C/C++教程
canvas图像识取技术以及智能化设计的思考

笔者最近一直在研究 前端可视化 和 搭建化 的技术, 最近也遇到一个非常有意思的课题, 就是基于设计稿自动提取图片信息, 来智能化出码. 当然本文并不会介绍很多晦涩难懂的技术概念, 我会从几个实际应用场景出发, 介绍如何通过canvas图像识取技术来实现一些有意思的功能. 最后会总结一些对智能化的思考以及对低代码方向的规划, 希望能对各位有所启发.
canvas图像识取技术
熟悉前端的朋友们也许对canvas并不陌生, 接下来我会带大家去实现如下几个应用场景, 来深入理解canvas图像识取技术.
- 基于图片动态生成网站主色和渐变色
- 基于图片/设计稿一键生成网站配色方案
- 图像识别技术方案
基于图片动态生成网站主色和渐变色
也许有朋友会问, 基于图片动态生成网站主色和渐变色, 它能解决什么问题呢? 又有怎样的应用场景呢? 这里笔者举几个实际应用的例子.
网易云音乐大家也许不陌生, 细心的朋友也许可以观察到, 网站banner部分的背景, 是不是很好的和banner形成很好的统一?
我们会发现, 每个轮播图的背景都基于当前图片颜色进行的渐变或模糊, 来实现和轮播图实现完美的统一.
目还有还很多类似的例子, 比如图片网站的背景, 图片卡片的背景, 都应用了类似的技术.
实现原理
我们知道canvas对象有3个方法:
- createImageData() 创建新的、空白的
ImageData对象 - getImageData() 返回
ImageData对象,该对象为画布上指定的矩形复制像素数据 - putImageData() 把图像数据(从指定的 ImageData 对象)放回画布上
为了分析图片数据, 我们需要用到上述的第二个方法getImageData.ImageData 对象不是图像,它规定了画布上一个部分(矩形),并保存了该矩形内每个像素的信息。对于 ImageData 对象中的每个像素,都存在着四元信息,即 RGBA 值:
- R - 红色(0-255)
- G - 绿色(0-255)
- B - 蓝色(0-255)
- A - alpha 通道(0-255; 0 是透明的,255 是完全可见的)
color/alpha 信息以数组形式存在,并存储于 ImageData 对象的 data 属性中。
有了以上的技术基础, 我们就完全有可能提取到图片的颜色信息, 并分析出图片的主色了. 所以我们的实现流程如下:
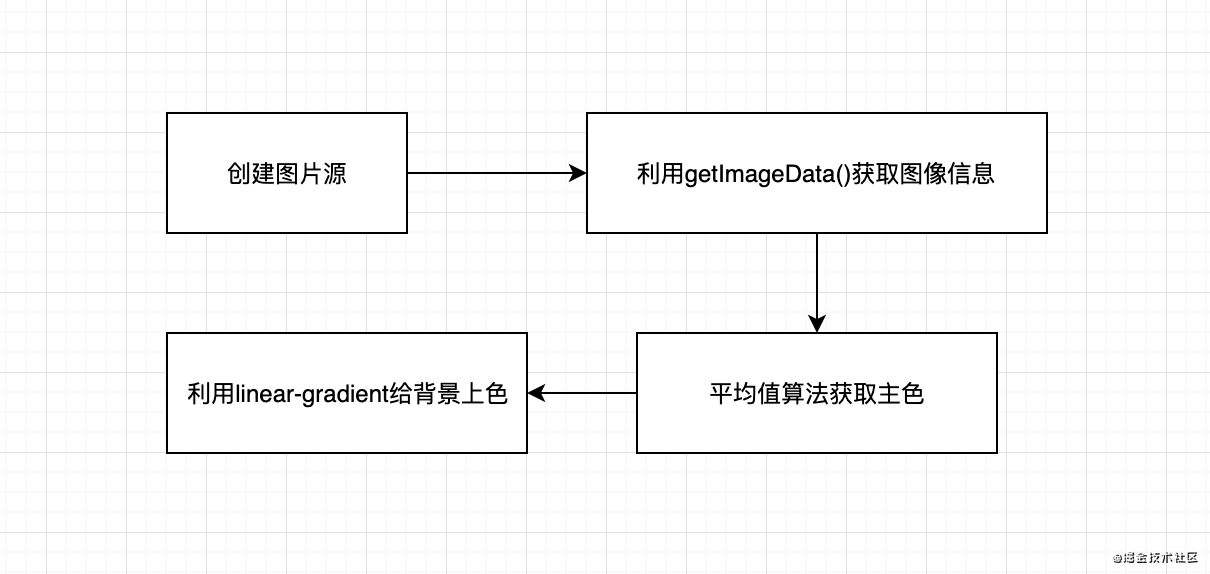
实现的参考代码如下:
img.onload = function () {
ctx.drawImage(img, 0, 0)
img.style.display = 'none'
// 获取像素数据
let data = context.getImageData(0, 0, img.width, img.height).data
// ImageData.data 类型为Uint8ClampedArray的一维数组,每四个数组元素代表了一个像素点的RGBA信息,每个元素数值介于0~255
let r = 0,
g = 0,
b = 0
// 取所有像素平均值
for (let row = 0; row < img.height; row++) {
for (let col = 0; col < img.width; col++) {
r += data[(img.width * row + col) * 4]
g += data[(img.width * row + col) * 4 + 1]
b += data[(img.width * row + col) * 4 + 2]
}
}
// 计算平均值
r /= img.width * img.height
g /= img.width * img.height
b /= img.width * img.height
// 将结果取整
r = Math.round(r)
g = Math.round(g)
b = Math.round(b)
// 给背景设置渐变
bgBox.style.backgroundImage = `linear-gradient(rgb(${r}), rgb(${g}), rgb(${b})`;
}
值得说明的是, 根据不同的区值场景, 我们还可以用到其他算法诸如:
- 平均值算法(获取主色调)
- 中位切分法(获取png图片的主色)
- 互补色计算法
基于图片/设计稿一键生成网站配色方案
以上介绍了使用canvas的取色方案, 接下来我们更进一步, 来探索一下如何基于图片/设计稿一键生成网站配色方案.
其实基于以上的例子我们完全可以自己实现一套网站配色生成工具, 这里为了节约时间, 笔者推荐一款比较强大的插件, 来帮我们实现类似的功能.

没错, 就是colorthief, 它支持浏览器和node环境, 所以作为前端, 我们可以很轻松的使用它并获取图像/设计稿的配色方案.
简单的使用例子如下:
import ColorThief from './node_modules/colorthief/dist/color-thief.mjs'
const colorThief = new ColorThief();
const img = document.querySelector('img');
if (img.complete) {
colorThief.getColor(img);
} else {
image.addEventListener('load', function() {
colorThief.getColor(img);
});
}
该库还有很多细化的api,比如控制生成质量, 粒度等, 我们可以以用它做一些更加智能的工具.
图像识别技术方案
图像识别技术可以帮助技术人员利用计算机对图像进行处理和分析,更好地识别各种不同模式的目标。 图像识别的过程和内容是比较多的,主要包括图像预处理和图像分割等内容,它在图像处理中的有效应用,还能够根据图像的特点对其进行判断匹配,让用户能够更加快速的地在图片中搜索自己想要获取的信息。
了解神经网络的朋友可能知道, 图像识别技术真正的解决方案是 卷积神经网络(CNNs或ConvNets).
从图像识别技术的术语来说就是,卷积神经网络按照关联程度筛选不必要的连接,进而使图像识别过程在计算上更具有可操作性。卷积神经网络有意地限制了图像识别时候的连接,让一个神经元只接受来自之前图层的小分段的输入(假设是3×3或5×5像素),避免了过重的计算负担。因此,每一个神经元只需要负责处理图像的一小部分。
当然作为前端工程师, 我们可能还涉及不到这么深的内容, 不过也不用担心, 目前已有很多工具帮我们解决了底层的分析难题. 比如国内比较有名的imgcook, 通过识别技术来生成可被浏览器消费的html代码.
其工作机制如下:
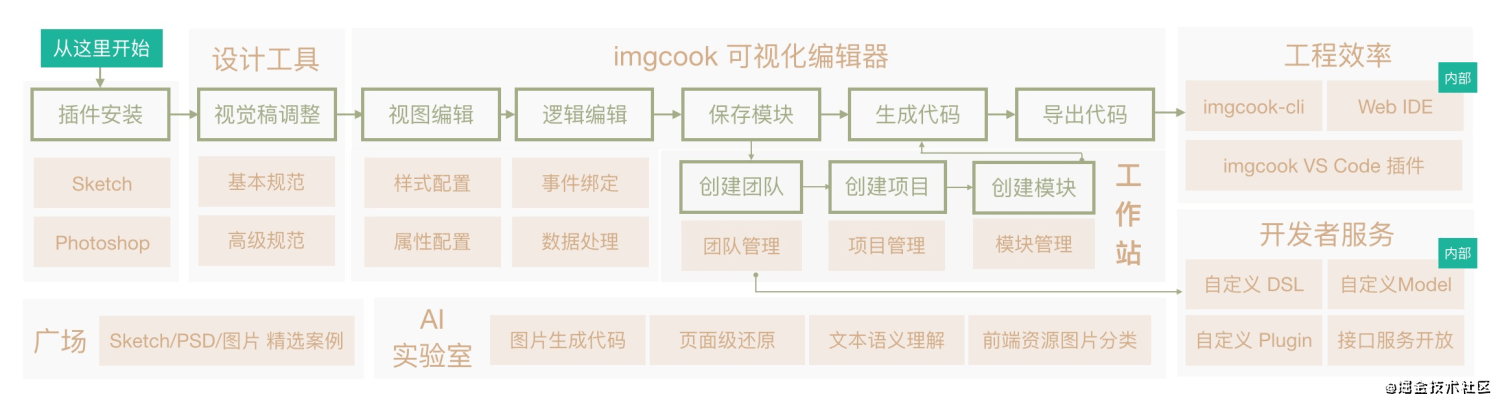
其底层识别技术也是基于对图片信息元的分析, 提取和转化, 来实现智能化编排的目的. 当然也有一些开源的库可以帮我们做到一定程度的识别能力. 我们可以基于这些方案, 制作一些对开发更智能化的工具.
这里笔者提一个图片识别的库GOCR.js, 供大家参考学习.

GOCR.js 是 GOCR(开源的 OCR 光学识别程序)项目的纯 JavaScript 版本,使用 Emscripten 进行自动转换。这是一个简单的 OCR (光学字符识别)程序,可以扫描图像中的文字回文本。
该库的使用也非常简单, 我们只需要引入该库, 输入如下代码即可:
var string = GOCR(image); alert(string);
演示如下:

智能化思考
最近几年国内外lowcode和nocode平台发展迅猛, 对于基础的搭建化已不能满足科技企业的需求, 智能化/自动化搭建平台不断涌现. 笔者之前文章 [分享10款2021年国外顶尖的lowcode开发平台]也介绍过很多国外的优秀lowcode平台, 很多也对智能化有了很多的实践落地. 笔者简化如下:
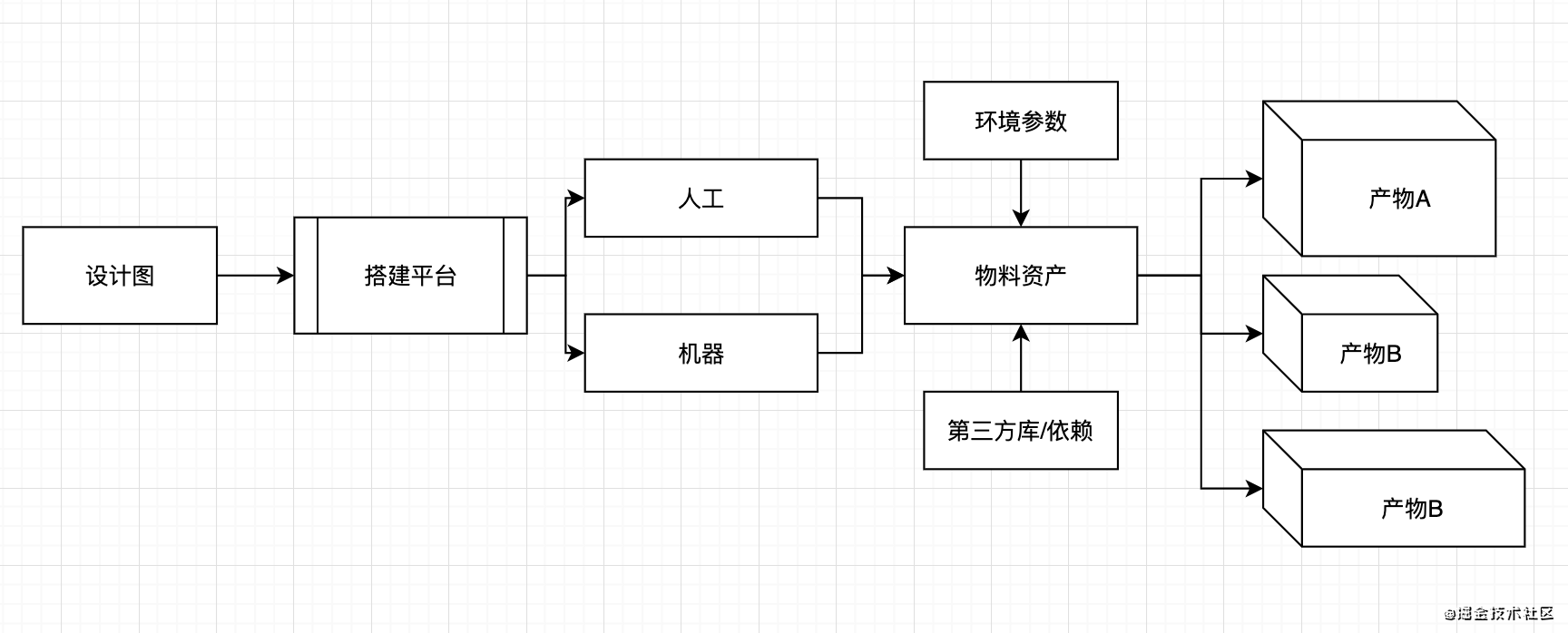
最近H5-Dooring可视化编辑器也在持续推迭代, 数据源已基本搭建完成, 后续还会按照更智能化的方向, 可视化大屏V6.Dooring也已上线第一个版本.
国内lowcode平台仍然有很长的路要走, 期待大家一起努力💪!
-
Rakuten 乐天积分系统从 Cassandra 到 TiDB 的选型与实战01-10
-
CMS内容管理系统是什么?如何选择适合你的平台?01-09
-
CCPM如何缩短项目周期并降低风险?01-08
-
Omnivore 替代品 Readeck 安装与使用教程01-08
-
Cursor 收费太贵?3分钟教你接入超低价 DeepSeek-V3,代码质量逼近 Claude 3.501-07
-
PingCAP 连续两年入选 Gartner 云数据库管理系统魔力象限“荣誉提及”01-06
-
Easysearch 可搜索快照功能,看这篇就够了01-05
-
BOT+EPC模式在基础设施项目中的应用与优势01-04
-
用LangChain构建会检索和搜索的智能聊天机器人指南01-03
-
图像文字理解,OCR、大模型还是多模态模型?PalliGema2在QLoRA技术上的微调与应用01-03
-
混合搜索:用LanceDB实现语义和关键词结合的搜索技术(应用于实际项目)01-03
-
停止思考数据管道,开始构建数据平台:介绍Analytics Engineering Framework01-03
-
如果 Azure-Samples/aks-store-demo 使用了 Score 会怎样?01-03
-
Apache Flink概述:实时数据处理的利器01-03
-
使用 SVN合并操作时,怎么解决冲突的情况?-icode9专业技术文章分享01-01
