Java教程
浏览器怎样渲染网页?

有时候我们在使用某个网站的时候会出现影响用户体验的共性问题,例如:网站加载速度过慢、一直在等待文件的加载、加载出来了界面却没有样式等。为了避免开发人员开发这种网站,我们需要深入理解浏览器渲染界面的生命周期。
Document Object Model (DOM)
首先我们需要理解什么是DOM,浏览器向服务器发送请求获取HTML数据,服务器以二进制字节流的形式向浏览器返回HTML文本,这个response的header中有这样的attribute:Content-Type:text/html;charset=UTF-8。text/html是一种MIME Type,它告知浏览器这种MIME Type是HTML Document。charset=UTF-8告知浏览器该MIME Type文件需要使用UTF-8的编码方式解码。根据这些信息,浏览器就能将二进制字节流转化为我们看到的HTML Document。
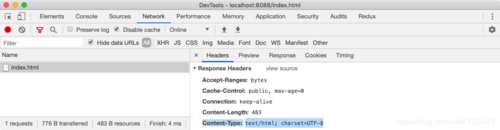
如果丢失response header中的text/html,浏览器就不能理解怎样处理该MIME Type,这个时候二进制字节流将会被渲染普通文本格式。但是如果一切正常,经过浏览器对该MIMET Type文件的转化,典型的HTML Document最终看起来会是这样:
<!DOCTYPE HTML><html> <head> <title>Rendering Test</title> <!-- stylesheet --> <link rel="stylesheet" href="./style.css"/> </head> <body> <div class="container"> <h1>Hello World!</h1> <p>This is a sample paragraph.</p> </div> <!-- script --> <script class="lazyload" src="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAAAXNSR0IArs4c6QAAAARnQU1BAACxjwv8YQUAAAAJcEhZcwAADsQAAA7EAZUrDhsAAAANSURBVBhXYzh8+PB/AAffA0nNPuCLAAAAAElFTkSuQmCC" data-original="./main.js"></script> </body></html>
在上面的代码段中,该网页依赖于为网页提供样式的style.css和为网页提供操作的main.js。在style.css添加一些炫酷的样式,我们的网页看起来如下图所示:
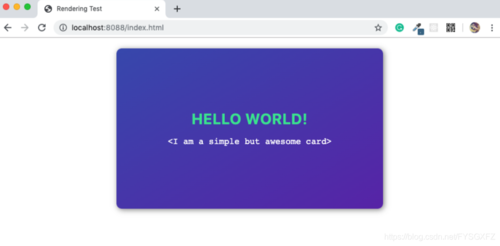
但是问题仍然存在啊,浏览器是怎样将平平无奇的只包含文本的HTML文件渲染成如此炫酷的界面呢?为了解决这个问题我们需要从DOM、CSSOM、Render Tree入手。
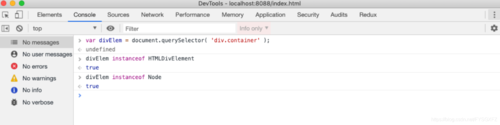
无论何时浏览器解析HTML代码,遇到HTML、body、div等元素,他都会创建与之对应的JavaScript Node对象,最终所有的元素都会被转化为JavaScript对象。由于每个HTML元素都有不同的属性,因此将通过不同的类(构造函数)创建Node对象。例如:div对应的Node对象HTMLDivElement继承自Node类,我们可以使用chrome的DevTools来做如下测试:
浏览器为每个元素创建完对象之后,它将会为这些Node对象创建一个树形结构。由于在HTML文档中元素之间互相嵌套,所以浏览器需要复制文档中的元素但是使用之前创建的Node对象来创建树形结构。这个步骤将有助于浏览器在整个生命周期内有效地呈现和管理网页。
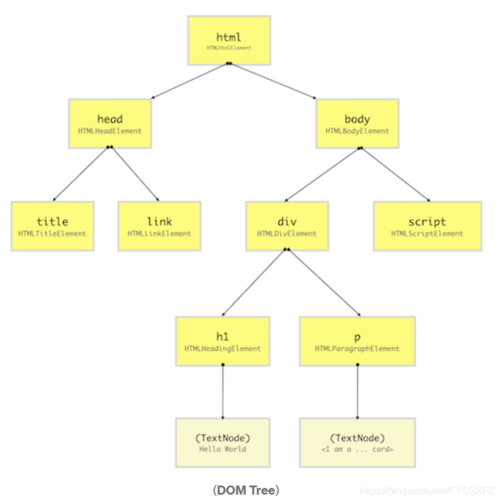
这就是DOM Tree。其结构如上图所示。
DOM Tree最顶端的元素是html,其分支是元素在文档中出现和嵌套来显示的。不论什么时候解析到HTML元素,浏览器都会创建与之对应的Node对象。
DOM节点并不一定总是HTML元素。 当浏览器创建DOM树时,它还将诸如注释,属性,文本之类的内容另存为树中的单独节点。 但为简单起见,我们仅考虑HTML元素(又称为DOM元素)的DOM节点。
DOM Tree通过实例对象的七个属性描述节点之间的关系,构成层次结构
1) ownerDocument属性: 该属性指向整个节点树中的文档节点
2) parentNode属性: 该属性指向节点树中该节点的父节点
3) previousSibling属性: 该属性指向节点树中该节点的左兄弟节点
4) nextSibling属性: 该属性指向节点树中该节点的右兄弟节点
5) childNodes属性: 该属性指向节点树中该节点的子节点NodeList集合
6) firstChild属性: 该属性指向节点树中该节点的子节点NodeList集合中的第一个字节点
7) lastChild属性: 该属性指向节点树中该节点的子节点NodeList集合中的最后一个字节点
可以通过Chrome DevTools来观察节点之间的继承关系:
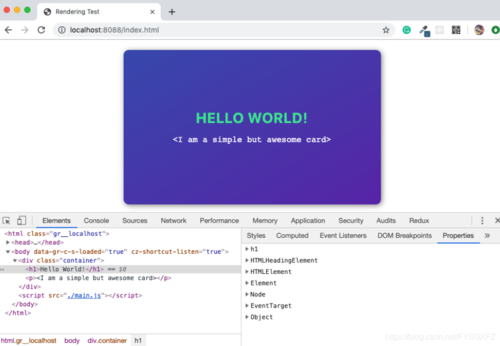
JavaScript不知道什么是DOM,DOM不是JavaScript规范的一部分。DOM是浏览器提供的高级Web API,用于高效地呈现网页并将其公开显示给开发人员,以便开发者动态操纵DOM元素。
使用DOM API开发人员可以对HTML元素进行增删改查的操作,可以在内存中创建或者拷贝HTML元素,在不渲染DOM Tree的情况下操作HTML元素。这使开发人员能够构建具有丰富用户体验的高度动态的网页。
CSS Object Model (CSSOM)
当我们设计网站的时候,我们需要将其设计地尽善尽美。为了达到这个目标我们在HTML元素上提供一些样式。在本页面中我们使用的是Cascading Style Sheets(级联样式)。使用CSS选择器我们能够定向操纵目标元素的样式。
外部CSS文件、通过<style>内嵌CSS样式、在HTML元素上使用style属性、使用JavaScript 应用在HTML元素上的方法是不同的,但是最终浏览器繁琐地将CSS样式应用在DOM元素上。
在构建好DOM Tree之后,浏览器会加载所有的CSS样式(外部CSS文件,<style>内嵌样式,行内style属性,用户代理样式等)来构建一个CSSOM。CSSOM是一个树形结构的CSS对象模型。
CSSOM Tree上的每一个节点都会保存CSS样式信息,最终会被应用DOM Tree的目标元素上。CSSOM不包含无法在屏幕上显示的<meta>、<script>等DOM元素。
浏览器本身会具有它自己的样式文件,定义我们没有自定义CSS样式的时候需要显示的样式。这被称为用户代理样式。浏览器在计算样式的时候会让用户自定义的样式覆盖用户代理样式。
根据W3C CSS的标准,即使用户和浏览器没有定义该CSS属性(例如:display),该属性也会有默认值。在选择CSS属性的默认值时,如果某个属性符合W3C文档中提到的继承条件,则将使用一些继承规则。
例如,如果HTML元素缺少color和font-size这些属性,则DOM元素会继承父级的值。 因此,您可以想象在HTML元素及其所有子元素都拥有这些属性。 这就是所谓的级联样式,这也是CSS是级联样式表的缩写的原因。 这也是为什么浏览器构造CSSOM(一种类似树的结构以根据CSS级联规则计算样式)的原因。
通过Chrome DevTools,从左侧面板中选择任何HTML元素,然后在右侧面板中单击“计算”选项卡可以观察该元素的样式。
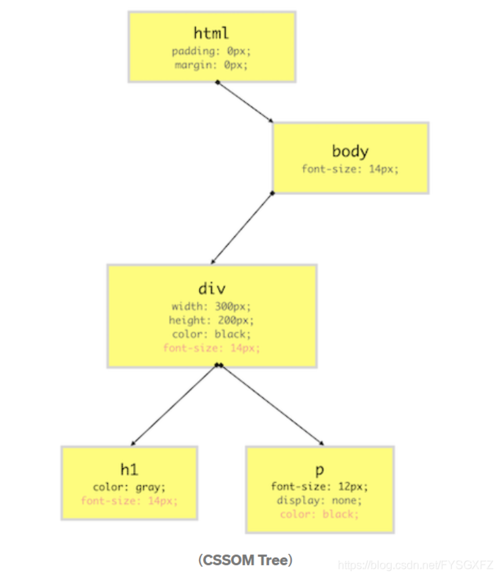
为上面的HTML文件添加如下样式:
html { padding: 0; margin: 0;
}body { font-size: 14px;
}.container { width: 300px; height: 200px; color: black;
}.container > h1 { color: gray;
}.container > p { font-size: 12px; display: none;
}最终会构建如下CSSOM Tree:
Render Tree
Render Tree也是通过将DOM和CSSOM树组合在一起而构建的树状结构。 浏览器必须计算每个可见元素的布局并将其绘制在屏幕上,因为该浏览器需要使用此Render Tree。 未构建Render Tree的情况下屏幕上不会显示任何内容,这就是我们同时需要DOM和CSSOM树的原因。
由于“渲染树”是在屏幕上显示的内容的底层表示,因此它不会包含不占据像素矩阵中任何区域的节点。 例如,display:none; 该元素的尺寸为0px X 0px,因此该元素不会出现在“渲染树”中。
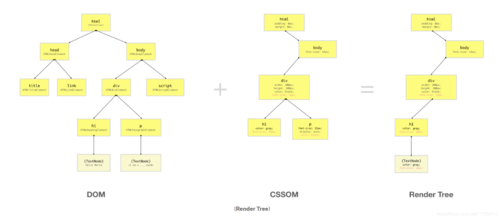
从上图可以看到,Render-Tree结合了DOM和CSSOM进而生成树状结构,其中仅包含将在屏幕上打印的元素。
在CSSOM中,位于div内的p元素属性为display:none,因此它及其子级不会出现在“渲染树”中,因为它在屏幕上不占空间。 但是,如果元素的属性为visibility:hidden或opacity:0,它们将占据屏幕上的空间,因此它们会出现在“渲染树”中。
与DOM API允许访问由浏览器构造的DOM Tree中的DOM元素不同,CSSOM对用户隐藏。 但是,由于浏览器将DOM和CSSOM结合在一起形成了“Render Tree”,因此浏览器通过在DOM元素本身上提供高级API来公开DOM元素的CSSOM节点。 这使开发人员可以访问或更改CSSOM节点的CSS属性。
Rendering Sequence
现在,我们对DOM,CSSOM和Render Tree有了很好的了解,让我们一起来了解浏览器如何使用它们来呈现网页。 对这个过程的简单了解对于任何Web开发人员都是至关重要的,因为它将帮助让我们设计的网站获得良好的用户体验和性能。
加载网页后,浏览器将首先读取HTML文本并从中构造DOM树。 然后,它处理CSS(无论是嵌入式CSS,嵌入式CSS还是外部CSS),并从中构造CSSOM树。
构造完这些树后,便会从中构造出渲染树。 一旦构建了Render Tree,浏览器便开始在屏幕上打印单个元素。
Layout operation
首先,浏览器创建每个单独的“渲染树”节点的布局。 布局包括每个节点的大小(以像素为单位)以及它将在屏幕上打印的位置。 由于浏览器正在计算每个节点的布局信息,因此此过程称为布局(layout)。
此过程也称为重排(reflow)或浏览器重排(browser reflow),并且在滚动,调整窗口大小或操作DOM元素时也可能发生。 这是可以触发元素的布局/重排的事件列表。
我们应该避免网页经历多次布局操作,因为这是一项繁杂的操作。 这是保罗·刘易斯(Paul Lewis)发表的一篇文章,他谈到了如何避免复杂而昂贵的布局操作也就是布局颠簸(layout thrashing)。
Paint operation
到目前为止,我们具有了需要在屏幕上打印的几何分布矩阵。 由于“渲染树”中的元素(或子树)可以彼此重叠,并且它们可以具有CSS属性,这些属性使它们经常更改外观,位置或形状(例如动画),因此浏览器会为其创建一个图层(layer)。
创建图层可帮助浏览器在网页的整个生命周期中有效执行绘画操作,例如在滚动或调整浏览器窗口大小时。图层还可以帮助浏览器正确地按照开发人员的意愿按顺序(沿z轴)绘制元素。
现在我们有了图层,我们可以将它们组合起来并在屏幕上绘制它们。但是浏览器并不会一次绘制所有图层。会分别绘制每个图层。
在每一层内部,浏览器会填充元素的任何可见属性(例如边框,背景色,阴影,文本等)的各个像素。此过程也称为光栅化(raster)。为了提高性能,浏览器可以使用不同的线程来执行光栅化。
Photoshop中的图层可以用来类比浏览器中的呈现网页的图层。您可以通过Chrome DevTools可视化网页上的不同图层。打开DevTools,然后从more tools选项中选择“Layers”。您也可以从该面板中可视化图层边框。
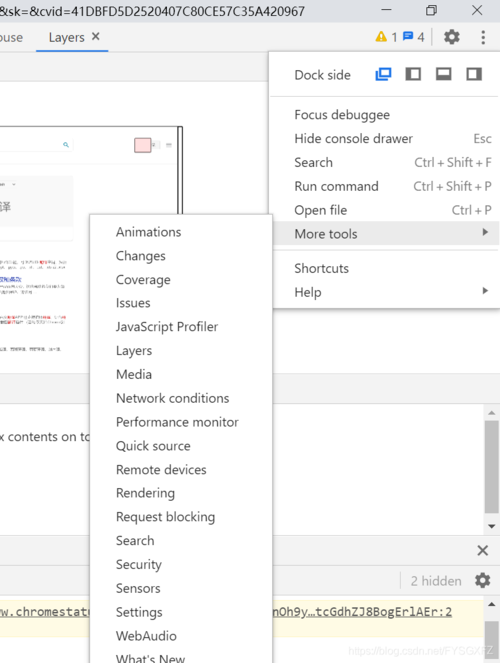
栅格化(raster)通常在CPU中完成,这样的速度缓慢且CPU资源本就稀缺。现在我们有了新的技术可以在GPU中进行栅格化进而增强性能。
Compositing operation
到目前为止,我们还没有在屏幕上绘制单个像素。 我们所拥有的是不同的层(bitmap images),应该以特定的顺序在屏幕上绘制它们。 在合成操作中,这些层被发送到GPU,最后将其绘制在屏幕上。
发送整个图层以进行绘制效率很低,所以每次进行reflow(layout)或repaint时都必须进行此操作。 因此,将一层分解为不同的块(tiles),然后将其绘制在屏幕上。 您还可以在Chrome DevTool 的 Rendering面板中可视化这些块(tiles)。
界面渲染顺序图

这一系列事件也被称为critical rendering path。
Browser engines
创建DOM Tree,CSSOM Tree和处理渲染逻辑的工作是使用浏览器引擎(也称为渲染引擎或布局引擎)完成的。 该浏览器引擎包含所有将网页从HTML代码渲染为屏幕上的实际像素所需要的元素和逻辑。
如果你听到有人在谈论WebKit,那么他们在谈论浏览器引擎。 WebKit被Apple的Safari浏览器使用,并且是Google Chrome浏览器的默认渲染引擎。
Rendering Process in browsers
HTML,CSS或JavaScript,这些语言是由某个实体或某个组织标准化的。 但是,浏览器如何统筹管理它们并且在屏幕上呈现出来没有相关的标准。 Google Chrome浏览器的引擎功能可能与Safari浏览器的引擎功能不同。
因此,很难预测它们在特定浏览器中的渲染顺序及其背后的机制。 但是,HTML5规范已经做出一些努力来标准化渲染过程在理论上应该如何工作,但是浏览器如何遵循此标准完全取决于各家厂商。
尽管存在这些不一致,但仍有一些通用原则被所有浏览器遵循。让我们一起来了解浏览器在屏幕上呈现内容的常用方法以及此过程的生命周期事件。为了理解此过程,我准备了一个小项目来测试不同的渲染方案(下面的链接)。
course-one/browser-rendering-test
Parsing and External Resources
解析的过程就是浏览器引擎不断读取HTML Document并构建DOM Tree的过程。因此这个过程也被称为DOM parsing,处理者也被称为解析器(DOM parser)。
许多浏览器提供DOM parser API构建DOM Tree,DOMParser类的一个实例表示一个DOM解析器,使用parseFromString原型方法,我们可以将原始HTML文本解析为一个DOM Tree。
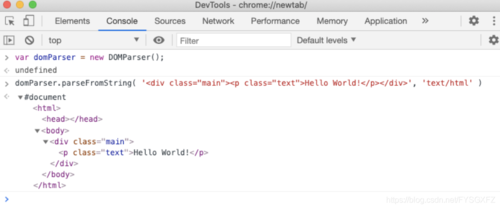
浏览器对网页发出请求,服务器做出响应,其中一些文件的的头部会被设置为Content-Type:text/ HTML,只要在该文本中加载出来字符(某一时刻该文本可能只加载出来了几个字符或者几行字符等等),浏览器就可以开始解析HTML。因此,浏览器可以增量地构建DOM树,一次一个节点。从上到下解析HTML,而不是在中间的任何位置,因为HTML表示一个嵌套的树状结构。
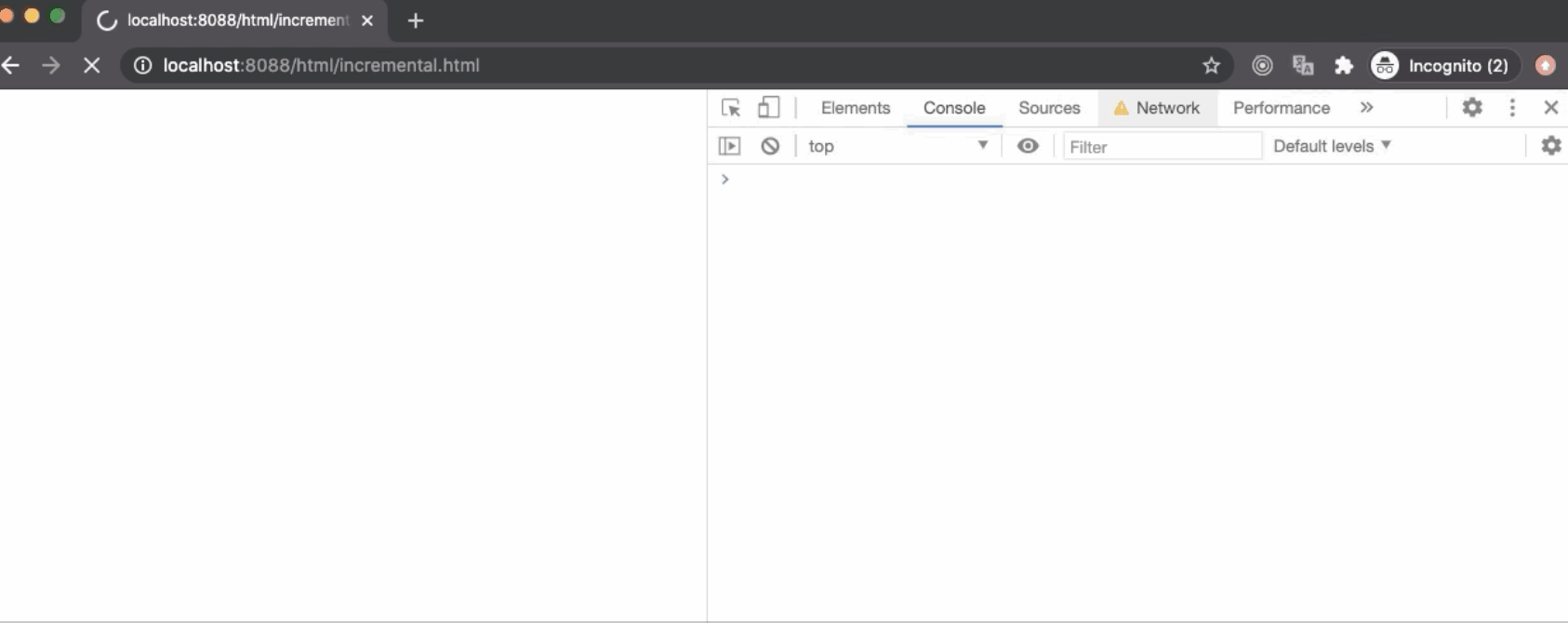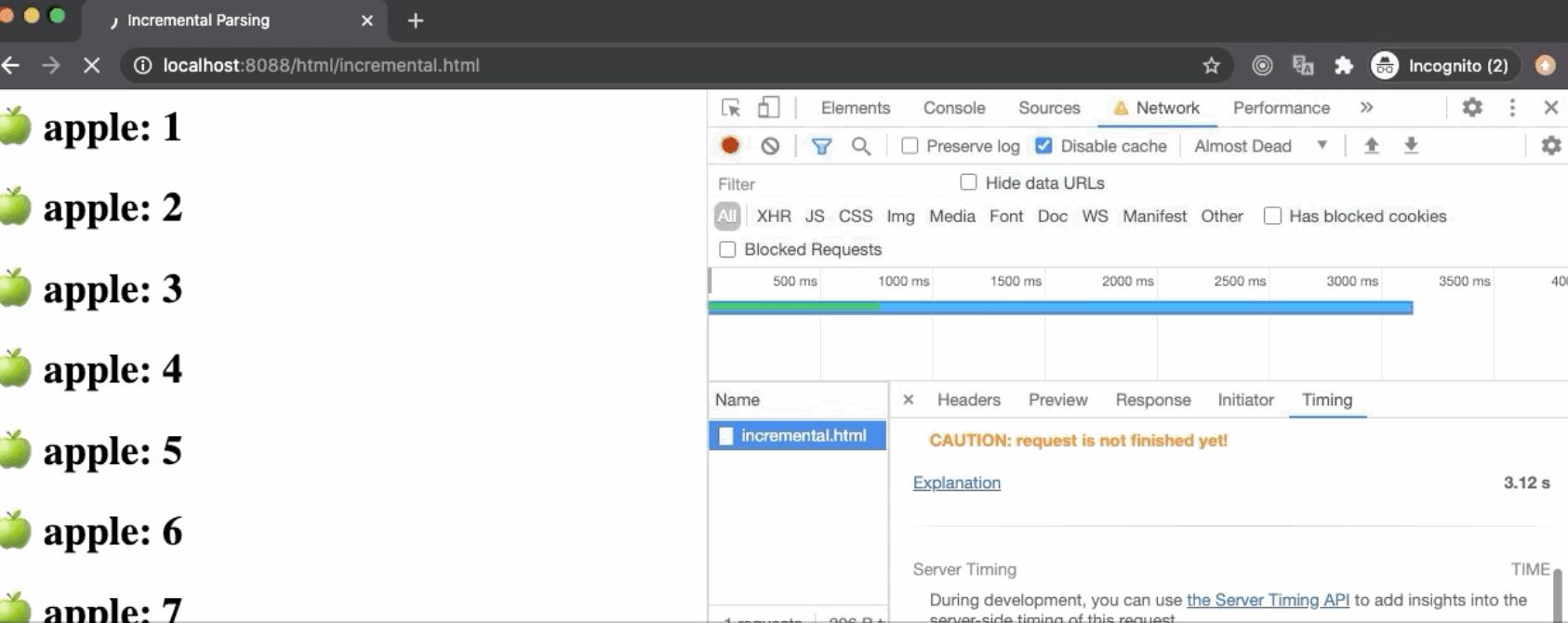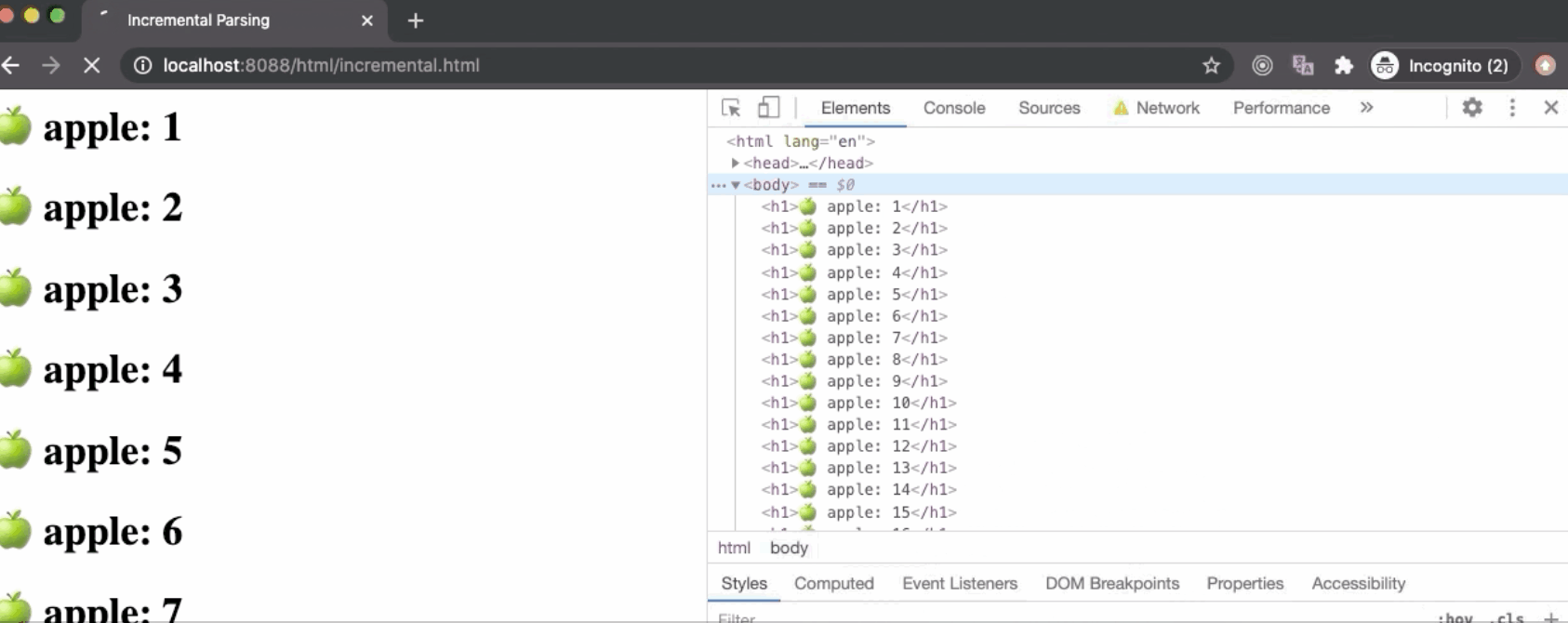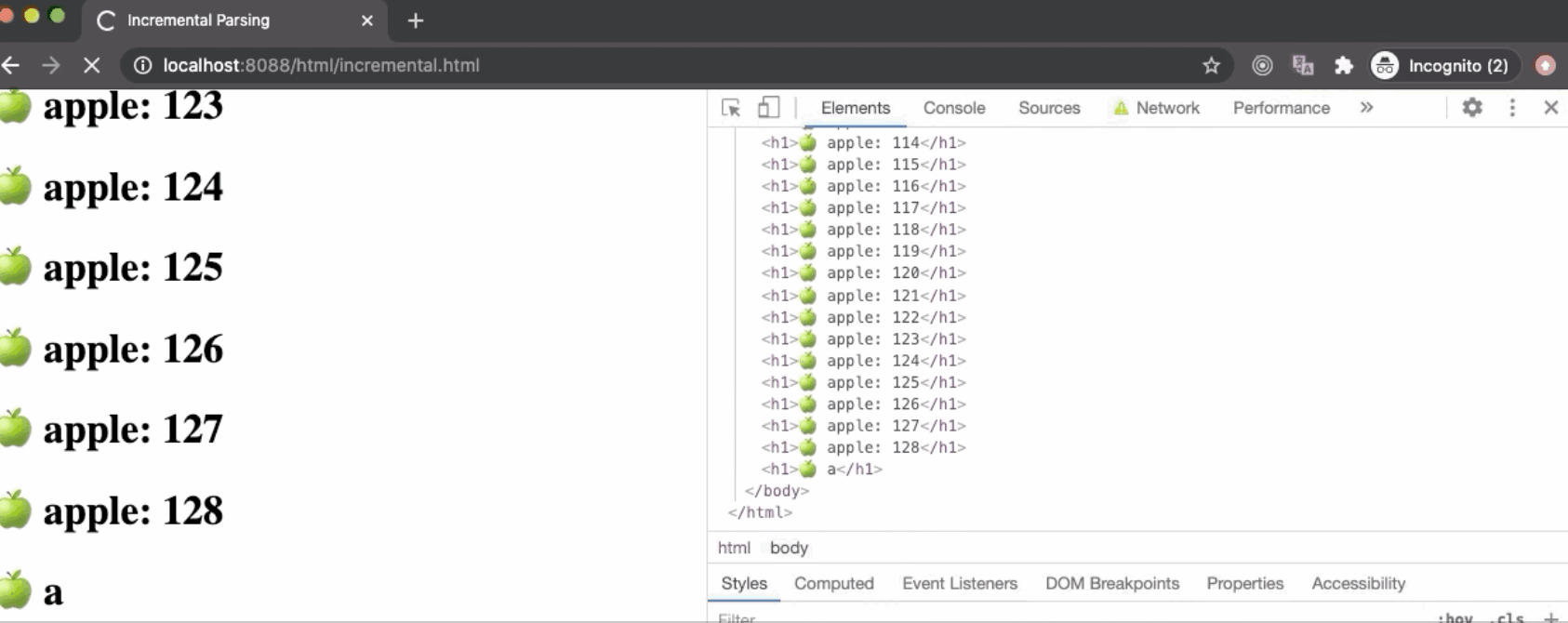
在上面的例子中,我们通过Chrome DevTools限制网速并访问incremental.html,浏览器会花费大量时间去加载文件,然后它将会从文本的第一个字节开始构建DOM Tree并print到界面上。

你可以观察Chrome Devtools中的性能(performance) 面板,你可以看到在Timing面板中发生的一些事件。我们通常称这些事件为“性能衡量标准”(performance metrics)。当这些事件尽可能地靠近彼此并且发生得越早,用户体验就越好。
FP是First Paint的首字母缩写,意思是浏览器开始在屏幕上打印东西的时间(可以简单抽象想象为打印body的背景色的第一个像素)。
FCP是First Contentful Paint的首字母缩写,意思是浏览器呈现文本或图像等内容的第一个像素的时间。LCP是“Largest Contentful Paint的缩写,意思是浏览器渲染大文本或图像的时间。
你可能听说过FMP(first meaningful paint),它也是一个类似于LCP的度量标准,但它已经从Chrome中删除,取而代之的是LCP。
L表示由浏览器在窗口对象上发出的onload事件。类似地,DCL表示在文档对象上发出的DOMContentLoaded事件。
当浏览器遇到外部资源,如一个JavaScript脚本文件< script src = " url " > < /script>,一个CSS样式表文件< link rel = "stylesheet" href = " url " / >,一个img文件< img src = " url " / >或任何其他外部资源,浏览器会在后台下载文件。
其中读者需要了解的也是最重要的是DOM解析通常发生在main thread上。 因此,如果主JavaScript执行线程繁忙,DOM会直到main thread空闲才开始解析。 您可能会问为什么这是如此重要? 因为脚本元素是parse-blocking的。 除脚本(.js)文件请求外,其他外部文件请求(例如图像,样式表,pdf,视频等)都不会阻止DOM构建/解析。
Parser-Blocking Scripts
parser-blocking script是会使HTML停止解析的脚本文件/代码。 当浏览器遇到脚本元素(如果它是嵌入式脚本)时,它将首先执行该脚本,然后继续解析HTML以构造DOM Tree。 因此,所有嵌入式脚本都是parser-blocking的。
如果脚本元素是外部脚本文件,浏览器将开始从主线程下载外部脚本文件,但是它将停止执行主线程,直到完成下载。 这意味着在下载脚本文件之前不能进行DOM解析。
一旦下载了脚本文件,浏览器将首先在主线程上执行下载的脚本文件,然后继续进行DOM解析。如果浏览器再次在HTML中找到另一个脚本元素,它将执行相同的操作。为什么浏览器必须停止DOM解析来下载并执行JavaScript?
因为JavaScript可以在运行时(runtime)访问DOM API,我们可以使用JavaScript访问和操作DOM元素。这就是动态Web框架(dynamic web frameworks,例如React和Angular)的工作方式。但是,如果浏览器并行运行DOM解析和脚本执行,则DOM解析器线程和主线程之间可能存在竞争情况(race conditions,对共享资源的同时访问会出现竞争情况),这就是为什么DOM解析必须在主线程上进行的原因。
但是,在大多数情况下,完全不必在后台下载脚本文件时停止DOM解析。因此,HTML5为我们提供了script标签的async属性。当DOM解析器遇到具有async属性的外部脚本元素时,即使在后台下载脚本文件,也不会停止DOM解析过程。但是,一旦下载了文件,解析将停止并执行脚本。
我们还为script元素提供了defer属性,该属性的作用类似于async属性,但与async属性不同的是,即使文件已完全下载,该脚本也不会立刻执行。解析器解析完所有HTML之后,将执行所有具有defer属性的脚本,这意味着DOM树已完全构建。与异步脚本不同,所有延迟脚本都按照它们在HTML文档(或DOM树)中出现的顺序执行。
所有常规脚本(嵌入式或外部)在停止DOM的构建时都被解析器阻止。在下载完成之前,它们不会阻止解析器执行。下载完成后,它将立即阻止解析器执行。但是,所有延迟脚本(deferred scripts)都是不会阻止解析器的执行,它们在完全构建DOM树之后执行。

在上面的示例中,parser-blocking.html文件在30个元素之后开始加载脚本,这就是为什么浏览器首先会显示30个元素,停止DOM解析并开始加载脚本文件。 第二个脚本文件没有延迟,因为它具有defer属性,它将在DOM树完全构建后执行。
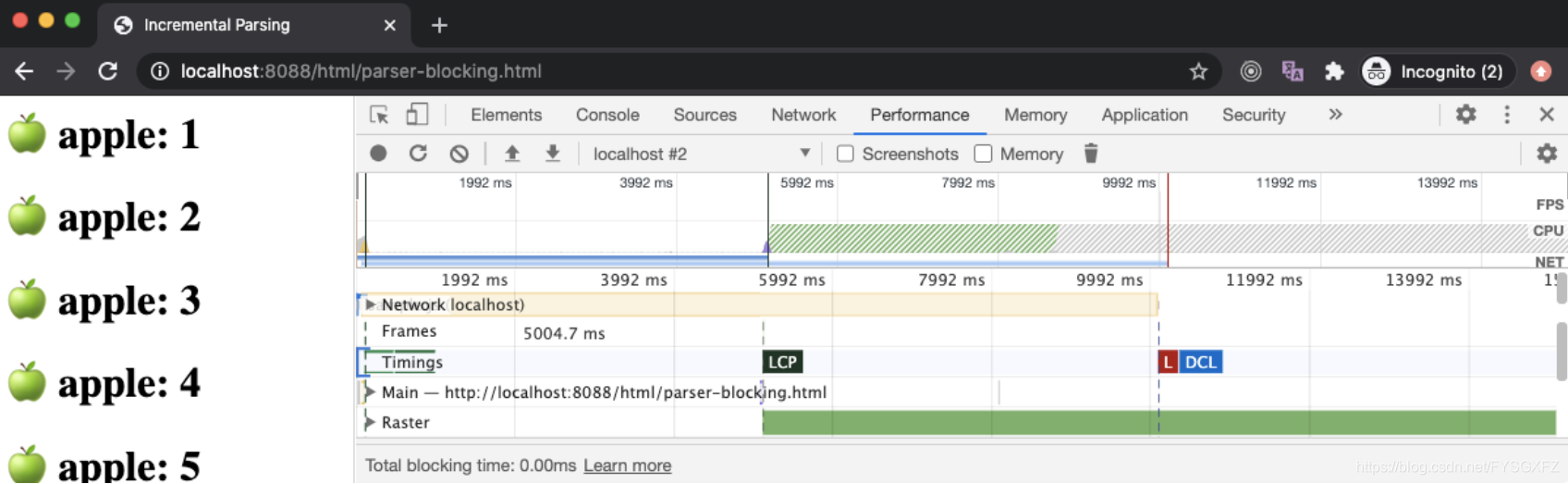
如果我们查看“性能”面板,则FP和FCP会尽可能提前显示,因为只要有一些HTML内容可用,浏览器就会开始构建DOM树,在屏幕上尽可能呈现一些像素。
LCP在5秒钟后发生,因为parser-blocking script将DOM parsing阻止了5秒钟(其下载时间占用5秒钟),并且当DOM解析器被阻止时,屏幕上仅呈现了30个文本元素,这不足命名为 largest paint(根据Google Chrome标准)。 一旦下载并执行了脚本,便会重新进行DOM解析,并在屏幕上呈现大量内容,从而引发LCP事件。
parser blocking 经常和 render blocking 关联起来,但是这两者是不同的,因为DOM Tree没有构建成功之前rendering是不会发生的。
某些浏览器可能包含speculative parsing,其中HTML parsing(而不是DOM Tree construction)被装载到单独的线程中,以便浏览器可以尽量读取诸如link,script,img等元素,并下载这些资源。
如果你有三个脚本文件,最好将这三个文件的加载放在一起。解析第一个脚本的时候,DOM解析器无法读取第二个脚本元素,因此在下载第一个脚本之前,浏览器将无法开始下载第二个脚本。 我们可以使用async标签解决此问题,但这样一来就不能保证异步脚本按顺序执行。
之所以称为推测性解析(speculative parsing),是因为浏览器会猜测将来可能会加载某些特定的资源,因此会在后台将其加载。 但是,如果某些JavaScript处理DOM并使用外部资源操作该元素,则该策略将失败,并且加载过的这些文件将一无是处。
每个浏览器都有自己的策略,因此不能保证何时或是否会进行推测解析。 但是,我们可以要求浏览器使用<link rel =“ preload”>标签提前加载一些资源。
Render-Blocking CSS
我们在实际应用过程中竟然发现CSS也可以阻止DOM解析????真的是这样吗????好吧,为了弄懂其中原理,我们需要了解渲染过程。
浏览器内部的浏览器引擎根据从服务器以文本文档形式接收的HTML文本构造DOM树。同样,它从样式文件(例如,外部CSS文件或HTML中的嵌入式CSS)构造CSSOM Tree。
DOM Tree和CSSOM Tree的构造都发生在主线程上,并且这些树可以同时构造。最终他们会共同形成Render Tree,用于在屏幕上paint内容。Render Tree随着DOM Tree的逐渐构建而逐渐构建。
正如我们所了解的那样,DOM Tree的生成是incremental,这意味着在浏览器读取HTML时,它将向DOM Tree中添加DOM元素。但是CSSOM Tree不是这种情况。与DOM Tree不同,CSSOM Tree的构建不是增量的,必须以特定的方式进行。
当浏览器找到<style>块时,它将解析所有嵌入式CSS并使用新的CSS规则更新CSSOM Tree。之后,它将继续以正常方式解析HTML。内联样式也是如此。但是,当浏览器遇到外部样式表文件时,情况会截然不同。与外部脚本文件不同,外部样式表文件不会阻止解析器执行,因此浏览器可以在后台默默下载,并且DOM解析将继续进行。
但是与HTML文件(用于DOM构建)不同,浏览器不会一次只处理一个字节的样式表文件内容。这是因为浏览器在读取CSS文件时无法逐步构建CSSOM Tree。原因是文件末尾的CSS规则可能会覆盖文件顶部写的CSS规则。
因此,如果浏览器在解析样式表内容时开始逐步构建CSSOM Tree,则由于相同的CSSOM节点将被更新,这会导致一颗CSSOM Tree的多次渲染,因为后面的样式将覆盖前面的样式。如果事实是这样的话,我们在浏览器上加载网页的时候将会看到元素的布局,颜色等样式不断变化,直到某一时刻才稳定下来。由于CSS样式是级联的,因此一项规则更改也会影响许多元素。
因此,浏览器不会增量(incrementally)处理外部CSS文件,并且在处理样式表中的所有CSS规则之后,会立即进行CSSOM Tree更新。 CSSOM树更新完成后,将更新“Render Tree”,然后将其呈现在屏幕上。
CSS也是一种阻止渲染的资源。浏览器发出获取外部样式表的请求后,将停止“Render Tree”构建。因此,关键渲染路径(Critical Rendering Path ---- CRP)会被卡住,在屏幕上不会渲染任何内容,如下所示。但是,在后台下载样式表时,仍在进行DOM树构建。
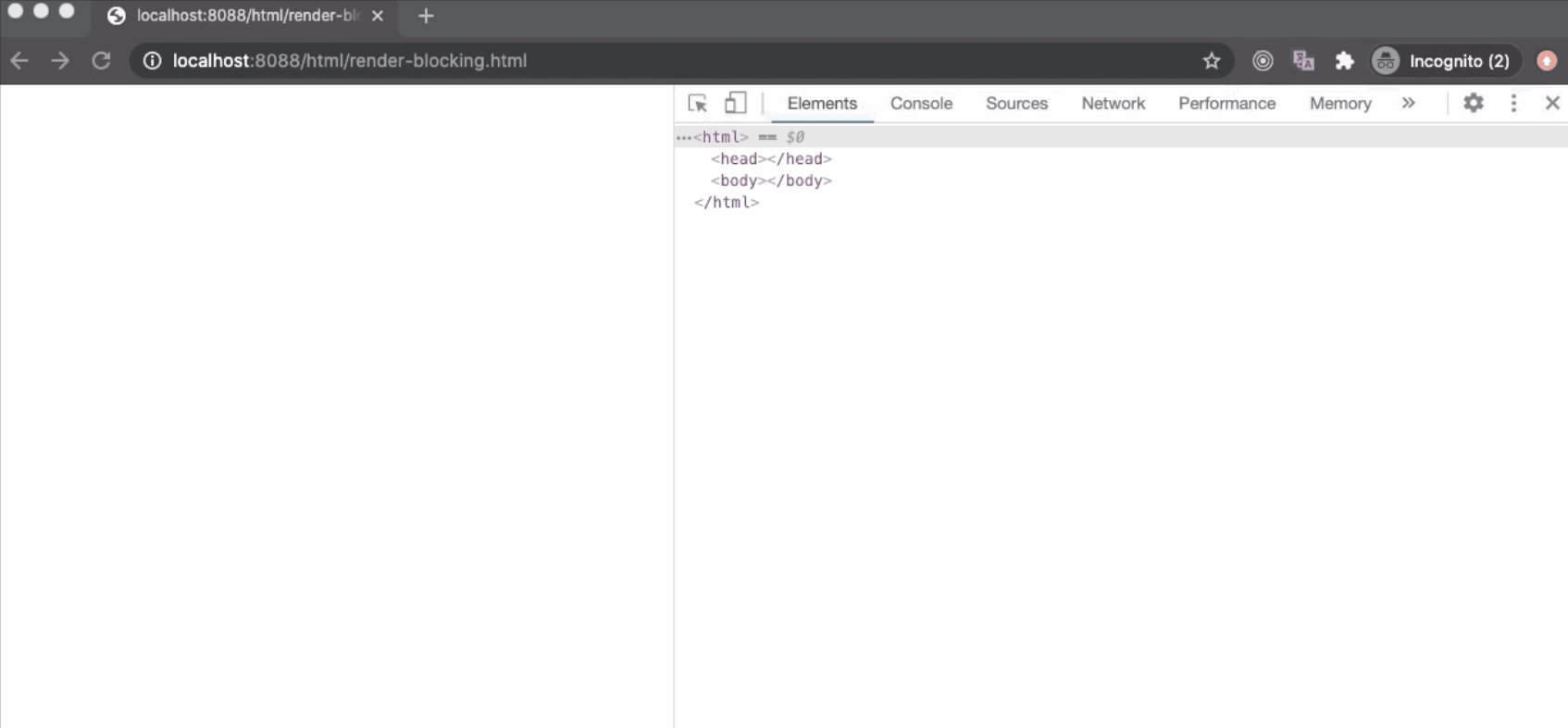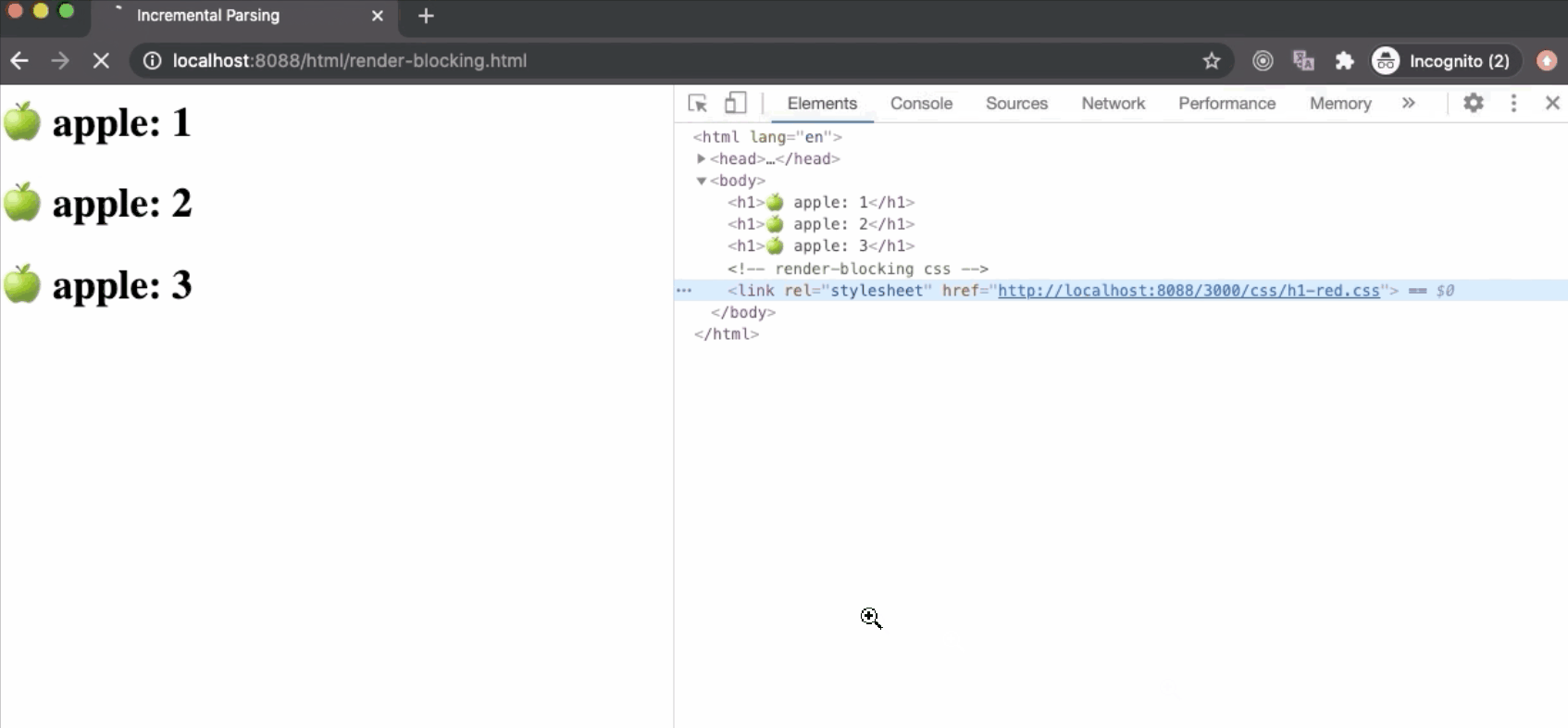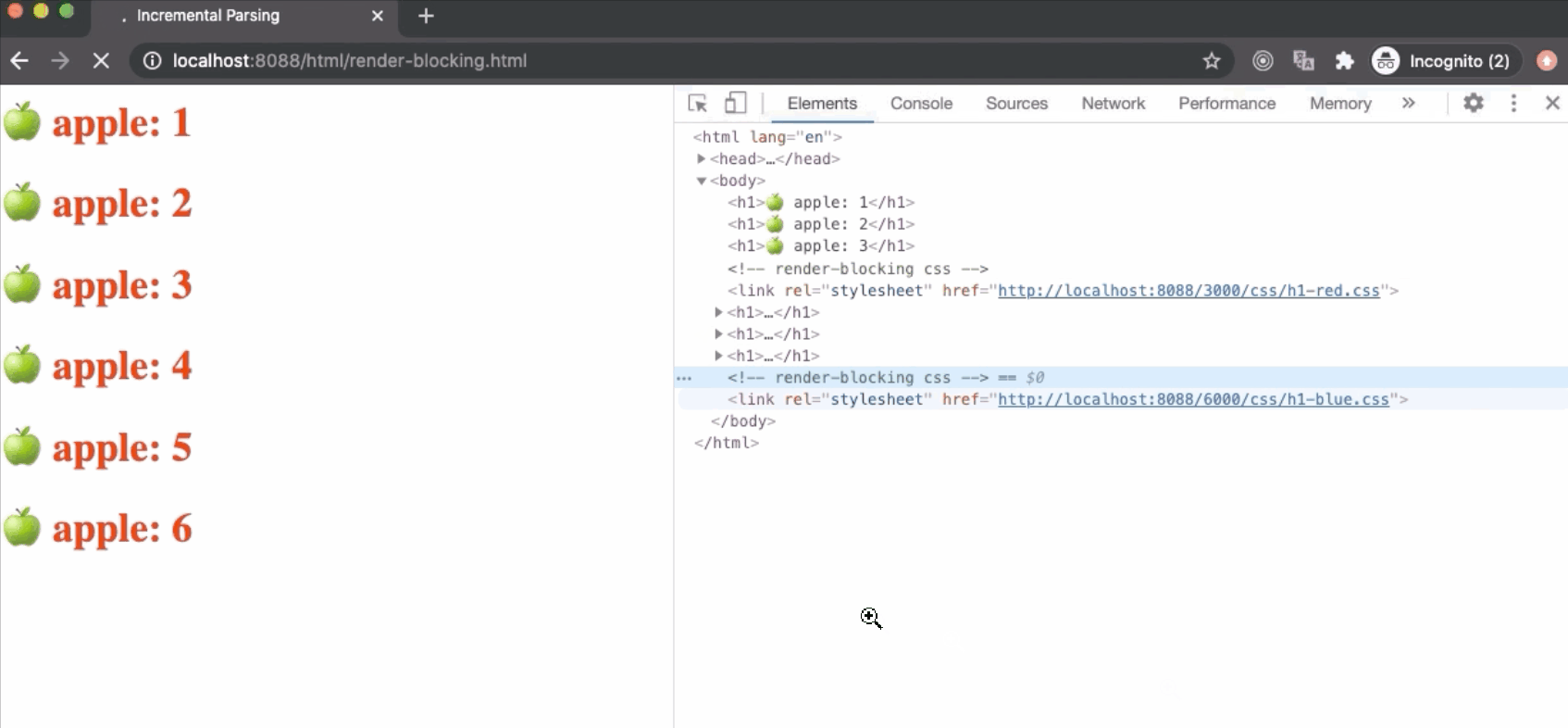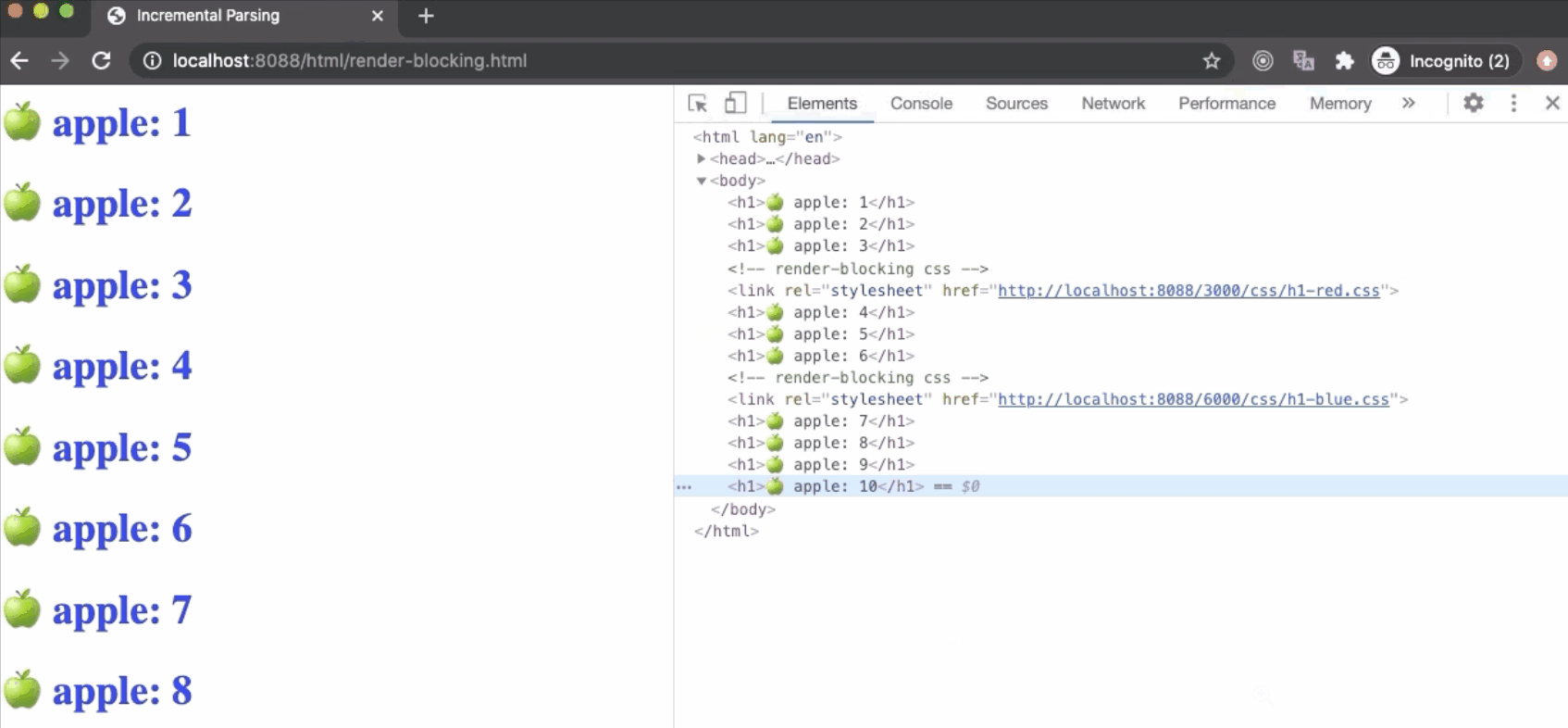
浏览器本来可以使用CSSOM Tree的“旧状态”来生成“Render Tree”,因为解析HTML是逐步的,在屏幕上渲染也是逐步的。但这有很大的缺点,在这种情况下,一旦下载并解析了样式表,并且更新了CSSOM,Render Tree将被更新并呈现在屏幕上。现在,使用“旧状态”样式的CSSOM重新使用“新状态”绘制可能导致出现“无状态”样式内容(Flash of Unstyled Content----FOUC),这对于UX(用户体验)来说是非常不好的。
因此,浏览器将等待,直到样式表被加载并解析。解析了样式表并更新了CSSOM之后,将更新“Rneder Tree”,并且将解除关键渲染路径(CRP)的阻塞,从而在屏幕上绘制“Rneder Tree”。由于这个原因,建议HTML文档尽量在header加载所有外部样式表。
让我们想象一个场景,其中浏览器已经开始解析HTML,并且遇到一个外部样式表文件。它将开始在后台下载文件,阻止关键渲染路径(CRP)并继续进行DOM解析。但是随后它遇到了一个脚本标签,因此它将开始下载外部脚本文件并阻止DOM解析。现在,浏览器处于空闲状态,等待样式表和脚本文件完全下载。
但是如果外部脚本文件已完全下载,而样式表仍在后台下载。浏览器应该执行脚本文件吗?这样做有什么危害吗?
CSSOM提供了一个高级JavaScript API与DOM元素的样式进行交互。例如,您可以使用elem.style.backgroundColor属性读取或更新DOM元素的背景颜色。与elem元素关联的样式对象已经公开了CSSOM API,并且还有许多其他API也可以做到这一点。
由于在后台下载样式表,因此JavaScript仍可以执行,因为主线程没有被装入的样式表阻塞。如果我们的JavaScript程序(通过CSSOM API)访问DOM元素的CSS属性,我们将获得适当的值(根据CSSOM的当前状态)。
但是一旦下载并解析了样式表,CSSOM Tree将会更新,我们的JavaScript现在具有该元素的“旧状态”样式,因为新的CSSOM更新可能会更改该DOM元素的CSS属性。因此,在下载样式表时执行JavaScript是不安全的。
根据HTML5规范,浏览器可以下载脚本文件,但是除非解析了所有以前的样式表,否则它不会执行。当样式表阻止脚本的执行时,它称为脚本阻止样式表(script-blocking stylesheet)或脚本阻止CSS(script-blocking CSS)。

在上面的示例中,script-blocking.html包含一个链接标记(用于外部样式表),后跟一个脚本标记(用于外部JavaScript)。 在这里,脚本的下载速度非常快,没有任何延迟,但是样式表的下载需要6秒钟。 因此,即使脚本已完全下载(如“Network”面板中所见),浏览器也不会立即执行该脚本。 仅在加载样式表之后,我们才能看到脚本记录的Hello World消息。
像async或defer属性使脚本元素成为non-parser-blocking document,也可以使用media属性将外部样式表标记为non-render-blocking。 使用media属性,浏览器可以智能决定何时加载样式表。
Document’s DOMContentLoaded Event
DOMContentLoaded(DCL)事件标记了浏览器何时从现有可用的HTML元素成功构建了完整的DOM Tree。 但是,触发DCL事件涉及许多可变因素。
document.addEventListener( 'DOMContentLoaded', function(e) { console.log( 'DOM is fully parsed!' );
} );如果我们的HTML不包含任何脚本,则不会阻止DOM解析,并且DCL将会在浏览器能够解析整个HTML文档时迅速启动。如果我们有parser-blocking脚本,则DCL必须等待,直到所有parser-blocking脚本都下载并执行。
将样式表应用在图片上时,情况变得有些复杂。即使您没有外部脚本,DCL也会等到所有样式表都加载完毕。由于DCL标志着整个DOM树准备就绪的时间点,但是除非CSSOM也已完全构建,否则DOM Tree将无法安全访问(进而获取样式信息)。因此,大多数浏览器都等到所有外部样式表都加载并解析完毕再触发DCL。
Script-blocking stylesheet显然会延迟DCL。在这种情况下,由于脚本正在等待样式表加载,因此不会构建DOM树。
DCL是网站性能指标之一。我们应该将DCL发生时间优化地尽可能的小。最佳实践之一是在可能的情况下对脚本元素使用defer和async标签,以便在后台下载脚本时浏览器可以执行其他操作。其次,我们应该优化the script-blocking and render-blocking stylesheets。
Window’s load event
JavaScript可以阻止DOM树的生成,但是外部样式表和文件(例如图像,视频等)却并非如此。
DOMContentLoaded事件标记了完全构建DOM树并且可以安全访问的时间点,window.onload事件标记了外部样式表和文件、Web应用程序已完成下载的时间点。
window.addEventListener( 'load', function(e) { console.log( 'Page is fully loaded!' );
} )
在上面的示例中,rendering.html文件的头部具有一个外部样式表,下载该样式表大约需要5秒钟。该样式表将阻止接下来任何会被呈现的内容(因为它阻止了CRP),因此FP和FCP在5秒钟后发生
此后,我们有一个img元素,完全加载大约需要10秒钟。因此,浏览器将继续在后台下载此文件,并继续进行DOM解析和渲染(因为外部图像资源既不会阻止解析器也不会阻止渲染)。
接下来,我们有三个外部JavaScript文件,分别需要3秒钟,6秒钟和9秒钟进行下载。它们不是异步的,这意味着总加载时间应接近18秒,因为在执行前一个脚本之前,后续脚本不会开始下载。但是,查看DCL事件,我们的浏览器似乎已经使用推测性策略下载了脚本文件,因此总加载时间接近9秒。
最后一个可能影响DCL的文件是最后一个脚本文件,其加载时间为9秒(因为样式表已在5秒内下载完毕),因此DCL事件发生在9.1秒左右。
我们还拥有另一个外部资源,即图像文件,它一直在后台加载。完全下载(需要10秒)后,所以在10.2秒后会触发窗口的加载事件,这表明网页(应用程序)已完全加载。
-
Java编程面试题详解与解答12-25
-
TS基础知识详解:初学者必看教程12-25
-
2024面试题解析与攻略:从零开始的面试准备指南12-25
-
数据结构与算法学习:新手入门教程12-25
-
初学者必备:订单系统资料详解与实操教程12-25
-
内网穿透资料入门教程12-24
-
微服务资料入门指南12-24
-
微信支付系统资料入门教程12-24
-
微信支付资料详解:新手入门指南12-24
-
Hbase资料:新手入门教程12-24
-
Java部署资料12-24
-
Java订单系统资料:新手入门教程12-24
-
Java分布式资料入门教程12-24
-
Java监控系统资料详解与入门教程12-24
-
Java就业项目资料:新手入门必备教程12-24
