Redis教程
基于Redis Cluster的分布式锁实现以互斥方式操作共享资源


今天要说的技术方案也是有一定项目背景的。在上一个项目中,我们需要对一个redis集群中过期的key进行处理,这是一个分布式系统,考虑到高可用性,需要具备过期处理功能的服务有多个副本,这样我们就要求在同一时间内仅有一个副本可以对过期的key进行处理,如果该副本挂掉,系统会在其他副本中再挑选出一个来处理过期的key。
很显然,这里涉及到一个选主(leader election)的过程。每当涉及选主,很多人就会想到一些高大上的分布式一致性/共识算法,比如:raft、paxos等。当然使用这些算法自然没有问题,但是也给系统徒增了很多复杂性。能否有一些更简单直接的方案呢?我们已经有了一个redis集群,是否可以利用redis集群的能力来完成这一点呢?
Redis原生并没有提供leader election算法,但Redis作者提供了分布式锁的算法,也就是说我们可以用分布式锁来实现一个简单的选主功能,见下图:
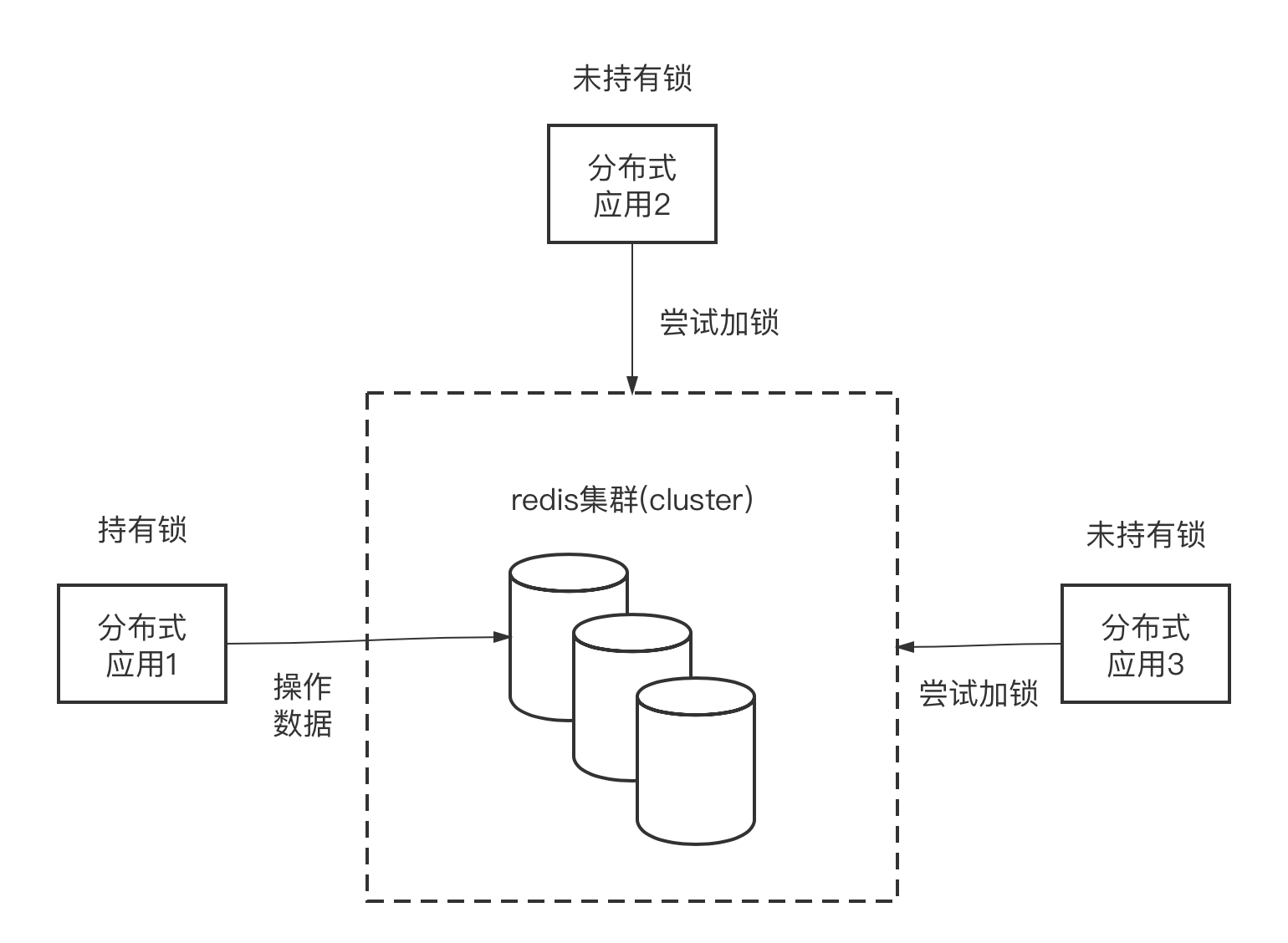
在上图中我们看到,只有持有锁的服务才具备操作数据的资格,也就是说持有锁的服务的角色是leader,而其他服务则继续尝试去持有锁,它们是follower的角色。
1. 基于单节点redis的分布式锁
在redis官方有关分布式锁算法的介绍页面中,作者给出了各种编程语言的推荐实现,而Go语言的推荐实现仅redsync这一种。在这篇短文中,我们就来使用redsync实现基于Redis分布式锁的选主方案。
在Go生态中,连接和操作redis的主流go客户端库有go-redis和redigo。最新的redsync版本底层redis driver既支持go-redis,也支持redigo,我个人日常使用最多的是go-redis这个客户端,这里我们就用go-redis。
redsync github主页中给出的例子是基于单redis node的分布式锁示例。下面我们也先以单redis节点来看看如何通过Redis的分布式锁实现我们的业务逻辑:
// github.com/bigwhite/experiments/blob/master/redis-cluster-distributed-lock/standalone/main.go
1 package main
2
3 import (
4 "context"
5 "log"
6 "os"
7 "os/signal"
8 "sync"
9 "sync/atomic"
10 "syscall"
11 "time"
12
13 goredislib "github.com/go-redis/redis/v8"
14 "github.com/go-redsync/redsync/v4"
15 "github.com/go-redsync/redsync/v4/redis/goredis/v8"
16 )
17
18 const (
19 redisKeyExpiredEventSubj = `__keyevent@0__:expired`
20 )
21
22 var (
23 isLeader int64
24 m atomic.Value
25 id string
26 mutexName = "the-year-of-the-ox-2021"
27 )
28
29 func init() {
30 if len(os.Args) < 2 {
31 panic("args number is not correct")
32 }
33 id = os.Args[1]
34 }
35
36 func tryToBecomeLeader() (bool, func() (bool, error), error) {
37 client := goredislib.NewClient(&goredislib.Options{
38 Addr: "localhost:6379",
39 })
40 pool := goredis.NewPool(client)
41 rs := redsync.New(pool)
42
43 mutex := rs.NewMutex(mutexName)
44
45 if err := mutex.Lock(); err != nil {
46 client.Close()
47 return false, nil, err
48 }
49
50 return true, func() (bool, error) {
51 return mutex.Unlock()
52 }, nil
53 }
54
55 func doElectionAndMaintainTheStatus(quit <-chan struct{}) {
56 ticker := time.NewTicker(time.Second * 5)
57 var err error
58 var ok bool
59 var cf func() (bool, error)
60
61 c := goredislib.NewClient(&goredislib.Options{
62 Addr: "localhost:6379",
63 })
64 defer c.Close()
65 for {
66 select {
67 case <-ticker.C:
68 if atomic.LoadInt64(&isLeader) == 0 {
69 ok, cf, err = tryToBecomeLeader()
70 if ok {
71 log.Printf("prog-%s become leader successfully\n", id)
72 atomic.StoreInt64(&isLeader, 1)
73 defer cf()
74 }
75 if !ok || err != nil {
76 log.Printf("prog-%s try to become leader failed: %s\n", id, err)
77 }
78 } else {
79 log.Printf("prog-%s is the leader\n", id)
80 // update the lock live time and maintain the leader status
81 c.Expire(context.Background(), mutexName, 8*time.Second)
82 }
83 case <-quit:
84 return
85 }
86 }
87 }
88
89 func doExpire(quit <-chan struct{}) {
90 // subscribe the expire event of redis
91 c := goredislib.NewClient(&goredislib.Options{
92 Addr: "localhost:6379"})
93 defer c.Close()
94
95 ctx := context.Background()
96 pubsub := c.Subscribe(ctx, redisKeyExpiredEventSubj)
97 _, err := pubsub.Receive(ctx)
98 if err != nil {
99 log.Printf("prog-%s subscribe expire event failed: %s\n", id, err)
100 return
101 }
102 log.Printf("prog-%s subscribe expire event ok\n", id)
103
104 // Go channel which receives messages from redis db
105 ch := pubsub.Channel()
106 for {
107 select {
108 case event := <-ch:
109 key := event.Payload
110 if atomic.LoadInt64(&isLeader) == 0 {
111 break
112 }
113 log.Printf("prog-%s 收到并处理一条过期消息[key:%s]", id, key)
114 case <-quit:
115 return
116 }
117 }
118 }
119
120 func main() {
121 var wg sync.WaitGroup
122 wg.Add(2)
123 var quit = make(chan struct{})
124
125 go func() {
126 doElectionAndMaintainTheStatus(quit)
127 wg.Done()
128 }()
129 go func() {
130 doExpire(quit)
131 wg.Done()
132 }()
133
134 c := make(chan os.Signal, 1)
135 signal.Notify(c, syscall.SIGINT, syscall.SIGTERM)
136 _ = <-c
137 close(quit)
138 log.Printf("recv exit signal...")
139 wg.Wait()
140 log.Printf("program exit ok")
141 }
上面示例代码比较长,但它很完整。我们一点点来看。
首先,我们看120~141行的main函数结构。在这个函数中,我们创建了两个新goroutine,main goroutine通过sync.WaitGroup等待这两个子goroutine的退出并使用quit channel模式(关于goroutine的并发模式的详解,可以参考我的专栏文章《Go并发模型和常见并发模式》)在收到系统信号(关于signal包的使用,请参见我的专栏文章《小心被kill!不要忽略对系统信号的处理》)后通知两个子goroutine退出。
接下来,我们逐个看两个子goroutine的执行逻辑。第一个goroutine执行的是doElectionAndMaintainTheStatus函数。该函数会持续尝试去持有分布式锁(tryToBecomeLeader),一旦持有,它就变成了分布式系统中的leader角色;成为leader角色的副本会保持其角色状态(见81行)。
尝试持有分布式锁并成为leader是tryToBecomeLeader函数的主要职责,该函数直接使用了redsync包的算法,并利用与redis node建立的连接(NewClient),尝试建立并持有分布式锁“the-year-of-the-ox-2021”。我们使用的是默认的锁属性,从redsync包的NewMutex方法源码,我们能看到锁默认属性如下:
// github.com/go-redsync/redsync/redsync.go
// NewMutex returns a new distributed mutex with given name.
func (r *Redsync) NewMutex(name string, options ...Option) *Mutex {
m := &Mutex{
name: name,
expiry: 8 * time.Second,
tries: 32,
delayFunc: func(tries int) time.Duration { return 500 * time.Millisecond },
genValueFunc: genValue,
factor: 0.01,
quorum: len(r.pools)/2 + 1,
pools: r.pools,
}
for _, o := range options {
o.Apply(m)
}
return m
}
我们看到锁有一个过期时间属性(expiry),过期时间默认仅有8秒。问题来了:一旦锁过期了,那么情况会怎样?事实是一旦锁过期掉,在leader尚未解锁时,其follower也会加锁成功,因为原锁的key已经因过期而被删除掉了。长此以往,整个分布式系统就会存在多个自视为leader的进程,整个处理逻辑就乱了!
解决这个问题至少可以有三种方案:
- 方案1:将锁的expiry设置的很长,长到一旦某个服务持有了锁,不需担心锁过期的问题;
- 方案2:在所的默认expiry到期之前解锁,所有服务重新竞争锁;
- 方案3:一旦某个服务持有了锁,则需要定期重设锁的expiry时间,保证锁不会过期,直到该服务主动执行unlock。
方案1的问题在于,一旦持有锁的leader因意外异常退出并且尚未unlock,那么由于锁的过期时间超级长,其他follower依然无法持有锁而变成下一任leader,导致整个分布式系统的leader缺失,业务逻辑无法继续进行;
方案2其实是基于Redis分布式锁的常规使用方式,但对于像我这里的业务场景,频繁lock和unlock没必要,我只需要保证系统中有一个leader一直在处理过期event即可,在服务间轮流处理并非我的需求。但这个方案是一个可行的方案,代码逻辑清晰也简单。
方案3则是非常适合我的业务场景的方案,持有锁的leader通过定期(<8s)的更新锁的过期时间来保证锁的有效性,这样避免了leader频繁切换。这里我们就使用了这一方案,见78~82行,我们在定时器的帮助下,定期重新设置了锁的过期时间(8s)。
在上述示例代码中,我们用一个变量isLeader来标识该服务是否持有了锁,由于该变量被多个goroutine访问和修改,因此我们通过atomic包实现对其的原子访问以避免出现race问题。
最后,我们说说这段示例承载的业务逻辑(doExpire函数)。真正的业务逻辑由doExpire函数实现。它通过监听redis 0号库的key空间的过期事件实现对目标key的过期处理(这里并未体现这一点)。
subscribe的subject字符串为**keyevent@0:expired**,这个字符串的组成含义可以参考redis官方对notifications的说明,这里的字串表明我们要监听key事件,在0号数据库,事件类型是key过期。
当在0号数据库有key过期后,我们的订阅channel(105行)就会收到一个事件,通过event的Payload我们可以得到key的名称,后续我们可以根据key的名字来过滤掉我们不关心的key,而仅对期望的key做相应处理。
在默认配置下, redis的通知功能处于关闭状态。我们需要通过命令或在redis.conf中开启这一功能。
$redis-cli 127.0.0.1:6379> config set notify-keyspace-events KEx OK
到这里,我们已经搞清楚了上面示例代码的原理,下面我们就来真实运行一次上面的代码,我们编译上面代码并启动三个实例:
$go build main.go $./main 1 $./main 2 $./main 3
由于**./main 1**先启动,因此第一个启动的服务一般会先成为leader:
$main 1 2021/02/11 05:43:15 prog-1 subscribe expire event ok 2021/02/11 05:43:20 prog-1 become leader successfully 2021/02/11 05:43:25 prog-1 is the leader 2021/02/11 05:43:30 prog-1 is the leader
而其他两个服务会定期尝试去持有锁:
$main 2 2021/02/11 05:43:17 prog-2 subscribe expire event ok 2021/02/11 05:43:37 prog-2 try to become leader failed: redsync: failed to acquire lock 2021/02/11 05:43:53 prog-2 try to become leader failed: redsync: failed to acquire lock $main 3 2021/02/11 05:43:18 prog-3 subscribe expire event ok 2021/02/11 05:43:38 prog-3 try to become leader failed: redsync: failed to acquire lock 2021/02/11 05:43:54 prog-3 try to become leader failed: redsync: failed to acquire lock
这时我们通过redis-cli在0号数据库中创建一个key1,过期时间5s:
$redis-cli 127.0.0.1:6379> setex key1 5 value1 OK
5s后,我们会在prog-1这个服务实例的输出日志中看到如下内容:
2021/02/11 05:43:50 prog-1 is the leader 2021/02/11 05:43:53 prog-1 收到并处理一条过期消息[key:key1] 2021/02/11 05:43:55 prog-1 is the leader
接下来,我们停掉prog-1:
2021/02/11 05:44:00 prog-1 is the leader ^C2021/02/11 05:44:01 recv exit signal... redis: 2021/02/11 05:44:01 pubsub.go:168: redis: discarding bad PubSub connection: read tcp [::1]:56594->[::1]:6379: use of closed network connection 2021/02/11 05:44:01 program exit ok
在停掉prog-1后的瞬间,prog-2成功持有了锁,并成为leader:
2021/02/11 05:44:01 prog-2 become leader successfully 2021/02/11 05:44:01 prog-2 is the leader
我们再通过redis-cli在0号数据库中创建一个key2,过期时间5s:
$redis-cli 127.0.0.1:6379> setex key2 5 value2 OK
5s后,我们会在prog-2这个服务实例的输出日志中看到如下内容:
2021/02/11 05:44:17 prog-2 is the leader 2021/02/11 05:44:19 prog-2 收到并处理一条过期消息[key:key2] 2021/02/11 05:44:22 prog-2 is the leader
从运行的结果来看,该分布式系统的运行逻辑是符合我们的设计预期的。
2. 基于redis集群的分布式锁
上面,我们实现了基于单个redis节点的分布式锁的选主功能。在生产环境,我们很少会使用单节点的Redis,通常会使用Redis集群以保证高可用性。
最新的redsync已经支持了redis cluster(基于go-redis)。和单节点唯一不同的是,我们传递给redsync的pool所使用的与redis的连接由Client类型变为了ClusterClient类型:
// github.com/bigwhite/experiments/blob/master/redis-cluster-distributed-lock/cluster/v1/main.go
const (
redisClusterMasters = "localhost:30001,localhost:30002,localhost:30003"
)
func main() {
... ...
client := goredislib.NewClusterClient(&goredislib.ClusterOptions{
Addrs: strings.Split(redisClusterMasters, ",")})
defer client.Close()
... ...
}
我们在本地启动的redis cluster,三个master的地址分别为:localhost:30001、localhost:30002和localhost:30003。我们将master的地址组成一个逗号分隔的常量redisClusterMasters。
我们对上面单节点的代码做了改进,将Redis连接的创建放在了main中,并将client连接作为参数传递给各个goroutine的运行函数。下面是cluster版示例代码完整版(v1):
// github.com/bigwhite/experiments/blob/master/redis-cluster-distributed-lock/cluster/v1/main.go
1 package main
2
3 import (
4 "context"
5 "log"
6 "os"
7 "os/signal"
8 "strings"
9 "sync"
10 "sync/atomic"
11 "syscall"
12 "time"
13
14 goredislib "github.com/go-redis/redis/v8"
15 "github.com/go-redsync/redsync/v4"
16 "github.com/go-redsync/redsync/v4/redis/goredis/v8"
17 )
18
19 const (
20 redisKeyExpiredEventSubj = `__keyevent@0__:expired`
21 redisClusterMasters = "localhost:30001,localhost:30002,localhost:30003"
22 )
23
24 var (
25 isLeader int64
26 m atomic.Value
27 id string
28 mutexName = "the-year-of-the-ox-2021"
29 )
30
31 func init() {
32 if len(os.Args) < 2 {
33 panic("args number is not correct")
34 }
35 id = os.Args[1]
36 }
37
38 func tryToBecomeLeader(client *goredislib.ClusterClient) (bool, func() (bool, error), error) {
39 pool := goredis.NewPool(client)
40 rs := redsync.New(pool)
41
42 mutex := rs.NewMutex(mutexName)
43
44 if err := mutex.Lock(); err != nil {
45 return false, nil, err
46 }
47
48 return true, func() (bool, error) {
49 return mutex.Unlock()
50 }, nil
51 }
52
53 func doElectionAndMaintainTheStatus(c *goredislib.ClusterClient, quit <-chan struct{}) {
54 ticker := time.NewTicker(time.Second * 5)
55 var err error
56 var ok bool
57 var cf func() (bool, error)
58
59 for {
60 select {
61 case <-ticker.C:
62 if atomic.LoadInt64(&isLeader) == 0 {
63 ok, cf, err = tryToBecomeLeader(c)
64 if ok {
65 log.Printf("prog-%s become leader successfully\n", id)
66 atomic.StoreInt64(&isLeader, 1)
67 defer cf()
68 }
69 if !ok || err != nil {
70 log.Printf("prog-%s try to become leader failed: %s\n", id, err)
71 }
72 } else {
73 log.Printf("prog-%s is the leader\n", id)
74 // update the lock live time and maintain the leader status
75 c.Expire(context.Background(), mutexName, 8*time.Second)
76 }
77 case <-quit:
78 return
79 }
80 }
81 }
82
83 func doExpire(c *goredislib.ClusterClient, quit <-chan struct{}) {
84 // subscribe the expire event of redis
85 ctx := context.Background()
86 pubsub := c.Subscribe(ctx, redisKeyExpiredEventSubj)
87 _, err := pubsub.Receive(ctx)
88 if err != nil {
89 log.Printf("prog-%s subscribe expire event failed: %s\n", id, err)
90 return
91 }
92 log.Printf("prog-%s subscribe expire event ok\n", id)
93
94 // Go channel which receives messages from redis db
95 ch := pubsub.Channel()
96 for {
97 select {
98 case event := <-ch:
99 key := event.Payload
100 if atomic.LoadInt64(&isLeader) == 0 {
101 break
102 }
103 log.Printf("prog-%s 收到并处理一条过期消息[key:%s]", id, key)
104 case <-quit:
105 return
106 }
107 }
108 }
109
110 func main() {
111 var wg sync.WaitGroup
112 wg.Add(2)
113 var quit = make(chan struct{})
114 client := goredislib.NewClusterClient(&goredislib.ClusterOptions{
115 Addrs: strings.Split(redisClusterMasters, ",")})
116 defer client.Close()
117
118 go func() {
119 doElectionAndMaintainTheStatus(client, quit)
120 wg.Done()
121 }()
122 go func() {
123 doExpire(client, quit)
124 wg.Done()
125 }()
126
127 c := make(chan os.Signal, 1)
128 signal.Notify(c, syscall.SIGINT, syscall.SIGTERM)
129 _ = <-c
130 close(quit)
131 log.Printf("recv exit signal...")
132 wg.Wait()
133 log.Printf("program exit ok")
134 }
和单一节点一样,我们运行三个服务实例:
$go build main.go $main 1 2021/02/11 09:49:16 prog-1 subscribe expire event ok 2021/02/11 09:49:22 prog-1 become leader successfully 2021/02/11 09:49:26 prog-1 is the leader 2021/02/11 09:49:31 prog-1 is the leader 2021/02/11 09:49:36 prog-1 is the leader ... ... $main 2 2021/02/11 09:49:19 prog-2 subscribe expire event ok 2021/02/11 09:49:40 prog-2 try to become leader failed: redsync: failed to acquire lock 2021/02/11 09:49:55 prog-2 try to become leader failed: redsync: failed to acquire lock ... ... $main 3 2021/02/11 09:49:31 prog-3 subscribe expire event ok 2021/02/11 09:49:52 prog-3 try to become leader failed: redsync: failed to acquire lock 2021/02/11 09:50:07 prog-3 try to become leader failed: redsync: failed to acquire lock ... ...
我们看到基于Redis集群版的分布式锁也生效了!prog-1成功持有锁并成为leader! 接下来我们再来看看对过期key事件的处理!
我们通过下面命令让redis-cli连接到集群中的所有节点并设置每个节点开启key空间的事件通知:
三主: $redis-cli -c -h localhost -p 30001 localhost:30001> config set notify-keyspace-events KEx OK $redis-cli -c -h localhost -p 30002 localhost:30002> config set notify-keyspace-events KEx OK $redis-cli -c -h localhost -p 30003 localhost:30003> config set notify-keyspace-events KEx OK 三从: $redis-cli -c -h localhost -p 30004 localhost:30004> config set notify-keyspace-events KEx OK $redis-cli -c -h localhost -p 30005 localhost:30005> config set notify-keyspace-events KEx OK $redis-cli -c -h localhost -p 30006 localhost:30006> config set notify-keyspace-events KEx OK
在node1节点上,我们set一个有效期为5s的key:key1:
localhost:30001> setex key1 5 value1 -> Redirected to slot [9189] located at 127.0.0.1:30002 OK
等待5s后,我们的leader:prog-1并没有如预期那样受到expire通知! 这是怎么回事呢?追本溯源,我们查看一下redis官方文档关于notifications的说明,我们在文档最后一段找到如下描述:
Events in a cluster Every node of a Redis cluster generates events about its own subset of the keyspace as described above. However, unlike regular Pub/Sub communication in a cluster, events' notifications are not broadcasted to all nodes. Put differently, keyspace events are node-specific. This means that to receive all keyspace events of a cluster, clients need to subscribe to each of the nodes.
这段话大致意思是Redis集群中的每个redis node都有自己的keyspace,事件通知不会被广播到集群内的所有节点,即keyspace的事件是node相关的。如果要接收一个集群中的所有keyspace的event,那客户端就需要Subcribe集群内的所有节点。我们来改一下代码,形成v2版(考虑到篇幅就不列出所有代码了,仅列出相对于v1版变化的代码):
// github.com/bigwhite/experiments/blob/master/redis-cluster-distributed-lock/cluster/v2/main.go
... ...
19 const (
20 redisKeyExpiredEventSubj = `__keyevent@0__:expired`
21 redisClusterMasters = "localhost:30001,localhost:30002,localhost:30003,localhost:30004,localhost:30005,localhost:30006"
22 )
... ...
83 func doExpire(quit <-chan struct{}) {
84 var ch = make(chan *goredislib.Message)
85 nodes := strings.Split(redisClusterMasters, ",")
86
87 for _, node := range nodes {
88 node := node
89 go func(quit <-chan struct{}) {
90 c := goredislib.NewClient(&goredislib.Options{
91 Addr: node})
92 defer c.Close()
93
94 // subscribe the expire event of redis
95 ctx := context.Background()
96 pubsub := c.Subscribe(ctx, redisKeyExpiredEventSubj)
97 _, err := pubsub.Receive(ctx)
98 if err != nil {
99 log.Printf("prog-%s subscribe expire event of node[%s] failed: %s\n",
100 id, node, err)
101 return
102 }
103 log.Printf("prog-%s subscribe expire event of node[%s] ok\n", id, node)
104
105 // Go channel which receives messages from redis db
106 pch := pubsub.Channel()
107
108 for {
109 select {
110 case event := <-pch:
111 ch <- event
112 case <-quit:
113 return
114 }
115 }
116 }(quit)
117 }
118 for {
119 select {
120 case event := <-ch:
121 key := event.Payload
122 if atomic.LoadInt64(&isLeader) == 0 {
123 break
124 }
125 log.Printf("prog-%s 收到并处理一条过期消息[key:%s]", id, key)
126 case <-quit:
127 return
128 }
129 }
130 }
131
132 func main() {
133 var wg sync.WaitGroup
134 wg.Add(2)
135 var quit = make(chan struct{})
136 client := goredislib.NewClusterClient(&goredislib.ClusterOptions{
137 Addrs: strings.Split(redisClusterMasters, ",")})
138 defer client.Close()
139
140 go func() {
141 doElectionAndMaintainTheStatus(client, quit)
142 wg.Done()
143 }()
144 go func() {
145 doExpire(quit)
146 wg.Done()
147 }()
148
149 c := make(chan os.Signal, 1)
150 signal.Notify(c, syscall.SIGINT, syscall.SIGTERM)
151 _ = <-c
152 close(quit)
153 log.Printf("recv exit signal...")
154 wg.Wait()
155 log.Printf("program exit ok")
156 }
在这个新版代码中,我们在每个新goroutine中实现对redis一个节点的Subscribe,并将收到的Event notifications通过“扇入”模式(更多关于并发扇入模式的内容,可以参考我的Go技术专栏文章《Go并发模型和常见并发模式》)统一写入到运行doExpire的goroutine中做统一处理。
我们再来运行一下这个示例,并在不同时机创建多个key来验证通知接收和处理的效果:
$main 1 2021/02/11 10:29:21 prog-1 subscribe expire event of node[localhost:30004] ok 2021/02/11 10:29:21 prog-1 subscribe expire event of node[localhost:30001] ok 2021/02/11 10:29:21 prog-1 subscribe expire event of node[localhost:30006] ok 2021/02/11 10:29:21 prog-1 subscribe expire event of node[localhost:30002] ok 2021/02/11 10:29:21 prog-1 subscribe expire event of node[localhost:30003] ok 2021/02/11 10:29:21 prog-1 subscribe expire event of node[localhost:30005] ok 2021/02/11 10:29:26 prog-1 become leader successfully 2021/02/11 10:29:31 prog-1 is the leader 2021/02/11 10:29:36 prog-1 is the leader 2021/02/11 10:29:41 prog-1 is the leader 2021/02/11 10:29:46 prog-1 is the leader 2021/02/11 10:29:47 prog-1 收到并处理一条过期消息[key:key1] 2021/02/11 10:29:51 prog-1 is the leader 2021/02/11 10:29:51 prog-1 收到并处理一条过期消息[key:key2] 2021/02/11 10:29:56 prog-1 收到并处理一条过期消息[key:key3] 2021/02/11 10:29:56 prog-1 is the leader 2021/02/11 10:30:01 prog-1 is the leader 2021/02/11 10:30:06 prog-1 is the leader ^C2021/02/11 10:30:08 recv exit signal... $main 3 2021/02/11 10:29:27 prog-3 subscribe expire event of node[localhost:30004] ok 2021/02/11 10:29:27 prog-3 subscribe expire event of node[localhost:30006] ok 2021/02/11 10:29:27 prog-3 subscribe expire event of node[localhost:30002] ok 2021/02/11 10:29:27 prog-3 subscribe expire event of node[localhost:30001] ok 2021/02/11 10:29:27 prog-3 subscribe expire event of node[localhost:30005] ok 2021/02/11 10:29:27 prog-3 subscribe expire event of node[localhost:30003] ok 2021/02/11 10:29:48 prog-3 try to become leader failed: redsync: failed to acquire lock 2021/02/11 10:30:03 prog-3 try to become leader failed: redsync: failed to acquire lock 2021/02/11 10:30:08 prog-3 become leader successfully 2021/02/11 10:30:08 prog-3 is the leader 2021/02/11 10:30:12 prog-3 is the leader 2021/02/11 10:30:17 prog-3 is the leader 2021/02/11 10:30:22 prog-3 is the leader 2021/02/11 10:30:23 prog-3 收到并处理一条过期消息[key:key4] 2021/02/11 10:30:27 prog-3 is the leader ^C2021/02/11 10:30:28 recv exit signal... $main 2 2021/02/11 10:29:24 prog-2 subscribe expire event of node[localhost:30005] ok 2021/02/11 10:29:24 prog-2 subscribe expire event of node[localhost:30006] ok 2021/02/11 10:29:24 prog-2 subscribe expire event of node[localhost:30003] ok 2021/02/11 10:29:24 prog-2 subscribe expire event of node[localhost:30004] ok 2021/02/11 10:29:24 prog-2 subscribe expire event of node[localhost:30002] ok 2021/02/11 10:29:24 prog-2 subscribe expire event of node[localhost:30001] ok 2021/02/11 10:29:45 prog-2 try to become leader failed: redsync: failed to acquire lock 2021/02/11 10:30:01 prog-2 try to become leader failed: redsync: failed to acquire lock 2021/02/11 10:30:16 prog-2 try to become leader failed: redsync: failed to acquire lock 2021/02/11 10:30:28 prog-2 become leader successfully 2021/02/11 10:30:28 prog-2 is the leader 2021/02/11 10:30:29 prog-2 is the leader 2021/02/11 10:30:34 prog-2 is the leader 2021/02/11 10:30:39 prog-2 收到并处理一条过期消息[key:key5] 2021/02/11 10:30:39 prog-2 is the leader ^C2021/02/11 10:30:41 recv exit signal...
这个运行结果如预期!
不过这个方案显然也不是那么理想,毕竟我们要单独Subscribe每个集群内的redis节点,目前没有理想方案,除非redis cluster支持带广播的Event notification。
以上示例代码可以在这里 https://github.com/bigwhite/experiments/tree/master/redis-cluster-distributed-lock 下载 。
Go技术专栏“改善Go语⾔编程质量的50个有效实践”正在慕课网火热热销中!本专栏主要满足广大gopher关于Go语言进阶的需求,围绕如何写出地道且高质量Go代码给出50条有效实践建议,上线后收到一致好评!欢迎大家订阅!

我的网课“Kubernetes实战:高可用集群搭建、配置、运维与应用”在慕课网热卖中,欢迎小伙伴们订阅学习!

讲师主页:tonybai_cn
讲师博客: Tony Bai
专栏:《改善Go语言编程质量的50个有效实践》
实战课:《Kubernetes实战:高可用集群搭建,配置,运维与应用》
免费课:《Kubernetes基础:开启云原生之门》
-
Redis入门教程:轻松掌握数据存储与操作10-22
-
Redis缓存入门教程:快速掌握Redis缓存基础知识10-22
-
Redis入门指南:轻松掌握Redis基础操作10-22
-
Redis Quicklist 竟让内存占用狂降50%?10-22
-
Redis学习:从入门到初级应用教程10-17
-
Redis入门:新手必读教程10-12
-
阿里云Redis项目实战:新手入门教程09-26
-
阿里云Redis资料入门教程09-26
-
阿里云Redis入门教程:快速掌握Redis的基本操作09-25
-
阿里云Redis学习:新手入门教程09-25
-
Redis资料入门教程:轻松掌握Redis基础知识09-21
-
Redis资料:入门级用户必学教程09-21
-
Redis资料:新手入门教程与实践指南09-21
-
Redis教程:从入门到实践的全面指南09-20
-
Redis教程:初学者快速入门指南09-20
