Java教程
一分钟了解堆的基本操作

基本操作
任何一个数据结构,无非就是增删改查四大类:
| 功能 | 方法 | 时间复杂度 |
|---|---|---|
| 增 | offer(E e) | O(logn) |
| 删 | poll() | O(logn) |
| 改 | 无直接的 API | 删 + 增 |
| 查 | peek() | O(1) |
这里 peek() 的时间复杂度很好理解,因为堆的用途就是能够快速的拿到一组数据里的最大/最小值,所以这一步的时间复杂度一定是 O(1) 的,这就是堆的意义所在。
那么我们具体来看 offer(E e) 和 poll() 的过程。
offer(E e)
比如我们新加一个 0 到刚才这个最小堆里面:

那很明显,0 是要放在最上面的,可是,直接放上去就不是一棵完全二叉树了啊。。
所以说,
- 我们先保证加了元素之后这棵树还是一棵完全二叉树,
- 然后再通过 swap 的方式进行微调,来满足堆序性。
这样就保证满足了堆的两个特点,也就是保证了加入新元素之后它还是个堆。
那具体怎么做呢:
Step 1.
先把 0 放在最后接上,别一上来就想着上位;

OK!总算先上岸了,然后我们再一步步往上走。
这里「能否往上走」的标准在于:
是否满足堆序性。
也就是说,现在 5 和 0 之间不满足堆序性,那么交换位置,换到直到满足堆序性为止。
这里对于最小堆来说的堆序性,就是小的数要在上面。
Step 2. 与 5 交换
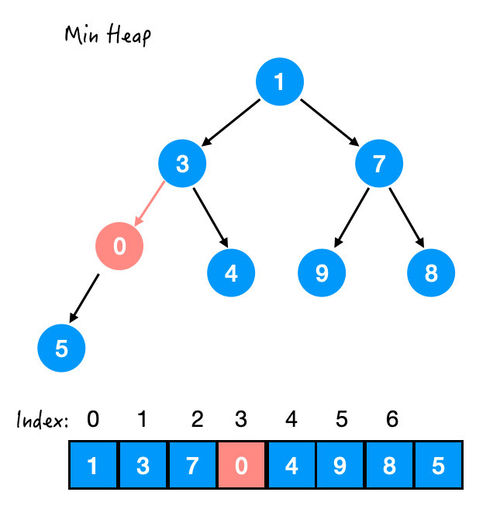
此时 0 和 3 不满足堆序性了,那么再交换。
Step 3. 与 3 交换

还不行,0 还比 1 小,所以继续换。
Step 4. 与 1 交换
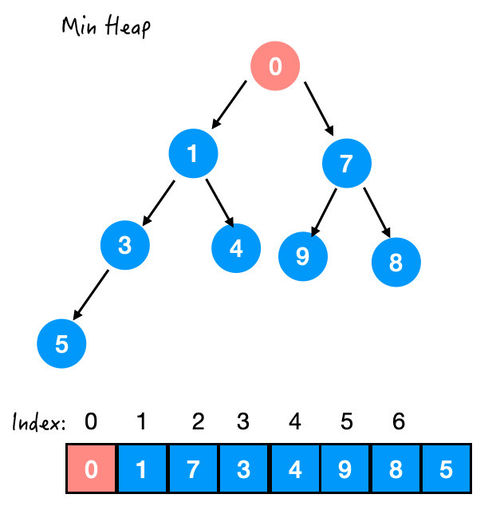
OK!这样就换好了,一个新的堆诞生了~
总结一下这个方法:
先把新元素加入数组的末尾,再通过不断比较与 parent 的值的大小,决定是否交换,直到满足堆序性为止。
这个过程就是 siftUp(),源码如下:

时间复杂度
这里不难发现,其实我们只交换了一条支路上的元素,
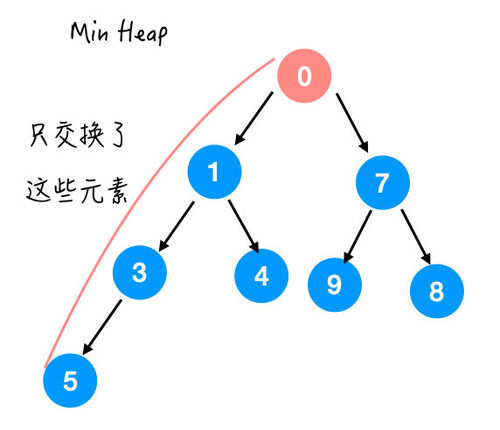
也就是最多交换 O(height) 次。
那么对于完全二叉树来说,除了最后一层都是满的,O(height) = O(logn)。
所以 offer(E e) 的时间复杂度就是 O(logn) 啦。
poll()
poll() 就是把最顶端的元素拿走。
对了,没有办法拿走中间的元素,毕竟要 VIP 先出去,小弟才能出去。
那么最顶端元素拿走后,这个位置就空了:

我们还是先来满足堆序性,因为比较容易满足嘛,直接从最后面拿一个来补上就好了,先放个傀儡上来。
Step1. 末尾元素上位
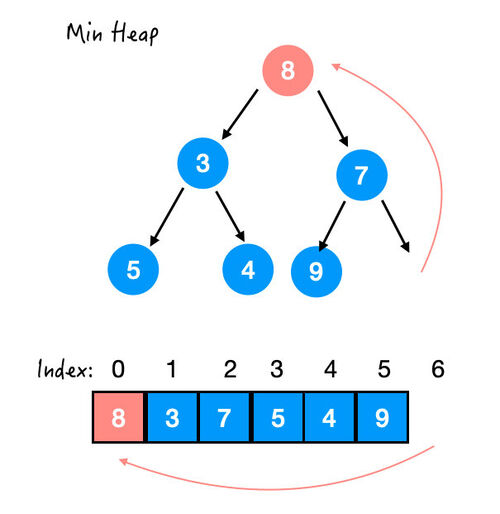
这样一来,堆序性又不满足了,开始交换元素。
那 8 比 7 和 3 都大,应该和谁交换呢?
假设与 7 交换,那么 7 还是比 3 大,还得 7 和 3 换,麻烦。
所以是与左右孩子中较小的那个交换。
Step 2. 与 3 交换

下去之后,还比 5 和 4 大,那再和 4 换一下。
Step 3. 与 4 交换
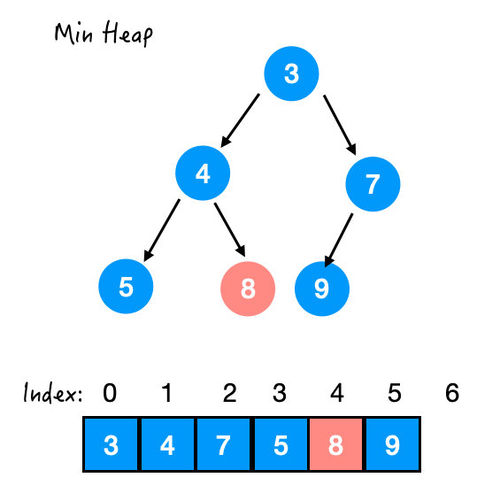
OK!这样这棵树总算是稳定了。
总结一下这个方法:
先把数组的末位元素加到顶端,再通过不断比较与左右孩子的值的大小,决定是否交换,直到满足堆序性为止。
这个过程就是 siftDown(),源码如下:

时间复杂度
同样道理,也只交换了一条支路上的元素,也就是最多交换 O(height) 次。
所以 offer(E e) 的时间复杂度就是 O(logn) 啦。
那以上就是有关堆的基本操作啦!对于堆,还有一个比较特别的操作,就是 heapify(),这是一个很神奇的操作,至于神奇在何处、为什么它能做到、它是怎么做到的,我们下一篇文章再说~
如果你喜欢这篇文章,记得给我点赞留言哦~你们的支持和认可,就是我创作的最大动力,我们下篇文章见!
我是小齐,纽约程序媛,终生学习者,每天晚上 9 点,云自习室里不见不散!
更多干货文章见我的 Github: https://github.com/xiaoqi6666/NYCSDE
-
怎么修改Kafka的JVM参数?-icode9专业技术文章分享12-24
-
线下车企门店如何实现线上线下融合?12-23
-
鸿蒙Next ArkTS编程规范总结12-23
-
物流团队冬至高效运转,哪款办公软件可助力风险评估?12-23
-
优化库存,提升效率:医药企业如何借助看板软件实现仓库智能化12-23
-
项目管理零负担!轻量化看板工具如何助力团队协作12-23
-
电商活动复盘,为何是团队成长的核心环节?12-23
-
鸿蒙Next ArkTS高性能编程实战12-23
-
数据驱动:电商复盘从基础到进阶!12-23
-
从数据到客户:跨境电商如何通过销售跟踪工具提升营销精准度?12-23
-
汽车4S店运营效率提升的核心工具12-23
-
ERP 系统开发案例:用 PERT 图打造高效项目管理12-23
-
初创团队必备!全面解析支持甘特图的项目管理工具与功能特点12-23
-
任务进度跟踪不再难!可视化项目协作工具精选12-23
-
看板工具为汽车销售门店协作赋能:关键方法12-23
