Java教程
《像素点旅行记WebView篇》

原文链接请参见BeesAndroid项目,
我们平时有没有思考过这样一个问题,当我们打开一个H5页面时,从手指触摸到屏幕到页面被渲染出来,这期间发生了哪些事情。这是一个比较有深度的问题,它可以考验我们对整个Android浏览器体系的掌握程度,其中不乏软件和硬件方面的知识,深入了解这些可以帮助我们在分析问题和设计方案时,看的更广,看的更深。
《像素点旅行记WebView篇》将以这个问题为出发点,深入探讨H5渲染过程中涉及到的各种理论知识。
如上图所示,我们来思考一下这个过程可能会涉及哪些流程。
- 触摸反馈:首先是触摸,这个触摸事件是怎么传递到Android里面的App的。
- 容器创建:当触摸事件传递到App中,Android是怎么启动WebView容器来加载URL的。这里会涉及Chromium内核的启动等相关知识。
- 页面加载:WebView启动以后,是怎样向服务端发送主文档请求的,又是怎么接收主文档响应的。
- 页面渲染:WebView接收到主文档之后,是怎么样将它解析成页面的,这个是最为关键也是最为复杂的一环。
虽然简单来说,大致是上面四个流程。但是内部的实现还是非常复杂的,我们来一一探究。文章较长,可以选择性的进行阅读。
触摸反馈
the_life_of_pixel_webview_01.drawio
当用户在和操作系统交互之前,他首先接触到的就是触摸屏,触摸屏是传感器的一种,目前市面上的触摸屏大都基于电容来实现的。早期还有电阻屏和表面声波屏。这几种屏幕的区别可以参考这篇文章。
电容屏是利用人体的电流感应进行工作的,用户触摸电容屏幕时,由于人体电场,用户和触摸屏表面会形成一个耦合电容。对于高频电流来说,电容是直接导体,于是手指从接触点吸走一个很小的电流(每天都在被电击😲)。这个电流从触摸屏的四角电极流出,并且流经这四个电极的电流和手指到四角的距离成正比,电容屏控制器芯片会对这个电流的比例做精确计算,得出触摸点的位置。
当触摸屏控制芯片得到触摸点位置以后会通过总线接口(例如PC总线接口)将信号传导到CPU的引脚上,它是依赖电气信号(电压高低变化)进行通信,这部分内容可以去《计算机体系结构》中进一步了解其中的原理,笔者也是个硬件小白,就不展开了。
CPU收到触屏控制器的电气信号以后就是触发CPU的中断机制,我们每次触摸会产生两次中断,滑动的时候回产生上百次中断。Android系统是基于Linux内核的,对于Linux内核来说每个外部设备都有一个唯一的标识符,称为中断请求号(IRQ),可以在adb shell下通过cat /proc/interrupts查看,例如:
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7 3: 20053 20264 12264 11228 7765 7477 7543 9172 GIC 27 Edge arch_timer 5: 928 1570 1080 994 483 375 505 522 GIC 80 Level timer 6: 0 0 0 0 0 0 0 0 GIC 81 Level acpu osa 7: 91 0 0 0 0 0 0 0 GIC 103 Level acpu om_timer 8: 0 0 0 0 0 0 0 0 GIC 104 Level hard_timer_irq 9: 1748 0 0 0 0 0 0 0 GIC 186 Level ipc_irq 10: 0 0 0 0 0 0 0 0 GIC 187 Level ipc_sem 39: 3803 0 0 0 0 0 0 0 GIC 152 Level ffd73000.i2c 40: 1890 0 0 0 0 0 0 0 GIC 113 Level fdf0c000.i2c 41: 2006 0 0 0 0 0 0 0 GIC 114 Level fdf0d000.i2c 43: 103 0 0 0 0 0 0 0 GIC 107 Level 48: 0 0 0 0 0 0 0 0 GIC 145 Level pl022 49: 0 0 0 0 0 0 0 0 GIC 112 Level pl022 52: 100195 0 0 0 0 0 0 0 GIC 182 Level asp_irq_slimbus 53: 36182 49662 0 0 0 0 0 0 GIC 169 Level mmc0 54: 2414 0 0 0 0 0 0 0 GIC 290 Level gpufreq 55: 0 0 0 0 0 0 0 0 GIC 291 Level gpufreq 56: 6464 0 0 0 0 0 0 0 GIC 292 Level gpufreq 57: 3530 0 0 0 0 0 0 0 GIC 277 Level irq_pdp 58: 0 0 0 0 0 0 0 0 GIC 278 Level irq_sdp 59: 0 0 0 0 0 0 0 0 GIC 279 Level irq_adp 64: 56 0 0 0 0 0 0 0 GIC 171 Level dw-mci 复制代码
我们在以前学习计算机原理的时候知道当中断产生以后,CPU会停下当前运行的程序,保存当前运行状态,然后跳转到相应的中断处理程序进行处理,这个处理程序一般是由三方内核驱动来实现的,例如Android input里的drivers/input/touchscreen/ektf3k.c。该驱动程序会调用它里面的input_report_abs等方法记录触摸屏下面的坐标信息,然后通过input模块将这些信息都写进/dev/input/event1设备文件中。我们可以通过getevent工具查看这些信息。
adb shell su -- getevent -lt /dev/input/event1
[ 78826.389007] EV_ABS ABS_MT_TRACKING_ID 0000001f [ 78826.389038] EV_ABS ABS_MT_PRESSURE 000000ab [ 78826.389038] EV_ABS ABS_MT_POSITION_X 000000ab [ 78826.389068] EV_ABS ABS_MT_POSITION_Y 0000025b [ 78826.389068] EV_ABS ABS_MT_SLOT 00000001 [ 78826.389068] EV_ABS ABS_MT_TRACKING_ID 00000020 [ 78826.389068] EV_ABS ABS_MT_PRESSURE 000000b9 [ 78826.389099] EV_ABS ABS_MT_POSITION_X 0000019e [ 78826.389099] EV_ABS ABS_MT_POSITION_Y 00000361 [ 78826.389099] EV_SYN SYN_REPORT 00000000 [ 78826.468688] EV_ABS ABS_MT_SLOT 00000000 [ 78826.468688] EV_ABS ABS_MT_TRACKING_ID ffffffff [ 78826.468719] EV_ABS ABS_MT_SLOT 00000001 [ 78826.468719] EV_ABS ABS_MT_TRACKING_ID ffffffff [ 78826.468719] EV_SYN SYN_REPORT 00000000 复制代码
当坐标信息被写进/dev/input/event1设备文件以后,应用程序只需要监听该设备文件的变化就可以知道用户进行了哪些触摸操作,但是实际操作这么做的话会非常繁琐,这一套繁琐的工作会交于各个系统的GUI框架来完成,Android系统上就是WindowManagerService了,它是Android系统内的窗口管理服务,它会负责读取位置信息,并分发到指定的App,回调响应的监听函数(onTouch)。
到这里,用户的触摸事件就传递到App的页面中了,这个时候回调onTouch方法,响应用户的触摸事件。在Android上打开一个H5,一般是打开一个Activity,这个Activity内部会有一个WebView,它会调用loadUrl方法来加载URL。
容器启动
上面我们提到H5是在WebView里被加载并渲染的,而WebView又是在Activity被加载的,所以一个H5容器的启动就包含两个方面:
- Activity启动与创建
- WebView启动与创建
注:为什么会特地聊聊容器启动呢,因为这个也是H5页面体验的重要组成部分,因为是Native的关系,前端同学可能会关注不到。而且容器导航阶段是重要的预加载时机,我们可以在这里做很多事情,例如:
- 接口预加载
- HTML文档预加载
- 资源预加载
- 导航的时候创建一个JS Engine,可以提前执行JS逻辑,把导航预加载这个能力开放给前端。
1 Activity启动与创建
注:这部分内容涉及比较多的Android知识,前端同学可以跳过。
Activity的启动流程图(放大可查看)如下所示:

整个流程涉及的主要角色有:
- Instrumentation: 监控应用与系统相关的交互行为。
- AMS:组件管理调度中心,什么都不干,但是什么都管。
- ActivityStarter:Activity启动的控制器,处理Intent与Flag对Activity启动的影响,具体说来有:1 寻找符合启动条件的Activity,如果有多个,让用户选择;2 校验启动参数的合法性;3 返回int参数,代表Activity是否启动成功。
- ActivityStackSupervisior:这个类的作用你从它的名字就可以看出来,它用来管理任务栈。
- ActivityStack:用来管理任务栈里的Activity。
- ActivityThread:最终干活的人,Activity、Service、BroadcastReceiver的启动、切换、调度等各种操作都在这个类里完成。
注:这里单独提一下ActivityStackSupervisior,这是高版本才有的类,它用来管理多个ActivityStack,早期的版本只有一个ActivityStack对应着手机屏幕,后来高版本支持多屏以后,就有了多个ActivityStack,于是就引入了ActivityStackSupervisior用来管理多个ActivityStack。
整个流程主要涉及四个进程:
- 调用者进程,如果是在桌面启动应用就是Launcher应用进程。
- ActivityManagerService等所在的System Server进程,该进程主要运行着系统服务组件。
- Zygote进程,该进程主要用来fork新进程。
- 新启动的应用进程,该进程就是用来承载应用运行的进程了,它也是应用的主线程(新创建的进程就是主线程),处理组件生命周期、界面绘制等相关事情。
有了以上的理解,整个流程可以概括如下:
- 点击桌面应用图标,Launcher进程将启动Activity(MainActivity)的请求以Binder的方式发送给了AMS。
- AMS接收到启动请求后,交付ActivityStarter处理Intent和Flag等信息,然后再交给ActivityStackSupervisior/ActivityStack
处理Activity进栈相关流程。同时以Socket方式请求Zygote进程fork新进程。 - Zygote接收到新进程创建请求后fork出新进程。
- 在新进程里创建ActivityThread对象,新创建的进程就是应用的主线程,在主线程里开启Looper消息循环,开始处理创建Activity。
- ActivityThread利用ClassLoader去加载Activity、创建Activity实例,并回调Activity的onCreate()方法。这样便完成了Activity的启动。
注:读者可以发现这上面有很多函数有Locked后缀,这代表这些函数需要进行多线程同步(synchronized)操作,它们会读写一些多线程共享的数据。
2 WebView启动创建
WebView如果只是把它当做一个View,那它的启动流程就与Android其他View没有什么区别了,从代码或者XML文件里解析并构建View对象。但是我们这里探讨的不是一个简单的View创建,而是借此讨论Chromium引擎(WebView基于Chromium内核实现)在Android平台的启动流程。
当我们提到启动流程,先思考一下启动了什么,答案当然是启动了进程&线程,它是我们代码运行的载体,因而Chromium的启动流程可以进一步提炼为Chromium中各种进程的启动流程。Android 7.0加入开发者选项,可以打开多进程。Android 8.0默认打开多进程。目前只有Render Process,GPU Process仍然为Browser Process的一个线程。
什么是Chromium多进程架构?
Chromium是一个多进程的架构,多进程架构的意义:
- 稳定性:不同H5页面运行在不同的进程中,彼此不会相互影响。独立进程还可以减少主进程的内存压力,提升主进程的稳定性。
- 安全性:Chromium利用双重防护机制实现SendBox机制。

Multi-process Architecture
如上图所示Chromium有多个进程,具体说来:
> 另外,Chromium在Android系统上有两套实现。
- Chrome浏览器:每个进程包含Main Thread、IO Thread等多个线程。Render Process和GPU Process基于Android Service组件实现。
- Android WebView:Android View组件,可以在Android App中使用,加载H5.
- 单进程:Render Process和GPU Process变成Browser Process中的线程。
- 多进程:Android 7.0加入开发者选项,可以打开多进程。Android 8.0默认打开多进程。目前只有Render Process,GPU Process仍然为Browser Process的一个线程。
当我们构建一个WebView实例的时候,它会先去加载Chromium相关so库,然后启动Browser、Render等进程以及进程运行的必要组件。这样整个容器就启动起来了。启动流程如下所示:
- Browser:负责启动Browser的是//android_webview里的AwBrowserProcess,它封装了//content/public/android下的BrowserStartupController。启动Browser的流程实际上就是在App的UI线程创建一个Browser Main Loop,Chromium以后需要请求Browser执行一个操作时,就可以像Browser Main Loop发送一个Task,当然这个Task绘制UI线程里执行。
- Render:负责启动Render的是//android_webview里的AwContents,它封装了//content/public/android下的ContentViewCore。启动Render在不同的版本有所区别。
- 在Android O之前是单进程架构,它会在当前App进程中创建一个线程,以后网页就在这个线程中渲染。这个称之为In-Process Renderer。
- 在Android O之后是多进程架构,它会单独创建一个进程,以后网页在这个进程里渲染。这个称之为Out-of-Process Renderer。
- GPU:Chromium的GPU实现在App的Render Thread,Render Thread是App自己创建的,因为Chromium无需单独启动它。不过android_webview模块会启动一个DeferredGpuCommandService服务,当CHromium的Browser和Render需要执行GPU操作时,会向DeferredGpuCommandService服务发送请求,DeferredGpuCommandService服务通过App的UI线程将GPU操作提交给Render Thread执行。
容器启动以后,便可以调用loadUrl去加载页面了。
页面加载
WebView容器创建完成以后,就可以调用它的loadUrl方法加载页面了。它会先向服务端请求HTML Document文档资源。发起请求前会先对URL进行解析,然后开启一个网络线程去请求HTML Document资源。如下所示:

注:上图中前面展示了是在一个浏览器内部发生页面导航跳转的情况,基本逻辑都是一直的,当我们直接打开一个H5时,可以视为从Start url request这个阶段开始。
按照颜色划分,整个页面导航加载的流程有三个角色:
- 黄色:Browser
- 蓝色:Network
- 绿色:Renderer
- BrowserInitialization:网址转换,将输入的关键字等转换为真正的网址。(直接打开H5没有这一步)。
- BeiginNavigation:调用BeiginNavigation函数开始导航。
- Start url request:启动URL请求。网络请求由NavigationURLLoader来管理。
- Read Response:读取响应。
- Find render:收到URL请求响应之后,跳回浏览器界面准备构建页面。
- Commit:告诉Renderer Process,收到了HTML文档,有新的页面需要渲染。
- Frame has commited navigation:给Browser Process一个ACK,告诉它已经收到了渲染请求。至于导航流程已经全部完成,但是由于还没有进入渲染流程,因而界面还是白屏。
- Load:读取HTML文档的Response,对其进行解析,并呈现的网页中。
- Load Stop:一旦Renderer Process渲染完成,它会通知Browser Process页面已经加装完成。
我们再把上面和W3C Navigation Timing进行对比,就可以对应上了。

关于HTTP请求&响应
网络请求主要由NavigationURLLoader来管理,发起HTTP请求主要包含以下流程:
- DNS解析
- 如果浏览器有缓存,则直接使用浏览器缓存,否则使用本机缓存。
- 如果本地没有,则使用DNS解析服务,查询对应IP。
- TCP建连(如果是HTTPS,还需要连接TLS连接)
- 三次握手建立连接
- 四次挥手断开连接
- 请求数据传输
- 应用层发送数据请求
- 传输层经历三次握手连接TCP连接
- 网络层进行IP寻址
- 数据链路层将数据封装成帧
- 物理层利用物理介质传输
- 读取请求响应
- 2xx:响应成功
- 3xx:重定向
- 4xx:客户端错误
- 5xx:服务端错误
这一块的内容网上资料很多,就不再展开了。
等到拿到HTML Response以后,开始进行流式传输Response到Renderer Process,开始进行渲染以及处理资源。接下来主要包含以下两件事情:
- Renderer Process将HTML渲染成与用户交互的页面,它主要包含两个部分:
- Blink:页面渲染,包含DOM tree、Layout、Paint、Raster等。
- V8:脚本解析&执行,修改页面,响应事件,下载资源等。
- 图片、JS、CSS等资源的下载(ResourceRequests)。
页面渲染
渲染流程里的图片来自于Chromium工程师的ppt Life of a Pixel的截图。
浏览器的渲染过程就是把网页通过渲染管道渲染成一个个像素点,最终输出到屏幕上。这里面就涉及3个角色
- 输入端:网页,Chromium将其抽象成Content。
- 渲染管线:主要是Blink负责DOM解析、样式布局、绘制等操作,将网页内容转换为绘制指令。
- 输出端:主要负责把绘制指令转换为像素,显示在屏幕上。
什么是输入端(Content)?
我们在Chromium这个项目里会频繁的看到Content这个概念,那么Content到底是什么呢。Content是渲染网页内容的区域,在Java层对应AwContent,底层有WebContents表示,如下所示:

content在代码由content::WebContents来描述,它在独立的Render进程由Blink创建。具体说来Content对应着前端开发中涉及的HTML、CSS、JS、image等,如下所示:

什么是渲染管线(Rendering Pipeline)?
渲染管线可以理解为对渲染流程的拆解,向工厂流水线一样,上一个车间生成的半成品送到下一个车间继续装配。拆解渲染流程有助于把渲染流程简单化,提高渲染效率。
渲染时动态的,内容发生变化时,就会触发渲染,更新像素点,和Android的绘制系统一样,触发绘制也是由invalidate机制触发的,触发渲染后,执行整个渲染管线是非常昂贵的,因而Blink也在想法设法减少不必要的渲染动作,提高渲染效率。
- 触发的条件如下所示:
- scrolling
- zooming
- animations
- incremental loading
- javascript
- 各个流程的触发方法如下:
- Style:Node::SetNeedsStyleRecalc()
- Layout:LayoutObject::SetNeedsLayout()
- Paint:PaintInvalidator::InvalidatePaint()
- RasterInvalidator::Generate()
渲染管道把网页转换为绘制指令后,它并不能直接把绘制指令变成像素点(光栅化)显示在屏幕上(Window),这个时候就需要借助操作系统自己的能力(底层的图形库),在图形界面这一块大部分平台都遵循OpenGL标准化的API。例如Windows上的DirectX,Android上的Vulcan。如下图所示:

通过上面的描述,我们了解了Conntent从哪里来,要到哪里去。总的来说就是把HTML、CSS、JS等转换为正确的OpenGL指令,然后渲染到屏幕上,与用户交互。
在了解了渲染的基本要素以后,我们来看看具体的渲染流程是怎样执行的,如下所示:

我们先来说结构
从上到下,分层来说:
- Blink:运行在Render进程的Render线程,它是Chromium的Blink渲染引擎,主要负责HTML/CSS的解析、jS的解释执行(V8)、DOM操作、排版、图层树的构建更新等任务。
- Layer Compositor:运行在Render进程的Compositor线程,它负责接收Blink生成的Main Frame,负责图层树的管理、图层的滚动、旋转等矩阵变化,图层的分块、光栅化、纹理上传等任务。
- Display Compositor:运行在Browser进程的UI线程,它负责接收Layer Compositor生成的Compositor Frame,输出最终的OpenGL绘制指令,将网页内容通过GL贴图操作绘制到目标窗口上。
这里面还提到了每个层级向上输出的产物帧,帧(Frame)描述了渲染流水线下级模块向上级模块输出的绘制内容相关数据的封装。
- Main Frame:包含了对网页内容的描述,主要以绘图指令的形式,或者理解为某个时间点对整个网页的一个矢量图快照。
- Compositor Frame:Layer Compositor接收Blink生成的Main Frame,并转换成内部的合成器结构。它会被发往Browser,并最终到达Compositor Frame,它主要由两部分构成:
- Resource:它是对Texture的封装,Layer Compositor为每个图层分块,然后为每个分块分配Resource,然后安排光栅化任务。
- Draw Quad:它代表了绘制指令(矩形绘制指令,指定了坐标、大小、变换矩阵等属性),Layer Compositor接收到Browser的绘制请求时,它会为当前可见区域每个图层的每个分块生成一个Draw Quad绘制指令。
- GL Frame:Display Compositor将Compositor Frame的每个Draw Quad绘制指令转换成一个GL多边形绘制指令,使用对应的Resource封装的Texture对目标窗口进行贴图。这个GL绘图指令的集合就构成了一个GL Frame,最终由GPU执行这些GL指令完成网页在窗口可见区域的绘制。
整个渲染水流水线的调度基于请求和状态机响应,调度的中枢运行在Browser UI线程,它按照显示器的VSync信号向Layer Compositor发出输出下一帧的请求,而Layer Compositor根据自身的状态机的状态决定是否需要Blink输出下一帧。而Layer Compositor和Display Compositor是生成者和消费者的关系,Display Compositor持有一个Compositor Frame队列不断的进行取出和绘制,输出的频率取决于 Compositor Frame的输入帧率和自身GL Frame的绘制频率。
我们再来说流程
- Parse/DOM:将Content解析成DOM树,它是后面各个渲染流程的基础。
- Style:解析并应用样式表。
- Layout:布局。
- Compositing update:将整个页面按照一定规则,分成独立的图层,便于隔离更新。
- prepaint:构建属性树,使得可以单独操作某个节点(变换、裁剪、特效、滚动),不至于影响它的子节点。
- paint:paint这个单词名词有油漆、颜料的含义。动词有用颜料画等含义。这里我觉得使用它的名词含义比较贴切,Paint操作会将布局树(Layout Tree)中的节点(Layout Object)转换成绘制指令(例如绘制矩形、绘制字体、绘制颜色,这有点像绘制API的调用)的过程。然后把这些操作封装在Dsipaly Item中,所以这些Display Item就像是油漆,它还没有真正的开始粉刷(绘制Draw)。
- Commit:commit会把paint阶段的数据拷贝的合成器线程。
- Tiling:raster接收到paint阶段的绘制指令之后,会先对图层进行分块。图块是栅格化(Raster)的基本工作单位。
- Raster:栅格化。
- Activate:栅格化是个异步的过程,因而图层树(Layer Tree)被分为了Pending Tree(负责接收Commit提交的Layer进行栅格化操作)和Activate Tree(从这里取出栅格化的Layer进行Draw操作),从Pending Tree拷贝Layer到Activate Tree的过程就叫做Activate。
- Draw:这里要和上面的Paint区分开来了,图块被栅格化以后,合成器线程会为每个图块生成draw quads(quads有四边形之意,它代表了在屏幕特定位置绘制图块的指令,包含属性树里面的变换、特效等信息),这些draw quads被封装到Compositor Frame中输出给GPU,Draw操作就是生成draw quads的过程。
- Display:生成了Compositor Frame以后,Viz会调用GL指令把draw quads最终输出到屏幕上。
我们来分别看具体的流程。
Blink
01 Parse
相关文档
- DOM标准
相关源码
- /blink/renderer/core/dom
当我们从服务器上下载了一份HTML文档,第一步就是解析,HTML解析器接收标签和文本流(HTML是纯文本格式)把HTML文档解析成DOM树。DOM(Document Object Model)即文档对象模型,DOM及时页面的内部表示,也为JavaScript暴露了API接口(V8 DOM API),可以让JavaScript程序改变文档的结构、样式和内容。
它是一个树状结构,我们在后续的渲染流程中还会看到很多树形结构(例如布局树、属性树等)因为它们都是基于DOM树的结构(HTML的结构)而来的。

注:HTML文档中可能包含多棵DOM树,因为HTML支持自定义元素,这种树通常被称为Shadow Tree。
解析HTML生成DOM树流程如下:
- HTMLDocumentParser负责解析HTML中的token,生成对象模型。
- HTMLTreeBuilder负责生成一棵完整的DOM树,同一个HTML文档可以包含多个DOM树,Custom Element元素具有一棵shadow tree。在shadow tree slot中传入的节点会被FlatTreeTraversal向下遍历时找到。
DOM树(DOM Tree)作为后续绘制流程的基础, 还会基于它生产各种类型的树,具体说来,主要会经历如下转换:
对象转换
- DOM Tree -> Render Tree -> Layer Tree
- DOM node -> RenderObject -> RenderLayer
DOM Tree(节点是DOM node)
当加载一个HTML时,会对他进行解析,生成一棵DOM树。DOM树上的每一个节点都对应这网页里面的每一个元素,网页可以通过JavaScript操作这棵DOM树。

How Webkit Works
Render Tree(节点是RenderObject)
但是DOM树本身并不能直接用于排版和渲染,因此内核会生成Render Tree,它是DOM Tree和CSS相结合的产物,两者的节点几乎是一一对应的。Render Tree是排版引擎和渲染引擎之间的桥梁。

How Webkit Works
Layer Tree(节点是RenderLayer)
渲染引擎并不是直接使用Render Tree进行绘制的,为了更加方便的处理定位、裁剪、业内滚动等操作,渲染引擎会生成一棵Layer Tree。渲染引擎会为一些特定的RenderObject生成相应的RenderLayer,不过该RenderObject的子节点没有相应的RenderLayer,那么它就从属于父节点的RenderLayer。渲染引擎会遍历每一个RenderLayer,再遍历从属于这个RenderLayer的RenderObject,将每一个RenderObject绘制出来。
可以这么理解,Layer Tree决定了网页的绘制顺序,从属于RenderLayer的RenderObject决定了这个Layer的绘制内容。
什么样的RenderObject会成为RenderLayer呢。GPU Accelerated Compositing in Chrome是这样定义的:
- It's the root object for the page
- It has explicit CSS position properties (relative, absolute or a transform)
- It is transparent
- Has overflow, an alpha mask or reflection
- Has a CSS filter
- Corresponds to
- Corresponds to a
对上面的流程不了解也没关系,我们下面会一一解释。
02 Style
当DOM树生成以后,就需要为每个元素设置一个样式,有的样式只是会影响某个节点,有的样式会影响整个节点下面的整个DOM子树的渲染(例如,节点的旋转变换)。

相关文档
- CSS Style Calculation in Blink
相关源码
- /blink/renderer/core/css
样式一般都是样式渲染器共同作用的结果,它有复杂的优先级语义和渲染过程,过程整体分为三步:
1 收集、划分和索引所有样式表中样式规则。

CSSParser首先CSS文件解析成对象模型StyleSheetContents,它里面包含各种样式规则(StyleRule),这些样式规则具有丰富的表现形式。包含选择器(CSSSelector)和属性值映射(CSSPropertyValue)在这些样式规则中,对象以各种方式建立索引,进行更有效的查找。
另外,样式属性以声明的方式进行定义,定义在Chromium里的css_properties,json5这个json文件里,这些定义会通过py脚本生成特定的C++类。
2 访问每个DOM元素并找到应用在该元素的所有规则。
样式引擎会遍历整个DOM树,计算每个节点的样式,计算样式(ComputeStyle)会完成property到rule的映射,例如字体样式、边距、背景色等。这些就是样式引擎的输出。

3 结合这些规则以及其他信息(样式引擎由部分默认的样式)生成最终的计算样式。
03 Layout
计算并应用了每个DOM节点的样式以后,就需要决定每个DOM节点的摆放位置。DOM节点都是基于盒模型摆放(一个矩形),布局就是计算这些盒子的坐标。

布局操作是建立在CSS盒模型基础之上的,如下所示:
|-------------------------------------------------|
| |
| margin-top |
| |
| |---------------------------------------| |
| | | |
| | border-top | |
| | | |
| | |--------------------------|--| | |
| | | | | | |
| | | padding-top |##| | |
| | | |##| | |
| | | |----------------| |##| | |
| | | | | | | | |
| ML | BL | PL | content box | PR |SW| BR | MR |
| | | | | | | | |
| | | |----------------| | | | |
| | | | | | |
| | | padding-bottom | | | |
| | | | | | |
| | |--------------------------|--| | |
| | | scrollbar height ####|SC| | |
| | |-----------------------------| | |
| | | |
| | border-bottom | |
| | | |
| |---------------------------------------| |
| |
| margin-bottom |
| |
|-------------------------------------------------|
复制代码
相关文档
- Blink Layout
- CSS Box Model Module Level 3
- LayoutNG
相关源码
- /blink/renderer/core/layout
基于DOM Tree会生成Layout Tee,生成每个节点的布局信息。布局的过程就是遍历整个Layout Tree进行布局操作。
DOM Tree和Layout Tree也不总是一一对应的,如果我们再标签里设置dispaly:none,它就不会创建一个布局对象(LayoutObject)。

04 Compositing Update
在Layout操作完成以后,理论上就可以开始Paint操作了,但是我们之前提过,如果直接开始Paint操作,绘制整个界面,代价是非常昂贵的。因此便引入了一个图层合成加速的概念。
什么是图层合成加速(Compositing Layer)?
图层合成加速基本思想是把整个页面按照一定规则分成多个图层(就像Photoshop的图层那样),在渲染时只需要操作必要的图层,其他图层只需要参与合成就行了,以此提高渲染效率。完成这个工作的线程叫Compositor Thread,值得一提的是Compositor Thread还具备处理输入事件的能力(例如滚动事件),但是如果在JavaScript注册了事件监听,它会把输入事件转发给主线程处理。

具体说来是为某些RenderLayer拥有自己独立的缓存,它们被称为合成图层(Compositing Layer),内核会被这些RenderLayer创建对应的GraphicsLayer。
- 拥有自己的GraphicsLayer的RenderLayer在绘制的时候就会绘制在自己的缓存里面。
- 没有自己的GraphicsLayer的RenderLayer会向上查找父节点的GraphicsLayer,直到RootRenderLayer(它总是会有自己的GraphicsLayer)为止,然后绘制在有GraphicsLayer的父节点的缓存里。

这样就形成了与RenderLayer Tree对应的GraphicsLayer Tree。当Layer的内容发生变化时,只需要更新所属的GraphicsLayer即可,而单一缓存架构下,就会更新整个图层,会比较耗时。这样就提高了渲染的效率。但是过多的GraphicsLayer也会带来内存的消耗,虽然减少了不必要的绘制,但也可能因为内存问题导致整体的渲染性能下贱。因而图层合成加速追求的是一个动态的平衡。
什么样的RenderLayer会被创建GraphicsLayer呢,GPU Accelerated Compositing in Chrome是这样定义的:
- Layer has 3D or perspective transform CSS properties
- Layer is used by
- Layer is used by a
- Layer is used for a composited plugin
- Layer uses a CSS animation for its opacity or uses an animated webkit transform
- Layer uses accelerated CSS filters
- Layer has a descendant that is a compositing layer
- Layer has a sibling with a lower z-index which has a compositing layer (in other words the layer overlaps a composited layer and should be rendered on top of it)
图层化的决策是由Blink来负责(未来可能会转移到Layer Compositor决策),根据DOM树生成一个图层树,并以DisplayList记录每个图层的内容。
了解了图层合成加速的概念以后,我们再来看看发生在Layout操作之后的Compositing update(合成更新),合成更新就是为特定的RenderLayer(创建规则我们已经描述过了)创建GraphicsLayer的过程,如下所示:

05 Prepaint
什么是属性树?
在描述属性的层次结构这一块,之前的方式是使用图层树的方式,如果父图层具有矩阵变换(平移、缩放或者透视)、裁剪或者特效(滤镜等),需要递归的应用到子节点,时间复杂度是O(图层数),这在极端情况下会有性能问题。
因此引入了属性树的概念,合成器提供了变换树、裁剪树、特效树等。每个图层都由若干节点id,分别对应不同属性树的矩阵变换节点、裁剪节点和特效节点。这样的时间复杂度就是O(要变化的节点),如下所示:

Prepaint的过程就是构建属性树的过程,如下所示:

06 Paint
创建完属性树(Prepaint)以后,就开始进入Paint阶段了。
相关文档
- renderer/core/paint
相关源码
- /blink/renderer/core/paint
Paint操作会将布局树(Layout Tree)中的节点(Layout Object)转换成绘制指令(例如绘制矩形、绘制字体、绘制颜色,这有点像绘制API的调用)的过程。然后把这些操作封装在Dsipaly Item中,这些Dsipaly Item存放在PaintArtifact中。PaintArtifact就是是Paint阶段的输出。
到目前为止,我们建立了可以重放的绘制操作列表,但没有执行真正的绘制操作。
注:重放(replay),现在图形系统大都采用recrod & replay机制,采集绘制指令与执行绘制指令相互分离,提高渲染效率

在绘制的过程中,会涉及一个绘制顺序的问题,它使用的是stacking order(z-index),而不是DOM order。z-index会决定绘制顺序,在没有z-order指定的情况下,Paint会按照以下顺序进行绘制。

- 背景色
- floats
- 前景色
- 轮廓
Paint操作最终会在Layout Tree的基础上生成一棵Paint Tree。

Layer Compositor
07 Commit
Paint阶段完成以后,进入Commit阶段。该阶段会更新图层和属性树的副本到合成器线程,以匹配提交的主线程状态。说的通俗点,就是把主线程里Paint阶段的数据(layers and properties)拷贝到合成器线程,供合成器线程使用。

08 Tiling
但是合成器线程接收到数据后,并不会立即开始合成,而是进行图层分块,这里又涉及一个分块渲染的技术。
什么是分块渲染?
分块渲染(Tile Rendering)就是把网页的缓存分为一格一格的小块,通常为256x256或者512x512,然后分块进行渲染。
分块渲染主要基于两个方面的考虑:
- GPU合成通常是使用OpenGL ES贴图实现的,这时候的缓存实际就是纹理(GL Texture),很多GPU对纹理的大小是有限制的,比如长宽必须是2的幂次方,最大不能超过2048或者4096等。无法支持任意大小的缓存。
- 分块缓存,方便浏览器使用统一的缓冲池来管理缓存。缓冲池的小块缓存由所有WebView共用,打开网页的时候向缓冲池申请小块缓存,关闭网页是这些缓存被回收。
图块(tiling)是栅格化工作的基本单位。 栅格化会根据图块与可见视口的距离安排优先顺序进行栅格化。离得近的会被优先栅格化,离得远的会降级栅格化的优先级。这些图块拼接在一起,就形成了一个图层,如下所示:

09 Raster
图层分块完成以后,接着就会进行栅格化(Raster)。
什么是光栅化(栅格化)?
光栅化(Raterization),又称栅格化,它用于执行绘图指令生成像素的颜色值,光栅化策略分为两种:
- 同步光栅化:光栅化和合成在同一线程,或者通过线程同步的方式来保证光珊化和合成
- 直接光栅化:直接将所有可见图层的eDisplayList中的可见区域的绘图指令进行执行,在目标Surface的像素缓冲区上生成像素的颜色值。当然如果是完全的直接光栅化,就不涉及图层合并了,也就不需要后面的合成了。
- 间接光栅化:允许为指定图层分配额外的缓冲区,该图层的光栅化会先写入自身的像素缓冲区,渲染引擎再将这些图层的像素缓冲区(Android里可以调用View.setLayerType允许应用为View分配像素缓冲区)通过合成输出大欧姆表Surface的像素缓冲区。Android和Flutter主要使用直接光栅化的测量,同时也支持间接光栅化。
- 异步分块光栅化
上面说到,在Paint阶段会生成DisplayItem列表,它们是对绘制指令的封装。光栅化(Raster)或者栅格化的过程就是把这些绘图指令变成位图(像素点,每个像素点都带有自己的颜色)。
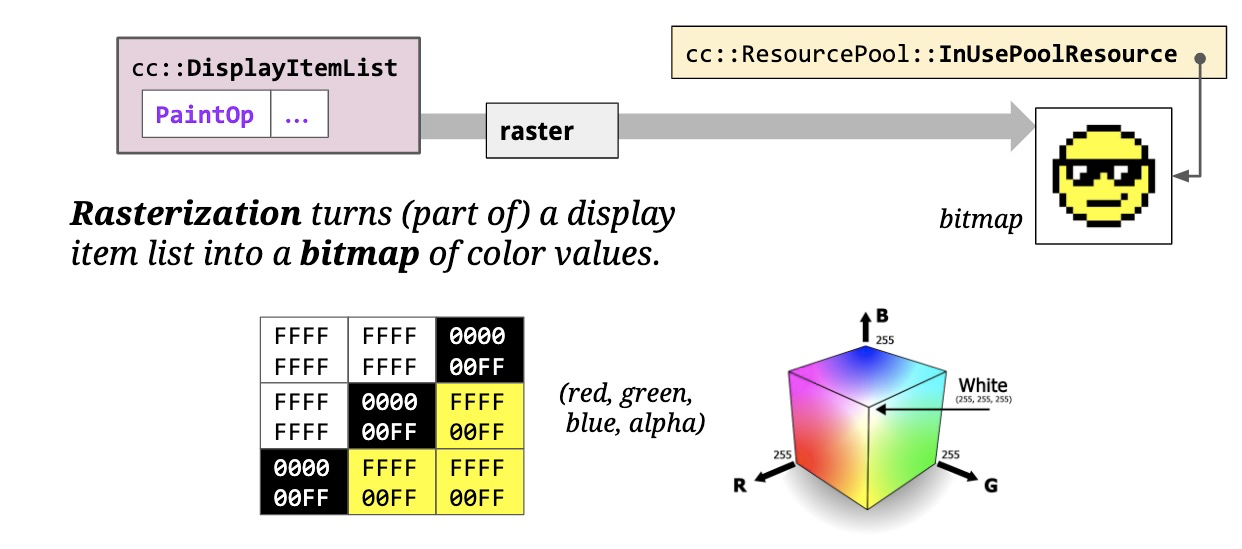
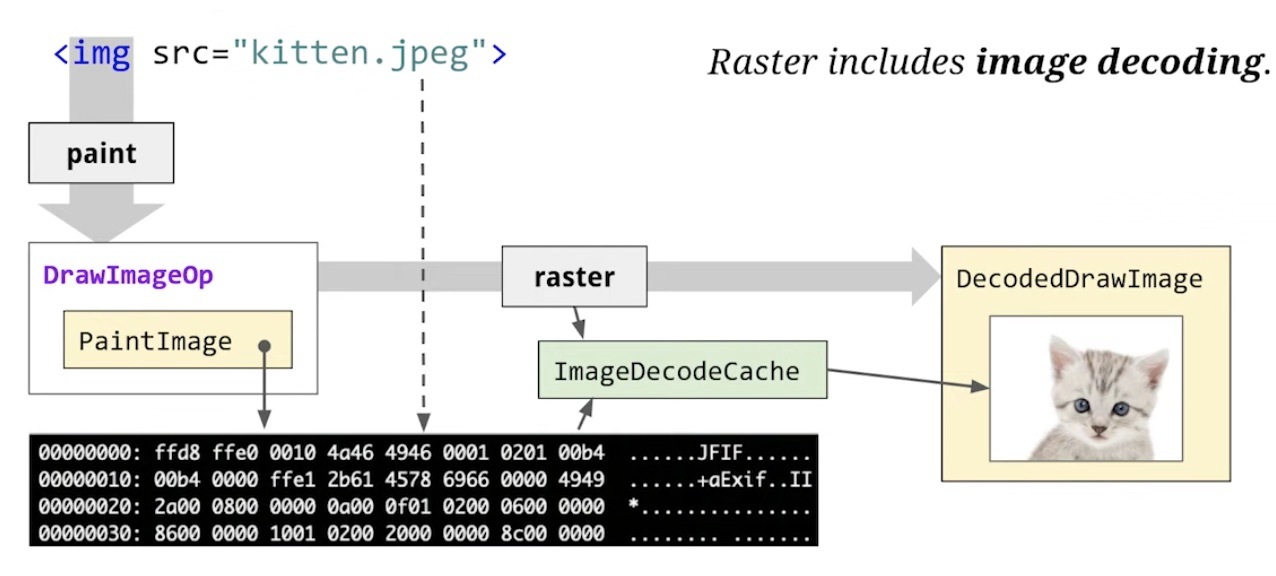
光栅化的过程还包括图片解码。
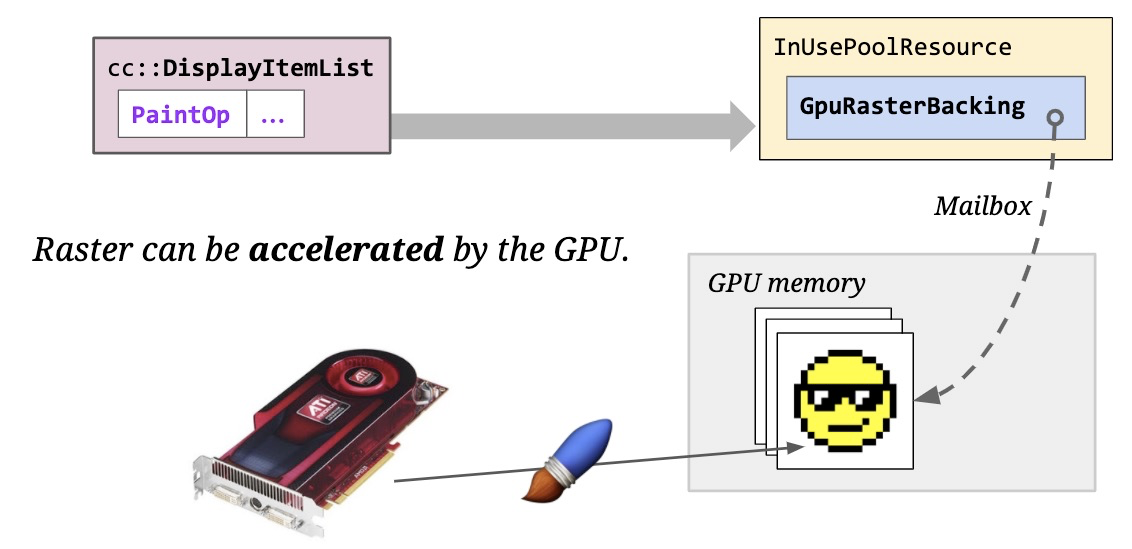
过去GPU只是作为一个内存(GPU Memory),这些内存被GL纹理(OpenGL中的标识符)所引用。我们会将栅格化的像素点放到主内存中,然后上传到GPU,以减小内存压力。
现在GPU已经可以运行产生像素点的着色器,可以在GPU上进行栅格化,这种模式成为加速栅格(硬件加速)。不管是硬件栅格化还是软件栅格化,本质上都是生成了某种内存中像素的位图,这个时候还没有显示到屏幕上。
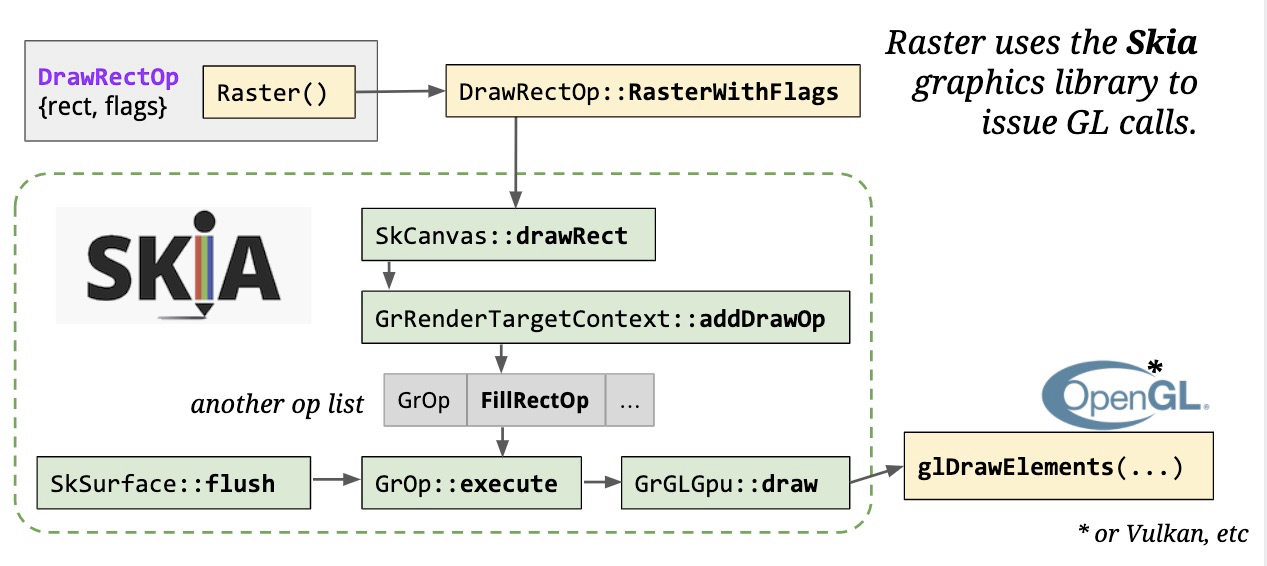
GPU栅格化并不是直接调用GPU,而是通过Skia图形库(Google维护的2D图形库,在Android、Flutter、Chromium都有使用)发出的OpenGL调用。如下所示:
Skia提供了某种抽象层,屏蔽了底层硬件、路径、贝塞尔曲线等复杂的概念,当需要栅格化显示项(Display Item)时,会先去调用SkCanvas上面的方法,它是Skia的调用入口。SkCanvas提供了Skia内部更多的抽象,在硬件加速时,它会构建另一个绘图操作缓冲区,然后对其进行刷新,在栅格化任务结束时,通过flush操作,我们获得了真正的GL指令。GL指令运行在GPU Process。
Skia和GL指令可以运行在不同进程,也可以运行在同一个进程这就产生了两种调用方式。
- In Proess Raster
- Out of Proess Raster
1 老版本的调用采用这种方式,Skia运行在Renderer Process,负责产生GL指令,GPU有单独的GPU Process,这种模式下Skia无法直接进行渲染系统调用,在初始化Skia的时候回给它一个函数指针表(指向了GL API,但不是真正的OpenGL API,而是Chromium提供的代理),函数指针表转换为真正的OpenGL API的过程称为命令缓冲区(GpuChannelMsg_FlushCommandBuffers),
单独的GPU进程有利于隔离GL操作,提升稳定性和安全性,这种模式也称为沙箱机制(不安全的操作运行在独立的进程里)。

2 新版本把绘制操作放到了GPU Process,在GPU一侧运行Skia,这有助于提升性能。

接下来就是执行GL指令,GL指令一般是由底层so库提供,在Windows平台上OpenGL还会被转换为DirectX(Microsoft的图形API,用于图形加速)。

10 Activate
在Commit之后,Draw之前有一个Activate操作。Raster和Draw都发生在合成器线程里的Layer Tree上,但是我们知道Raster操作是异步的,有可能需要执行Draw操作的时候,Raster操作还没完成,这个时候就需要解决这个问题。
它将Layer树分为:
- Pending Tree:负责接收commit,然后将Layer进行Raster操作
- Active Tree:会从这里取出栅格化好的Layer进行draw操作。
这个拷贝的过程就称为Activate,如下所示:

事实上Layer Tree主要有四种:
- 主线程图层树:cc::Layer,始终存在。
- Pending树:cc::LayerImpl,合成器线程,用于光栅化阶段,可选。
- Active树:cc::LayerImpl,合成器线程,用于绘制阶段,始终存在。
- Recycle树:cc::LayerImpl,合成器线程,与Pending树不会同时存在。
主线程的图层树由LayerTreeHost拥有,每个图层以递归的方式拥有其子图层。Pending树、Active树、Recycle树都是LayerTreeHostImpl拥有的实例。这些树被定义在cc/trees目录下。之所以称之为树,是因为早期它们是基于树结构实现的,目前的实现方式是列表。
11 Draw
当每个图块都被光栅化以后,合成器线程会为每个图块生成draw quads(在屏幕指定位置绘制图块的指令,包含了属性树里面的变换、特效等操作),这些draw quads指令被封装在CompositorFrame对象中,CompositorFrame对象也是Render Process的输出产物。它会被提交到GPU Process中。我们平时提到的60fps输出帧率里面的帧指的就是Compositor Frame。
Draw操作就是栅格化的图块生成draw quads的过程。

Display Compositor
12 Display
相关文档
- Viz Doc
Draw操作完成以后,就生成了Compositor Frame,它们会被输出到GPU Process。 它会从多个来源的Render Process接收Compositor Frame。
- Browser Process也有自己的Compositor来生成Compositor Frame,这些一般是用来绘制Browser UI(导航栏,窗口等)。
- 每次创建tab或者使用iframe,会创建一个独立的Render Process。

Display Compositor运行在Viz Compositor thread,Viz会调用OpenGL指令来渲染Compositor Frame里面的draw quads,把像素点输出到屏幕上。
什么是VIz?
Viz是VIsual的缩写,它是Chromium整体架构转向服务化的一个重要组成部分,包含Compositing、GL、Hit Testing、Media、VR/AR等众多功能。
VIz也是双缓冲输出的,它会在后台缓冲区绘制draw quads,然后执行交换命令最终让它们显示在屏幕上。
什么是双缓冲机制?
在渲染的过程中,如果只对一块缓冲区进行读写,这样会导致一方面屏幕要等到去读,而GPU要等待去写,这样要造成性能低下。一个很自然的想法是把读写分开,分为:
- 前台缓冲区(Front Buffer):屏幕负责从前台缓冲区读取帧数据进行输出显示。
- 后台缓冲区(Back Buffer):GPU负责向后台缓冲区写入帧数据。
这两个缓冲区并不会直接进行数据拷贝(性能问题),而是在后台缓冲区写入完成,前台缓冲区读出完成,直接进行指针交换,前台变后台,后台变前台,那么什么时候进行交换呢,如果后台缓存区已经准备好,屏幕还没有处理完前台缓冲区,这样就会有问题,显然这个时候需要等屏幕处理完成。屏幕处理完成以后(扫描完屏幕),设备需要重新回到第一行开始新的刷新,这期间有个间隔(Vertical Blank Interval),这个时机就是进行交互的时机。这个操作也被称为垂直同步(VSync)。
到这里,整个渲染流程就结束了,前端的代码变成了可以与用户交互的像素点。
-
手写消息中间件:从零开始的指南11-26
-
Java语音识别项目资料:新手入门教程11-26
-
JAVA语音识别项目资料:新手入门教程11-26
-
Java语音识别项目资料:入门与实践指南11-26
-
Java云原生资料入门教程11-26
-
Java云原生资料入门教程11-26
-
Java云原生资料:新手入门教程11-26
-
Java创意资料:新手入门的创意学习指南11-25
-
JAVA对接阿里云智能语音服务资料详解:新手入门指南11-25
-
Java对接阿里云智能语音服务资料详解11-25
-
Java对接阿里云智能语音服务资料详解11-25
-
JAVA副业资料:新手入门及初级提升指南11-25
-
Java副业资料:入门到实践的全面指南11-25
-
Springboot应用的多环境打包项目实战11-25
-
SpringBoot应用的生产发布项目实战入门教程11-25
