云计算
【2020版冲刺年薪30W】超全大数据学习路线+思维导图

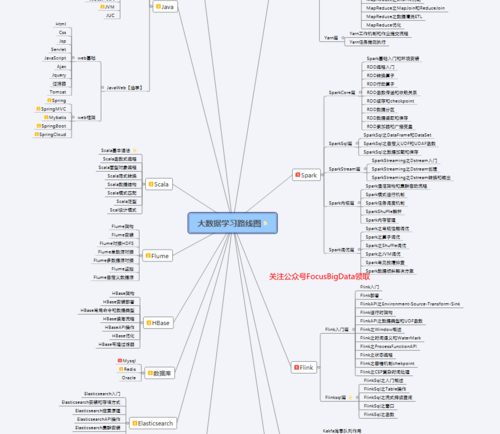
大数据学习路线
下面和大家讲一下大数据学习的路线,帮助大家快速进入大数据行业。我会结合自己的实际经历还说明学习路线。该路线针对的对象是零基础小白,目标是到初中级大数据工程师,要求掌握数据建模,数据存储,数据存储,数据传输,数据分析等能力达到大数据岗位的应聘标准。
(一)Java基础和web开发
很多人问过我,学大数据要不要学Java,我的答案是肯定的。首先Java是一门面向对象的编程语言,也是一门应用非常之广的语言,对于零基础的小白必须先有一些基本的编码能力和面向对象编程的思想。其次很多框架的底层就是用Java进行开发的,比如Hadoop,如果想要更近一步,源码是要看的。所以学习Java基础是十分必要的。Java基础重点包括:
- Java常用类【特别是字符串处理相关的类】
- 异常处理
- 集合泛型
- IO流
- 多线程
- 反射
- 网络编程
- 常见设计模式
- JVM【难点+重点,但比较花时间】
那么JavaWeb开发要不要会呢?我的建议是了解就行,了解常见的SSM框架,了解Web项目大致的开发流程,对整个软件的开发有一个感性的认识,这样就足够了。当然学有余力请继续深入。
(二)工具类
软件开发都绕不开使用别人的轮子,好的工具让我们开发效率大大提升,下面工具必须掌握:
编辑器:Eclipse + IDEA
项目构建工具:Maven + Gradle(有余力)
数据库:Mysql【初期先了解增删改查,后面有时间能多深入就多深入】
操作系统:Linux【常见命令会就行】
脚本语言:Shell【看得懂就行】
虚拟机:VMware 创建-克隆虚拟机,拍摄-还原快照【操作过就行】
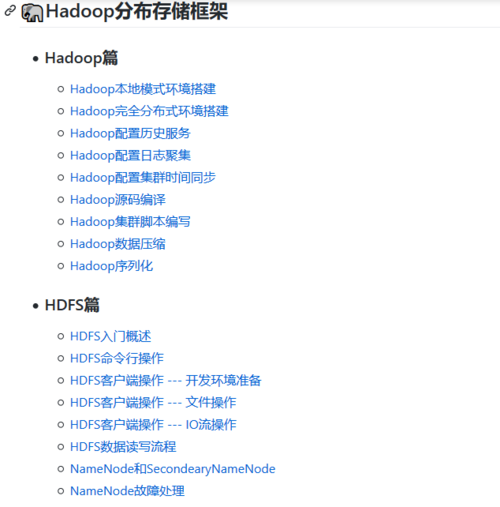
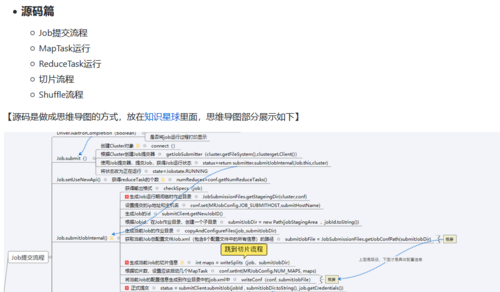
(三)Hadoop生态系统
- HDFS:学会搭建完全分布式集群,知道如何根据业务编写MapReduce程序,并放到集群上运行
- YARN:知道它是个资源管理器和k8s一样,熟悉Job提交的过程
- Mapreduce:编写业务程序【熟悉一些数据倾斜的解决方案和底层Shuffle过程】
- Zookeeper:分布式协调框架【知道Zookeeper选举机制和常用命令】
- Hive:数据仓库,底层是MapReduce【重点掌握:HQL语句书写,窗口函数,多做一些案例总结自己的套路,优化也要了解一下】
- HBase:超大型分布式数据库,经常用来做实时查询【了解HBase架构,RowKey设计原则,后面开发用到再来深入】
- Flume:数据传输框架【知道Flume组成,拦截器和选择器使用】
- Kafka:消息缓存框架【Kafka架构-压测-监控-ISR同步队列-事务-高效读取】
- Sqoop:关系型数据库和HDFS,HBase之间数据的传输框架
- Ambari: 用于配置、管理和监视Hadoop集群,基于Web,界面友好
- Impala: 对存储在Apache Hadoop的HDFS,HBase的数据提供直接查询互动的SQL
(四)Spark生态
到这里又要学习一门新的编程语言Scala,初入Scala可能会对它的语法结构产生不习惯,熟悉之后你会发现Java代码是很繁琐的。编程语言是什么不重要,关键是背后的思想和逻辑才重要。
Scala:了解基础语法、函数式编程和隐式转换就行
Spark:可以看作是对Hadoop框架的优化,它是基于内存进行计算的,性能提高很多。【熟悉Spark部署方式-提交流程-参数设置-RDD血统-宽窄依赖-转换和行动算子-广播变量和累加器-性能调优】
Spark-Sql:spark中负责和数据库交互的模块【熟悉DataFrame-DataSet,SQL语句书写,UDF和UDTF函数使用】
Spark-Streaming:spark中负责流式计算的模块【了解流式计算的原理,背压机制,窗口函数】

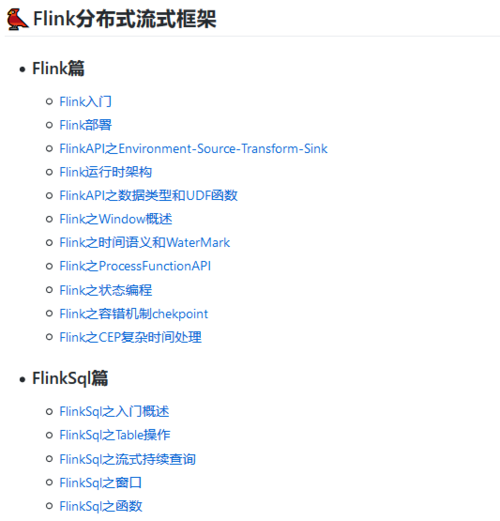
(五)Flink框架
Flink是目前最火的处理流式数据的框架应掌握一下内容
本文配套GitHub:https://github.com/zhutiansama/FocusBigData
-
简易入门:掌握软件架构的基础知识11-22
-
架构师入门指南:从零开始学习软件架构设计11-22
-
系统架构师学习:入门与初级实践指南11-22
-
系统架构师教程:入门与初级指南11-22
-
系统架构师教程:新手入门必读11-22
-
系统架构师资料入门指南11-22
-
负载均衡入门:新手必读教程11-20
-
系统部署入门:新手必读指南11-20
-
初学者的负载均衡教程:轻松入门与实战11-20
-
系统部署教程:初学者必备指南11-20
-
负载均衡项目实战:新手入门教程11-20
-
系统部署项目实战:新手入门教程11-20
-
负载均衡资料入门指南11-20
-
微服务资料入门教程:轻松掌握微服务基础知识11-20
-
负载均衡入门:新手必读指南11-20
