C/C++教程
揭秘TDSQL-A:兼容Oracle的同时支持海量数据交互

6月5日在“国产数据库硬核技术沙龙-TDSQL-A技术揭秘”系列分享中,5位腾讯云技术大咖分别从整体技术架构、列式存储及相关执行优化、集群数据交互总线、Fragment执行框架/查询分片策略/子查询框架以及向量化执行引擎等多个方面对TDSQL-A进行了深入解读。
其中腾讯云数据库高级工程师-陈再妮,对于“TDSQL-A海量数据交互之道及企业级数据库能力”,进行议题分享。没有观看直播的小伙伴,可不要错过本次分享内容的文字实录。
以下内容为现场分享实录:
TDSQL-A 是腾讯基于开源数据库PG自主研发的分布式分析型数据库系统,最早可追溯到08年,到现在已经经历10余年打磨,团队拥有数十篇核心研发专利。TDSQL-A 全面兼容 PostgreSQL,高度兼容 Oracle 语法,采用无共享架构,支持行列混合存储,在具备业界领先的数据分析能力的同时还具有完整支持分布式事务ACID的能力。
下面是TDSQL-A的总体架构,中间是数据交互总线,它将整个分布式集群的各个节点有机地联合起来,负责整个集群中所有节点数据的交互。这个数据交互总线,我们称它为FN(forward node),FN通过业界领先的集群内通讯技术,可以支持上千台节点的超大规模集群,非常适用于 PB 级的海量 OLAP 场景。
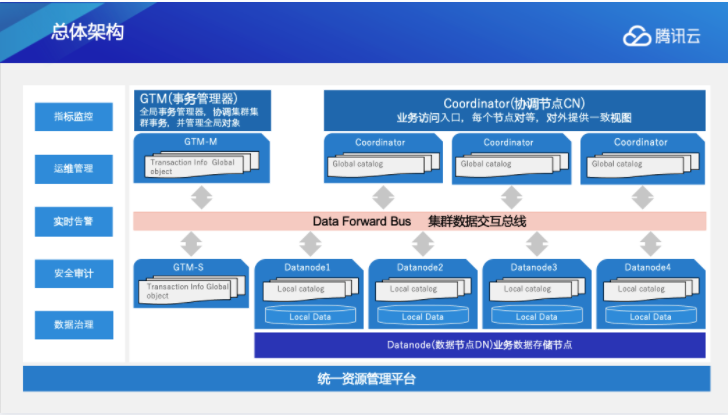
1
FN设计与部署方式
1.1 原分布式执行框架
对分布式系统来说,数据重分布是无法避免的,就如下图中所示的,当某个表的hash join的字段不是分布键时,我们就需要进行数据重分布。在数据重分布的过程中,我们需要创建相应的连接和进程。
假定我们系统现在有N个DN,DN即数据节点,在数据重分布过程中每个DN都要跟其他DN之间建立连接,那么这个系统中的连接数就是NN。如果有M层Join,那就是MNN个连接,再假定我们系统的并发数是X,在这个基础上再乘以X,那就是XMNN个连接。
这样的话,当整个集群规模达到千百台、并发为上百个时,整个集群的连接数将会有上亿个。这个连接数是非常庞大的,此外,如果连接太多创建回收socket也会成为瓶颈。为了解决这个问题,我们引入了数据交互总线节点FN(forward node)。
1.2 优化后的分布式执行框
我们在每台服务器上都部署了一个FN,用于跟其他节点之间的数据通信,图中用红色标记的节点就是FN。FN通过FID,src_node_id, dest_node_id来进行网络数据路由。而FID则标识了查询的RemotSubplan。整个业务逻辑归结起来就是,我是谁,我从哪里来,要到哪里去。
通过这种路由方式,在系统中有N个DN数据节点的情况下,不管整个系统的查询有多复杂,并发量有多大,整个集群之间最多有服务器个数N*(N-1)个socket连接,有效降低了整个集群内的连接数量。此外,本机节点通过共享内存进行数据交互可以不走网络,这样就可以支持超大规模的集群部署。
1.3 部署结构
为了将服务器资源充分利用起来,一般情况下我们会在服务器上部署多个CN或者DN。比如下图中这个服务器上就部署了两个DN,而FN我们只需要在每台服务上部署一个即可,也就是说,一个FN可以服务于这个机器上的多个CN/DN节点的通讯。
FN实际上也是一个postgres进程,与CN、DN或者GTM属于平级的关系。FN进程在启动时,可以采用参数-Z forwardnode来标识该进程为FN。把FN设计为postgres进程的优点在于可以复用PG的元数据管理、参数配置等。加入FN的主要目的,在于减少DN之间、CN和DN之间数据交换时创建的连接,从而保证大规模集群下网络连接不成为瓶颈。
1.4 通讯消息
在分布式系统中,节点之间的消息一般分为两种类型;一种是控制消息,走的是控制流;一种是数据消息,走的是数据流。
在TDSQL-A中,控制消息一般用于元数据的分发管理和命令的传递。传递方式跟PG是一致的,采用的是Libpq协议。数据的传输通过FN来进行,采用的是TCP/IP协议,FN之间建立Socket连接,来进行数据的传送。
控制消息的应用场景可以归为以下三类:
CN向DN下发plan或者sql,commit/rollback等执行命令
CN/DN向本机FN发起启动时节点的注册/退出时节点注销请求
不同机器上的FN之间相互注册/注销请求(FN跟FN之间,也是通过注册、注销进行交互的)
对于数据消息,它需要通过FN来进行转发。这里我们又可以把它细分为不同服务器之间、同一服务器内部这两种应用场景。
在不同服务器之间,CN、DN只需要与本机的FN进行交互,不再需要与其他CN/DN之间进行连接。FN根据目的节点的ID,去和目的节点的FN进行连接,这是服务器之间的转发。
在同一服务器内部,CN/DN与FN通过共享内存来进行通信。比如说,DN通过共享内存将数据传递给FN,FN再通过共享内存将数据传输到本机器上的其他DN,这样就不需要进行网络通信。
不管是在服务器之间,还是同一个服务器内部,都是由FN进行处理,这样的话,可以做到数据通信的统一管理。我们也不用担心FN会成为瓶颈,因为在FN内部也可以配置为多线程进行运行。
1.5 集群初始化
由于引入了FN,我们需要对整个集群的初始化进行调整,调整后的流程如下图所示。
初始化过程先是GTM,再到FN,最后是CN、DN。需要注意的是,我们要保证FN启动后,本机上的CN、DN再启动,这是因为本机上的CN、DN启动后需要向本机的FN进行注册,只有注册成功才能够对外提供服务。关闭顺序恰好与启动顺序相反,也就是说,关闭的时候先关闭DN、CN,再关闭FN,最后是GTM。
2
FN数据发送与接收过程
2.1 执行计划
我们举一个例子。有两张表,一个是A表,一个是B表,它们都有两列,f1列作为分布列,f2不是分布列,我们要进行一个join的查询:B表用的是f2,它不是一个分布列,这样的话就需要进行数据重分布,就发生了数据的交互。
前面提到FN是通过FID、原节点ID、目的节点ID进行数据路由,原节点ID、目的节点ID很清楚不赘述,先重点了解FID。
FID在生成执行计划的时候已经确定,整体执行计划如下:如右下角的方框所示,先对B表进行数据扫描,扫描完之后把数据重分布发送到其他机器节点上,其他机器节点收到这部分数据后进行一个join,join结束之后再进行投影。
扫描之后再发送出去这一部分,对应的FID是FID2;join结果发送数据这一部分,对应的是FID1;最后收到数据做投影的是FID0——只要牵扯到数据交互,就会有FID来进行标识。这个FID是GTM来进行统一分配管理,可以保证任意时刻都是全局唯一,这也就能标识”我是谁”这个逻辑。
2.2 数据传输
针对上面的执行计划,我们来详细看一下数据的传输过程。在执行FID2的时候,DN1上的数据需要传输到DN2上,DN2上的数据也需要传输到DN1上。我们先看DN1怎么到DN2这个链路。首先是FN1通过共享内存,拿到DN1上的数据后,发现要去的是DN2,而且现在执行的是fid2这个执行计划,它就把这部分数据通过fid2发送了出去。服务器3上的FN,就会在自己的fid2的接收队列中收到这部分数据,收到这部分数据后,再通过共享内存传递给这个服务器上的DN2,这样数据就传送过来了。同样的,DN2上的数据也是这样传送过去DN1的。在DN1和DN2完成数据传输后,需要把Join结果数据传送到CN上去做投影,此部分对应的是fid1,CN上的FN作为一个目的节点,它会从fid1的接收队列中收到来自于FN1、FN2的数据,然后通过共享内存传递到CN,CN再返回到客户端,这样就完成了整个数据传输的路由过程。
2.3 FN内部架构
下图是FN内部的详细架构。FN内部大概可分为四类:
元数据管理,管理与其他节点通信的所需的信息,比如节点ID、注册进程ID、FID使用情况等;
针对每个DN节点要进行数据传送的共享内存,一般共享内存中存储的是一些DN节点的统计信息、拥塞控制信息;
FN作为发送者,这里会有一些发送的共享内存、发送队列、发送线程;
FN作为接收者,会有一些接收的共享内存、接收线程和接收队列。
2.4 数据收发流程
模块是怎么相互合作来进行发送、接收数据的。
首先我们来看一下数据发送过程。前面提到,CN/DN启动的时候需要向本机的FN进行注册,注册时FN就会为注册的节点分配好内存空间,放在buffer pool里面,留待以后备用。这样的话,以后注册节点的这些DProcess进程(就是真正去处理用户请求的进程)它调用接口向FN申请共享内存,如果要发送,就把自己那部分的数据放到申请的内存里面去,放完之后,将这部分数据放到发送端FN的Fragment的消息队列里去,它就返回了。FN内部会有调度线程,会根据数据的FID从Fragment队列中读出来,看这个消息要去的目的节点是哪里,把它调度到对应的目的节点的发送消息队列里面去。FN内部有一个发送线程,发送线程就会真正地进行发送,发送完之后将那部分内存释放回buffer pool,这是整个发送过程。
接收端这边,收到数据也会向对应的buffer pool请求一块内存来存放这部分数据。然后把这部分存放接收数据的内存挂载到接收队列里面,接收端的FN也有自己的调度线程,会检查接收队列里面的消息的FID,根据FID再把它调度到对应的Fragment队列里去。最后DN2端这边的DProcess消费进程(用于处理用户请求),它会从Fragment消费队列中把对应的数据读出来,读出来后把这块内存再释放回去,这样就完成了整个FN内部数据的收发流程。
3
企业级Oracle兼容能力解读
3.1 分区表能力
首先是最常用的分区表能力。TDSQL-A支持range、list、hash、高性能等间隔分区,并且可以支持多级分区级联,在分区表的访问方法上,也全面兼容了oracle的语法,除了可以直接访问子表外,还可以关联父表名字来进行访问。还可以支持Update分区字段的值。
就像下图中的例子所示:0-30是一个子表,30-60是一个子表,我们可以把这个表里面的id,即分区键,把它改成不属于它以前这个分区范围内的数据,改了之后TDSQL-A内部会自动修改这条数据,将它由以前的分区挪到新的分区里面。以前的分区就查不到这条数据了。
除此之外,我们还支持分区子表的合并拆分能力、新加分区时default分区自动移动的能力。
我们先来看分区子表的拆分与合并。随着时间的推移,在使用过程中,系统的分区会越来越多,为了方便管理,很多用户就会想将早期的分区进行合并,TDSQL-A也像oracle一样提供了这样的能力。像图中左边所示,它可以通过merge partitions将1月份和2月份的分区进行合并,形成一个稍大的分区,这样就可以有效地去减少分区的数量。
分区的拆分刚好与合并相反,对于用户经常访问的热点数据,如果这些热点数据所处的分区内数据太多的话,每次就会扫到很多不必要的数据,我们可以通过拆分,将热点的分区拆分掉,拆分之后,在后续进行热点访问的时候,比如说我要访问“50”这个数据,我就只扫描30-60的子分区,0-30的分区就不需要扫描,这就能有效减少数据扫描,提高查询效率。
分区表一般会有默认的default分区,用来存储不属于其它分区的数据。在下图这个例子中,比如说2019年12月份的数据,还有2020年3月份的数据,它都不属于前面已创建的这两个子分区,但如果用户在之后创建了2020年3月份这个新分区的话,我们数据库就会自动把这部分属于这个分区的数据从default这个默认分区,移动到对应的分区里。之后default分区中就不包含这部分数据了,只有剩下的其他数据。这类似于oracle创建了分区之后default分区会自动移动的功能。
3.2 数据治理能力
TDSQL-A支持不同子分区存储到不同的节点组,不同的节点组关联着不同机器,通过这样的方案可以将热数据存储在配置好的机器上,冷数据存储在稍微差点的机器上,以此来实现冷热数据的分级存储,降低用户数据的存储成本。
3.3 存储过程能力
另一个重要的 Oracle兼容能力就是存储过程,TDSQL-A中也是支持的。比如说,存储过程中可以指定,在i是偶数的时候,对这个事物进行提交,它是奇数的时候,对它进行回滚。这样的话,最终执行完成之后,这个数据表中就只有偶数的数据。
3.4 函数扩展语法能力
此外,为了全面兼容oracle,TDSQL-A的函数在创建调用语法上也进行了适配。比如说创建的时候,可以不像PG那样指定用$$进行包围,可以做到像oracle一样以斜杠来进行结尾。如果有空参数的话,也可以不需要括号。
我们还可以在任意statement前或者是block前去添加label,然后通过goto去跳转到指定label里去。如果是原生PG的话,一般只有循环前面才能添加label。这些都是属于TDSQL-A自己开发的新功能。
在函数上面,我们还添加了对WITH FUNCTION的语法支持。比如说这个例子中SELECT调用的这个add_fnc函数,就只对这个SELECT有用,对于其他任何查询都是没有用的。而且如果这个WITH FUNCTION函数的函数名跟系统中其他函数名重名的话,这个SELECT中的函数优先级是高于其他函数的。
3.5 PACKAGE支持
和存储函数相关的package,我们也是支持的。通过创建这样的一些包,用户可以将一些常用的函数分装到一个包里去,之后可以指定一个包来进行相应的调用。这里需要注意的是,创建的话,应该是先创建包再去创建一个包体,删除的话刚好是相反的。
3.6 ROWID & ROWNUM支持
很多用户经常使用的oracle中典型的ROWID和ROWNUM,TDSQL-A也是支持的。如果用户在建表的时候,指定了WITH ROWID这样的参数,这样建出来的表在后面进行查询时,就可以指定要查的这个ROWID,就可以看到它唯一标识了这一行的数据,并且在进行数据变更之后,仍然可以保证这个ROWID不变。跟ROWID相近的还有ROWNUM,但实际上ROWNUM跟它有很大区别,它不是真正存储的,它只是用户在进行查询之后,对返回的记录进行编号。
3.7 MERGE INTO 语法支持
TDSQL-A还支持MERGE INTO语法。我们添加了对MergeStmt子句的解析,也增加了MERGE命令,可以做到将两个表进行MERGE合并。像这个例子中所示,将MERGE INTO到test1里,使用参考test2,如果匹配上的话,就对test1的数据进行更新,如果不匹配,就可以通过这个语法,将 test2里面的数据全部添加到test1里去,达到合并的目的。、
3.8 Start with connect by支持
Oracle里的start with connect by层次查询,TDSQL-A也是支持的。它实际上是进行了树的中序遍历。我们是通过一个递归CTE来进行实现的,最终实现层次查询的结果。
3.9 PIVOT & UNPIVOT支持
TDSQL-A还支持PIVOT和UNPIVOT函数。PIVOT是一个把行数据转成列属性的函数,UNPIVOT刚好相反,是将列属性转成行数据。大概的实现方法是:对于PIVOT,针对不在这个in中的这些列,把它转换为一个grop by里面的字段,来进行实现。对于UNPIVO,把这些数据转换成一个lateral join来进行实现。这些比较有特点的Oracle常用函数,TDSQ-A都是支持的。
3.10 其他兼容能力
此外我们还支持Oracle中List AGG、SQL hints、同义词、Dual表、各种日期、时间、字符串、表达式等常用函数,可以做到Oracle常用语法的90%以上兼容。
-
国产医疗级心电ECG采集处理模块01-11
-
Rakuten 乐天积分系统从 Cassandra 到 TiDB 的选型与实战01-10
-
CMS内容管理系统是什么?如何选择适合你的平台?01-09
-
CCPM如何缩短项目周期并降低风险?01-08
-
Omnivore 替代品 Readeck 安装与使用教程01-08
-
Cursor 收费太贵?3分钟教你接入超低价 DeepSeek-V3,代码质量逼近 Claude 3.501-07
-
PingCAP 连续两年入选 Gartner 云数据库管理系统魔力象限“荣誉提及”01-06
-
Easysearch 可搜索快照功能,看这篇就够了01-05
-
BOT+EPC模式在基础设施项目中的应用与优势01-04
-
用LangChain构建会检索和搜索的智能聊天机器人指南01-03
-
图像文字理解,OCR、大模型还是多模态模型?PalliGema2在QLoRA技术上的微调与应用01-03
-
混合搜索:用LanceDB实现语义和关键词结合的搜索技术(应用于实际项目)01-03
-
停止思考数据管道,开始构建数据平台:介绍Analytics Engineering Framework01-03
-
如果 Azure-Samples/aks-store-demo 使用了 Score 会怎样?01-03
-
Apache Flink概述:实时数据处理的利器01-03
