Python教程
逆向分析pptv,利用python实现下载蓝光画质视频(Vip)

前言
前几天我想看一个番剧, 正好搜索到了 PP视频,我才知道PP视频就是PPTV聚力,我想把番剧下载下来,结果发现视频竟然不是m3u8格式,而是多段mp4,所以简单的写了个脚本,可以在不登录的情况下直接下载vip和付费视频蓝光画质(只能说明这个视频网站做的不行)
开始分析
经过调试我首先得到了视频地址的url

https://10314.vcdn.pplive.cn/0/0/1/2de8f8694a79c437a11b09941fb1cb0a.mp4?h5vod.ver=2.1.3&k=0b6a74e50374776203bd05d55a090fba-e800-1588284812&type=mhpptv
当然,我当时拿到的url 是很长的一段还有其他参数,但是我发现那些参数都是无用的影响访问的参数只有这几个
h5vod.ver : 固定值
type : 固定值
k : 变值
说明 k 是一个接口得到的, 所以我需要找到对应的接口就可以了
但是现在还有一个问题就是 这个只是视频的一段, 其他视频分段地址又是什么样的呢?
经过我反复调试发现 url 中的
https://10314.vcdn.pplive.cn/a/b/c/
(对应位置我用字母来代替数字了,为了描述方便)
a 分段视频的第几段
b 默认为0 就可以(具体表示什么不清楚,但是瞎填肯定是不行的)
c 这个数字可以随意瞎填,因为后台解析没用到这个参数,但是要有这个参数
a 为 0 第一段视频, a 为 1 为第二段视频
所以接下来的问题就是找到那个接口了
经过调试发现了一个接口
https://web-play.pptv.com/webplay3-0-12407631.xml?o=0&version=6&type=mhpptv&appid=pptv.web.h5&appplt=web&appver=4.0.7&cb=a
这个接口参数只有一个变量 那就是12407631,也就是id,每一集都有唯一的 id ,而这个id 我们也可以通过访问对应视频播放界面的url后返回的html源码中查看到

返回的不只是一集,而是全剧的每一集id都可以通过一个url来获取到
那么我们来看看 这个接口返回了哪些内容

几种画质的 mp4,知道这些那么我们还差一个 k参数就可以构造视频的url了
经过我查找发现了k值, 一个视频的一种清晰度对应唯一一个k值

这里用了url编码看起来乱七八糟,用python解码一下
from urllib.parse import unquote
print(unquote("4e6a8848fb388e09708a132bf4caeb4e-5775-1588285899%26bppcataid%3D17"))
输出:
4e6a8848fb388e09708a132bf4caeb4e-5775-1588285899&bppcataid=17
可以看到 & 符号前面的就是k ,所以到时候我们可以用& 进行分割然后取出 k
到此看起来问题全部解决了我们也可以构造视频url 了,但是还有一个问题, 那就是视频到底分多少段我们还不知道, 毕竟我们不能遍历去访问直到访问不到数据(那样太傻了)
其实接口里面也存在这样的数据了
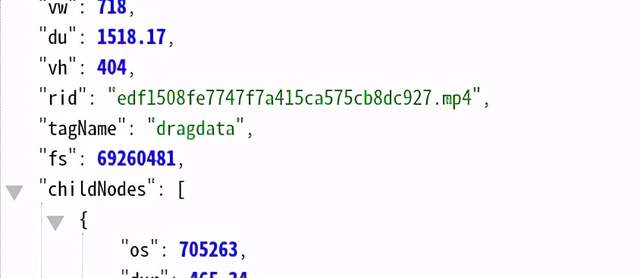
画质下面mp4 字段 childNodes 是一个列表,这个列表的长度减1 就是不同画质的分段数, 减1 是因为最后一个元素识别的内容不是描述视频分段信息的, 不得不说这个接口返回的数据构造的真是及其混乱, 我解析的时候都费了很大劲!
到此为止问题全部解决
python代码
import requests
import re
import json
import os
from threading import Thread
import sys
import time
requests.packages.urllib3.disable_warnings()
def progress():
width=30
while True:
global all_num
global now_num
percent = now_num/all_num * 100
left = int(width * percent // 100)
right = width - left
print('\r[', '#' * left, ' ' * right, ']',f' {percent:.0f}%',sep='', end='', flush=True)
if all_num == now_num:
break
time.sleep(1)
def hecheng(sh,path):
# 判断是否只是一段视频
if len(os.listdir(path)) <= 2:
os.remove(path+os.sep+"1.txt")
else:
os.system(sh)
for i in os.listdir(path):
if i != 'output.mp4':
os.remove(path+os.sep+i)
def download(url,id_,name):
global now_num
data = requests.get(url,headers={"Range": "bytes=0-"},stream=True).content
with open(name+os.sep+str(id_)+'.mp4','wb') as f:
f.write(data)
now_num += 1
def api_get(id_):
global all_num
global now_num
all_num = 0
now_num = 0
api_url = f"https://web-play.pptv.com/webplay3-0-{id_}.xml?o=0&version=6&type=mhpptv&appid=pptv.web.h5&appplt=web&appver=4.0.7&cb=a"
s = requests.get(api_url,verify=False,headers=headers)
data = json.loads(s.text[2:-4])
try:
name = data['childNodes'][2]['nm']
except Exception:
name = data['childNodes'][0]['nm']
print("正在下载:"+name)
rid = data['childNodes'][-4]['rid']
all_num = len(data['childNodes'][-4]['childNodes']) -1
kk = data['childNodes'][-5]['childNodes'][-1]['childNodes'][0].split('%26')[0]
if not os.path.exists(name):
os.makedirs(name)
# 合成命令
a1 = os.path.abspath(name+os.sep+'1.txt')
a2 = os.path.abspath(name+os.sep+'output.mp4')
sh = f'ffmpeg -f concat -safe 0 -i "{a1}" -c copy "{a2}" -loglevel error'
path = os.path.dirname(a1)
# 启动进度条线程
progress_t = Thread(target=progress)
progress_t.start()
t_list = []
t_list.append(progress_t)
f = open(name+os.sep+'1.txt','w')
for i in range(all_num):
video_url = f"https://10314.vcdn.pplive.cn/{i}/0/1/{rid}?h5vod.ver=2.1.3&k={kk}&type=mhpptv"
f.write("file "+ os.path.abspath(name+os.sep+f'{i}.mp4')+"\n")
t = Thread(target=download,args=(video_url,i,name))
t_list.append(t)
t.start()
if not mul_t:
t.join()
f.close()
for t in t_list:
t.join()
# print(sh)
print("\n"+name+" 正在合成...")
hecheng(sh,path)
print(name+" 合并成功")
def start(url,is_all,s,e,mul_t):
response = requests.get(url,verify=False,headers=headers)
if response.status_code == 200:
result = re.findall("var webcfg = (.*?);",response.text)
data = json.loads(result[0])
if is_all:
# 下载剧集
try:
for item in data['playList']['data']['list'][s-1:e]:
api_get(item['id'])
except Exception:
for item in data['playList']['data']['list']:
api_get(item['id'])
else:
# 下载单集
api_get(data['id'])
if __name__ == "__main__":
all_num = 0
now_num = 0
headers = {
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36"
}
url = input("输入地址:")
is_all = input("是否下载全剧(默认否):")
if is_all:
r = input("请输入下载剧集(例如1-5,默认全部):")
if r:
s,e = r.split("-")
s = int(s)
if e:
e = int(e)
else:
e = None
else:
s = None
e = None
mul_t = input("是否启用多线程下载(默认否):")
start(url,is_all,s,e,mul_t)
也是做了一个简单的命令行工具,功能有限
- 通过一次输入可以下载全集的蓝光画质视频
- 下载vip 视频
- 下载付费视频
- 下载完分段视频自动调用 ffmpeg 命令进行合成
- 选择性 下载 m-n 集视频
- 多线程下载(下载电影的时候最好不要开启)
使用方法: 视频播放界面的url输入进去,然后回车, 剩下的参数不写直接回车相当于默认, 随意写什么相当于是
其他注意 : windows 使用调用 ffmpeg先要把其加入系统环境变量里面,另外 第 81 行代码应改为
f.write("file "+ (os.path.abspath(name+os.sep+f'{i}.mp4')+"\n").replace("\\","\\\\"))
这个主要是windows 脑残的文件路径问题
-
用FastAPI掌握Python异步IO:轻松实现高并发网络请求处理01-03
-
封装学习:Python面向对象编程基础教程01-02
-
Python编程基础教程12-28
-
Python编程入门指南12-27
-
Python编程基础12-27
-
Python编程基础教程12-27
-
Python编程基础指南12-27
-
Python编程入门指南12-24
-
Python编程基础入门12-24
-
Python编程基础:变量与数据类型12-24
-
使用python部署一个usdt合约,部署自己的usdt稳定币12-23
-
Python编程入门指南12-20
-
Python编程基础与进阶12-20
-
Python基础编程教程12-19
-
python 文件的后缀名是什么 怎么运行一个python文件?-icode9专业技术文章分享12-19
