Python教程
拒绝我复制?那我就利用Python跟我一起写某度文库下载器

前言
度娘啊,你以为你把百度网盘取消限速了,我们就满意了?当然不满意,还有某度文库呢!本来好好的文档,非得不让我们下载……今天,就教大家跟我一起写某度文库下载器Weeker,拒绝某库,从我做起。
我们的下载器是一个GUI程序,具体架构是,先写核心文件(get.py),再写命令行解析文件(weeker.py),接着使用Fire生成命令行,最后用Gooey把CLI转换为GUI。
准备
安装
- 安装Python 3.8;
- 安装依赖(依赖的作用下文会详解):pip install requests docx beautifulsoup4 Gooey
目录
初始化项目(下面的脚本是在Unix或Linux上运行的):
```
当然在学习Python的道路上肯定会困难,没有好的学习资料,怎么去学习呢?
学习Python中有不明白推荐加入交流Q群号:928946953
群里有志同道合的小伙伴,互帮互助, 群里有不错的视频学习教程和PDF!
还有大牛解答!
```
复制代码 隐藏代码 cd /path/to/project mkdir Weeker touch get.py weeker.py
爬虫核心
第一步,打开get.py,先引入类库:
复制代码 隐藏代码 from os import getcwd, system from re import sub import requests import docx from bs4 import BeautifulSoup
每个模块的作用如下:
|
模块名称 |
作用 |
|
os |
获取当前目录 |
|
re |
替换文档中的特定字符 |
|
requests |
用来做网络请求,不用多说。 |
|
docx |
用来将txt转换为docx格式。 |
|
bs4 |
用来把文本从html中解析出来。 |
由于保存文件时我们需要判断路径,定义一个pwd常量,用来存储“当前路径:
复制代码 隐藏代码 pwd = getcwd()
再声明一个get
url:ua:path:output:convert方法,来实现我们的爬虫函数,其中:
|
参数名称 |
作用 |
|
url |
文档地址,比如随便搜了一个: |
|
ua |
User Agent。我试了一下,如果使用浏览器UA是不行的,会爬到一个广告界面,然后告诉你此操作需要登录,因此我们要使用Googlebot或Baiduspider来绕过UA检测(这就是为什么搜索引擎能搜到),以为我们是一个搜索引擎。跟推荐使用后者,毕竟百度和文库一家人嘛。 |
|
path |
存储目录,不包括文件名。 |
|
output |
带有后缀名的文件名。 |
|
convert |
转换后的格式。 |
编写get:::::函数
获取html&解析
把光标移到get:::::函数。首先照例我们要用requests,并且祭上bs4一条龙解析:
复制代码 隐藏代码
headers = { 'User-Agent': ua }
result = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text, "html.parser")
# 为了方便管理文本,我们定义一个数组用来存储文档的每一行
everyline = []
添加标题
我们给文档先添上标题,也就是网页的标题。
复制代码 隐藏代码 everyline.append(soup.title.string)
但是这样会有一个问题,添加出来的标题都是“xxxxxxx_百度文库”,很不雅观。所以抬上re.sub作替换,改成:
复制代码 隐藏代码
everyline.append(re.sub('_百度文库', '', soup.title.string, 1))
获取正文
通过观察网页,我们发现,bd doc-reader这个class有重大嫌疑,这个class里的东西都是正文内容:
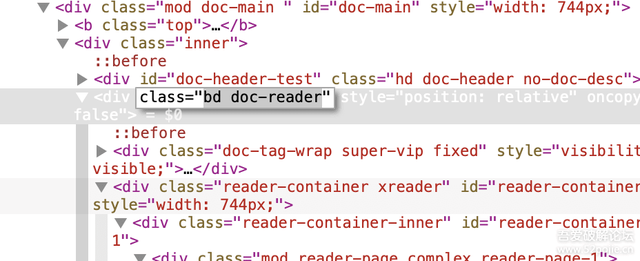
我们通过bs4解析它,发现内容中有很多\n、\x0c和空格,\n是换行符,我们把它分割到数组中,而后两者分别删除即可:
复制代码 隐藏代码
for doc in soup.find_all('div', attrs={"class": "bd doc-reader"}):
everyline.extend(doc.get_text().split('\n')) # 扩展数组
everyline = [i.replace(' ', '') for i in everyline]
everyline = [i.replace('\x0c', '') for i in everyline]
保存文件
接下来就是保存文件。我的思路是,先按照txt格式保存,然后再判断convert参数,如果填写了docx,再将txt加后缀并修改为docx。
复制代码 隐藏代码
final_path = path
# 如果是相对路径,连接pwd改成绝对路径,否则python不支持。
if not path.startswith('/'):
final_path = pwd + '/' + final_path
try:
file = open(final_path + '/' + output, 'w', encoding='utf-8')
for line in everyline:
file.write(line)
file.write('\n')
file.close()
except FileNotFoundError as err:
print("wenku: error: Output directory does not exist. Quitting.")
exit(1)
# 如果有convert请求
if convert == 'docx':
with open(final_path + '/' + output) as f:
docu = docx.Document() # 创建对象
docu.add_paragraph(f.read()) # 添加段落
docu.save(final_path + '/' + output + '.' + convert) # 保存文档,文件名为xxx.xxx.docx
system('rm ' + final_path + '/' + output) # 删除try中保存的文件
创建GUI
打开weeker.py。
首先是两句 import,其中Gooey可以用类似argparse的语法将CLI转换为GUI。
复制代码 隐藏代码 from gooey import Gooey, GooeyParser import get
接着添加if __name__ == '__main__':
复制代码 隐藏代码
if __name__ == '__main__':
main()
我们来定义一下这个main():
复制代码 隐藏代码
@Gooey(encoding='utf-8', program_name="Weeker ", language='chinese')
def main():
parser = GooeyParser(description="百度文库下载器,干杯!")
parser.add_argument("url", metavar='文档地址', widget="TextField")
parser.add_argument("ua", metavar='用户UA', widget="Dropdown", choices={"Googlebot": 1, 'Baiduspider': 2})
parser.add_argument("path", metavar='保存路径', widget="DirChooser")
parser.add_argument("output", metavar='重命名', widget="TextField")
parser.add_argument("convert", metavar='格式转换', widget="Dropdown", choices={'docx': 1})
args = parser.parse_args()
get.get(args.url, ua=args.ua, path=args.path, output=args.output, convert=args.convert)
@Gooey是一个修饰器,可以把main()转换为一个Gooey函数。在main中,我们写下类似argparse的parser.add_argument函数,最终定义args = parser.parse_args(),从args的成员获取每个参数的输入,传到get.py里。我们运行一下,神奇的一幕发生了:
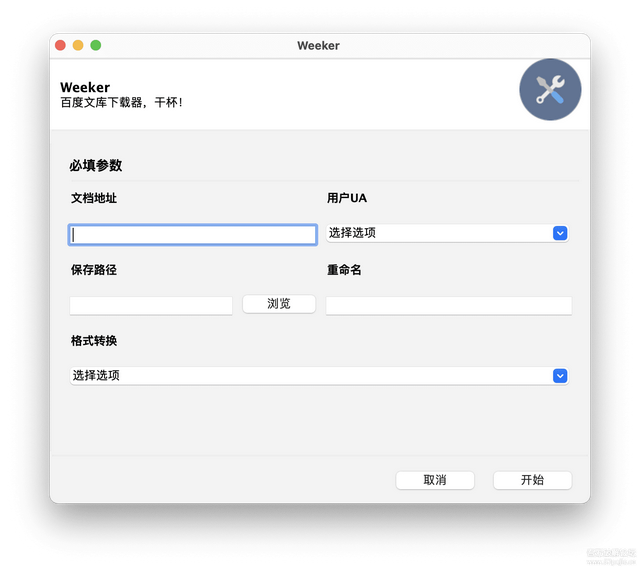
我们成功地把CLI转换成了GUI!!!
注I:如果你喜欢命令行,可以GitHub搜python-fire,直接将函数和参数暴漏给CLI,效果更佳。
注II:因为电脑原因,打包不了成品,因此有需要者请自行编译。
注III:附件里有两个py文件。
注IV:我刚看见源码里面有一句import写错了,如果你下载了源码,请先照文中代码核对一下。
-
Python编程基础教程12-28
-
Python编程入门指南12-27
-
Python编程基础12-27
-
Python编程基础教程12-27
-
Python编程基础指南12-27
-
Python编程入门指南12-24
-
Python编程基础入门12-24
-
Python编程基础:变量与数据类型12-24
-
使用python部署一个usdt合约,部署自己的usdt稳定币12-23
-
Python编程入门指南12-20
-
Python编程基础与进阶12-20
-
Python基础编程教程12-19
-
python 文件的后缀名是什么 怎么运行一个python文件?-icode9专业技术文章分享12-19
-
使用python 把docx转为pdf文件有哪些方法?-icode9专业技术文章分享12-19
-
python怎么更换换pip的源镜像?-icode9专业技术文章分享12-19
