C/C++教程
如何将 PyTorch Lightning 模型部署到生产中

大规模服务PyTorch Lightning模型的完整指南。

纵观机器学习领域,主要趋势之一是专注于将软件工程原理应用于机器学习的项目激增。 例如,Cortex再现了部署无服务器功能但具有推理管道的体验。类似地,DVC实现了现代版本控制和CI / CD管道,但仅用于ML。
PyTorch Lightning具有类似的理念,仅适用于训练。框架为PyTorch提供了Python包装器,可让数据科学家和工程师编写干净,可管理且性能卓越的训练代码。
作为构建 整个部署平台的人 ,部分原因是我们讨厌编写样板,因此我们是PyTorch Lightning的忠实拥护者。本着这种精神,我整理了将PyTorch Lightning模型部署到生产环境的指南。在此过程中,我们将研究几种导出PyTorch Lightning模型以包括在推理管道中的选项。
部署PyTorch Lightning模型进行推理的每种方法
有三种方法可以导出PyTorch Lightning模型进行投放:
将模型另存为PyTorch检查点
将模型转换为ONNX
将模型导出到Torchscript
我们可以通过Cortex为这三个服务。
1.直接打包和部署PyTorch Lightning模块
从最简单的方法开始,让我们部署一个没有任何转换步骤的PyTorch Lightning模型。
PyTorch Lightning Trainer是一个抽象样板训练代码(思考训练和验证步骤)的类,它具有内置的save_checkpoint()函数,该函数会将您的模型另存为.ckpt文件。要将模型保存为检查点,只需将以下代码添加到训练脚本中:

现在,在我们开始为该检查点提供服务之前,需要注意的是,虽然我一直说“ PyTorch Lightning模型”,但PyTorch Lightning是PyTorch的包装器-项目的README字面意思是“ PyTorch Lightning只是有组织的PyTorch。” 因此,导出的模型是普通的PyTorch模型,可以相应地使用。
有了保存的检查点,我们可以在Cortex中轻松地为模型提供服务。如果您不熟悉Cortex,可以 在这里快速熟悉一下,但是Cortex部署过程的简单概述是:
我们使用Python为我们的模型编写了一个预测API
我们在YAML中定义我们的API基础结构和行为
我们使用CLI中的命令部署API
我们的预测API将使用Cortex的Python Predictor类定义一个init()函数来初始化我们的API并加载模型,并使用一个define()函数在查询时提供预测:

很简单 我们从训练代码中重新调整了一些代码的用途,添加了一些推理逻辑,仅此而已。需要注意的一件事是,如果将模型上传到S3(推荐),则需要添加一些逻辑来访问它。
接下来,我们在YAML中配置基础架构:

再次,简单。我们给我们的API起个名字,告诉Cortex我们的预测API在哪里,并分配一些CPU。
接下来,我们部署它:

请注意,我们还可以部署到集群,由Cortex加速和管理:

在所有部署中,Cortex都会容器化我们的API并将其公开为Web服务。通过云部署,Cortex可以配置负载平衡,自动扩展,监视,更新和许多其他基础架构功能。
就是这样!现在,我们有一个实时Web API,可根据要求提供模型预测。
2.导出到ONNX并通过ONNX运行时进行投放
现在,我们已经部署了一个普通的PyTorch检查点,让事情复杂一些。
PyTorch Lightning最近添加了一个方便的抽象,用于将模型导出到ONNX(以前,您可以使用PyTorch的内置转换功能,尽管它们需要更多样板)。要将模型导出到ONNX,只需将以下代码添加到您的训练脚本中:

请注意,您的输入样本应模仿实际模型输入的形状。
导出ONNX模型后,就可以使用Cortex的ONNX Predictor为其提供服务。代码基本上看起来是相同的,并且过程是相同的。例如,这是一个ONNX预测API:

基本上一样。唯一的区别是,我们不是通过直接初始化模型,而是通过onnx_client访问该数据,这是Cortex为服务于我们的模型而启动的ONNX运行时容器。
我们的YAML看起来也很相似:
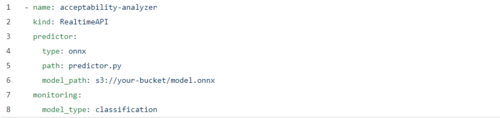
我在此处添加了一个监视标志,目的只是为了显示配置的简便程度,并且有一些ONNX特定字段,但其他方面都是相同的YAML。
最后,我们使用与之前相同的$ cortex deploy命令进行部署,并且我们的ONNX API已启用。
3.使用Torchscript的JIT编译器进行序列化
对于最终部署,我们将把PyTorch Lightning模型导出到Torchscript并使用PyTorch的JIT编译器提供服务。要导出模型,只需将其添加到您的训练脚本中:

用于此目的的Python API与原始PyTorch示例几乎相同:
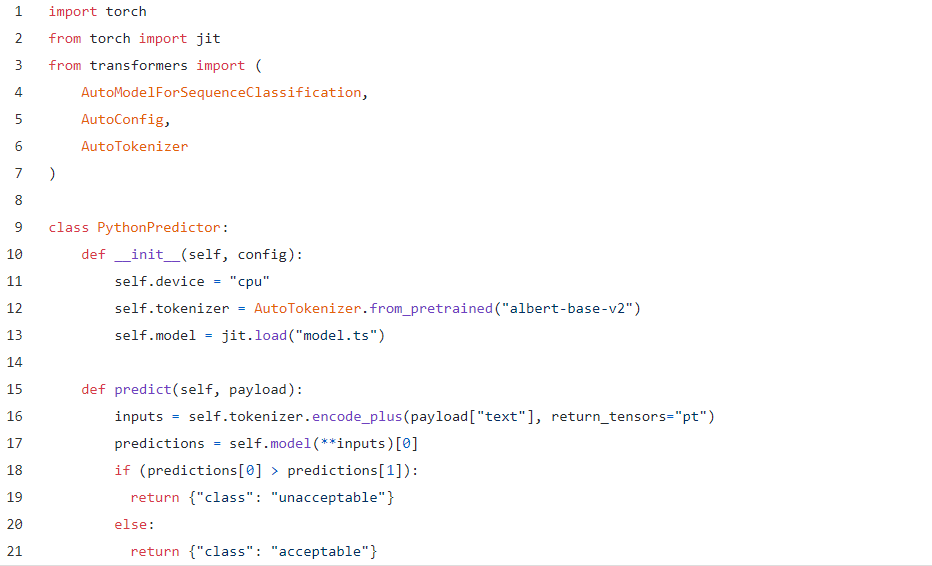
YAML保持与以前相同,并且CLI命令当然是一致的。如果需要的话,我们实际上可以更新我们以前的PyTorch API来使用新模型,只需将新的旧的dictor.py脚本替换为新的脚本,然后再次运行$ cortex部署:
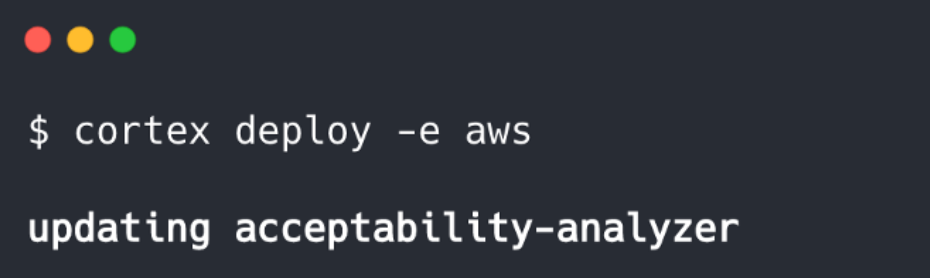
Cortex在此处自动执行滚动更新,在该更新中,新的API会被启动,然后与旧的API交换,从而避免了模型更新之间的任何停机时间。
这就是全部。现在,您已经具有用于实时推理的完全可操作的预测API,可根据Torchscript模型提供预测。
那么,您应该使用哪种方法?
显而易见的问题是哪种方法效果最好。事实是,这里没有简单的答案,因为这取决于您的模型。
对于BERT和GPT-2等Transformer模型,ONNX可以提供令人难以置信的优化(我们测得的CPU吞吐量提高了40倍 )。对于其他模型,Torchscript的性能可能比香草PyTorch更好-尽管这也带有一些警告,因为并非所有模型都干净地导出到Torchscript。
幸运的是,使用任何选项进行部署都很容易,您可以并行测试所有这三个选项,并查看哪种方式最适合您的特定API。
如果你喜欢本文的话,欢迎点赞转发!谢谢。
-
增量更新怎么做?-icode9专业技术文章分享11-23
-
压缩包加密方案有哪些?-icode9专业技术文章分享11-23
-
用shell怎么写一个开机时自动同步远程仓库的代码?-icode9专业技术文章分享11-23
-
webman可以同步自己的仓库吗?-icode9专业技术文章分享11-23
-
在 Webman 中怎么判断是否有某命令进程正在运行?-icode9专业技术文章分享11-23
-
如何重置new Swiper?-icode9专业技术文章分享11-23
-
oss直传有什么好处?-icode9专业技术文章分享11-23
-
如何将oss直传封装成一个组件在其他页面调用时都可以使用?-icode9专业技术文章分享11-23
-
怎么使用laravel 11在代码里获取路由列表?-icode9专业技术文章分享11-23
-
怎么实现ansible playbook 备份代码中命名包含时间戳功能?-icode9专业技术文章分享11-22
-
ansible 的archive 参数是什么意思?-icode9专业技术文章分享11-22
-
ansible 中怎么只用archive 排除某个目录?-icode9专业技术文章分享11-22
-
exclude_path参数是什么作用?-icode9专业技术文章分享11-22
-
微信开放平台第三方平台什么时候调用数据预拉取和数据周期性更新接口?-icode9专业技术文章分享11-22
-
uniapp 实现聊天消息会话的列表功能怎么实现?-icode9专业技术文章分享11-22
