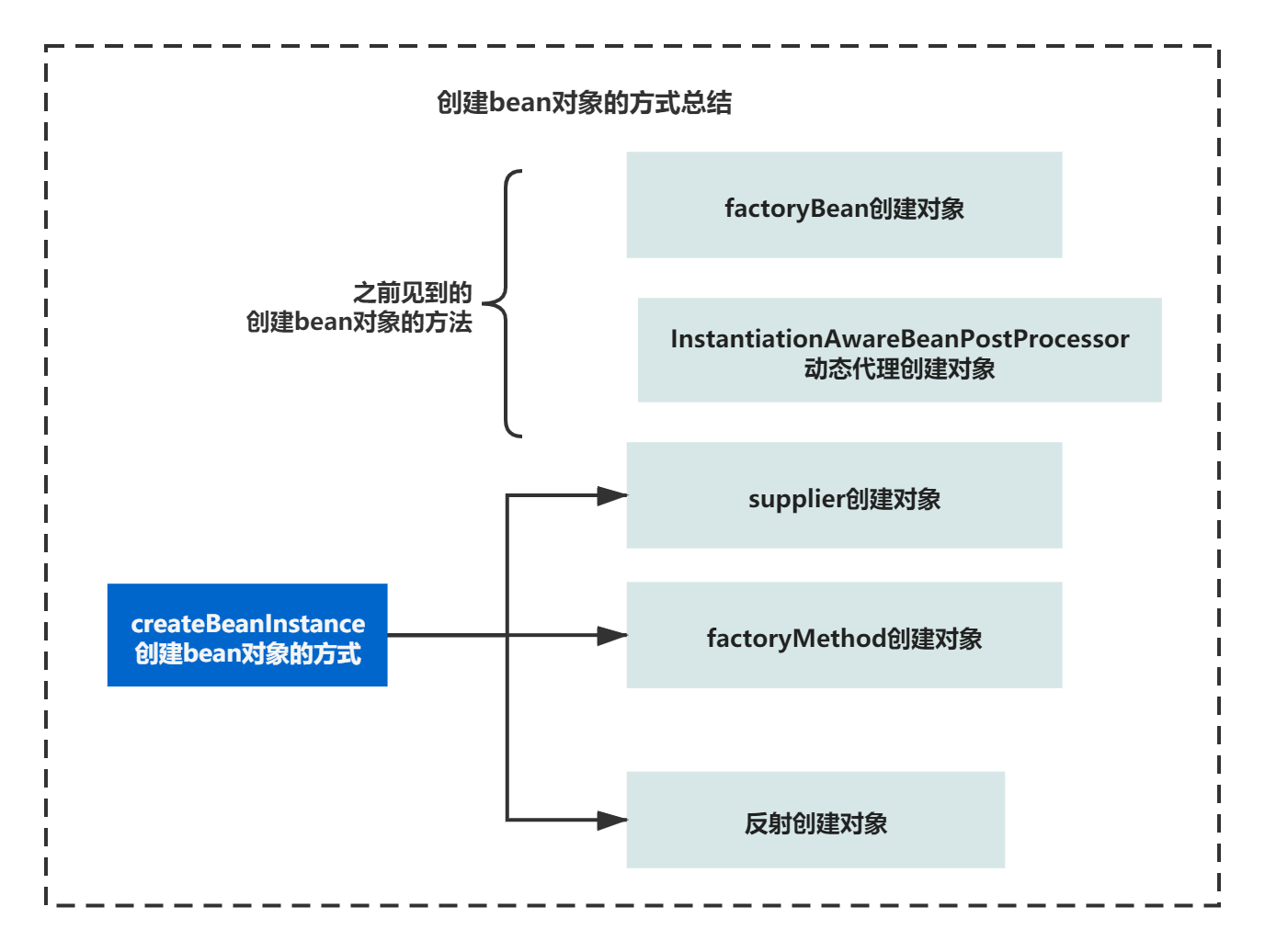
到这里bean 的创建的流程,我们就大体分析完了,由于我们不是分析Spring,所以就不会再对这里面的每个细节进行分析了。
之后有机会出Spring成长记的时候,我可以在带大家详细分析吧。
只是熟悉SpringBoot中,Spring实例化bean的流程了解到这里基本就可以了。
创建的bean整个流程可以总结下图的几步:
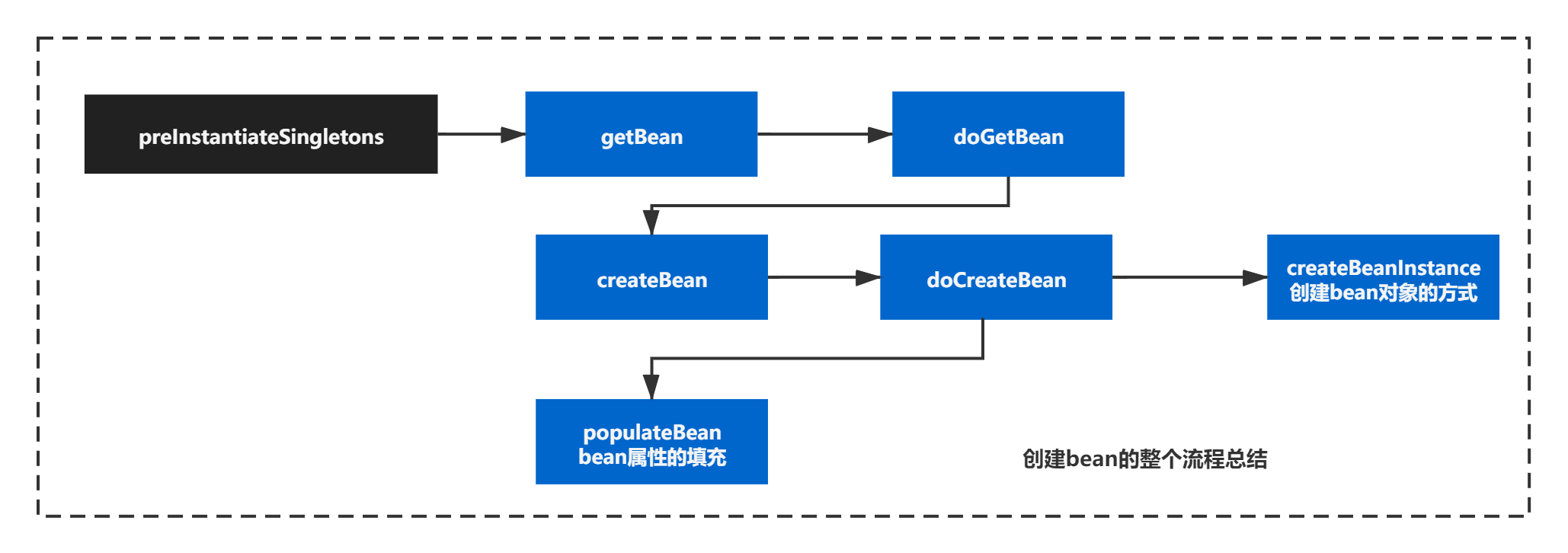
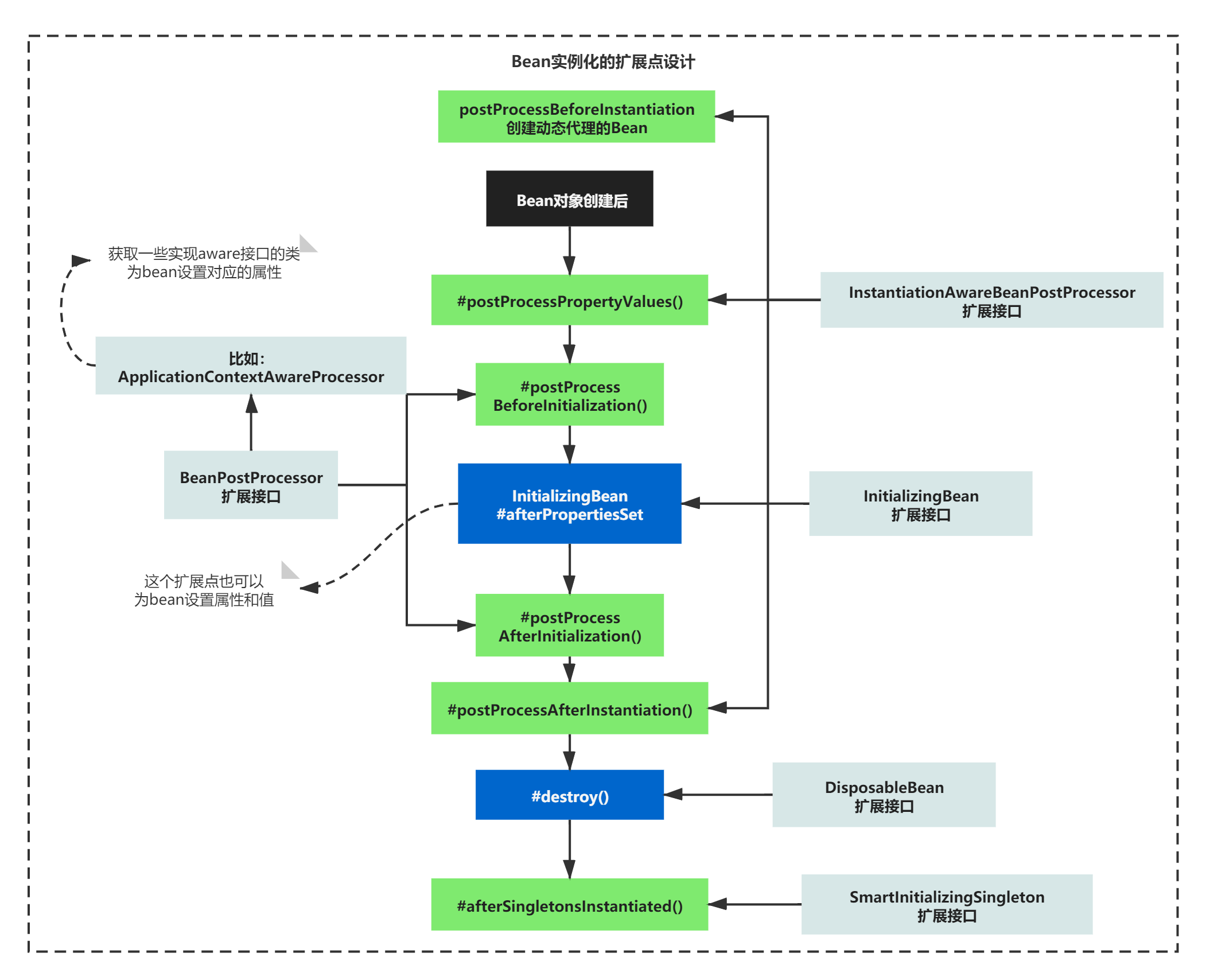
Bean实例化的扩展点设计
最后我们来看下Bean扩展设计吧,这个其实网上都有一大堆了,但是你一定要注意,你得会区分优劣的文章、提炼关键点,要对这些有自己的思考才行。
就像我现在给大家分享的,就是我对扩展点的思考。这个是我一直给大家强调的。
好了,我来简单说下,我对Bean的扩展点设计的思考和理解吧。
在Spring中,Bean实例化的时候,有很多扩展点,这些扩展点其实还是很关键的。
比如:在Spring的生态系统中,很多技术都是通过Bean的扩展点来实现的。而且包括第三方的技术,比如bytetcc分布式事物框架的实现原理和Bean扩展点BeanPostProcessor就有很大的关系、大企业自研框架,可以实现自定义注解的处理、自定义配置文件的处理、给自己开发的bean设置属性等等。
那Bean的扩展点设计了哪些呢?我给大家花了一个图,基本就能概况常见的扩展点了,当然可能还有一些其他的扩展点,不管有多少个,它们都是扩展点,合理利用就好了 ,这个是关键。
Bean实例化时,常见的扩展点的设计如图所示:
小结
如果你去看Bean的实例化的整个流程,其实其中的细节很复杂的,如果在复杂中找到关键点,是SpringBoot成长记以来,一直想要教给大家的。
最后通过对Bean实例化的分析,让大家熟练的应用了之前的学到的先脉络后细节、抓大放小、连蒙带猜、画核心组件图、流程图、看注释等思想和方法。
而且每看一阵子逻辑,要对它做出思考,思考它的设计,它的扩展、它的思想理念等等。
这个是常用的一套方法论,可能不适合所有场景,但是大多情况可以让你阅读源码或者研究技术原理的时候,不那么不安,不会觉得它们太难,可以让你有方向、有方法。
今天的内容,其实没有什么要总结的,比较重要的就是最后bean 的扩展设计,我就不在重复了。
好了,我们下一节再见!
-
消息中间件底层原理资料详解11-27
-
RocketMQ底层原理资料详解:新手入门教程11-27
-
MQ底层原理资料详解:新手入门教程11-27
-
MQ项目开发资料入门教程11-27
-
RocketMQ源码资料详解:新手入门教程11-27
-
本地多文件上传简易教程11-27
-
消息中间件源码剖析教程11-26
-
JAVA语音识别项目资料的收集与应用11-26
-
Java语音识别项目资料:入门级教程与实战指南11-26
-
SpringAI:Java 开发的智能新利器11-26
-
Java云原生资料:新手入门教程与实战指南11-26
-
JAVA云原生资料入门教程11-26
-
Mybatis官方生成器资料详解与应用教程11-26
-
Mybatis一级缓存资料详解与实战教程11-26
-
Mybatis一级缓存资料详解:新手快速入门11-26
