Java教程
Java最大栈深度有多大?- 重温JVM核心知识

一、问题:Java最大支持栈深度有多大?
从Java运行时数据区域我们知道,线程中的 栈结构如下: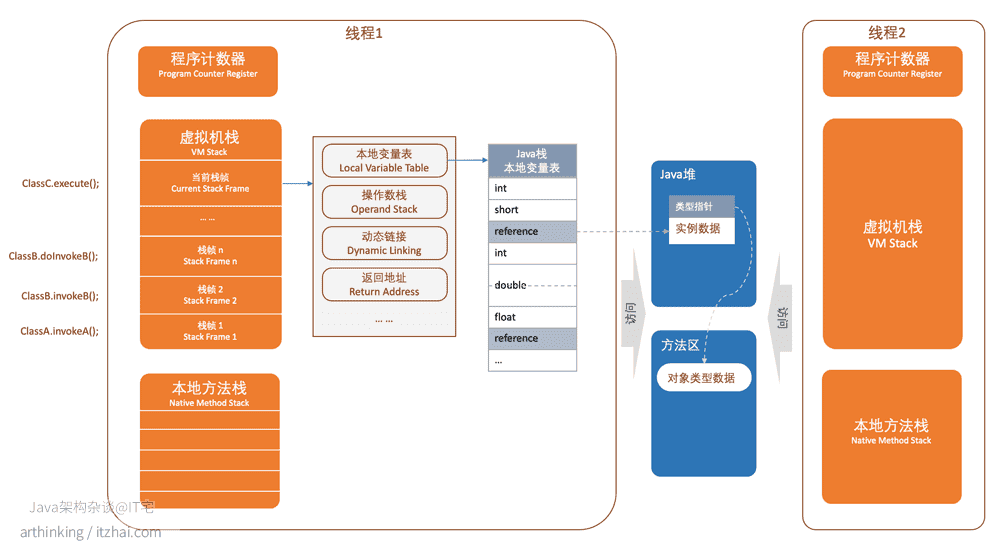
每个栈帧包含:本地变量表,操作数栈,动态链接,返回地址等东西...
也就是说栈调用深度越大,栈帧就越多,就越耗内存。
1、测试案例
1.1、测试线程栈大小对栈深度的影响
下面我们用一个测试例子来说明:
有如下递归方法:
public class StackTest {
private int count = 0;
public void recursiveCalls(String a){
count++;
System.out.println("stack depth: " + count);
recursiveCalls(a);
}
public void test(){
try {
recursiveCalls("a");
} catch (Exception e) {
System.out.println(e);
}
}
public static void main(String[] args) {
new StackTest().test();
}
}
我们设置启动参数
-Xms256m -Xmx256m -Xmn128m -Xss256k
输出内容:
stack depth: 1556 Exception in thread "main" java.lang.StackOverflowError at sun.nio.cs.UTF_8.updatePositions(UTF_8.java:77)
可以发现,栈深度为1556的时候,就报 StackOverflowError了。
接下来我们调整-Xss线程栈大小为 512k,输出内容:
stack depth: 3249 Exception in thread "main" java.lang.StackOverflowError at java.nio.charset.CharsetEncoder.encode(CharsetEncoder.java:579)
发现栈深度变味了3249,说明了:
随着线程栈的大小越大,能够支持越多的方法调用,也即是能够存储更多的栈帧。
1.2、测试方法参数个对栈深度的影响
这里我们固定设置-Xss为256k。
我们知道此时的深度为:1556。
接下来我们给方法添加参数:
public class StackTest {
private int count = 0;
public void recursiveCalls(String a){
count++;
System.out.println("stack depth: " + count);
recursiveCalls(a);
}
public void test(){
try {
recursiveCalls("a");
} catch (Exception e) {
System.out.println(e);
}
}
public static void main(String[] args) {
new StackTest().test();
}
}
为何要添加参数呢,因为添加参数之后,栈帧中的本地变量表就会增加内容,我们可以尝试使用以下命令查看下Class文件的汇编指令:
javap -v StackTest.class
可以发现recursiveCalls方法的本地变量表的确增加了,对应方法的入参 a:
LocalVariableTable:
Start Length Slot Name Signature
0 44 0 this Lcom/itzhai/jvm/stacks/StackTest;
0 44 1 a Ljava/lang/String;
这个时候我们在执行程序看看结果:
stack depth: 1318 Exception in thread "main" java.lang.StackOverflowError at java.nio.Buffer.<init>(Buffer.java:201)
可以发现,栈深度由原来的1556编程了1318。
可以得出结论:
局部变量表内容越多,那么栈帧就越大,栈深度就越小。
2、结论
- 随着线程栈的大小越大,能够支持越多的方法调用,也即是能够存储更多的栈帧;
- 局部变量表内容越多,那么栈帧就越大,栈深度就越小。
我们在评审写代码的时候,发现了堆栈溢出,可以查看下对应类的本地变量表,是不是太多了,可不可以优化下代码,或者加大下线程栈的大小,以增加栈的深度。
References:What is the maximum depth of the java call stack?
二、重温JVM知识
1. JDK,JRE,JVM的联系是啥?
JVM Java Virtual Machine
JDK Java Development Kit
JRE Java Runtime Environment
直接上官网上的介绍的图片,一目了然。

2. JVM的作用是啥?

JVM有2个特别有意思的特性,语言无关性和平台无关性。
- 语言无关性:是指实现了Java虚拟机规范的语言对可以在JVM上运行,如Groovy,和在大数据领域比较火的语言Scala,因为JVM最终运行的是class文件,只要最终的class文件复合规范就可以在JVM上运行。
- 平台无关性:是指安装在不同平台的JVM会把class文件解释为本地的机器指令,从而实现Write Once,Run Anywhere
3.JVM运行时数据区
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有些区域则依赖用户线程的启动和结束而建立和销毁。
Java虚拟机所管理的内存将会包括以下几个运行时数据区域

其中方法区和堆是所有线程共享的数据区程序计数器,虚拟机栈,本地方法栈是线程隔离的数据区,画一个逻辑图

3.1程序计数器
程序计数器是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器
为什么要记录当前线程所执行的字节码的行号?直接执行完不就可以了吗?
因为代码是在线程中运行的,线程有可能被挂起。即CPU一会执行线程A,线程A还没有执行完被挂起了,接着执行线程B,最后又来执行线程A了,CPU得知道执行线程A的哪一部分指令,线程计数器会告诉CPU。
3.2虚拟机栈
虚拟机栈存储当前线程运行方法所需要的数据,指令,返回地址等。
虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧用于存储局部变量表,操作数栈,动态链接,方法出口等信息。每个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈道出栈的过程。
局部变量表存储存储局部变量,是一个定长为32位的局部变量空间。其中64位长度的long和double类型的数据会占用2个局部变量空间(Slot),其余的数据类型只占用一个。引用类型(new出来的对象)如何存储?看下图
public int methodOne(int a, int b) {
Object obj = new Object();
return a + b;
}

如果局部变量是Java的8种基本基本数据类型,则存在局部变量表中,如果是引用类型。如String,局部变量表中存的是引用,而实例在堆中。
假如methodOne方法调用methodTwo方法时, 虚拟机栈的情况如下:

当虚拟机栈无法再放下栈帧的时候,就会出现StackOverflowError。
接着解释一下操作数栈,还是比较容易理解的假如Test.java中有如下方法,
public int getSum(int a, int b) {
return a + b;
}
反编译生成的Test.class文件,并输出到show.txt中
javap -v Test.class > show.txt
show.txt的内容如下
public int getSum(int, int);
descriptor: (II)I
flags: ACC_PUBLIC
Code:
stack=2, locals=3, args_size=3
0: iload_1
1: iload_2
2: iadd
3: ireturn
LineNumberTable:
line 12: 0
解释一下上面的语句
iload_1:局部变量1压栈 iload_2:局部变量2压栈 iadd:栈顶2个元素相加,计算结果压栈
简单2个数相加都会用到栈,这个栈就是操作数栈,更不用说复杂的语法了
3.3本地方法栈
本地方法栈(Native Method Stack)与虚拟机栈锁发挥的作用是非常相似的,他们之间的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的Native方法服务。
3.4Java堆
对于大多数应用来说,Java堆(Java Heap)是Java虚拟机锁管理的内存中最大的一块。Java堆是所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。
3.5方法区
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息,常量,静态变量,即时编译器编译后的代码等数据。
4.JVM内存模型

由颜色可以看出,jdk1.8之前,堆内存被分为新生代,老年代,永久带,jdk1.8及以后堆内存被分成了新生代和老年代。新生代的区域又分为eden区,s0区,s1区,默认比例是8:1:1,元空间可以理解为直接的物理内存

参考文档
- https://www.itzhai.com/articles/how-stack-frame-can-a-thread-hold.html
- https://www.itzhai.com/articles/how-java-runtime-data-area-works.html
- https://zhuanlan.zhihu.com/p/109794172
了解更多知识,关注我。
-
百万架构师第十五课:源码分析:Spring 源码分析:SpringMVC核心原理及源码分析|JavaGuide01-12
-
有哪些好用的家政团队管理工具?01-11
-
营销人必看的GTM五个指标01-11
-
办公软件在直播电商前期筹划中的应用与推荐01-11
-
提升组织效率:上级管理者如何优化跨部门任务分配01-11
-
酒店精细化运营背后的协同工具支持01-11
-
跨境电商选品全攻略:工具使用、市场数据与选品策略01-11
-
数据驱动酒店管理:在线工具的核心价值解析01-11
-
cursor试用出现:Too many free trial accounts used on this machine 的解决方法01-11
-
百万架构师第十四课:源码分析:Spring 源码分析:深入分析IOC那些鲜为人知的细节|JavaGuide01-11
-
不得不了解的高效AI办公工具API01-11
-
2025 蛇年,J 人直播带货内容审核团队必备的办公软件有哪 6 款?01-10
-
高效运营背后的支柱:文档管理优化指南01-10
-
年末压力山大?试试优化你的文档管理01-10
-
跨部门协作中的进度追踪重要性解析01-10
